
![]()
![]()
![]()
![]()
![]()
![]()
Reproduce, Automate, Scale your data science.
Welcome to Polyaxon, a platform for building, training, and monitoring large scale deep learning applications. We are making a system to solve reproducibility, automation, and scalability for machine learning applications.
Polyaxon deploys into any data center, cloud provider, or can be hosted and managed by Polyaxon, and it supports all the major deep learning frameworks such as Tensorflow, MXNet, Caffe, Torch, etc.
Polyaxon makes it faster, easier, and more efficient to develop deep learning applications by managing workloads with smart container and node management. And it turns GPU servers into shared, self-service resources for your team or organization.
-
Install CLI
# Install Polyaxon CLI $ pip install -U polyaxon -
Create a deployment
# Create a namespace $ kubectl create namespace polyaxon # Add Polyaxon charts repo $ helm repo add polyaxon https://charts.polyaxon.com # Deploy Polyaxon $ polyaxon admin deploy -f config.yaml # Access API $ polyaxon port-forward
Please check polyaxon installation guide
-
Start a project
# Create a project $ polyaxon project create --name=quick-start --description='Polyaxon quick start.'
-
Train and track logs & resources
# Upload code and start experiments $ polyaxon run -f experiment.yaml -u -l -
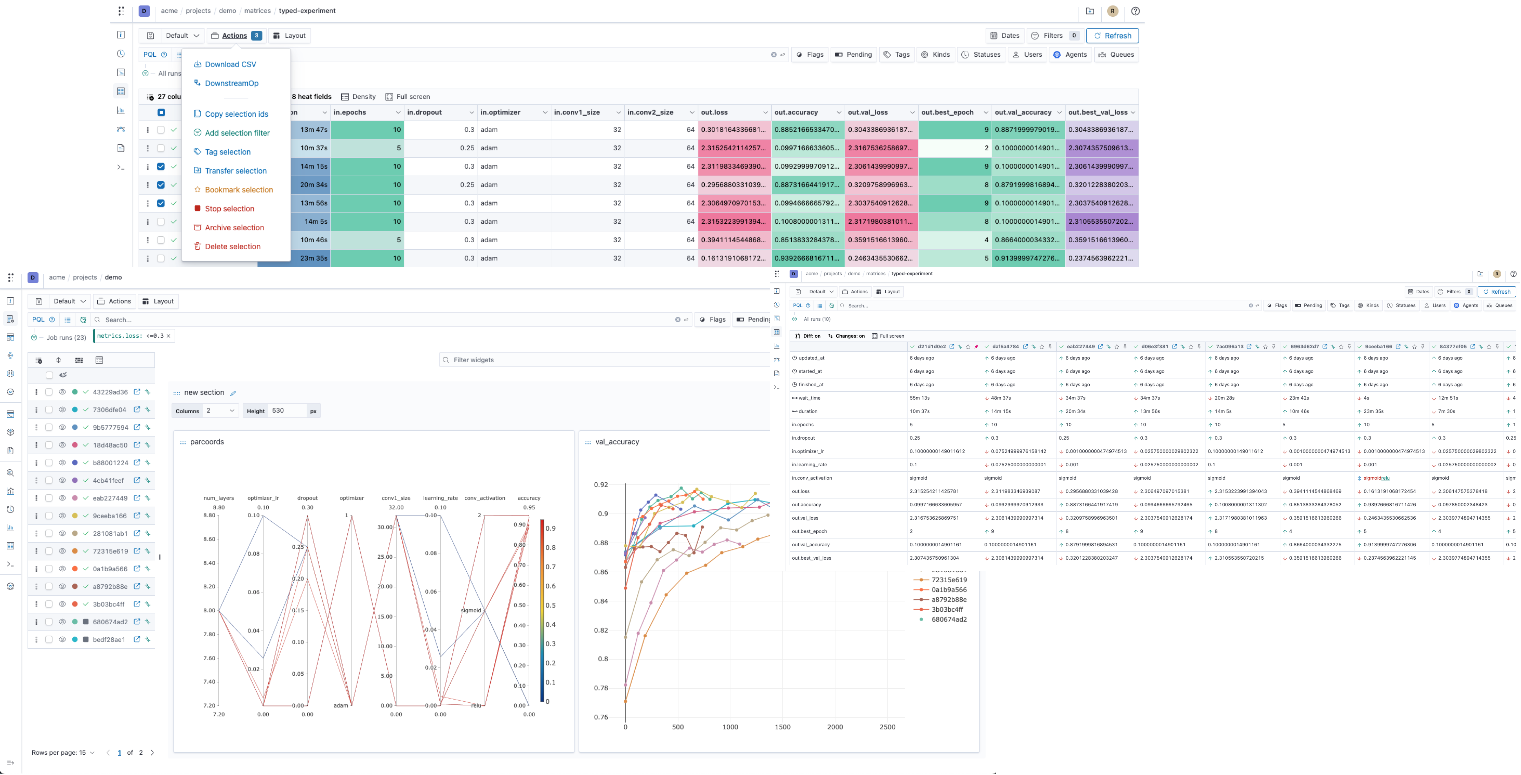
Dashboard
# Start Polyaxon dashboard $ polyaxon dashboard Dashboard page will now open in your browser. Continue? [Y/n]: y
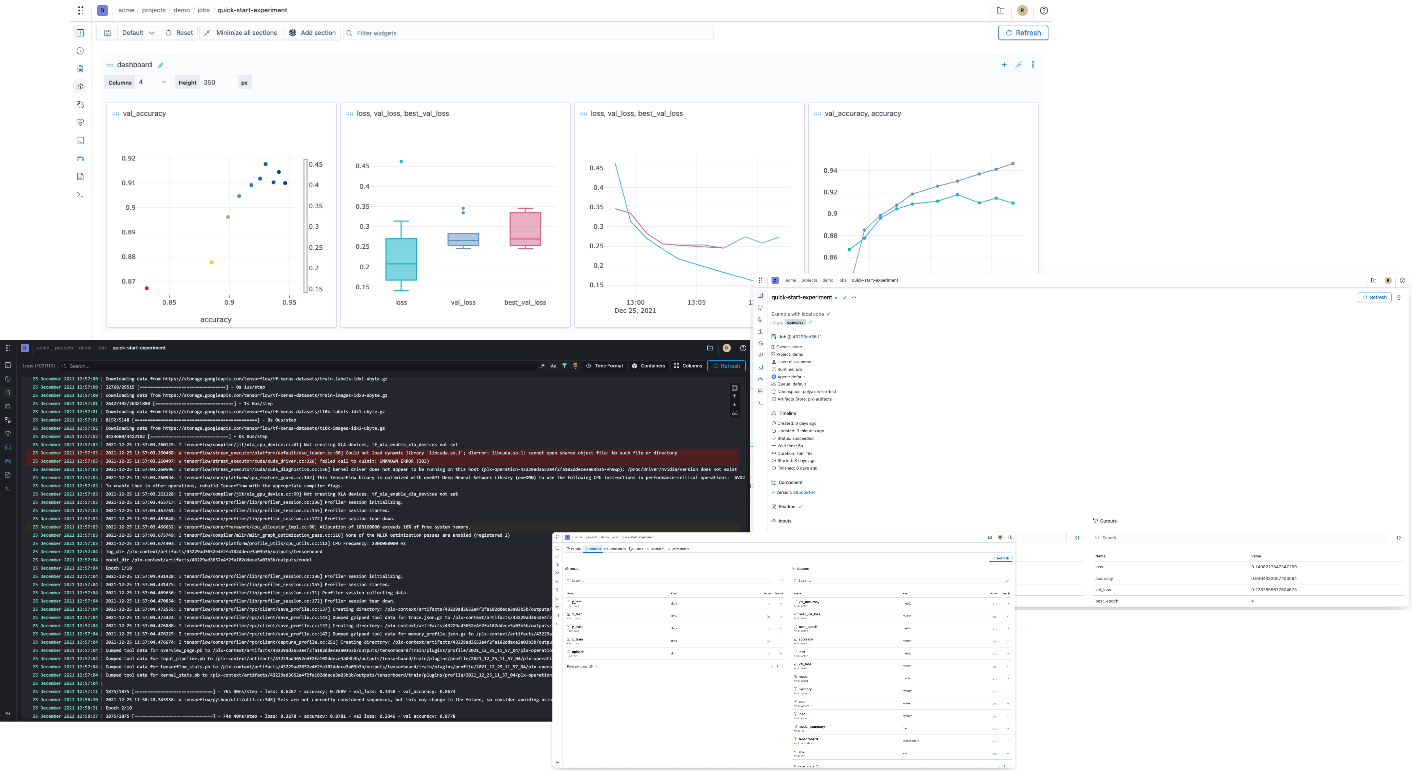
- Notebook
# Start Jupyter notebook for your project $ polyaxon run --hub notebook
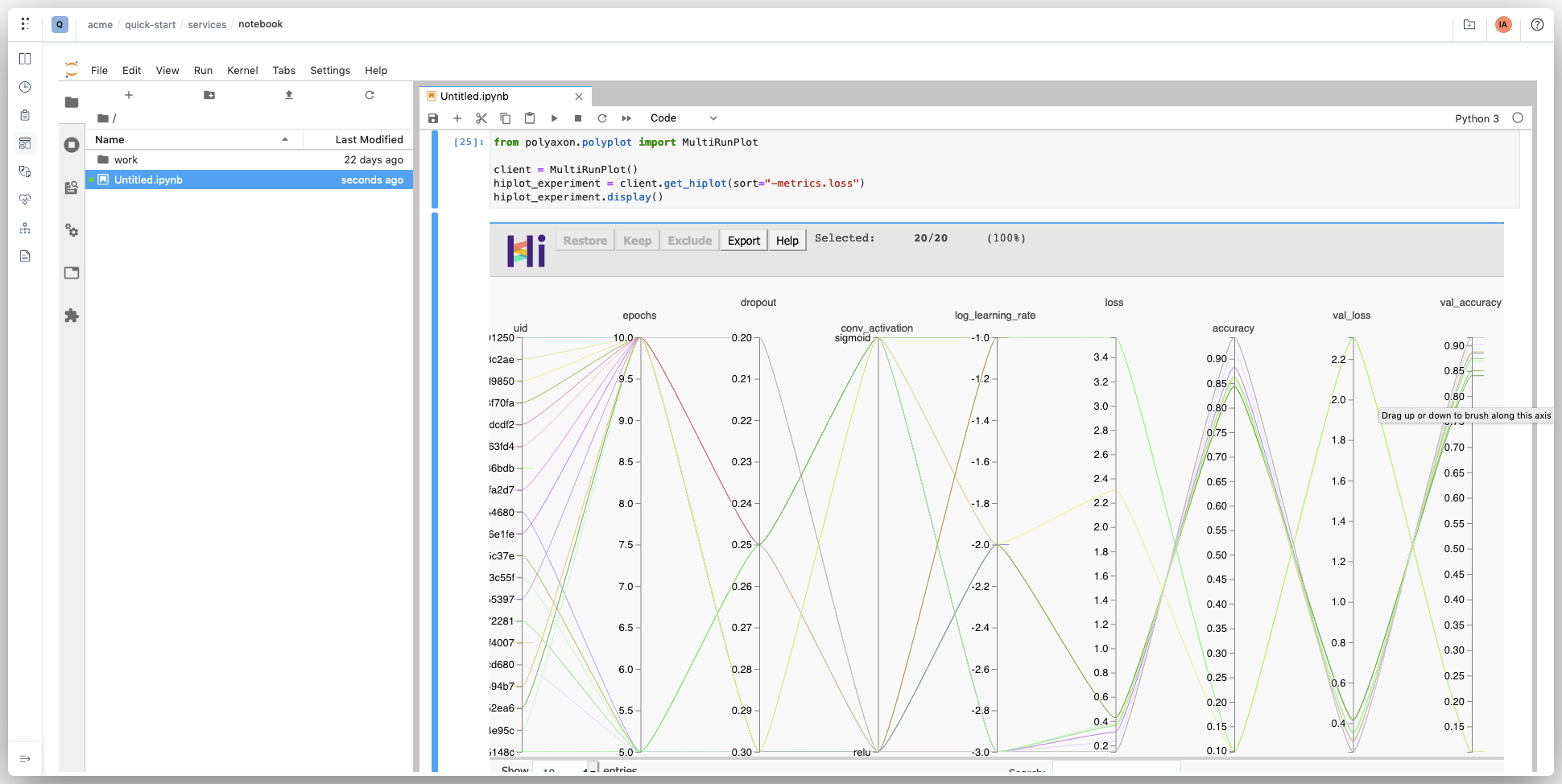
- Tensorboard
# Start TensorBoard for a run's output $ polyaxon run --hub tensorboard -P uuid=UUID
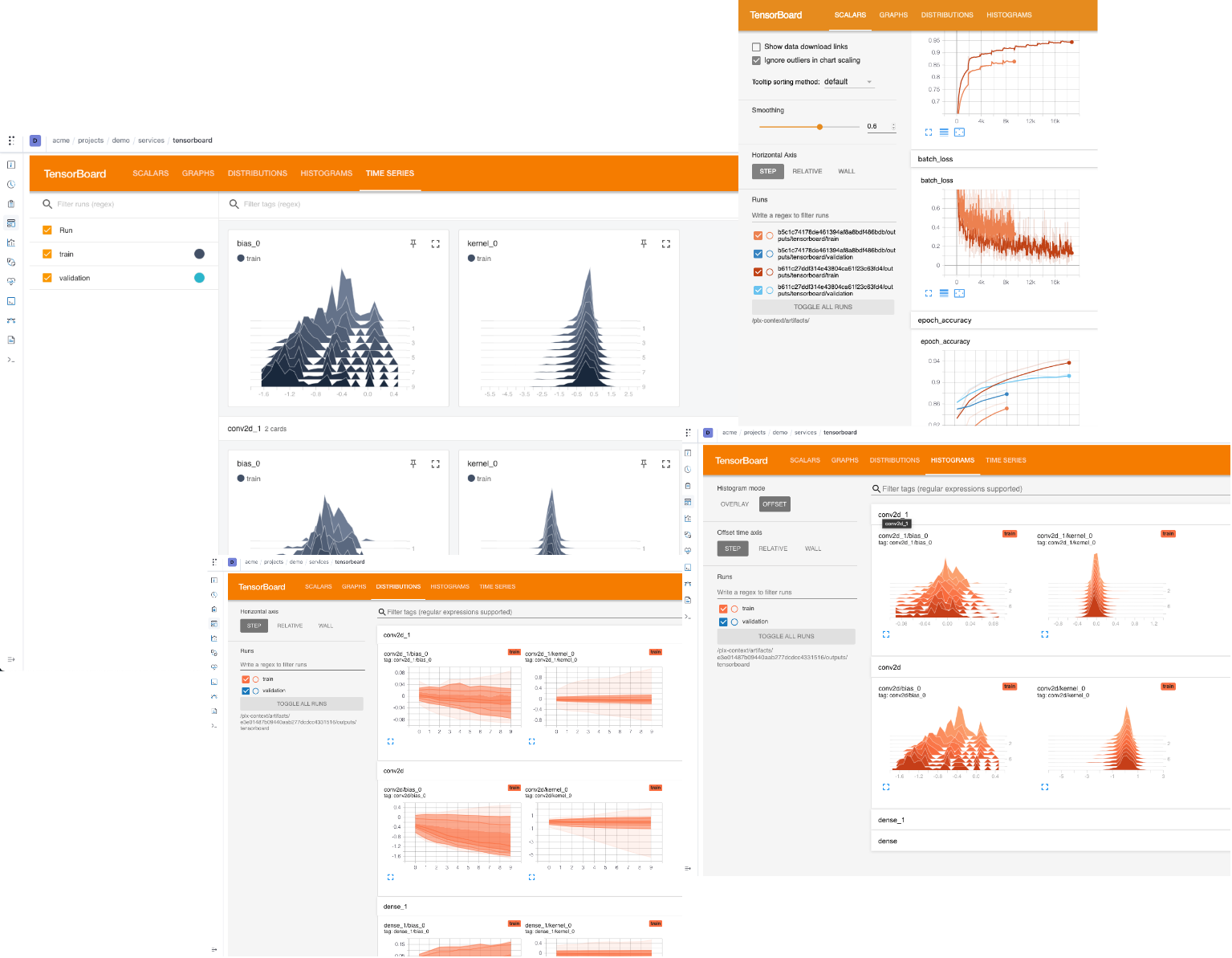
Please check our quick start guide to start training your first experiment.
Polyaxon supports and simplifies distributed jobs. Depending on the framework you are using, you need to deploy the corresponding operator, adapt your code to enable the distributed training, and update your polyaxonfile.
Here are some examples of using distributed training:
Polyaxon has a concept for suggesting hyperparameters and managing their results very similar to Google Vizier called experiment groups. An experiment group in Polyaxon defines a search algorithm, a search space, and a model to train.
You can run your processing or model training jobs in parallel, Polyaxon provides a mapping abstraction to manage concurrent jobs.
Polyaxon DAGs is a tool that provides container-native engine for running machine learning pipelines. A DAG manages multiple operations with dependencies. Each operation is defined by a component runtime. This means that operations in a DAG can be jobs, services, distributed jobs, parallel executions, or nested DAGs.

Check out our documentation to learn more about Polyaxon.
Polyaxon comes with a dashboard that shows the projects and experiments created by you and your team members.
To start the dashboard, just run the following command in your terminal
$ polyaxon dashboard -yPolyaxon is stable and it's running in production mode at many startups and Fortune 500 companies.
Please follow the contribution guide line: Contribute to Polyaxon.
If you use Polyaxon in your academic research, we would be grateful if you could cite it.
Feel free to contact us, we would love to learn about your project and see how we can support your custom need.