This is an unofficial implementation of the ImageBind Trainer with LoRA fine-tuning. To adapt this repository to your own dataset,
checkout train.py and replace the dreambooth with your own.
Make sure to clone this repository recursively to include the submodules:
git clone --recurse-submodules -j8 https://github.com/fabawi/ImageBind-LoRA.gitFor installation, please follow the original usage instructions.
Install matplotlib when using the train.py script without the --headless argument.
Warning: If you receive the following error -> "'FastAPI' object has no attribute 'debug'", upgrade fastapi to the latest version:
pip install --upgrade fastapiIn example.py, you can find an example of how to use the model for inference. To try the LoRA fine-tuned model,
change lora=True within the script. To try the original ImageBind model, set lora=False.
example explanation: The dreambooth dataset contains the classes dog3, dog5, and dog8. Since the original
ImageBind model was not trained on some arbitrary number-naming scheme, it matches the wrong images with dog8 and dog5.
However, the LoRA fine-tuned model separates the 3 dog classes, indicating it was successfully adapted
to the toy dataset. This approach distorts the pretrained features of ImageBind. To maintain the original embeddings,
we propose experimenting with the two-step fine-tuning approach described in
this paper: linear probing followed by full model fine-tuning.
To avoid diverging too far from the objective: fine-tuning the multimodal representation; We limit those two steps to fine-tuning the ImagBind model.
In our implementation, linear probing is analogous to fine-tuning the last layer, whereas full model fine-tuning is analogous to LoRA fine-tuning
(Although tuning the full model is still possible by not setting the --lora argument).
ImageBind-LoRA support linear probing by passing the --linear_probing argument to train.py. Note that the training process
should then be split into two stages, passing --linear_probing in an initial training session, followed by --lora on training
completion. With linear_probing, no distortion to original pretrained features is observed. All classes are accurately predicted
when setting lora=False and linear_probing=True in example.py. Given that the example is running on a minimal toy dataset (dreambooth)
and that the samples belong to a different distribution than the pretrained samples of ImageBind, we observe better outcomes than fine-tuning
with LoRA. This would most likely not be the case when fine-tuning on larger datasets.
To train the model, run:
python train.py --batch_size 12 --max_epochs 500 \
--lora --lora_modality_names vision text \
--self_contrast --datasets dreamboothYou can enable logging using comet, wandb or tensorboard by setting the --loggers argument to the chosen logger/s.
Make sure to install the respective logging packages beforehand as well as the necessary environment variables.
To specify the layers or modalities to apply LoRA to,
use the --lora_layer_idxs and --lora_modality_names arguments.
To override specific layer counts for a certain modality, you could target the modality specifically,
e.g., add the following argument to specify LoRA for the first 6 layers of the vision trunk only:
--lora_layer_idxs_vision 1 2 3 4 5 6To train on GPU (currently runs on a single GPU, but multi-GPU training will be added soon), set the --device argument:
--device cuda:0The LoRA models used in example.py
(checkpoints found in .checkpoints/lora/550_epochs/ with postix _dreambooth_last.safetensors),
was trained for ~2 hours on a 3080Ti with 12 GB VRAM, consuming 5.66 GB VRAM and ~4 GB RAM. The model converged to a similar state in less than 30 mins.
INFO:
8.0 M Trainable params
1.2 B Non-trainable params
1.2 B Total params
4,815.707 Total estimated model params size (MB)
We set the train arguments as follows:
# installed comet-ml:
# pip install comet-ml
# and set the env variables:
# export COMET_API_KEY=<MY_API_KEY>
# export COMET_WORKSPACE=<MY_WORKSPACE_NAME>
# export COMET_PROJECT_NAME=Imagebind-lora
python train.py --batch_size 12 --max_epochs 550 --num_workers 4 \
--lora --lora_modality_names vision text \
--self_contrast --datasets dreambooth \
--device cuda:0 --headless --loggers cometNote: To perform linear probing (optimizing the last layer of each modality's head only), maintain all arguments,
replacing --lora with --linear_probing (Both cannot be set in the same run).
On running --lora in the next training session/s, the checkpoint of the heads is automatically loaded and saved,
assuming the --lora_checkpoint_dir remains the same.
Rohit Girdhar*, Alaaeldin El-Nouby*, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, Ishan Misra*
To appear at CVPR 2023 (Highlighted paper)
[Paper] [Blog] [Demo] [Supplementary Video] [BibTex]
PyTorch implementation and pretrained models for ImageBind. For details, see the paper: ImageBind: One Embedding Space To Bind Them All.
ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. It enables novel emergent applications ‘out-of-the-box’ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation.
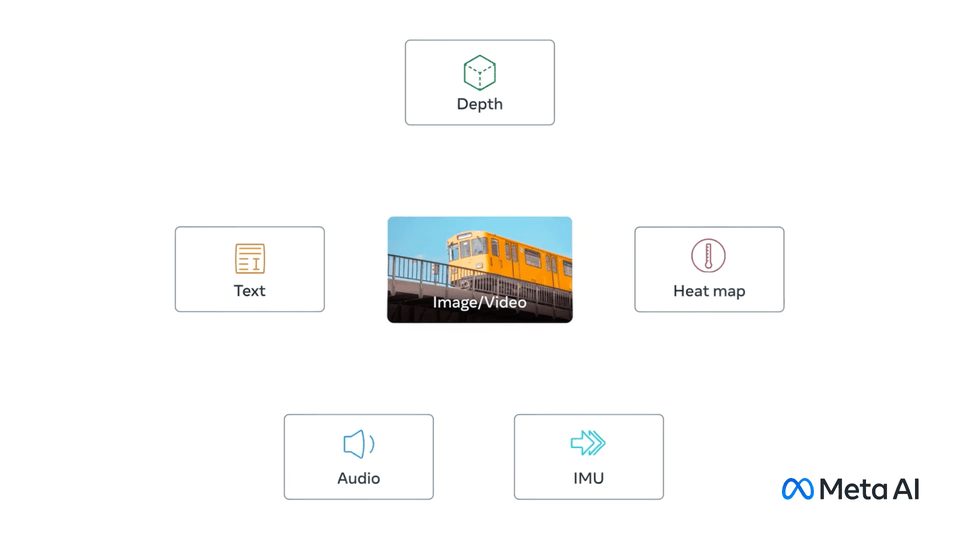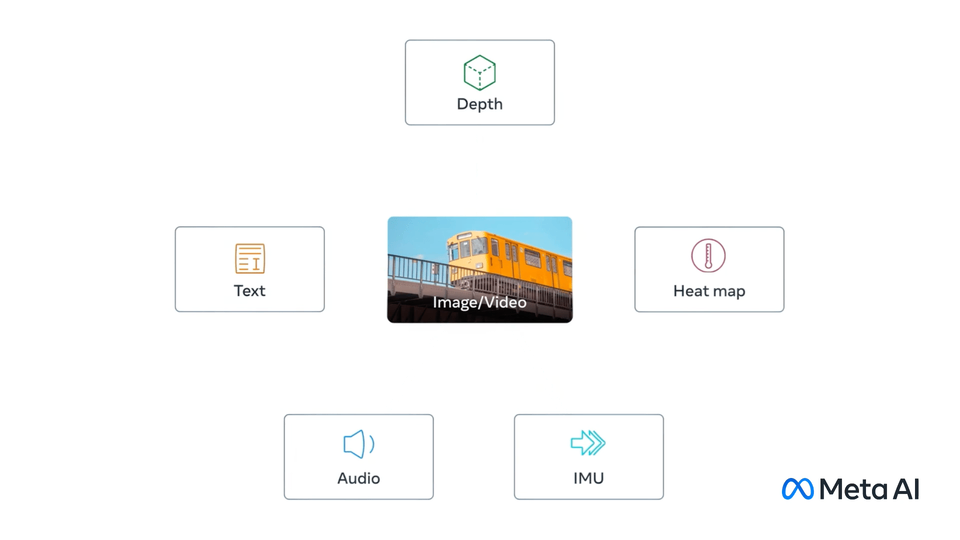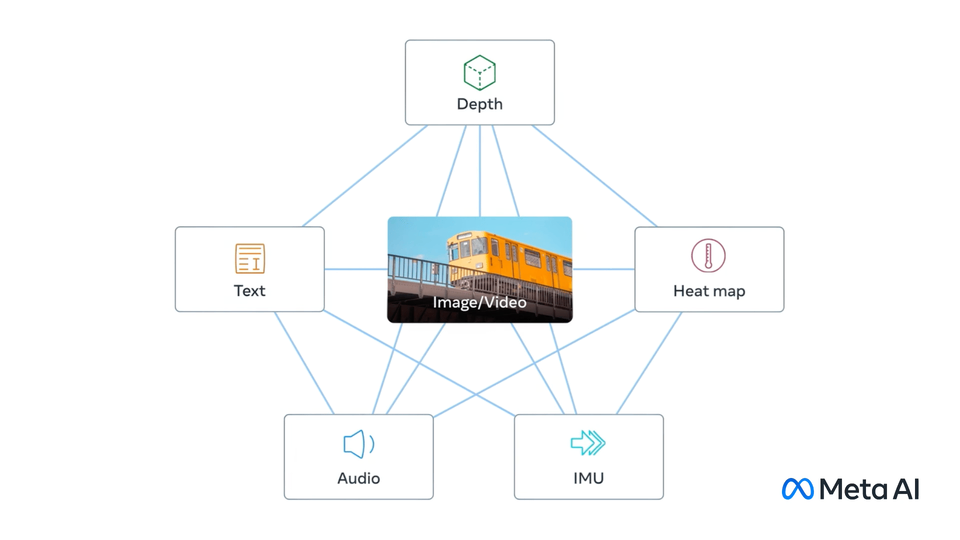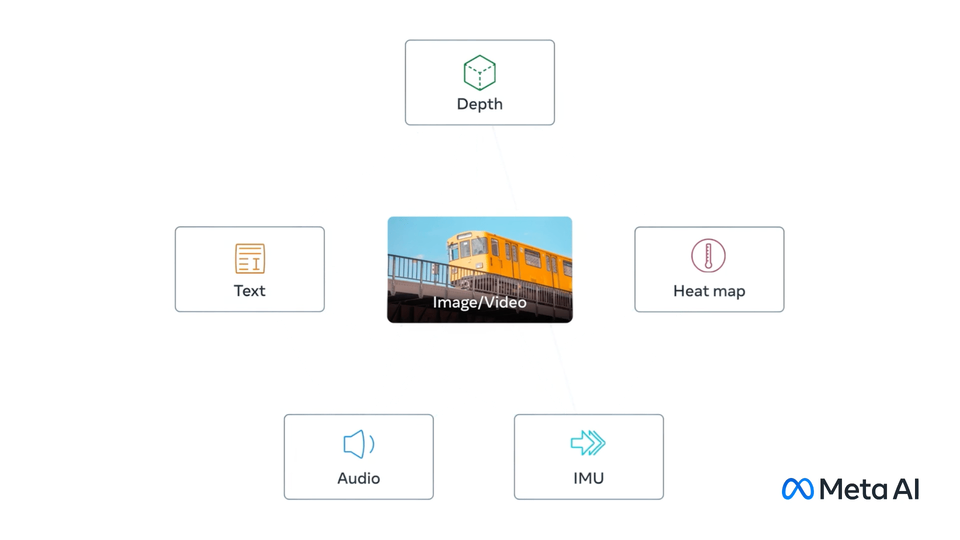
Emergent zero-shot classification performance.
| Model | IN1k | K400 | NYU-D | ESC | LLVIP | Ego4D | download |
|---|---|---|---|---|---|---|---|
| imagebind_huge | 77.7 | 50.0 | 54.0 | 66.9 | 63.4 | 25.0 | checkpoint |
Install pytorch 1.13+ and other 3rd party dependencies.
conda create --name imagebind python=3.8 -y
conda activate imagebind
pip install -r requirements.txtFor windows users, you might need to install soundfile for reading/writing audio files. (Thanks @congyue1977)
pip install soundfile
Extract and compare features across modalities (e.g. Image, Text and Audio).
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
# Expected output:
#
# Vision x Text:
# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
# [3.3836e-05, 9.9994e-01, 2.4118e-05],
# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
#
# Audio x Text:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
#
# Vision x Audio:
# tensor([[0.8070, 0.1088, 0.0842],
# [0.1036, 0.7884, 0.1079],
# [0.0018, 0.0022, 0.9960]])Please see the model card for details.
ImageBind code and model weights are released under the CC-BY-NC 4.0 license. See LICENSE for additional details.
See contributing and the code of conduct.
If you find this repository useful, please consider giving a star ⭐ and citation
@inproceedings{girdhar2023imagebind,
title={ImageBind: One Embedding Space To Bind Them All},
author={Girdhar, Rohit and El-Nouby, Alaaeldin and Liu, Zhuang
and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan},
booktitle={CVPR},
year={2023}
}