This is the code repository of the paper:
Topologically-Aware Deformation Fields for Single-View 3D Reconstruction
Shivam Duggal, Deepak Pathak
Carnegie Mellon University
CVPR 2022
Abstract
Overview
Requirements
Datasets
Training & Evaluation
Visualization Scripts
Pre-trained Models
Texture Transfer
Acknowledgemt
Citation
We present a framework for learning 3D object shapes and dense cross-object 3D correspondences from just an unaligned category-specific image collection. The 3D shapes are generated implicitly as deformations to a category-specific signed distance field and are learned in an unsupervised manner solely from unaligned image collections and their poses without any 3D supervision. Generally, image collections on the internet contain several intra-category geometric and topological variations, for example, different chairs can have different topologies, which makes the task of joint shape and correspondence estimation much more challenging. Because of this, prior works either focus on learning each 3D object shape individually without modeling cross-instance correspondences or perform joint shape and correspondence estimation on categories with minimal intra-category topological variations. We overcome these restrictions by learning a topologically-aware implicit deformation field that maps a 3D point in the object space to a higher dimensional point in the category-specific canonical space. At inference time, given a single image, we reconstruct the underlying 3D shape by first implicitly deforming each 3D point in the object space to the learned category-specific canonical space using the topologically-aware deformation field and then reconstructing the 3D shape as a canonical signed distance field. Both canonical shape and deformation field are learned end-to-end in an inverse-graphics fashion using a learned recurrent ray marcher (SRN) as a differentiable rendering module. Our approach, dubbed TARS, achieves state-of-the-art reconstruction fidelity on several datasets: ShapeNet, Pascal3D+, CUB, and Pix3D chairs.


Please run the following commands to setup the conda environment for running the TARS codebase.
When compiling CUDA code, you may need to set CUDA_HOME.
conda env create --file requirements.yaml python=3.7
conda activate tars-env
cd external/chamfer3D
python3 setup.py install
-
CUBS-200-2011: To download the CUBS dataset (including pre-computed SfM poses), please follow the instructions mentioned here.
-
ShapeNet [Chairs, Planes, Cars]: To download the ShapeNet dataset, please follow the instructions mentioned here.
-
Pascal3D+ [Chairs]: To download the Pascal3D chairs dataset, please follow the instructions mentioned here.
-
Pix3D [Chairs]: To download the Pix3D chairs dataset, please refer to Pix3D's official website. Some images of the Pix3D chairs dataset are highly occluded/ truncated. We removed such images using the annotated truncation tag associated with each image and also by manual filtering.
For more details on these datasets, please refer to paper appendix section A.1.
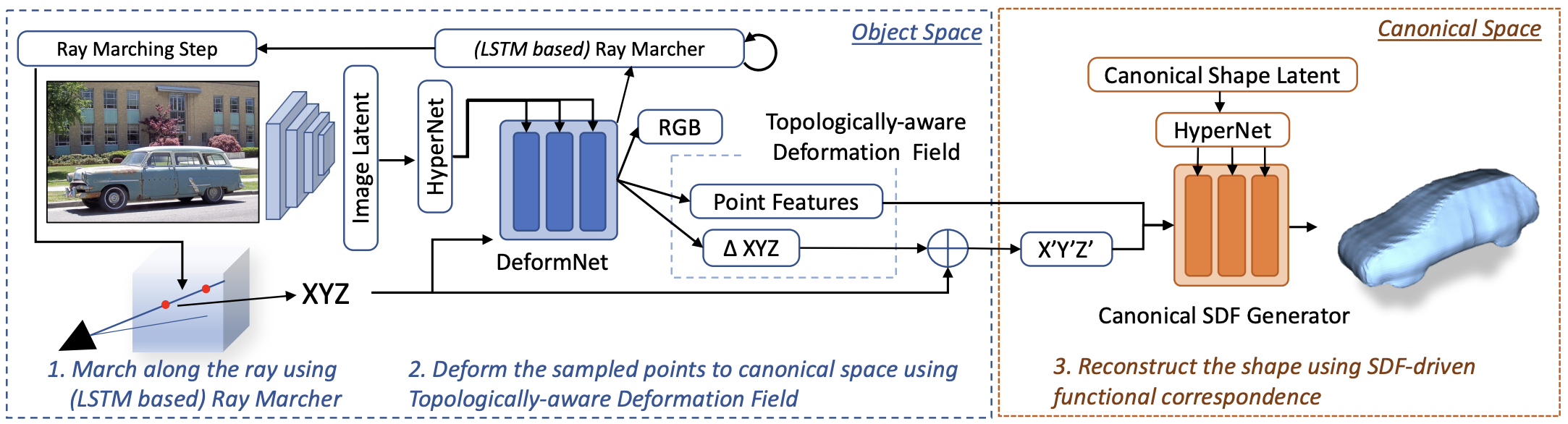
The overall pipeline, as shown below, has three core moduels: (a) SDF Generator, (b) DeformNet, (c) Renderer.
Run the following steps sequentially to train TARS on your favorite dataset:
-
All training jobs are supported with
visdom visualiation(for 3D visualization of the reconstruction 3D point clouds during training). To use visdom, launch the visdom server in a separate shell / tmux session:visdom -port 9001 --hostname localhost
-
To train TARS on any of the above datasets, the bash scripts provided in
scripts/<dataset_name>need to be the executed in the order mentioned below, where<dataset_name>could beshapenet/chair,shapenet/car,shapenet/airplane,cub,pascal3d/chair,pix3d_pascal3d/chair. -
The whole training procedure is broken into 2 main stages (and two intermediate pre-training stages), executed sequentially:
-
Pre-training SDF Generator: In this stage, we fit an MLP (termed as SDF Generator) to predict the signed distance field (SDF) of each 3D point w.r.t. a unit sphere (for which the SDF can be determined analytically). This serves as a good initialization for the SDF Generator which is later used to predict the SDF of arbitrary instances/ shapes.
bash scripts/<dataset_name>/pretrain_sdf_generator.sh -
Stage 1: This stage involves training the image encoder, SDF Generator, and the renderer jointly using category-specific image collection (with associated camera poses and silhouettes) as the training data. In this stage, given the input object's single-view image, we first extract a latent embedding using the image encoder. Next, using the image embedding, we directly predict the SDF value of each 3D point in the normalized object space w.r.t the input objects' surface. We train this whole pipeline using rendering-based losses.
bash scripts/<dataset_name>/train_stage_1.sh -
Post Stage 1 training, using the image latent embeddings of all the training instances, we generate a canonical shape latent code (which is later optimized in stage 2) as the mean of all the training instance image latent codes.
bash scripts/<dataset_name>/dump_canonical_shape.sh -
Pre-training DefomNet: Pre-training DefomNet: In this stage, we fit an MLP (termed as DeformNet) to map a unit sphere to the learned canonical shape (from stage 1). More precisely, we deform each 3D point from the object space to the canonical space, such that the SDF of the canonical point w.r.t canonical surface is equal to the SDF of the object-space point w.r.t the surface of the unit sphere. Basically, through this, we try to reconstruct a unit sphere by mapping to the canonical shape.
bash scripts/<dataset_name>/pretrain_deformnet.sh -
Stage 2: This final training stage involves tuning all the modules: Image Encoder, DeformNet, Canonical Shape Code, SDF Generator, and the Renderer, using category-specific image collection (with associated camera poses and silhouettes) as the training data. Using the image embedding (extracted using the image encoder), we deform each 3D point from the object space to the canonical space. Using the canonical latent encoding and the SDF Generator, we predict the SDF of the deformed point. We train this whole pipeline mainly using rendering-based losses.
bash scripts/<dataset_name>/train_stage_2.sh
-
Given an input image, we learn the underlying 3D shape as a signed-distance field (SDF). The SDF of the input object is generated by mapping each 3D point (sampled uniformly within a unit cube) to the canonical space (using DeformNet) and then determining the SDF using the Canonical SDF Generator (and the canonical latent code). 3D mesh can then be extracted using marching cubes on the predicted SDF.
bash scripts/<dataset_name>/evaluate.sh
Running the above command will dump the output data (3D mesh and corresponding canonical 3D points) inside output/<dataset_name>/reconstruction_stage_two/<job_name>/dump, where <dataset_name> refers to config parameter: data.dataset and <job_name> refers to config paramrter: name.
The provided evaluation scripts use the shared pretrained TARS models for inference. Make sure to download the required pretrained model into pretrained_models directory (inside TARS root directory) before running the corresponding ./evaluate.sh. To use your own trained models, simply replace the --load tag with the path to your model.
-
We used the python library:
open3dto visualize the reconstructed 3D meshes. This would require connecting to a display (if you are working remotely without a GUI support). -
To create the 3D mesh GIFs as shown in the paper video, we used the python library:
pyvista. -
The visualization scripts are available as interactive jupyter cells in visualization_scripts/mesh_visualizer.ipynb. Note you would have to explicitly install pyvista if you want to render GIFs. (
python3 -m pip install pyvista)
To remotely connect to a display, you could use one of the following: teamviewer, google remote desktop or vncserver.
Please download the trained TARS models from the following links and dump them in a new pretrained_models folder in the TARS root directory:
For the Pix3D dataset, as mentioned in the paper, the reconstruction results obtained by training only the small Pix3D (+ Pascal3D combined) dataset
are quite noisy. As an alternative, we recommend using the trained ShapeNet model for Pix3D reconstruction (i.e --load in scripts/pix3d_pascal3d/chair/evaluate.sh is set to pretrained_models/shapenet_chair.ckpt).
-
We provide three textured meshes from the Pascal3D dataset. Download the
textured_meshesfolder in the TARS root directory. To use these meshes to transfer texture to other Pascal3D meshes, refer to visualization_scripts/texture_transfer.ipynb -
In order to perform the texture experiment with other textured meshes, please follow the following guidelines:
- Reconstruct 3D meshes (3D point cloud and 3D canonical point cloud) using TARS, following Evaluation.
- Paint any of the dumped
mesh.plyfile using meshlab. - Create a folder similar to one of the three folders in the downloaded
textured_meshesdirectory. - Follow step in visualization_scripts/texture_transfer.ipynb to perform texture transfer.
We would like to acknowledge the authors of SDF-SRN repository for code inspiration.
If you use our code or the paper, please consider citing the following:
@article{duggal2022tars3D, author = {Duggal, Shivam and Pathak, Deepak}, title = {Topologically-Aware Deformation Fields for Single-View 3D Reconstruction}, journal= {CVPR}, year = {2022} }
Correspondences to Shivam Duggal ([email protected]).