【编者的话】本文作者是Red Hat的软件工程师 - Marek Goldmann,这篇文章详细介绍了Docker容器的资源管理,总共分了三大部分:CPU、内存以及磁盘IO。作者通过实践举例给读者勾勒出一幅清晰明了的Docker资源管理的画卷。
在这篇博客文章中,我想谈谈Docker容器资源管理的话题。我们往往不清楚它是怎样工作的以及我们能做什么不能做什么。我希望你读完这篇博客文章之后,可以帮助你更容易理解有关Docker资源管理的内容。
注意:我们假设你在一个systemd可用的系统上运行了 Docker。如果你是使用RHEL/CentOS 7+或Fedora 19+,
systemd肯定可用,但是请注意在不同的systemd版本之间可能配置选项会有变化。有疑问时,使用你所工作的系统的systemd的帮助说明。
###1. 基础概念 Docker使用cgroups 归类运行在容器中的进程。这使你可以管理一组进程的资源,可想而知,这是非常宝贵的。
如果你运行一个操作系统,其使用systemd管理服务。每个进程(不仅仅是容器中的进程)都将被放入一个cgroups树中。如果你运行systemd-cgls命令,你自己可以看到这个结构:
{{{ $ systemd-cgls ├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 ├─machine.slice │ └─machine-qemu\x2drhel7.scope │ └─29898 /usr/bin/qemu-system-x86_64 -machine accel=kvm -name rhel7 -S -machine pc-i440fx-1.6,accel=kvm,usb=off -cpu SandyBridge -m 2048 ├─system.slice │ ├─avahi-daemon.service │ │ ├─ 905 avahi-daemon: running [mistress.local │ │ └─1055 avahi-daemon: chroot helpe │ ├─dbus.service │ │ └─890 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation │ ├─firewalld.service │ │ └─887 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid │ ├─lvm2-lvmetad.service │ │ └─512 /usr/sbin/lvmetad -f │ ├─abrtd.service │ │ └─909 /usr/sbin/abrtd -d -s │ ├─wpa_supplicant.service │ │ └─1289 /usr/sbin/wpa_supplicant -u -f /var/log/wpa_supplicant.log -c /etc/wpa_supplicant/wpa_supplicant.conf -u -f /var/log/wpa_supplica │ ├─systemd-machined.service │ │ └─29899 /usr/lib/systemd/systemd-machined
[SNIP]}}}
当我们想管理资源的时候,这个方法提供了很大的灵活性,因为我们可以分别管理每个组。尽管这篇博客文章着重于容器,但同样的原则也适用于其他的进程。
注意:如果你想知道更多关于systemd的知识,我强烈推荐RHEL 7的 Resource Management and Linux Containers Guide(资源管理与Linux容器指南)。
####1.1 测试说明
在我的例子中,我将使用stress工具来帮助我生成容器的一些负载,因此我可以真实地看到资源的申请限制。我使用这个Dockerfile创建了一个名为stress的定制的Docker镜像:
{{{ FROM fedora:latest RUN yum -y install stress && yum clean all ENTRYPOINT ["stress"]}}}
####1.2 关于资源报告工具的说明
你使用这个工具来报告cgroups不知道的使用情况如top,/proc/meminfo等等。这意味着你将报告关于这台主机的信息即使是它们在容器内运行。关于这个主题,我发现了一篇不错的文章来自于Fabio Kung。读一读它吧。
因此,我们能做什么?
如果你想快速发现在该主机上使用最多资源的容器(或是最近的所有systemd服务),我推荐systemd-cgtop命令:
{{{ $ systemd-cgtop Path Tasks %CPU Memory Input/s Output/s
/ 226 13.0 6.7G - - /system.slice 47 2.2 16.0M - - /system.slice/gdm.service 2 2.1 - - - /system.slice/rngd.service 1 0.0 - - - /system.slice/NetworkManager.service 2 - - - -
[SNIP]}}}
这个工具能快速预览在系统上正在运行的东西。但是如果你想得到关系使用情况的更详细信息(比如,你需要创建一个好看的图表),你可以去分析/sys/fs/cgroup/…目录。我将向你展示去哪里能找到我们将讨论的每个有用的资源文件(看下面的CGroups fs段落)。
###2. CPU
Docker能够指定(通过运行命令的-c开关)给一个容器的可用的CPU分配值。这是一个相对权重,与实际的处理速度无关。事实上,没有办法说一个容器只可以获得1Ghz CPU。请记住。
每个新的容器默认的将有1024CPU配额,当我们单独讲它的时候,这个值并不意味着什么。但是如果我们启动两个容器并且两个都将使用 100%CPU,CPU时间将在这两个容器之间平均分割,因为它们两个都有同样的CPU配额(为了简单起见,假设没有任何其他进程在运行)。
如果我们设置容器的CPU配额是512,相对于另外一个容器,它将使用一半的CPU时间。但这不意味着它仅仅能使用一半的CPU时间。如果另外一个容器(1024配额的)是空闲的 - 我们的容器将被允许使用100%CPU。这是需要注意的另外一件事。
限制仅仅当它们应该被执行的时候才会强制执行。CGroups不限制进程预先使用(比如,不允许它们更快地运行即使它们有空余资源)。相反的,它提供了它尽可能提供的以及它仅仅在必需的时候限制(比如,当太多的进程同时大量地使用CPU)。
当然,这很难说清楚(我想说的是这不可能说清楚的)多少资源应该被分配给你的进程。这实际取决于其他进程的行为以及多少配额被分配给它们。
####2.1 示例:管理一个容器的 CPU 分配
正如我在前面提到的,你可以使用-c开关来分配给运行在容器中的所有进程的配额值。
因为在我的机器上我有4核,我将使用4压测:
{{{ $ docker run -it --rm stress --cpu 4 stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd }}}
如果你想以相同的方式启动两个容器,两个都将使用 50% 左右的 CPU。但是当我们修改其中一个容器的 shares 时,将发生什么?
{{{ $ docker run -it --rm -c 512 stress --cpu 4 stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd }}}
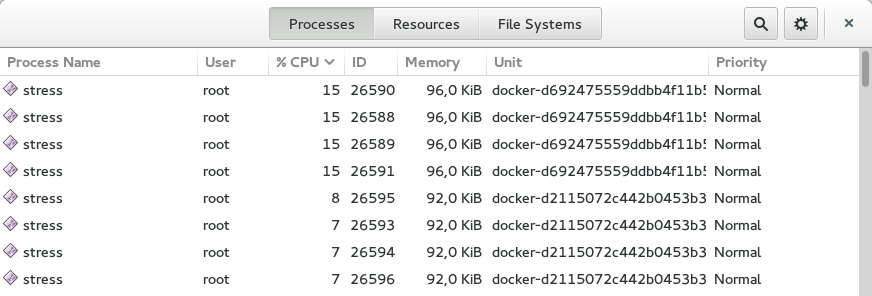
正如你所看到的,CPU在两个容器之间是以这样的方式分割了,第一个容器使用了60%的CPU,另外一个使用了30%左右。这似乎是预期的结果。
注意:丢失的约10%CPU被GNOME、Chrome和我的音乐播放器使用了。
####2.2 Attaching containers to cores
除了限制 CPU配额,我们可以做更多的事情:我们可以把容器的进程固定到特定的处理器(core)。为了做到这个,我们使用docker run命令的--cpuset开关。
为了允许仅在第一个核上执行:
{{{ docker run -it --rm --cpuset=0 stress --cpu 1 }}}
为了允许仅在前两个核上执行:
{{{ docker run -it --rm --cpuset=0,1 stress --cpu 2 }}}
你当然可以混合使用选项--cpuset与-c。
注意:Share enforcement仅仅发生在当进程运行在相同的核上的时候。这意味着如果你把一个容器固定在第一个核,而把另外一个容器固定在另外一个核,两个都将使用各自核的 100%,即使它们有不同的CPU配额设置(再次声明,我假设仅仅有两个容器运行在主机上)。
####2.3 变更一个正在运行的容器的配额 有可能改变一个正在运行的容器的配额(当然或是任何其他进程)。你可以直接与cgroups文件系统交互,但是因为我们有systemds,我们可以通过它来为我们管理。
为了这个目的,我们将使用systemctl命令和set-property参数。使用docker run命令新的容器将有一个systemd scope,自动分配到其内的所有进程都将被执行。为了改变容器中所有进程的CPU配额,我们仅仅需要在scope内改变它,像这样:
{{{ $ sudo systemctl set-property docker-4be96b853089bc6044b29cb873cac460b429cfcbdd0e877c0868eb2a901dbf80.scope CPUShares=512 }}}
注意:添加
--runtime暂时地改变设置。否则,当主机重启后,这个设置会被记住。
把默认值从1024变更到512。你可以看到下面的结果。这一变化发生在记录中。请注意CPU使用率。在systemd-cgtop中100%意味着满额使用了一核,并且这是正确的,因为我绑定了两个容器在相同的核上。
注意:为了显示所有的属性,你可以使用
systemctl show docker-4be96b853089bc6044b29cb873cac460b429cfcbdd0e877c0868eb2a901dbf80.scope命令。想要列出所有可用的属性,请查看man systemd.resource-control。
####2.4 CGroups fs
你可以在/sys/fs/cgroup/cpu/system.slice/docker-$FULL_CONTAINER_ID.scope/下发现指定容器的关于CPU的所有信息,例如:
{{{ $ ls /sys/fs/cgroup/cpu/system.slice/docker-6935854d444d78abe52d629cb9d680334751a0cda82e11d2610e041d77a62b3f.scope/ cgroup.clone_children cpuacct.usage_percpu cpu.rt_runtime_us tasks cgroup.procs cpu.cfs_period_us cpu.shares cpuacct.stat cpu.cfs_quota_us cpu.stat cpuacct.usage cpu.rt_period_us notify_on_release }}}
注意:关于这些文件的更多信息,请移步 RHEL Resource Management Guide查看。
####2.5 概要重述 需要记住的一些事项:
- CPU配额仅仅是一个数字 - 与CPU速度无关
- 新容器默认有
1024配额 - 在一台空闲主机上,低配额的容器仍可以使用100%的CPU
- 如果你想,你可以把容器固定到一个指定核
###3. 内存 现在让我看下内存限制。
第一件事需要注意的是,默认一个容器可以使用主机上的所有内存。
如果你想为容器中的所有进程限制内存,使用docker run命令的 -m开关即可。你可以使用bytes值定义它的值或是添加后缀(k,m或g)。
####3.1 示例:管理一个容器的内存分配
你可以像这样使用-m开关:
{{{ $ docker run -it --rm -m 128m fedora bash }}}
为了显示限制的实际情况,我将再次使用我的stress镜像。考虑一下的运行:
{{{ $ docker run -it --rm -m 128m stress --vm 1 --vm-bytes 128M --vm-hang 0 stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd }}}
stress工具将创建一个进程,并尝试分配128MB内存给它。它工作的很好,但是如果我们使用的比实际分配给容器的更多的内存会发生什么?
{{{ $ docker run -it --rm -m 128m stress --vm 1 --vm-bytes 200M --vm-hang 0 stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd }}}
它照样正常工作,是不是很奇怪?是的,我同意。
我们可以在 libcontainer源码找到解释(cgroups的Docker接口)。我们可以看到源码中默认的memory.memsw.limit_in_bytes值是被设置成我们指定的内存参数的两倍,当我们启动一个容器的时候。memory.memsw.limit_in_bytes参数表达了什么?它是memory和swap的总和。这意味着Docker将分配给容器-m内存值以及-mswap值。
当前的Docker接口不允许我们指定(或者是完全禁用它)多少的swap应该被使用,所以我们现在需要一起使用它。
有了以上信息,我们可以再次运行我们的示例。这次我们尝试分配超过我们分配的两倍内存。它将使用所有的内存和所有的 swap,然后玩完了。
{{{ $ docker run -it --rm -m 128m stress --vm 1 --vm-bytes 260M --vm-hang 0 stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [1] (415) <-- worker 6 got signal 9 stress: WARN: [1] (417) now reaping child worker processes stress: FAIL: [1] (421) kill error: No such process stress: FAIL: [1] (451) failed run completed in 5s }}}
如果你尝试再次分配比如 250MB(--vm-bytes 250M),它将会很好的工作。
警告:如果你不通过
-m开关限制内存,swap也被不会被限制。(这在技术上是不正确的; 这有限度, 但是它设置的值在我们当前运行的系统是不可达的。 例如在我的笔记本上 16GB 的内存值是 18446744073709551615,这是 ~18.5 exabytes…)
不限制内存将导致一个容器可以很容易使得整个系统不稳定的问题。因此请记住要一直使用-m参数。( 或者是使用MemoryLimit属性。)
####3.2 CGroups fs
你可以在/sys/fs/cgroup/memory/system.slice/docker-$FULL_CONTAINER_ID.scope/下面发现关于内存的所有信息,例如:
{{{ $ ls /sys/fs/cgroup/memory/system.slice/docker-48db72d492307799d8b3e37a48627af464d19895601f18a82702116b097e8396.scope/ cgroup.clone_children memory.memsw.failcnt cgroup.event_control memory.memsw.limit_in_bytes cgroup.procs memory.memsw.max_usage_in_bytes memory.failcnt memory.memsw.usage_in_bytes memory.force_empty memory.move_charge_at_immigrate memory.kmem.failcnt memory.numa_stat memory.kmem.limit_in_bytes memory.oom_control memory.kmem.max_usage_in_bytes memory.pressure_level memory.kmem.slabinfo memory.soft_limit_in_bytes memory.kmem.tcp.failcnt memory.stat memory.kmem.tcp.limit_in_bytes memory.swappiness memory.kmem.tcp.max_usage_in_bytes memory.usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.use_hierarchy memory.kmem.usage_in_bytes notify_on_release memory.limit_in_bytes tasks memory.max_usage_in_bytes }}}
注意:想了解关于这些文件的更多信息,请移步到 RHEL资源管理指南,内存篇。
###4. 块设备(磁盘) 对于块设备,我们可以考虑两种不同类型的限制:
- 读写速率
- 可写的空间 (定额)
第一个是非常容易实施的,但是第二个仍未解决。
注意:我假设你正在使用devicemapper storage作为Docker的后端。使用其他后端,任何事情都将不是确定的。
####4.1 限制读写速率
Docker没有提供任何的开关来定义我们可以多快的读或是写数据到块设备中。但是CGroups内建了。它甚至通过BlockIO*属性暴露给了systemd。
为了限制读写速率我们可以分别使用BlockIOReadBandwidth和BlockIOWriteBandwidth属性。
默认带宽是没有被限制的。这意味着一个容器可以使得硬盘”发热“,特别是它开始使用swap的时候。
####4.2 示例:限制写速率 让我测试没有执行限制的速率:
{{{ $ docker run -it --rm --name block-device-test fedora bash bash-4.2# time $(dd if=/dev/zero of=testfile0 bs=1000 count=100000 && sync) 100000+0 records in 100000+0 records out 100000000 bytes (100 MB) copied, 0.202718 s, 493 MB/s
real 0m3.838s user 0m0.018s sys 0m0.213s }}}
花费了 3.8秒来写入100MB数据,大概是26MB/s。让我们尝试限制一点磁盘的速率。
为了能调整容器可用的带宽,我们需要明确的知道容器挂载的文件系统在哪里。当你在容器里面执行mount命令的时候,你可以发现它,发现设备挂载在root文件系统:
{{{ $ mount /dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88 on / type ext4 (rw,relatime,context="system_u:object_r:svirt_sandbox_file_t:s0:c447,c990",discard,stripe=16,data=ordered) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) tmpfs on /dev type tmpfs (rw,nosuid,context="system_u:object_r:svirt_sandbox_file_t:s0:c447,c990",mode=755)
[SNIP]}}}
在我们的示例中是/dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88。
你也可以使用nsenter得到这个值,像这样:
{{{ $ sudo /usr/bin/nsenter --target $(docker inspect -f '{{ .State.Pid }}' $CONTAINER_ID) --mount --uts --ipc --net --pid mount | head -1 | awk '{ print $1 }' /dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88 }}}
现在我们可以改变BlockIOWriteBandwidth属性的值,像这样:
{{{ $ sudo systemctl set-property --runtime docker-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88.scope "BlockIOWriteBandwidth=/dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88 10M" }}}
这应该把磁盘的速率限制在10MB/s,让我们再次运行dd:
{{{ bash-4.2# time $(dd if=/dev/zero of=testfile0 bs=1000 count=100000 && sync) 100000+0 records in 100000+0 records out 100000000 bytes (100 MB) copied, 0.229776 s, 435 MB/s
real 0m10.428s user 0m0.012s sys 0m0.276s }}}
可以看到,它花费了10s来把100MB数据写入磁盘,因此这速率是 10MB/s。
注意:你可以使用
BlockIOReadBandwidth属性同样的限制你的读速率
####4.3 限制磁盘空间 正如我前面提到的,这是艰难的话题,默认你每个容器有10GB的空间,有时候它太大了,有时候不能满足我们所有的数据放在这里。不幸的是,为此我们什么都不能做。
我们能做的唯一的事情就是改变新容器的默认值,如果你认为一些其他的值(比如 5GB)更适合你的情况,你可以通过指定Docker daemon的 --storage-opt来实现,像这样:
{{{ docker -d --storage-opt dm.basesize=5G }}}
你可以调整一些其他的东西,但是请记住,这需要在后面重起你的Docker daemon,想了解更多的信息,请看这里(译注:这是Docker 1.2版本的README)。
####4.4 CGroups fs
你可以在/sys/fs/cgroup/blkio/system.slice/docker-$FULL_CONTAINER_ID.scope/目录下发现关于块设备的所有信息,例如:
{{{ $ ls /sys/fs/cgroup/blkio/system.slice/docker-48db72d492307799d8b3e37a48627af464d19895601f18a82702116b097e8396.scope/ blkio.io_merged blkio.sectors_recursive blkio.io_merged_recursive blkio.throttle.io_service_bytes blkio.io_queued blkio.throttle.io_serviced blkio.io_queued_recursive blkio.throttle.read_bps_device blkio.io_service_bytes blkio.throttle.read_iops_device blkio.io_service_bytes_recursive blkio.throttle.write_bps_device blkio.io_serviced blkio.throttle.write_iops_device blkio.io_serviced_recursive blkio.time blkio.io_service_time blkio.time_recursive blkio.io_service_time_recursive blkio.weight blkio.io_wait_time blkio.weight_device blkio.io_wait_time_recursive cgroup.clone_children blkio.leaf_weight cgroup.procs blkio.leaf_weight_device notify_on_release blkio.reset_stats tasks blkio.sectors }}}
注意:想了解关于这些文件的更多信息,请移步到 RHEL Resource Management Guide, blkio section。
###总结 正如你所看到的,Docker容器的资源管理是可行的。甚至非常简单。唯一的事情就是我们不能为磁盘使用设置一个定额,Docker开源项目里有一个的相关问题列表 -- 跟踪它并且评论。
希望你发现我的文章对你有用。Docker万岁!
原文链接:Resource management in Docker (翻译:叶可强)