1.1 临时节点方案
1.2 临时有序节点方案
1.3 读写锁
二、 Apache Curator
2.1 基本使用
2.2 源码解析
JDK 原生的锁可以让不同线程之间以互斥的方式来访问共享资源,但如果想要在不同进程之间以互斥的方式来访问共享资源,JDK 原生的锁就无能为力了。此时可以使用 Zookeeper 来实现分布式锁。具体分为以下两种方案:

临时节点方案的原理如下:
- 让多个进程(或线程)竞争性地去创建同一个临时节点,由于 ZooKeeper 不允许存在两个完全相同节点,因此必然只有一个进程能够抢先创建成功 ;
- 假设是进程 A 成功创建了节点,则它获得该分布式锁。此时其他进程需要在 parent_node 上注册监听,监听其下所有子节点的变化,并挂起当前线程;
- 当 parent_node 下有子节点发生变化时候,它会通知所有在其上注册了监听的进程。这些进程需要判断是否是对应的锁节点上的删除事件。如果是,则让挂起的线程继续执行,并尝试再次获取锁。
这里之所以使用临时节点是为了避免死锁:进程 A 正常执行完业务逻辑后,会主动地去删除该节点,释放锁。但如果进程 A 意外宕机了,由于声明的是临时节点,因此该节点也会被移除,进而避免死锁。
临时节点方案的实现比较简单,但是其缺点也比较明显:
- 缺点一:当 parent_node 下其他锁变动或者被删除时,进程 B,C,D 也会收到通知,但是显然它们并不关心其他锁的释放情况。如果 parent_node 下存在大量的锁,并且程序处于高并发状态下,则 ZooKeeper 集群就需要频繁地通知客户端,这会带来大量的网络开销;
- 缺点二:采用临时节点方案创建的锁是非公平的,也就是说在进程 A 释放锁后,进程 B,C,D 发起重试的顺序与其收到通知的时间有关,而与其第一次尝试获取锁的时间无关,即与等待时间的长短无关。
当程序并发量不高时,可以采用该方案来实现,因为其实现比较简单。而如果程序并发量很高,则需要采用下面的临时有序节点方案:
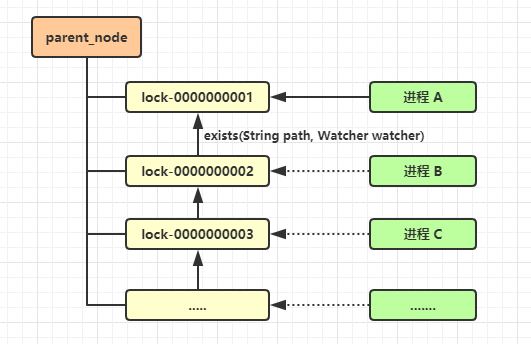
采用临时有序节点时,对应的流程如下:
- 每个进程(或线程)都会尝试在 parent_node 下创建临时有序节点,根据临时有序节点的特性,所有的进程都会创建成功;
- 然后每个进程需要获取当前 parent_node 下该锁的所有临时节点的信息,并判断自己是否是最小的一个节点,如果是,则代表获得该锁;
- 如果不是,则挂起当前线程。并对其前一个节点注册监听(这里可以通过 exists 方法传入需要触发 Watch 事件);
- 如上图所示,当进程 A 处理完成后,会触发进程 B 注册的 Watch 事件,此时进程 B 就知道自己获得了锁,从而可以将挂起的线程继续,并开始业务的处理。
这里需要注意的是一种特殊的情况,其过程如下:
- 如果进程 B 创建了临时节点,并且通过比较后知道自己不是最小的一个节点,但还没有注册监听;
- 而 A 进程此时恰好处理完成并删除了 01 节点;
- 接着进程 B 再调用 exist 方法注册监听就会抛出 IllegalArgumentException 异常。这虽然是一个异常,通常代表前一个节点已经不存在了。
在这种情况下进程 B 应该再次尝试获取锁,如果获取到锁,则就可以开始业务的处理。下文讲解 Apache Curator 源码时也会再次说明这一点。
通过上面对的介绍,可以看出来临时有序节点方案正好解决了临时节点方案的两个缺点:
- 每个临时有序节点只需要关心它的上一个节点,而不需要关心其他的额外节点和额外事件;
- 实现的锁是公平的,先到达的进程创建的临时有序节点的值越小,因此能更快地获得锁。
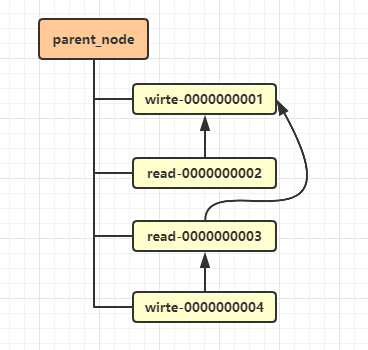
临时有序节点方案的另外一个优点是其能够实现共享锁,比如读写锁中的读锁。
如下图所示,可以将临时有序节点分为读锁节点和写锁节点:
- 对于读锁节点而言,其只需要关心前一个写锁节点的释放。如果前一个写锁释放了,则多个读锁节点对应的线程可以并发地读取数据;
- 对于写锁节点而言,其只需要关心前一个节点的释放,而不需要关心前一个节点是写锁节点还是读锁节点。因为为了保证有序性,写操作必须要等待前面的读操作或者写操作执行完成。
Apache Curator 是 ZooKeeper 的 Java 客户端,它基于临时有序节点方案实现了分布式锁、分布式读写锁等功能。使用前需要先导入 Apache Curator 和 ZooKeeper 相关的依赖,并保证 ZooKeeper 版本与服务器上 ZooKeeper 的版本一致:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
</dependency>基本使用如下:
RetryPolicy retryPolicy = new RetryNTimes(3, 5000);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.0.105:2181")
.sessionTimeoutMs(10000).retryPolicy(retryPolicy)
.namespace("mySpace").build();
client.start();
// 1. 创建分布式锁
InterProcessMutex lock = new InterProcessMutex(client, "/distributed/myLock");
// 2.尝试获取分布式锁
if (lock.acquire(10, TimeUnit.SECONDS)) {
try {
System.out.println("模拟业务耗时");
Thread.sleep(3 * 1000);
} finally {
// 3.释放锁
lock.release();
}
}
client.close();之后就可以启动多个程序进程来进行测试,此时 ZooKeeper 上的数据结构如下:

在我们指定的路径下,会依次创建多个临时有序节点,而当业务逻辑处理完成后,这些节点就会被移除。这里我们使用的是单机版本的 ZooKeeper ,而集群环境下也是一样,和 Redis 主从模式下的延迟复制会导致数据不一致的情况不同,ZooKeeper 集群各个节点上的数据一致性可以由其自身来进行保证。
Apache Curator 底层采用的是临时有序节点的实现方案,下面我们来看一下其源码中具体是如何实现的:
上面最核心的方法是获取锁的 acquire() 方法 ,其定义如下:
@Override
public boolean acquire(long time, TimeUnit unit) throws Exception{
return internalLock(time, unit);
}可以看到,它在内部调用了 internalLock() 方法,internalLock 方法的源码如下:
// threadData是一个线程安全的Map,其中Thread是持有锁的线程,LockData是锁数据
private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
private boolean internalLock(long time, TimeUnit unit) throws Exception{
Thread currentThread = Thread.currentThread();
// 首先查看threadData中是否已经有当前线程对应的锁
LockData lockData = threadData.get(currentThread);
if ( lockData != null ){
//如果锁已存在,则将其计数器加1,这一步是为了实现可重入锁
lockData.lockCount.incrementAndGet();
return true;
}
// 【核心方法:尝试获取锁】
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
// 如果获取到锁,则将其添加到threadData中
if ( lockPath != null ){
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
}
return false;
}上面真正去尝试获取锁的方法是 attemptLock():
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception{
final long startMillis = System.currentTimeMillis();
final Long millisToWait = (unit != null) ? unit.toMillis(time) : null;
final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
int retryCount = 0; // 重试次数
String ourPath = null;
boolean hasTheLock = false;
boolean isDone = false;
// 当出现NoNodeException异常时候依靠该循环进行重试
while ( !isDone ){
isDone = true;
try{
// 【核心方法:根据锁路径来创建对应的节点】
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
// 【核心方法:获取锁】
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
}
catch ( KeeperException.NoNodeException e ){
// 如果出现异常,并且还没有到达给ZooKeeper配置的最大重试时间或最大重试次数,则循环继续,并再次尝试获取锁
if ( client.getZookeeperClient().getRetryPolicy()
.allowRetry(retryCount++,System.currentTimeMillis() - startMillis,
RetryLoop.getDefaultRetrySleeper()) ){
isDone = false;
}else{
throw e;
}
}
}
// 如果获取到锁,则跳出循环,并返回锁的路径
if ( hasTheLock ){
return ourPath;
}
return null;
}这里两个核心的方法是 createsTheLock() 和 internalLockLoop() 。createsTheLock 的实现比较简单,就是根据我们指定的路径来创建临时节点有序节点:
@Override
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception{
String ourPath;
// 如果lockNodeBytes不为空,则创建一个含数据的临时有序节点
if ( lockNodeBytes != null ){
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().
withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, lockNodeBytes);
}else{
//否则则创建一个空的临时有序节点
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().
withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);
}
// 返回创建好的节点路径
return ourPath;
}这里返回的临时有序节点的路径会作为参数传递给 internalLockLoop() 方法。在文章开头介绍原理时,我们说过每个线程创建好临时有序节点后,还需要判断它所创建的临时有序节点是否是当前最小的节点,internalLockLoop() 方法主要做的就是这事:
private boolean internalLockLoop ( long startMillis, Long millisToWait, String ourPath) throws Exception {
// 是否持有锁
boolean haveTheLock = false;
boolean doDelete = false;
try {
if (revocable.get() != null) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
// 如果连接ZooKeeper客户端处于启动状态,也就是想要获取锁的进程仍然处于运行状态,并且还没有获取到锁,则循环继续
while ((client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock) {
// 对所当前所有的子节点按照从小到大进行排序
List<String> children = getSortedChildren();
// 将createsTheLock方法获得的临时有序节点的路径进行截取,只保留节点名的部分
String sequenceNodeName = ourPath.substring(basePath.length() + 1);
// 判断当前节点是否是最小的一个节点
PredicateResults predicateResults = driver.
getsTheLock(client, children, sequenceNodeName, maxLeases);
// 如果当前节点是最小的一个节点(排他锁情况),则此时就获得了锁
if (predicateResults.getsTheLock()) {
haveTheLock = true;
} else {
// 如果当前节点不是最小的一个节点,先拼接并获取前一个节点完整的路径
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized (this) {
try {
// 然后对前一个节点进行监听
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
// 如果设置了等待时间
if (millisToWait != null) {
// 将等待时间减去到目前为止所耗费的时间
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
// 如果等待时间小于0,则说明我们耗费的时间已经超过了等待时间,此时获取的锁无效,需要删除它
if (millisToWait <= 0) {
//设置删除标志位,并退出循环
doDelete = true;
break;
}
// 如果还有剩余时间,则在剩余时间内继续等待获取锁
wait(millisToWait);
} else {
// 如果没有设置等待时间,则持续等待获取锁
wait();
}
} catch (KeeperException.NoNodeException e) {
// 这个异常抛出时,代表对前一个节点设置监听时,前一个节点已经不存在(被释放),此时捕获该异常,
// 但不需要进行任何额外操作,因为循环会继续,就可以再次尝试获取锁
}
}
}
}
} catch (Exception e) {
ThreadUtils.checkInterrupted(e);
doDelete = true;
throw e;
} finally {
// 如果抛出了异常或者超时,则代表该进程创建的锁无效,需要将已创建的锁删除。以便后面的进程继续尝试创建锁
if (doDelete) {
deleteOurPath(ourPath);
}
}
return haveTheLock;
}这里对上面判断当前节点是否是持有锁的节点的 getsTheLock 方法进行一下说明:
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);和上文介绍的一样,判断当前节点是否是持有锁的节点,在不同锁类型(如读写锁和互斥锁)的判断是不同的,因此 getsTheLock 方法有着不同的实现。这里以StandardLockInternalsDriver 为例,它使用的是互斥锁的判断规则:即只要当前节点是最小的一个节点,就能持有锁:
public PredicateResults getsTheLock(CuratorFramework client, List<String> children,
String sequenceNodeName, int maxLeases) throws Exception {
// 获取当前节点在已经排好序的节点中的下标index
int ourIndex = children.indexOf(sequenceNodeName);
// 如果ourIndex小于0,则抛出NoNodeException的异常
validateOurIndex(sequenceNodeName, ourIndex);
// 如果ourIndex小于maxLeases(默认值是1),则代表它就是0,也就是从小到大排好序的集合中的第一个,也就是最小的一个
boolean getsTheLock = ourIndex < maxLeases;
// 如果是最小的一个,此时就已经获取到锁,不需要返回前一个节点的名称,否则需要返回前一个节点的名称,用于后续的监听操作
String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);
return new PredicateResults(pathToWatch, getsTheLock);
}这里解释一下 maxLease 这个参数的意义:默认值为 1,就是互斥锁;如果默认值大于 1,假设 maxLease 的值是 5,则最小的 5 个临时有序节点都可以认为是能持有锁的节点,此时最多可以有 5 个线程并发访问临界区, 在功能上类似于 Java 中Semaphore(信号量)机制 。
以上就是所有获取锁的源码解析,而释放锁的过程就比较简单了。release() 方法的源码如下:
public void release() throws Exception {
Thread currentThread = Thread.currentThread();
// 根据当前线程来获取锁信息
InterProcessMutex.LockData lockData = threadData.get(currentThread);
// 如果获取不到,则当前线程不是锁的持有者,此时抛出异常
if (lockData == null) {
throw new IllegalMonitorStateException("You do not own the lock: " + basePath);
}
// 因为Zookeeper实现的锁具有重入性,所以将其计数器减少1
int newLockCount = lockData.lockCount.decrementAndGet();
if (newLockCount > 0) {
return;
}
// 如果计数器的值小于0,代表解锁次数大于加锁次数,此时抛出异常
if (newLockCount < 0) {
throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);
}
try {
// 如果到达这一步,则说明计数器的值正好等于0,此时可以将节点真正的删除,释放锁
internals.releaseLock(lockData.lockPath);
} finally {
// 将锁信息从threadData移除
threadData.remove(currentThread);
}
}真正删除锁节点的方法存在于 releaseLock() 中,其源码如下:
final void releaseLock(String lockPath) throws Exception{
client.removeWatchers();
revocable.set(null);
deleteOurPath(lockPath); //删除ZooKeeper上对应的节点
}- 倪超 . 从 Paxos 到 Zookeeper——分布式一致性原理与实践 . 电子工业出版社 . 2015-02-01
- https://curator.apache.org/curator-recipes/index.html