1.1 InnoDB
1.2 MyISAM
1.3 MEMORY
1.4 CSV
1.5 ARCHIVE
1.6 MEGRE
二、索引
2.1 B+ tree 数据结构
2.2 B+ tree 索引
2.3 哈希索引
2.4 索引的优点
2.5 使用策略
三、锁
3.1 共享锁与排它锁
3.2 意向共享锁与意向排它锁
3.3 一致性读
3.4 锁的算法
四、事务
4.1 ACID 定义
4.2 事务的实现
4.3 并发问题
4.4 隔离级别
五、数据库设计范式
InnoDB 是 MySQL 5.5 之后默认的存储引擎,它具有高可靠、高性能的特点,主要具备以下优势:
- DML 操作完全遵循 ACID 模型,支持事务,支持崩溃恢复,能够极大地保护用户的数据安全;
- 支持多版本并发控制,它会保存数据的旧版本信息,从而可以支持并发和事务的回滚;
- 支持行级锁,支持类似 Oracle 的一致性读的特性,从而可以承受高并发地访问;
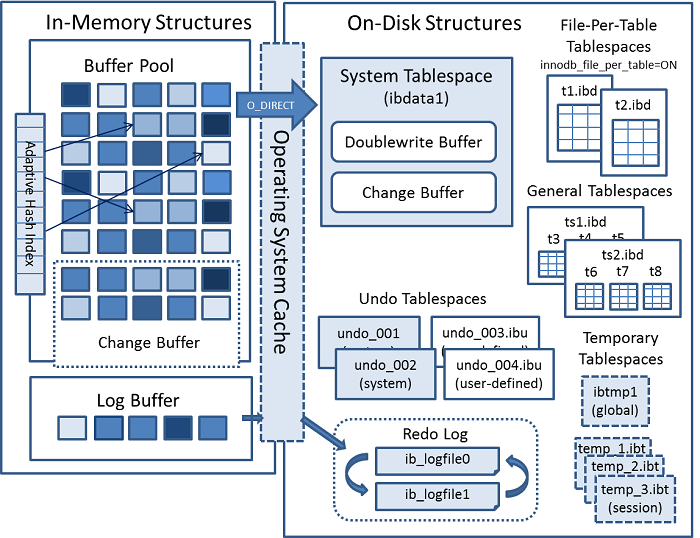
- InnoDB 组织数据时默认按照主键进行聚簇,从而可以提高主键查找的效率。对于频繁访问的数据,InnoDB 还会为其建立哈希索引,从而提高等值查询的效率,这也称为自适应哈希索引;
- InnoDB 基于磁盘进行存储,所有存储记录按 页 的方式进行管理。为弥补 CPU 速度与磁盘速度之间的鸿沟,InnoDB 引用缓存池 (Buffer Pool) 来提高数据的整体性能。查询时,会将目标页读入缓存中;修改时,会先修改缓冲池中的页,然后再遵循 CheckPoint 机制将页刷回磁盘。所有缓存页通过最近最少使用原则 ( LRU ) 来进行定期清理。
- InnoDB 支持两次写 (DoubleWrite) ,从而可以保证数据的安全,提高系统的可靠性。
一个 InnoDB 引擎完整的内存结构和磁盘结构如下图所示:
MyISAM 是 MySQL 5.5 之前默认的存储引擎。创建 MyISAM 表时会创建两个同名的文件:
- 扩展名为
.MYD(MYData):用于存储表数据; - 扩展名为
.MYI(MYIndex): 用于存储表的索引信息。
在 MySQL 8.0 之后,只会创建上述两个同名文件,因为 8.0 后表结构的定义存储在 MySQL 数据字典中,但在 MySQL 8.0 之前,还会存在一个扩展名为 .frm 的文件,用于存储表结构信息。MyISAM 与 InnoDB 主要的区别其只支持表级锁,不支持行级锁,不支持事务,不支持自动崩溃恢复,但可以使用内置的 mysqlcheck 和 myisamchk 工具来进行检查和修复。
MEMORY 存储引擎(又称为 HEAP 存储引擎)通常用于将表中的数据存储在内存中,它具有以下特征:
- MEMORY 表的表定义信息存储在 MySQL 数据字典中,而实际的数据则存储在内存空间中,并以块为单位进行划分;因此当服务器重启后,表本身并不会被删除,只是表中的所有数据都会丢失。
- MEMORY 存储引擎支持 HASH 索引和 BTREE 索引,默认采用 HASH 索引。
- MEMORY 表使用固定长度的行存储格式,即便是 VARCHAR 类型也会使用固定长度进行存储。
- MEMORY 支持 AUTO_INCREMENT 列,但不支持 BLOB 列或 TEXT 列。
- MEMORY 表和 MySQL 内部临时表的区别在于:两者默认都采用内存进行存储,但 MEMORY 表不受存储转换的影响,而内部临时表则会在达到阈值时自动转换为磁盘存储。
基于以上特性,MEMORY 表主要适合于存储临时数据 ,如会话状态、实时位置等信息。
CSV 存储引擎使用逗号分隔值的格式将数据存储在文本文件中。创建 CSV 表时会同时创建两个同名的文件:
- 一个扩展名为
csv,负责存储表的数据,其文件格式为纯文本,可以通过电子表格应用程序 (如 Microsoft Excel ) 进行修改,对应的修改操作也会直接反应在数据库表中。 - 另一个扩展名为
CSM,负责存储表的状态和表中存在的行数。
ARCHIVE 存储引擎默认采用 zlib 无损数据压缩算法进行数据压缩,能够利用极小的空间存储大量的数据。创建 ARCHIVE 表时,存储引擎会创建与表同名的 ARZ 文件,用于存储数据。它还具有以下特点:
- ARCHIVE 引擎支持 INSERT,REPLACE 和 SELECT,但不支持 DELETE 或 UPDATE。
- ARCHIVE 引擎支持 AUTO_INCREMENT 属性,并支持在其对应的列上建立索引,如果尝试在不具有 AUTO_INCREMENT 属性的列上建立索引,则会抛出异常。
- ARCHIVE 引擎不支持分区操作。
MERGE 存储引擎,也称为 MRG_MyISAM 引擎,是一组相同 MyISAM 表的集合。 ”相同” 表示所有表必须具有相同的列数据类型和索引信息。可以通过 UNION = (list-of-tables) 选项来创建 MERGE 表,如下:
mysql> CREATE TABLE t1 ( a INT NOT NULL AUTO_INCREMENT PRIMARY KEY, message CHAR(20)) ENGINE=MyISAM;
mysql> CREATE TABLE t2 ( a INT NOT NULL AUTO_INCREMENT PRIMARY KEY, message CHAR(20)) ENGINE=MyISAM;
mysql> INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');
mysql> INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');
mysql> CREATE TABLE total (a INT NOT NULL AUTO_INCREMENT,message CHAR(20), INDEX(a))
ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;创建表时可以通过 INSERT_METHOD 选项来控制 MERGE 表的插入:使用 FIRST 或 LAST 分别表示在第一个或最后一个基础表中进行插入;如果未指定 INSERT_METHOD 或者设置值为 NO ,则表示不允许在 MERGE 表上执行插入操作。MERGE 表支持 SELECT,DELETE,UPDATE 和 DELETE 语句,示例如下:
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
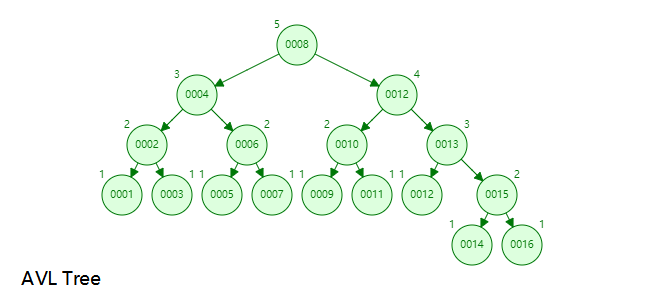
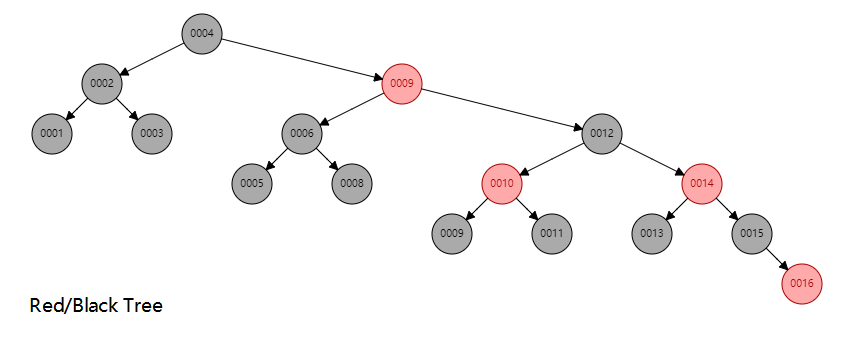
+---+---------+如果没有特殊说明,通常大多数数据库采用的索引都是 B+ tree 索引,它是基于 B+ tree 这种数据结构构建的。为什么采用 B+ tree 而不是平衡二叉树 (AVL) 或红黑树等数据结构?这里假设索引为 1-16 的自增数据,各类数据结构的表现如下:
平衡二叉树数据结构:
红黑树数据结构:
Btree 数据结构:

B+ Tree 数据结构
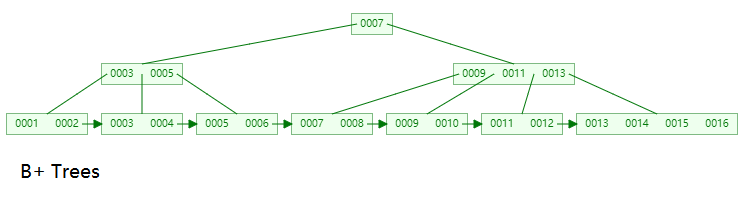
以上图片均通过数据结构可视化网站 Data Structure Visualizations 自动生成,感兴趣的小伙伴也可自行尝试。
从上面的图示中我们可以看出 B+ Tree 树具有以下优点:
- B+ Tree 树的所有非叶子节点 (如 003,007),都会在叶子节点冗余一份,所有叶子节点按照链表的方式进行组织,这样带来的好处是在范围查询中,只需要通过遍历叶子节点就可以获取到所有的索引信息。
- B+ Tree 的所有非叶子节点都可以存储多个数据值,存储量取决于节点的大小,在 MySQL 中每个节点的大小为 16K ,因此其具备更大的出度,即在相同的数据量下,其树的高度更低。
- 所有非叶子节点都只存储索引值,不存储实际的数据,只有叶子节点才会存储指针信息或数据信息。按照每个节点为 16K 的大小计算,对于千万级别的数据,其树的高度通常都在 3~6 左右 (取决于索引值的字节数),因此其查询性能非常优异。
- 叶子节点存储的数据取决于不同数据库的实现,对于 MySQL 来说,取决于使用的存储引擎和是否是主键索引。
对于 InnoDB ,因为主键索引是聚集索引,所以其叶子节点存储的就是实际的数据。而非主键索引存储的则是主键的值 :
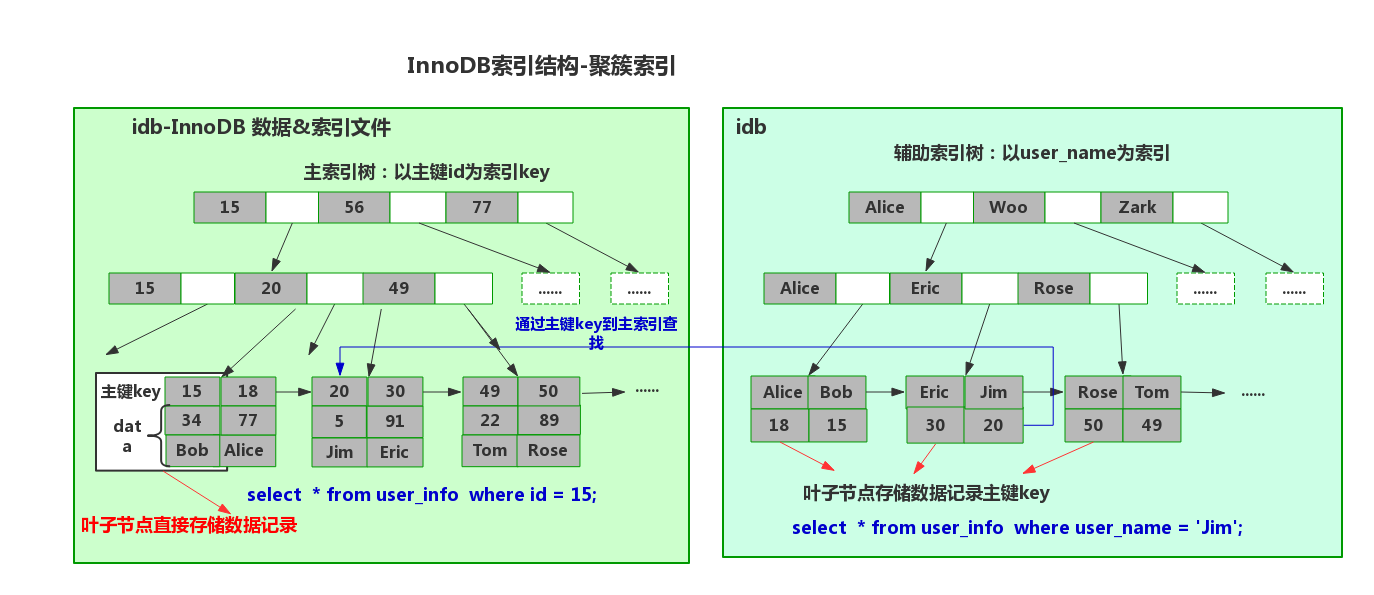

- 全值匹配:以索引为条件进行精确查找。如
emp_no字段为索引,查询条件为emp_no = 10008。 - 前缀匹配:以联合索引的前缀为查找条件。如
emp_no和dept_no为联合索引,查找条件为emp_no = 10008。 - 列前缀匹配:匹配索引列的值的开头部分。如
dept_no为索引,查询条件为dept_no like "d1%"。前缀匹配和列前缀匹配都是索引前缀性的体现,在某些时候也称为前缀索引。 - 匹配范围值:按照索引列匹配一定范围内的值。如
emp_no字段为索引,查询条件为emp_no > 10008。 - 只访问索引的查询:如
emp_no字段为索引,查询语句为select emp_no from employees,此时 emp_no 索引被称为本次查询的覆盖索引,即只需要从索引上就可以获取全部的查询信息,而不必访问实际表中的数据。 - 精确匹配某一列并范围匹配某一列:如
emp_no和dept_no为联合索引,查找条件为dept_no = "d004" and emp_no < 10020,这种情况下索引顺序可以是(emp_no, dept_no),也可以是(dept_no, emp_no),使用 EXPLAIN 来分析的话,其 TYPE 类型都是 range(使用索引进行范围扫描),但(dept_no, emp_no)性能更好。
使用哈希索引时,存储引擎会对索引列的值进行哈希运算,并将计算出的哈希值和指向该行数据的指针存储在索引中,因此它更适用于等值查询,而不是范围查询,同样也不能用于优化排序和分组等操作。在建立哈希索引时,需要选取选择性比较高的列,即列上的数据不容易重复 (如身份证号),这样可以尽量避免哈希冲突。因为哈希索引并不需要存储索引列的数据,所以其结构比较紧凑,对应的查询速度也比较快。
InnoDB 引擎有一个名为 “自适应哈希索引 (adaptive hash index)” 的功能,当某些索引值被频繁使用时,它会在内存中基于 B+ tree 索引再创建一个哈希索引,从而让 B-Tree 索引具备哈希索引快速查找的优点。
- 索引极大减少了服务器需要扫描的数据量;
- 索引可以帮助服务器避免排序和临时表;
- 索引可以将随机 IO 转换为顺序 IO。
- 在查询时,应该避免在索引列上使用函数或者表达式。
- 对于多列索引,应该按照使用频率由高到低的顺序建立联合索引。
- 尽量避免创建冗余的索引。如存在索引 (A,B),接着又创建了索引 A,因为索引 A 是索引 (A,B) 的前缀索引,从而出现冗余。
- 建立索引时,应该考虑查询时候的排序和分组的需求。只有当索引列的顺序和 ORDER BY 字句的顺序完全一致,并且遵循同样的升序或降序规则时候,MySQL 才会使用索引来对结果做排序。
InnoDB 存储引擎支持以下两种标准的行级锁:
- 共享锁 (S Lock,又称读锁) :允许加锁事务读取数据;
- 排它锁 (X Lock,又称写锁) :允许加锁事务删除或者修改数据。
排它锁和共享锁的兼容情况如下:
| X | X | |
|---|---|---|
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
为了说明意向锁的作用,这里先引入一个案例:假设事务 A 利用 S 锁锁住了表中的某一行,让其只能读不能写。之后事务 B 尝试申请整个表的写锁,如果事务 B 申请成功,那么理论上它就应该能修改表中的任意一行,这与事务 A 持有的行锁是冲突的。想要解决这个问题,数据库必须知道表中某一行已经被锁定,从而在事务 B 尝试申请整个表的写锁时阻塞它。想要知道表中某一行被锁定,可以对表的每一行进行遍历,这种方式可行但是性能比较差,所以 InnoDB 引入了意向锁。
- 意向共享锁 (IS Lock) :当前表中某行或者某几行数据存在共享锁;
- 意向排它锁 (LX Lock) :当前表中某行或者某几行数据存在排它锁。
按照意向锁的规则,当上面的事务 A 给表中的某一行加 S 锁时,会同时给表加上 IS 锁,之后事务 B 尝试获取表的 X 锁时,由于 X 锁与 IS 锁并不兼容,所以事务 B 会被阻塞。
| X | IX | S | IS | |
|---|---|---|---|---|
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
| IX | 不兼容 | 兼容 | 不兼容 | 兼容 |
| S | 不兼容 | 不兼容 | 兼容 | 兼容 |
| IS | 不兼容 | 兼容 | 兼容 | 兼容 |
1. 一致性非锁定读
一致非锁定读 (consistent nonlocking read) 是指在 InnoDB 存储引擎下,如果将要读取的行正在执行 DELETE 或 UPDATE 操作,此时不必去等待行上锁的释放,而是去读取 undo 日志上该行的快照数据,具体如下:
- 在 READ COMMITTED 事务隔离级别下,读取被锁定行的最新一份快照数据;
- 在 REPEATABLE READ 事务隔离级别下,读取事务开始时所处版本的数据。
基于多版本并发控制和一致性非锁定读,可以避免获取锁的等待,从而提高并发访问下的性能。
2. 一致性锁定读
一致性锁定读则允许用户按照自己的需求在进行 SELECT 操作时手动加锁,通常有以下两种方式:
- SELECT ... FOR SHARE:在读取行上加 S 锁;
- SELECT ... FOR UPDATE:在读取行上加 X 锁。
InnoDB 存储引擎支持以下三种锁的算法:
Record Lock:行锁,用于锁定单个行记录。示例如下:
-- 利用行锁可以防止其他事务更新或删除该行
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;Gap Lock:间隙锁,锁定一个范围,但不包括记录本身,主要用于解决幻读问题,示例如下:
-- 利用间隙锁可以阻止其他事务将值15插入列 t.c1
SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;Next-Key Lock:等价于 行锁+间隙锁,既锁定范围,也锁定记录本身。可以用于解决幻读中的 ”当前读“ 的问题。
InnoDB 存储引擎完全支持 ACID 模型:
1. 原子性(Atomicity)
事务是不可分割的最小工作单元,事务的所有操作要么全部提交成功,要么全部失败回滚,不存在部分成功的情况。
2. 一致性(Consistency)
数据库在事务执行前后都保持一致性状态,数据库的完整性没有被破坏。
3. 隔离性(Isolation)
允许多个并发事务同时对数据进行操作,但一个事务所做的修改在最终提交以前,对其它事务是不可见的。
4. 持久性(Durability)
一旦事务提交,则其所做的修改将会永远保存到数据库中。即使宕机等故障,也不会丢失。
数据库隔离性由上一部分介绍的锁来实现,而原子性、一致性、持久性都由 undo log 和 redo log 来实现。
- undo log:存储在 undo 表空间或全局临时表空间的 undo 日志段 (segment) 上,用于记录数据修改前的状态,主要用于帮助事务回滚以及实现 MVCC 功能 (如一致性非锁定读)。
- redo log:负责记录数据修改后的值,主要用于保证事务的持久化。
在并发环境下,数据的更改通常会产生下面四种问题:
1.丢失更新
一个事务的更新操作被另外一个事务的更新操作所覆盖,从而导致数据不一致:

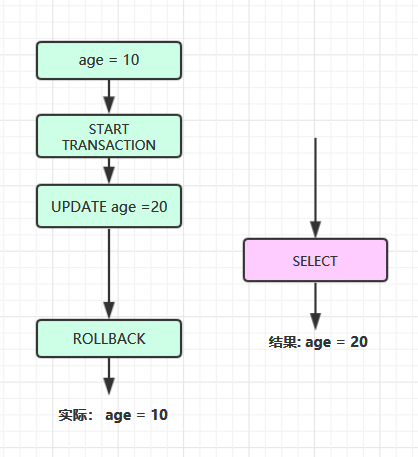
2. 脏读
在不同的事务下,一个事务读取到其他事务未提交的数据:
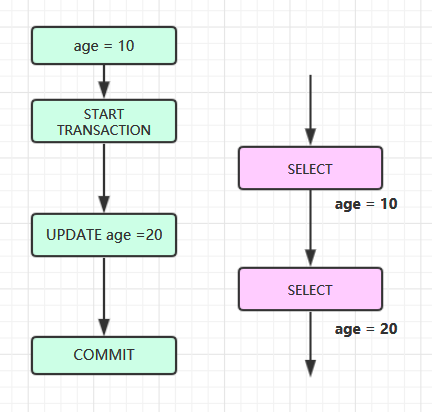
3. 不可重复读
在同一个事务的两次读取之间,由于其他事务对数据进行了修改,导致对同一条数据两次读到的结果不一致:
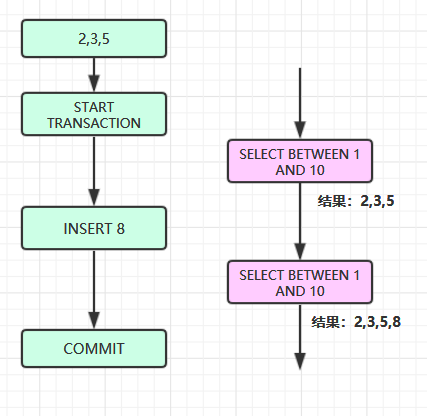
4.幻读
在同一个事务的两次读取之间,由于其他事务对数据进行了修改,导致第二次读取到第一次不存在数据,或第一次原本存在的数据,第二次却读取不到,就好像之前的读取是 “幻觉” 一样:
想要解决以上问题,可以通过设置隔离级别来实现:InnoDB 支持以下四个等级的隔离级别,默认隔离级别为可重复读:
- 读未提交:在此级别下,一个事务中的修改,即便没有提交,对其他事务也是可见的。
- 读已提交:在此级别下,一个事务中的修改只有已经提交的情况下,对其他事务才是可见的。
- 可重复读:保证在同一个事务中多次读取同样数据的结果是一样的。
- 串行化:所有事务强制串行执行,由于已经不存在并行,所以上述所有并发问题都不会出现。
在每个级别下,并发问题是否可能出现的情况如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(READ UNCOMMITTED) | 可能出现 | 可能 | 可能 |
| 读已提交(READ COMMITTED) | 不可能出现 | 可能 | 可能 |
| 可重复读(REPEATABLE READ) | 不可能 | 不可能 | 可能 |
| 串行化(SERIALIZABLE) | 不可能 | 不可能 | 不可能 |
就数据库层面而言,当前任何隔离级别下都不会发生丢失更新的问题,以 InnoDB 存储引擎为例,如果你想要更改表中某行数据,该行数据上必然会加上 X 锁,而对应的表上则会加上 IX 锁,其他任何事务都必须等待获取该锁才能进行修改操作。
数据库设计当中常用的三范式如下:
要求表中的每一列都是不可再细分的原子项。这是最低的范式要求,通常都能够被满足。
要求非主键列必须完全依赖于主键列,而不能存在部分依赖。示例如下:
| mechanism_id (组织机构代码) | employee_id (雇员编号) | ename (雇员名称) | mname (机构名称) |
|---|---|---|---|
| 28193182 | 10001 | heibaiying | XXXX公司 |
以上是一张全市在职人员统计表,主键为:机构编码 + 雇员编号。表中的雇员名称完全依赖于此联合主键,但机构名称却只依赖于机构编码,这就是部分依赖,因此违背了第二范式。此时常用的解决方式是建立一张组织机构与组织名称的字典表。
非主键列不能依赖于其他非主键列,如果其他非主键列又依赖于主键列,此时就出现了传递依赖。示例如下:
| employee_id (雇员编号) | ename (雇员名称) | dept_no (部门编号) | dname(部门名称) |
|---|---|---|---|
| 10001 | heibaiying | 06 | 开发部 |
以上是一张雇员表,雇员名称和所属的部门编号都依赖于主键 employee_id ,但部门名称却依赖于部门编号,此时就出现了非主键列依赖于其他非主键列,这就违背的第三范式。此时常用的解决方式是建立一张部门表用于维护部门相关的信息。
从上面的例子中我们也可以看出,想要完全遵循三范式设计,可能需要额外增加很多表来进行维护。所以在日常开发中,基于其他因素的综合考量,可能并不会完全遵循范式设计,甚至可能违反范式设计,这就是反范式设计。
- 官方文档:The InnoDB Storage Engine,Optimization and Indexes,InnoDB Locking and Transaction Model
- 姜承尧 . MySQL技术内幕:InnoDB存储引擎(第2版) . MySQL技术内幕 . 2013-05
- 施瓦茨 (Baron Schwartz) / 扎伊采夫 (Peter Zaitsev) / 特卡琴科 (Vadim Tkachenko) . 高性能mysql(第3版) . 电子工业出版社 . 2013-05-01
- InnoDB 数据页解析
- MySQL索引背后的数据结构及算法原理
- MYSQL-B+TREE索引原理
- Innodb中的事务隔离级别和锁的关系