1.1 核心组件
1.2 分片键
1.3 分片策略
1.4 块拆分
1.5 数据查询
1.6 非分片集合
二、集群搭建
2.1 分片副本集配置
2.2 配置副本集配置
2.3 路由服务配置
2.4 配置分发
2.5 启动分片和配置服务
2.6 初始化所有副本集
2.7 启动路由服务
2.8 测试分片
在单机环境下,高频率的查询会给服务器 CPU 和 I/O 带来巨大的负担,基于这个原因,MongoDB 提供了分片机制用于解决大数据集的分布式部署,从而提高系统的吞吐量。一个标准的 MongoDB 分片集群通常包含以下三类组件:
- shard :用于存储分片数据的 Mongod 服务器,为保证数据高可用,建议部署为副本集。
- config servers :配置服务器,它是整个集群的核心,用于存储集群的元数据和配置信息 (如分片服务器上存储了哪些数据块以及这些块的数据范围) 。从 MongoDB 3.4 开始,必须将配置服务器部署为副本集。
- mongos :查询服务的路由器,它是集群对外提供服务的门户。mongos 从配置服务器获取数据块的相关信息,并将客户端请求路由到对应的分片服务器上。

为了将集合中的不同文档分发到不同的数据块,MongoDB 需要用户指定分片键,之后基于选定的分片策略将数据拆分到不同的数据块。每个需要分片的集合只能有一个分片键:
- 对于非空集合进行分片时,分片键必须是该集合的索引或者前缀索引 (即索引必须以分片键开头)。
- 对于空集合,如果符合规则的索引不存在,则 MongoDB 将自动用分片键创建索引。
当前 MongoDB 4.x 支持两种分片策略:分别是散列分片和范围分片。
- 散列分片:对分片键进额行哈希散列然后分配到某个数据块;
- 范围分片:对分片键按照范围分配到某个数据块上。
散列分片有利于数据更加均匀的分布,但是在按照范围进行查询的场景下性能比较低 (如查询某个编号范围内的订单信息),因为按照这种分片规则相邻的数据通常不在同一个数据块上,此时需要在整个集群范围内进行广播和查询。
范围查询则反之,在范围查询的场景下性能比较好,但是数据可能出现分布不均匀的情况。假设分片键恰好是单调递增的,此时数据可能长期驻留在最后一个数据段,所以范围分片更适合于那些分片键长期稳定在某个区间范围内的数据,如年龄等。
需要特别注意的是分片键在选定后就无法修改,所以在选择分片键的时候应该要进行全面的考量。
无论采用何种分片策略,数据最终都被存储到对应范围的数据块 (chunk) 上,每个块默认的大小都是 64 M。由于数据源源不断的加入,当块超过指定大小时,就会进行块拆分。需要强调的是块拆分是一个轻量级的操作,因为在本质上并没有任何数据的移动,只是由 config servers 更新关于块的元数据信息。

当某个分片服务器上的数据过多时候,此时为了避免单服务器上 CPU 和 IO 操作的性能问题,就会发生块迁移,将块从一个分片迁移到另外一个分片,同时 config servers 也会更新相关块的元数据信息。 块迁移是由在后台运行的平衡器 (balancer) 所负责的,它在后台进行持续监控,如果最大和最小分片之间的块数量差异超过迁移阈值,平衡器则开始在群集中迁移块以确保数据的均匀分布。

块的大小是可以手动进行配置修改,但需要注意权衡利弊:
- 小块会导致频繁的数据拆分和迁移,从而致保证数据均匀的分布,但数据迁移会带来额外的网络开销,同时也会降低路由性能;
- 大块意味着更少的数据拆分和迁移,更少的网络开销,但会存在数据分布不均匀的风险。
这里需要注意块的迁移不会对查询造成任何影响,MongoDB 集群和 Redis 集群的查询原理不同。对于 Redis Cluster 而言,数据的散列规则同时也是查询时的路由规则。但是对于 MongoDB 分片集群而言,查询需要先经过 mongos ,mongos 会从 config servers 上获取块的位置信息和数据范围,然后按照这些信息进行匹配后再路由到正确的分片上。因此,从本质上而言 MongoDB 的分片策略和路由规则没有任何关系,假设按照分片策略将某文档分发到 Shard A 的 Chunk01 上,之后 Chunk01 迁移到 Shard B , 由于配置服务器会更新 Chunk01 块的位置信息,所以仍然能够正确路由到。
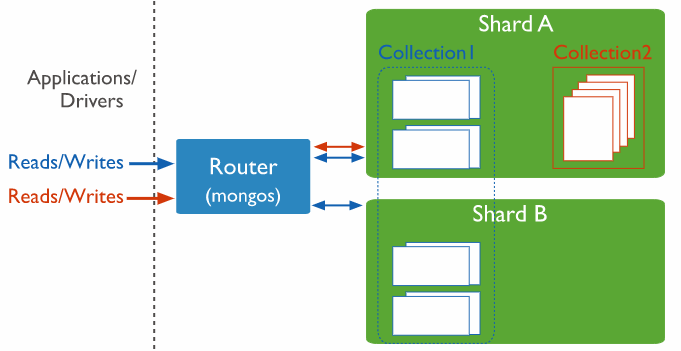
以上的所有讲解都是针对分片集合的,而在实际开发中并非每个集合都需要进行分片,MongoDB 允许在同一数据库下混合使用分片和非分片集合。每个数据库都有自己的主分片,所有非分片集合统一存储在主分片上。需要特别说明的是主分片和复本集中的主节点没有任何关系,在新数据库创建时程序会自动选择当前集群中最少数据量的分片作为主分片。如下图所示: Shard A 为主分片,集合 Collection1 是分片集合,而集合 Collection2 是非分片集合。

这里我只有三台服务器,为保证高可用,三台服务器上均部署 mongod 服务(每个服务器上使用不同端口部署两个 mongod 服务),形成两个分片副本集;同时三台服务器上均部署 config servers 服务,形成一个配置副本集:

第一个分片副本集的配置 mongod-27018.conf 如下:
processManagement:
# 以后台进程的方式启动
fork: true
systemLog:
destination: file
path: "/home/mongodb/log-27018/mongod.log"
logAppend: true
storage:
dbPath: "/home/mongodb/data-27018"
net:
# 分片服务的默认端口号为 27018
port: 27018
bindIp: 0.0.0.0
replication:
# 副本集的名称
replSetName: rs0
sharding:
# 在集群中的角色为分片
clusterRole: shardsvr第二个分片副本集的配置 mongod-37018.conf 如下:
processManagement:
fork: true
systemLog:
destination: file
path: "/home/mongodb/log-37018/mongod.log"
logAppend: true
storage:
dbPath: "/home/mongodb/data-37018"
net:
port: 37018
bindIp: 0.0.0.0
replication:
# 副本集的名称
replSetName: rs1
sharding:
# 在集群中的角色为分片
clusterRole: shardsvr新建副本集配置文件 mongo-config-server.conf ,内容如下:
processManagement:
fork: true
systemLog:
destination: file
path: "/home/mongodb/config-server-log/mongod.log"
logAppend: true
storage:
dbPath: "/home/mongodb/config-serve-data"
net:
# 配置服务的默认端口为27019
port: 27019
bindIp: 0.0.0.0
replication:
replSetName: configReplSet
sharding:
# 在集群中的角色为配置服务
clusterRole: configsvr新建 mongos 路由服务配置文件 mongos.conf ,内容如下:
processManagement:
fork: true
systemLog:
destination: file
path: "/home/mongodb/mongos-log/mongod.log"
logAppend: true
net:
# mongos服务默认的端口号为27017
port: 27017
bindIp: 0.0.0.0
sharding:
# 至少需要提供配置副本集中任意一个服务的地址
configDB: configReplSet/hadoop001:27019,hadoop002:27019,hadoop003:27019将以上所有配置分发到其他两台主机上:
scp mongod-27018.conf mongod-37018.conf mongo-config-server.conf mongos.conf root@hadoop002:/etc/
scp mongod-27018.conf mongod-37018.conf mongo-config-server.conf mongos.conf root@hadoop003:/etc/配置文件中所有用到的文件夹需要预先创建,否则无法正常启动服务,三台主机均执行以下命令:
mkdir -p /home/mongodb/log-27018
mkdir -p /home/mongodb/data-27018
mkdir -p /home/mongodb/log-37018
mkdir -p /home/mongodb/data-37018
mkdir -p /home/mongodb/config-server-log
mkdir -p /home/mongodb/config-serve-data
mkdir -p /home/mongodb/mongos-log分片在三台主机上执行以下命令,启动分片服务和配置服务:
mongod -f /etc/mongod-27018.conf
mongod -f /etc/mongod-37018.conf
mongod -f /etc/mongo-config-server.conf在任意一台主机上执行以下命令,初始化所有副本集:
初始化分片副本集rs0:
# 连接到
mongo 127.0.0.1:27018
# 初始化副本集rs01
rs.initiate( {
_id : "rs0",
members: [
{ _id: 0, host: "hadoop001:27018" },
{ _id: 1, host: "hadoop002:27018" },
{ _id: 2, host: "hadoop003:27018" }
]
})
# 退出
exit初始化分片副本集rs1,步骤同上,命令如下:
rs.initiate( {
_id : "rs1",
members: [
{ _id: 0, host: "hadoop001:37018" },
{ _id: 1, host: "hadoop002:37018" },
{ _id: 2, host: "hadoop003:37018" }
]
})初始化配置副本集configReplSet,步骤同上,命令如下:
rs.initiate( {
_id : "configReplSet",
members: [
{ _id: 0, host: "hadoop001:27019" },
{ _id: 1, host: "hadoop002:27019" },
{ _id: 2, host: "hadoop003:27019" }
]
})在任意一台主机或多台主机上启动路由服务。mongos 是没有副本集的概念的,所以如果你想启动多个路由服务,只需要在多台服务器上分别启动即可,启动命令如下:
mongos -f /etc/mongos.conf在 mongos.conf 文件中已经通过配置参数 sharding.configDB 配置了配置副本集的信息,所以路由服务已经能够感知到配置副本集,所以接下来只需要将分片副本集的信息传递给 mongos 即可,命令如下:
# 连接到mongos服务
mongo 127.0.0.1:27017
# 切换到管理员角色
use admin
# 添加分片副本集
db.runCommand({ addshard : "rs0/hadoop001:27018,hadoop002:27018,hadoop003:27018",name:"shard0"})
db.runCommand({ addshard : "rs1/hadoop001:37018,hadoop002:37018,hadoop003:37018",name:"shard1"})务必注意,在添加分片副本集之前一定要切换到管理员角色,否则后面的添加操作会返回 "ok" : 0 的失败状态码,同时会提示 addShard may only be run against the admin database. 添加成功后,可以使用 sh.status() 查看集群状态,此时输出如下,可以看到两个分片副本集已经被成功添加。

连接到 mongos ,对 testdb 数据库开启分片功能,同时设置集合 users 的分片键为用户 id,后面的 1 表示范围分片,如果想要采用哈希分片,则对应的写法为: {uid:"hashed"} 。
db.runCommand({ enablesharding : "testdb" })
db.runCommand({ shardcollection : "testdb.users",key : {uid:1} })切换到 testdb 数据库,为用户表创建索引,命令如下:
use testdb
db.users.createIndex({ uid:1 })使用以下命令插入部分数据,用于测试的数据量可以按自己服务器的性能进行修改:
var arr=[];
for(var i=0;i<3000000;i++){
arr.push({"uid":i,"name":"user"+i});
}
db.users.insertMany(arr);插入数据完成后,执行 sh.status() 命令可以查看分片情况,以及块的数据信息,部分输出如下:
