![]()
How to use: This pipeline was built using GCP tools, AI Platform pipelines to create the Kubeflow pipeline, AI Platform notebook to create the Jupyter notebook instances to set up and run the pipelines, and Cloud Storage to store the input data, pipeline generated meta-data and the models.
BERT from TF HUB
- Model: BERT base uncased (english)
- Data: IMDB movie review (5,000 samples)
- Pre-processing: Text trimming, Tokenizer (sequence length of 128, lower case)
- Training:
epochs: 3,batch size: 32,learning rate: 1e-5,loss: binary crossentropy.
Here is a brief introduction to each of the Python files.
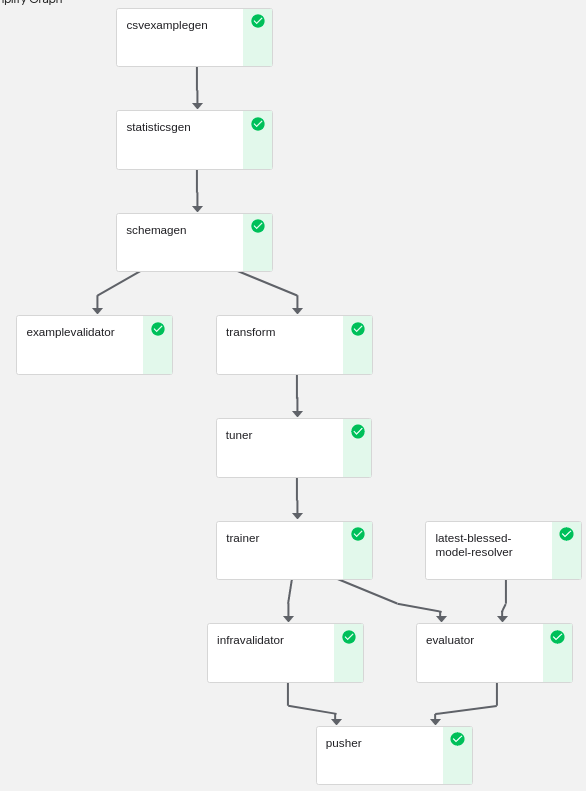
- pipeline - This directory contains the definition of the pipeline
- configs.py — defines common constants for pipeline runners
- pipeline.py — defines TFX components and a pipeline
- train_utils.py — defines train utility functions for the pipeline
- transform_utils.py — defines transform utility functions for the pipeline
- kubeflow_runner.py — define runners for Kubeflow orchestration engine
- For this Vertex AI version of the code, I could not train and deploy the BERT model, for some reason I was not able to configure the environment that runs the deployed pipeline, and that environment did not have some dependencies like
tensorflow-textthat was essential to use BERT, here I used was a LSTM model instead.
Kubeflow pipeline generated by this code