RDA Technical Guidelines
This Technical Guidelines document is a guide for RDA usage within a local application. It instructs developers on how to use RDA data available via the RDA Registry. The Technical Guidelines are intended for the use of technical users of the data, and explain the decisions that underlie the data and the structure of the RDA Registry.
RDA is based on the Functional Requirements for Bibliographic Records (FRBR) and Functional Requirements for Authority Data (FRAD) conceptual models. Those models include entities that are useful to identify and describe resources in order to support discovery and other tasks undertaken by a user. FRBR defines four user tasks:
Search: Search for a resource corresponding to stated criteria (i.e., to search either a single entity or a set of entities using an attribute or relationship ofthe entity as the search criteria).
Identify: Identify a resource (i.e., to confirm that the entity described or located corresponds to the entity sought or to distinguish between two or more entities with similar characteristics).
Select: Select a resource that is appropriate to the user’s needs (i.e., to choose an entity that meets the user’s requirements with respect to content, physical format, etc., or to reject an entity as being inappropriate to the user’s needs).
Obtain: Access a resource either physically or electronically through an online connection to a remote computer and/or acquire a resource through purchase, license, loan, etc.
Each RDA element is related to one or more user tasks.
FRBR was first published in 1998 (http://www.ifla.org/publications/functional-requirements-for-bibliographic-records) as a final report of a study group of the International Federation of Library Associations and Institutions (IFLA). It was first envisioned as an entity-relationship model, but has since been presented in an object-oriented model known as FRBRoo (http://www.cidoc-crm.org/frbr_inro.html). Although one might expect that in the internet age such a model based on traditional notions of ‘catalogs’ might be outdated and abandoned, it continues to be discussed, adapted and improved. Details of FRBRer classes and properties as well as review activities are available directly from the IFLA website (http://www.ifla.org/publications/functional-requirements-for-bibliographic-records) as well as in the Open Metadata Registry (http://metadataregistry.org/schema/show/id/5.html).
FRAD, an extension of the conceptual model of FRBR, was published in 2009. Details of FRAD classes and properties have also been made available in the Open Metadata Registry: http://metadataregistry.org/schema/show/id/24.html.
A third model cited as a basis for RDA is the Dublin Core Abstract Model (DCAM), originally published by the Dublin Core Metadata Initiative (DCMI) in 2007 (http://dublincore.org/documents/abstract-model/). DCMI, recognizing changes in the metadata environment since the publication of the Resource Description Framework (RDF) by the World Wide Web Consortium (W3C), is in the process of reviewing the DCAM.
Further information on these three models is available in the References section at the end of this document.
Possibly the most important shift in bibliographic approaches that RDA represents is the focus on relationships. RDA is currently focused on seven entities, falling into two groups: Work/Expression/Manifestation/Item (WEMI) for describing and identifying resources; and Person/Family/Corporate body (PFC) for describing and identifying the agents responsible for various aspects of resources. The entities are defined and distinct and RDA assigns separate sets of attributes to them.
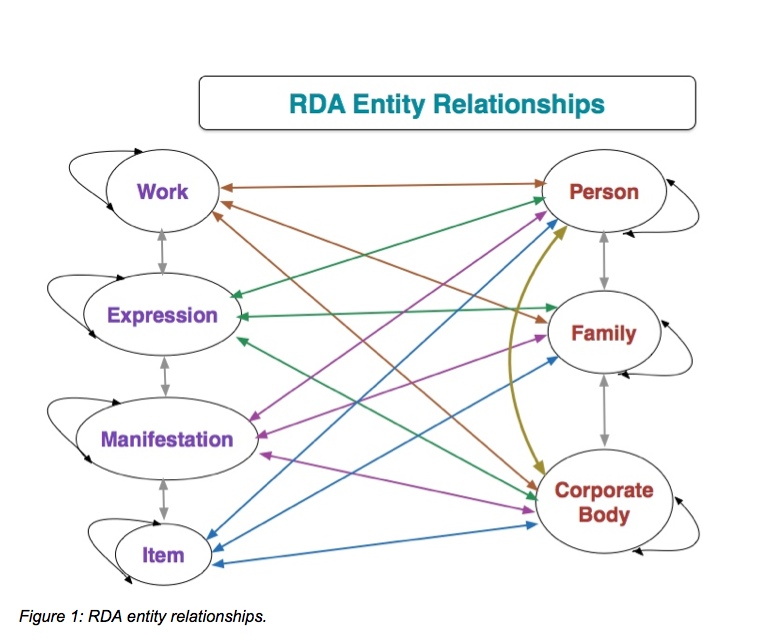
Because several aspects of FRBR were in flux at the time the RDA standard vocabularies were near completion, RDA defined some of the FRBR entities for itself, including Agent as the super-entity for the FRAD group. The classes and properties for “FRBR in RDA” are available in the Open Metadata Registry (http://metadataregistry.org/schema/show/id/14.html).
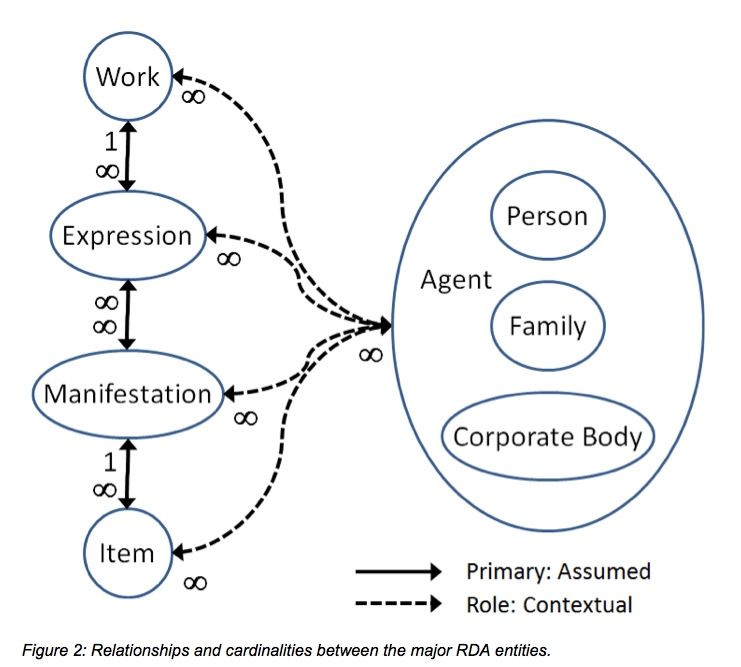
The entities in the WEMI group are inter-locked when used to describe a single resource.
- An Expression must express one and only one Work
- A Manifestation must realize at least one Expression
- An Item must exemplify one and only one Manifestation
The entities in the PFC group have a different relationship. They have a common Agent super-entity but each entity includes attributes to describe a particular kind of agent. RDA provides primary or high-level relationships between the entities in the WEMI group, and between WEMI entities and Agent entities. These relationships are represented as reciprocal pairs for separate directions to and from each entity.
The primary relationship cardinality is usually shown (as in the FRBR report, etc.) as a single-headed arrow for “one” and a double-headed arrow for “many”. The diagram above replaces that convention with “one” and the “infinity” symbol, equally acceptable and understood. The strict cardinality of “one and only one” is shown by using the full line: these relationships are primary and assumed by any application of the model (and resulting data).
In addition to the WEMI and PFC entities, RDA refines the high-level FR Family relationships with a rich set of relationship designators between the separate entities. RDA also provides designators for relating individual WEMI entities from different resources, for instance relationships between separate works. Designators for relating individual Agent entities enable authority control and navigation, ideally using URIs rather than text strings.
##Use of the Open Metadata Registry with GitHub
In early 2014, the newly published RDA namespace (http://RDARegistry.info) went live, incorporating an updated view of the RDA element sets, new services, and a platform to continue development of the automation routines and documentation. Currently, the RDA Registry vocabularies are maintained using a combination of Git, GitHub, and the Open Metadata Registry (OMR). The vocabularies are edited and maintained in the OMR, which generates an RDF Schema, serialized in several flavours of RDF:
- RDF/XML (application/rdf+xml),
- Turtle (text/turtle),
- Notation 3 (text/rdf+n3),
- N-Triples (text/rdf+nt),
- JSON-LD (application/json+ld),
- RDF/JSON (application/rdf+json).
Git is relied on for versioning of the element set vocabularies as a single ‘collection’. The various serializations, once they are generated, are committed to a local Git repository and then pushed to the ‘master’ branch of a public repository on GitHub. Pushing an update to the master branch of the GitHub repository triggers an immediate update of the vocabularies on a dedicated server at rdaregistry.info. Requests by machines for any of the flavours of RDF from this server are evaluated using content negotiation and served as data. Requests for HTML will be redirected to www.rdaregistry.info, which is hosted on GitHub using GitHub Pages. These pages, based on a template and directly accessing the vocabularies hosted at rdaregistry.info, provide humans with the opportunity to browse and search the latest version of individual vocabularies.
GitHub also provides a place to raise and discuss issues related to both the technical and semantic aspects of the vocabularies, as well as providing the ability to access and download every previously published version of the vocabularies in the rdaregistry.info namespace.
###Versioning
When systems are consuming published linked data on the web that references, rather than embeds, the vocabularies that provide the semantics on which the data depends, those vocabulary references are as subject to link rot and volatility as any other data on the web. The challenge for decades with public, shared infrastructure, whether it's vocabularies or services, has been a choice between system stability and system flexibility. The open source community has begun to embrace the flexibility and agility of a highly volatile development ecosystem and developers are designing systems that favour this approach over the relatively static approach of infrequent and carefully vetted releases.
A commitment to guaranteeing backward compatibility within certain version ranges provides the ability for vocabulary consumers to specify usage of a particular intermediate (not simply major) version or a range of intermediate versions. If producers commit to following semantic versioning guidelines, and make all versions available to consuming systems, then the data that references these vocabularies can be trusted to be semantically consistent. This allows producers and consumers to update vocabularies frequently to correct bugs and expand the vocabulary (usually) without fear.
Changes to the vocabularies published via the OMR to GitHub always result in a new version, however minor, being assigned to the vocabularies as a group. The version designations follow the general principles of Semantic Versioning, resulting in a 3-tier numbering system:
- A change that has no effect on the semantics of any Element will result in a 'patch' version that will increment the third segment of the number: "1.1.X"
- A change that affects the semantics of any property of any Element will result in a 'minor' version that will increment the second segment "1.X.0", and reset the third segment to 0
- A change that breaks backwards semantic compatibility will result in a 'major' version change that increments the first segment "X.0.0", and resets the other segments to 0. We expect major versions to be extremely rare.
For additional information on versioning, see: Versioning Vocabularies in a Linked Data World by Diane Hillmann, Jon Phipps, and, Gordon Dunsire. Presented at the IFLA 2014 Satellite meeting, Paris, France, Aug. 2014
###Releases
Every time a release is pushed to GitHub, it is 'tagged' with the version number of the release. GitHub recognizes any tag as a release and takes a snapshot of the state of the entire repository at the point in time that the tag was applied. GitHub then creates downloadable zip and tar files for that snapshot. It also makes it possible to reference the snapshot with a specific URI.
The master branch of the repository will always contain the latest version, which will always have a release tag. The current version can also be referenced by checking the contents of the version file in the root directory of the repository. When appropriate, a list of the changes will be added to the release. The list of releases, along with the downloadable files and reference URLs, is available: https://github.com/RDARegistry/RDA-Vocabularies/releases
Detailed history information on changes to individual statements of the vocabularies (what, when and who) continues to be maintained within the OMR, and those changes continue to be viewable on the OMR site for each vocabulary and via the OMR change feeds.
###Organization of the vocabularies in the RDA Registry
The RDA Registry (http://www.rdaregistry.info/) provides extensively rearranged and updated element sets to reflect recent decisions by the Joint Steering Committee for the Development of RDA (JSC).
The published vocabularies are made available as a group of related Element Sets which reflect the underlying FRBR conceptual model.
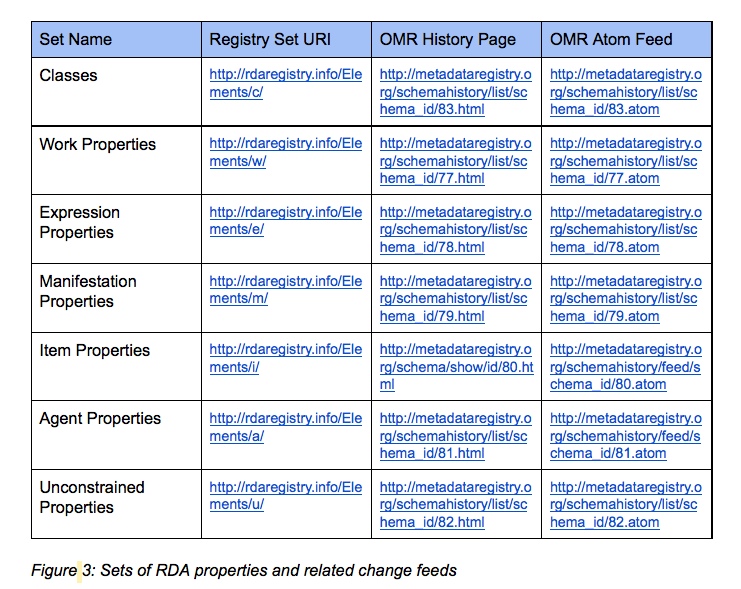
RDA element sets include:
- a set of classes representing the RDA entities Work, Expression, Manifestation, Item (WEMI), Person, Family, and Corporate Body (PFC), taken from FRBR and FRAD.
- a set for each RDA WEMI entity Work properties, Expression properties, Manifestation properties, and Item properties representing the RDA elements for their attributes and relationships.
- a set for the RDA super-entity Agent properties including the RDA entities Person, Family, Corporate Body, representing the RDA elements for their attributes and relationships.
- a set of unconstrained properties without links to the RDA entities for use by non-FRBR applications, representing generalized RDA elements for attributes and relationships. These ‘unconstrained’ elements are in a separate set, but they have the same internal relationships as the elements in the ‘constrained’ sets.
The draft version of the RDA elements available at http://rdvocab.info were never officially published, so those elements are now deprecated, with users and applications redirected to the current official versions at http://www.rdaregistry.info. A Map from deprecated to published RDA properties contains redirections for the most popular properties that have been deprecated; a Map from deprecated to published RDA classes contains redirections for all of the classes that have been deprecated.
The RDA Value Vocabularies designed to be used with the elements are still available at http://rdvocab.info. Some of these are published (and thus usable), but most are not, and decisions about whether and/or how to move them to the RDA Registry are still pending. Whatever the decision, appropriate redirection will be supplied so that those using the currently published Value Vocabularies will not be left behind.
###Technical notifications and documentation
The OMR user interface is used as the starting point for maintenance changes and entry of new data for the RDA Registry. As new data is published in the OMR, it becomes available for transfer to the RDA Registry project site on GitHub using standard GitHub protocols as described above. At present, the process of invoking the commit status and moving changes into the RDA Registry is a manual one, and the decision to push data from the OMR to the RDA Registry made by the JSC Chair and the RDA Registry developer.
Based on the extent of changes, a decision is made at that time what the version increment should be (http://www.rdaregistry.info/rgAbout/versions.html), thus signaling to developers monitoring the changelog that they may have to update their local files. As these changes move to the RDA Registry itself, automated processes update the download files for each set of elements and each individual type of file.
Developers and others interested in changes to the RDA element sets have available notification feeds from either the OMR or the RDA Registry on GitHub. The table above provides quick element set level access to all all feeds from the OMR, which automatically tracks all changes to the vocabularies, however minor, at the individual statement level. This makes for a highly granular and detailed feed. The RDA Registry feed on the other hand, tracks only published commits to the master branch of the vocabularies, and can be used to receive notification of new published versions.
As new or updated processes are introduced the automated public documentation is updated and announced to a number of outlets, with more general announcements available on a soon-to-be announced blog, as well as RDA-L.
###How to flag issues and/or contact us with questions
The project maintains a FAQ (http://www.rdaregistry.info/rgFAQ) which will be expanded as questions come in and can be answered usefully using that format. Depending on the type of question or concern, there are various options for contact:
- JSC: Gordon Dunsire ([email protected])
- MMA: Diane Hillmann ([email protected])
- OMR technical issues: Jon Phipps ([email protected])
- ALA Digital Reference: James Hennelly ([email protected])
The GitHub Issues page: https://github.com/RDARegistry/RDA-Vocabularies/issues is probably the best option for technical issues that require time to investigate and correct because it tracks issues over time and allows contact between questioner and responder to be public.
##Technical features of the RDA Vocabularies
Among the important goals of the evolving RDA Registry is to build an infrastructure that can grow not only in English, but in other languages used in countries adopting RDA. To support that objective, the RDA Registry design illustrates some decisions that reflect commitment to those objectives, but are quite different than choices made by other evolving standards. Some specific aspects can be seen in the image below:
Use of Slash URIs
The RDA Registry uses slash URIs to enable download of individual properties/classes instead of the entire schema download required by hash URIs. Download of the entire set of ontologies, by set or in its entirety, is provided by GitHub as .zip or .tar files.
Use of HTTP URIs
The RDA Registry uses HTTP URIs to enable easy resolution of the URIs without the necessity to maintain a separate resolution service. HTTP URIs also support public/global reuse and mapping of RDA vocabularies with a variety of other vocabularies.
Verbalized Labels
The publication of the RDA Registry introduced ‘verbalized’ labels and reciprocal properties. They are created by applying a mechanical device to render RDA labels and definitions as directional verbs, in order to clarify their semantics, specifically the direction of a relationship property, and to create labels and definitions for versions of the properties unconstrained by the Functional Requirements for Bibliographic Records (FRBR) and Functional Requirements for Authority Data (FRAD). The methodology, as applied to relationship designator elements, is discussed in RDF representation of RDA relationship designators: a follow-up discussion paper and its appendices. Since the automated changes, efforts have been made to minimize and correct the occasional oddly phrased results as well as to improve the clarity and consistency of the original element labels. Questions or concerns about current labels should be forwarded using the GitHub Issues Page (https://github.com/RDARegistry/RDA-Vocabularies/issues)
Lexical aliases
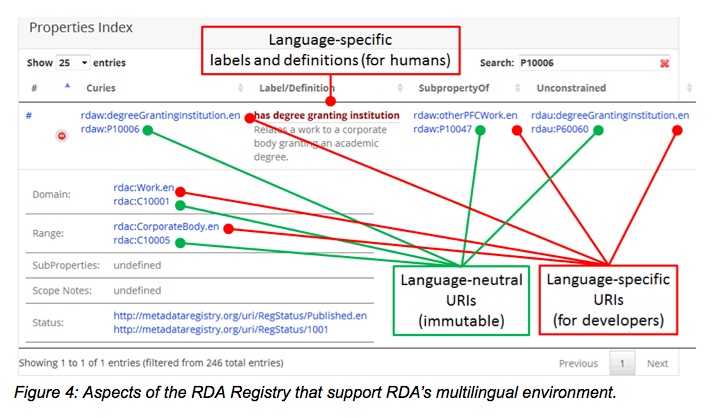
The decision was made to use numeric rather than ‘readable’ URIs for the element sets. This decision reflects the international environment of RDA and its translations. There are significant problems associated with using transparent, human-readable URIs as a mnemonic device, especially when the properties and values of bibliographic display labels such as RDA’s relationship designators are still under active development. The ‘canonical’ URIs in the RDA Registry are ‘opaque’:
These URIs are intended to support multilingual and multicultural descriptive environments and their alignment. Each canonical URI maybe be represented in data by any number of language-specific ‘lexical aliases’ intended to be readable by humans in each language represented:
The lexical aliases, derived from the label in each language, always resolve for machines using a permanent redirect to the canonical opaque identifier. This strategy also allows minor, non-semantic changes in the labels to be reflected in the lexical aliases without requiring a new canonical URI to be created. Non-cosmetic changes to definitions will result in a new canonical URI.
###RDA constrained and unconstrained properties and their relationship
A major goal of RDA from the beginning was to be usable by non-library applications. That important point suggests that one way to look at the relationship between the RDA constrained and unconstrained properties is to think of the unconstrained set as basic RDA--usable by anyone--and the constrained set as an Application Profile (not yet fully documented), containing the additional information required to use RDA in a FRBR-based bibliographic metadata environment.
To enable such a broad array of uses, the unconstrained set of properties does not assume the use of the RDA Data Model, based on FRBR and FRAD. Both sets have similar semantics (definitions), but the constrained set includes additional information:
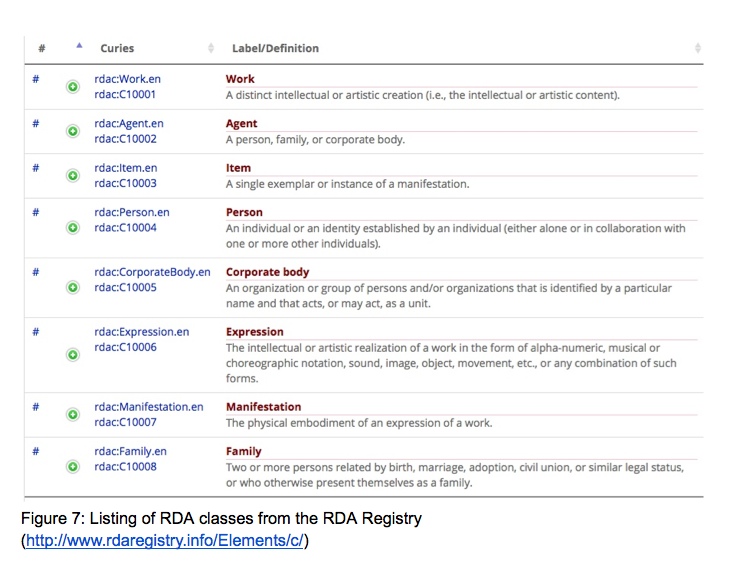
For RDA the domain is expressed using the classes defined for RDA at http://www.rdaregistry.info/Elements/c/. These include the four WEMI classes (Work, Expression, Manifestation and Item), plus Agent and the FRAD classes (Person, Corporate Body and Family).
The range defines the specific set to which the value belongs (ex. Work) and the context in which it must be understood. Any statement that associates a constrained RDA descriptive element (a ‘subject’ in RDF terms) with a resource (an ‘object’ in RDF) must adhere to the requirements expressed by Domain and Range assigned.
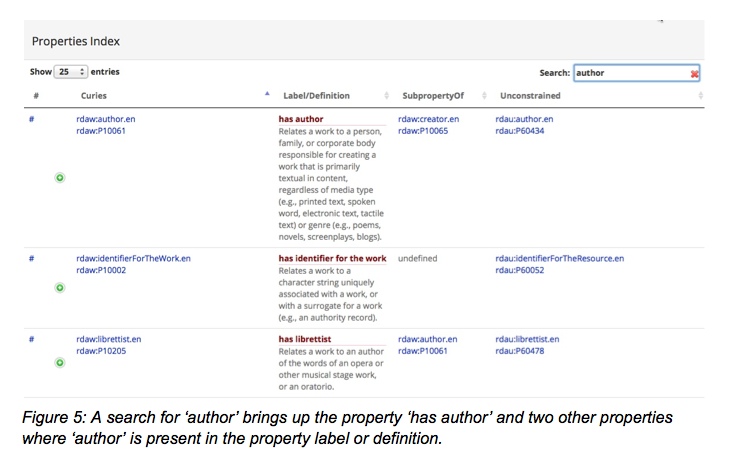
Note that there is no display on the page above for domain or range for ‘has author’, but the textual definition contains the information:
“Relates a work to a person, family, or corporate body responsible for creating a work that is primarily textual in content, regardless of media type (e.g., printed text, spoken word, electronic text, tactile text) or genre (e.g., poems, novels, screenplays, blogs).”
In the representation below, work is the domain, person, family, or corporate body is the range. The HTML page seen in Fig. 1 assumes that the user is human, and thus can read the definition. However, the technical version of this page provides information intended for machines, which does not assume human interpretations.

The domain in the illustration above refers to C10001, which is the identifier for Work; the range refers to C10002, the class of Agent, which includes Person, Corporate Body and Family.
For more information on the uses of unconstrained properties, see the sections on Mapping [link] and Extension and refinement [link].
##Usage, interpretation and inference
Developers using RDA need to understand the ramifications of these constraints and how basic inference works in this context. The RDA model constraints were developed to make use of RDF inference rules and semantic reasoning in a bibliographic description based on RDF where statements are necessarily terse and built up from the simple “subject--predicate--object” triples to support logical conclusions not explicitly in the data.
As an example, the RDA Registry includes the following information for the constrained property “has preferred title for the work”:
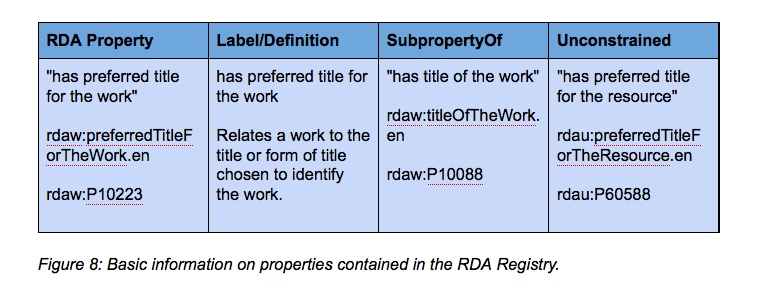
The use of the domain of rda:Work in the constrained property limits its use to the top level of the WEMI stack, while the unconstrained property does not. When the constrained property is used in the context of the RDA model, it defines a ‘preferred title’ as an attribute of an rda:Work, which is defined as “A distinct intellectual or artistic creation (i.e., the intellectual or artistic content)”. However, the unconstrained version states its context quite differently, substituting the more general ‘resource’ for the more specific ‘Work’ of the RDA constrained property, and does not apply the ‘preferred title’ attribute to any particular class of ‘thing’. In the RDF world “Resources can be anything, including documents, people, physical objects, and abstract concepts.” (http://www.w3.org/TR/2014/NOTE-rdf11-primer-20140624/). Thus from the more specific notion of ‘work’ to the more general ‘any thing’, a very important shift is evident between constrained and unconstrained properties.
Unconstrained properties are essential when mapping constrained properties in non-RDA domains to unconstrained RDA properties. Since the domain of an unconstrained property is the class of all things, any property constrained by any domain can be defined as a subproperty (or some other relationship such as owl:equivalentProperty) of an unconstrained RDA property, whereas creating such a relationship with a constrained RDA property would infer that the ‘thing’ being described is a member of both constraining domains (sets/classes), which is usually neither accurate nor logical (although it can be).
###RDA Records?
One of the most significant differences between RDA and traditional notions of records is the fact that RDA itself does not favor any specific "record" schema. An ‘RDA Record’ is an aggregation of one or more sets of RDF statements, and has many possible boundaries, not just one.
For instance, is an RDA record only the information contained in the WEMI stack, or should information for each WEMI entity need to stand on its own? Should a ‘record’ encompass related PFC information as well, or just the links to those entities? Depending on what function the record aggregation is intending to serve, whether it’s sharing with another party or being the basis of a display, the answer might be different.
Because each of the entities has an identifier, the links to other entities (shown above in Figure 1: RDA Entity Relationships) may be included or not included in defined distributions, regardless whether the distribution boundaries are defined by the data provider or a specific downstream user. For instance, a consumer of an RDA aggregation requiring all the data a provider has available might wish a distribution that includes not just the links to all the agents related to the aggregation (and their roles), but the specific data about those agents: birth/death dates, pseudonyms, titles of other resources, etc.
###Using RDA with other schemas
RDA exists in a multiple schema world, not in a silo. Taking advantage of the potential of this more complex environment requires a very different mindset than that of the traditional library world, including some new skills and ways of looking at the challenges of relating schemas.
Mapping is essential to this new environment, in ways very different than the crosswalking used extensively in the traditional environment. Crosswalks work reasonably well in a closed world where the focus is on schema to schema transformations, where the ‘maps’ created were essentially documents intended for use in particular applications. [see Dunsire article in ‘Resources’ for more on these issues]
Any discussion on mapping must necessarily be based on an understanding of [unconstrained and constrained properties](#constrained and unconstrained), [domains and ranges](#Domain and Range).
##Basic mapping guidelines and examples: subproperty relationships
Traditional ‘Format-to-Format’ crosswalks generally designed for use within specific applications, give us a very limited view of the potential of mapping, essentially operating as a reductive process that dilutes the power of semantics by substitution. Within the semantic web context, a map is essentially two or more RDF elements (classes, properties, concepts) linked with an ontological property (RDFS, OWL, etc.). Mapping requires careful analysis of how properties and classes in existing schemas are defined and contextualized, and relationships must be defined without the ‘if/then’ notions that live within most crosswalks.
The map example below is defined as a ‘bottom-up’ map, starting from a very specific term and rising to seek the most general concept, in this case the Dublin Core contributor element. In this image, relationships that are not currently formally available show as a dotted line.
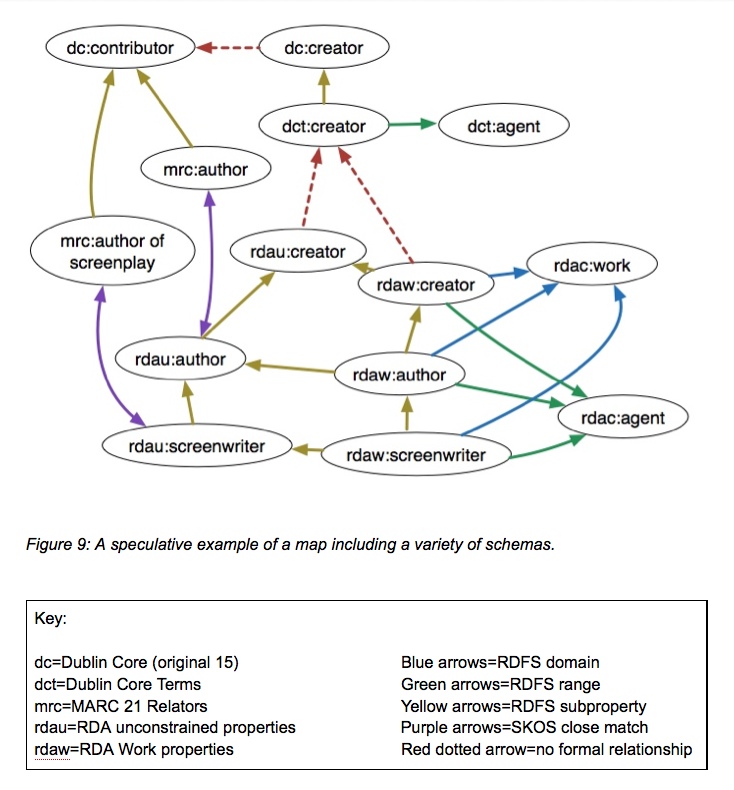
Some of the relationships shown above might be expressed as triples (shown here in plain text):
- rdaw:screenwriter rdfs:subPropertyOf rdaw:author
- rdaw:author rdfs:subPropertyOf rdaw:creator
- rdaw:creator rdfs:range rdac:agent
- rdaw:author rdfs:range rdac:agent,
or, using canonical URIs:
- rdaw:P10203 rdfs:subPropertyOf rdaw:P10061
- rdaw:P10061 rdfs:subPropertyOf rdaw:P10065
- rdaw:P10065 rdfs:range rdac:C10002
- rdaw:P10061 rdfs:range rdac:C10002
Viewing the same map from the top-down, it’s clear that there is a gap in the general DC properties in that dc:creator is not explicitly defined as a subproperty of dc:contributor, although it’s clear from the definitions of those two properties that dc:creator is a refinement of dc:contributor.
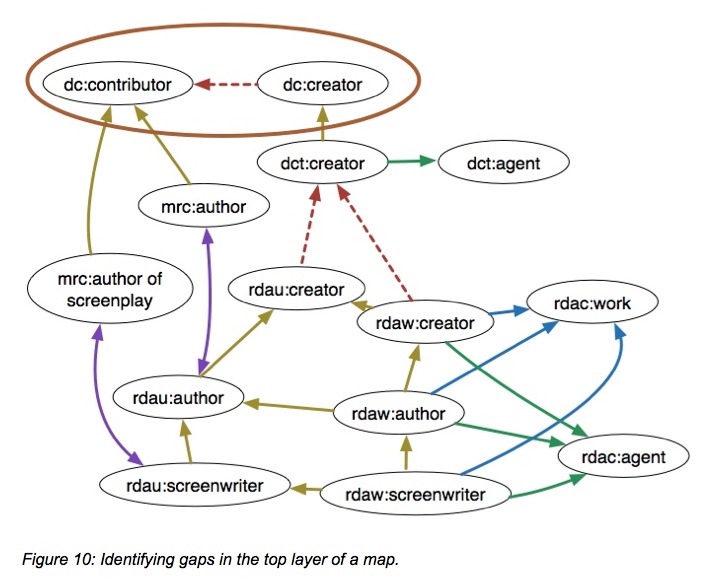
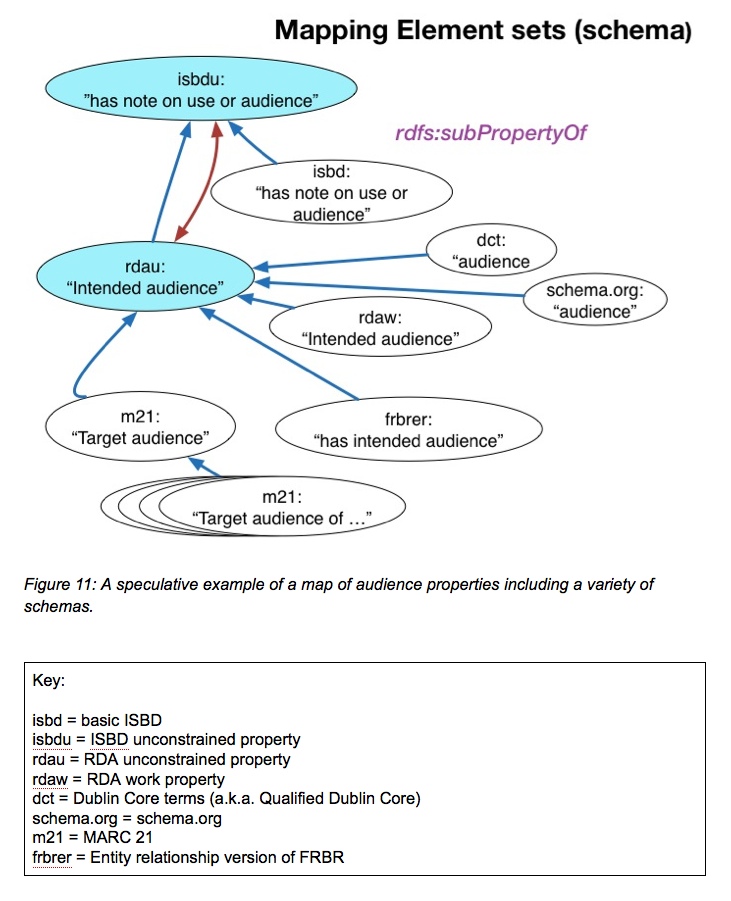
Seen below is an example map of the element sets dealing with “Audience”. All of the blue arrows reflect subproperty relationships with other schemas, with the unconstrained property rdau: “Intended audience” serving as the gathering point for audience properties from other, non-RDA schemas as well as the constrained rdaw: “Intended audience”. The filled blue properties are both unconstrained, and the red arrow connecting them reflects the fact that either the ISBD or the RDA unconstrained properties could serve to gather the related subproperties.
Some additional maps expressed as RDF triples in Turtle, are included in the RDA Registry as part of the tools tab: http://www.rdaregistry.info/Maps/index.html.
##Mapping Value Vocabularies
Several of the element sets noted above are intended to be used with value vocabularies, and these can also be mapped using different relationships appropriate for concepts. Value vocabularies in RDA are expressed using the Simple Knowledge Organisation System (SKOS), published by the World Wide Web Consortium in 2009 (http://www.w3.org/2004/02/skos/). The basic version of SKOS builds on familiar thesaural standards for thesauri, classifications, subject headings, taxonomies, and folksonomies developed by ISO and NISO over the past decades. As a semantic web standard built atop RDF and OWL, SKOS provides the basis for mapping these conceptual vocabularies.
Mapping value vocabularies, whether expressed in SKOS or not, depends not on the labels, but instead on how the vocabulary concepts are defined, and how those definitions are similar or different. This process is made more difficult because many of the older vocabularies in the library domain assume a common understanding and do not specifically define concepts in their vocabularies. This might have been a reasonable accommodation where a limited number of value vocabularies were actually used, but dysfunctional in the current environment of many, many vocabularies.
For example, the definition of the MARC 21 code “e” is “Intended for adults”. Unimarc and PBCore don’t provide definitions at all, but Unimarc separates adults into “general” and “serious” categories, which, without definitions, are difficult to determine in relationship to other attempts to categorize audiences.
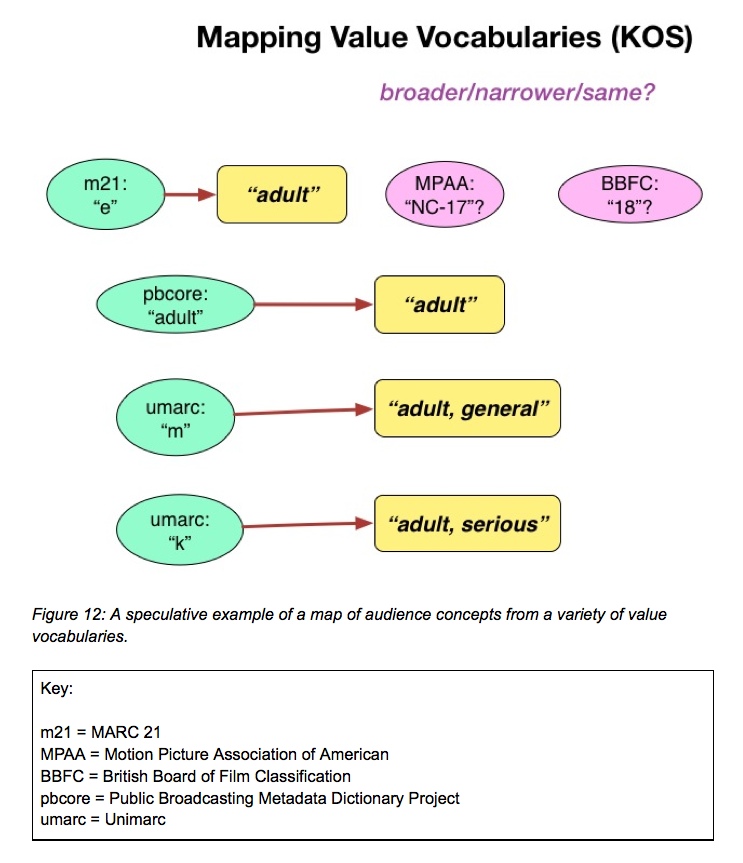
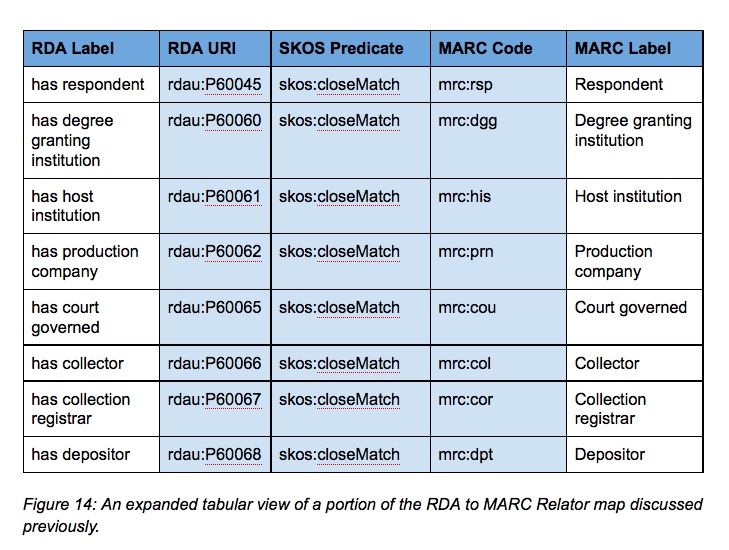
Maps can bridge different vocabularies in a variety of ways. The RDA Registry includes a number of maps, among them a map from RDA relationship designators to MARC Relators. These are solely intended for machines, so are expressed in a very terse way. As an example, the first portion of the RDA to MARC Relators map looks like this in a Turtle (terse triple language, or ttl) serialization.
The subject of each mapping is an RDA unconstrained property with no domain or range and typed as rdfs:Property. The property represents a relationship element or a relationship designator from Appendix I of the RDA Toolkit, not differentiated with respect to RDA entities. The predicate of each mapping is a SKOS property with no domain or range.
The object of each mapping is the URI of a MARC relator code with no domain or range and typed as skos:Concept, rdfs:Property, owl:ObjectProperty, and mads:Topic. This map is embedded in the Unconstrained properties element set (Maps can bridge different vocabularies in a variety of ways. The RDA Registry includes a number of maps, among them a map from RDA relationship designators to MARC Relators. These are solely intended for machines, so are expressed in a very terse way. As an example, the first portion of the RDA to MARC Relators map looks like this in a Turtle (terse triple language, or ttl) serialization.
The subject of each mapping is an RDA unconstrained property with no domain or range and typed as rdfs:Property. The property represents a relationship element or a relationship designator from Appendix I of the RDA Toolkit, not differentiated with respect to RDA entities. The predicate of each mapping is a SKOS property with no domain or range.
The object of each mapping is the URI of a MARC relator code with no domain or range and typed as skos:Concept, rdfs:Property, owl:ObjectProperty, and mads:Topic. This map is embedded in the Unconstrained properties element set.(http://www.rdaregistry.info/Elements/u/)

The triples above are shown in the blue central cells in the table below, with the labels added at each end.
Figure 14: An expanded tabular view of a portion of the RDA to MARC Relator map discussed previously
{kind=link}
##Extension and refinement
In the earlier days of library descriptive metadata based on AACR2 and MARC, decisions about expansion or change in either the AACR2 rules or the MARC standard were discussed and managed by specific standards organizations and processes. Because both standards relied on print publications to describe usage and define vocabularies, the processes of change were slow and implementation required built in time for the revision of the print publications prior to allowing usage within a shared distribution system.
The inclusion of generalized, unconstrained properties suggests a path for extension of RDA elements and value vocabularies for the use of specialized library communities as well as non-library sectors. For the same reasons that mapping activities use unconstrained RDA, extension efforts can use those same unentailed portions of RDA to extend beyond the ‘standard’, but limited, elements and values.
There are a number of use cases for extension and/or refinement of RDA properties and value vocabularies:
- The target vocabulary in RDA is not specific enough to accommodate the needs of a community dealing with special categories of materials
- The users of a particular domain desire to be able to discover materials with a finer granularity of types or topics, so far unavailable in RDA
- A specialized community has a different understanding of a related domain, but wishes to use RDA as their basis for description. A common example of this is the situation where most non-specialist libraries don’t distinguish between colorized and original versions of movies when determining the boundaries of a work, but specialized media collections often consider them separate works.
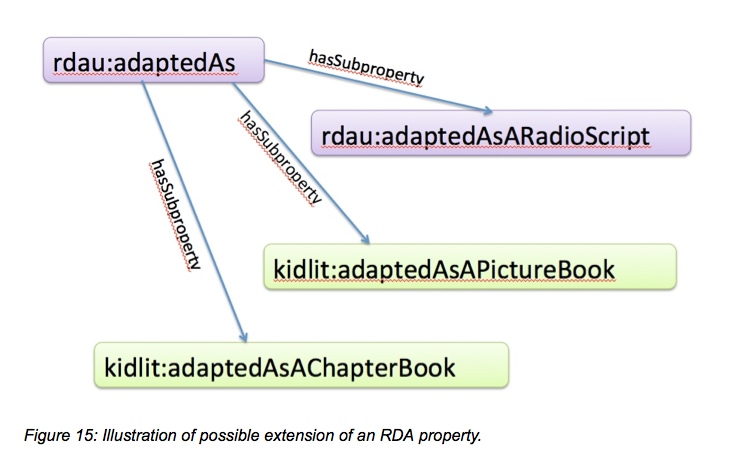
The scenario illustrated in the diagram above shows how a general RDA relationship property can be extended to a different community--here a fictional children’s literature community--using a similar subproperty relationship already part of RDA as a model for extension. In this case the extending community would need to build and expose their extensions in standard ways so that others could benefit from their work and understand their data.
The notion of extension as shown above assumes a trust of the base vocabulary management, in that extending an existing property in another namespace requires that the existing property stay the same over time. Some discussions about extension or refinement suggest that the originating property (RDA: adaptedAs, shown above in green) could be copied into the extended schema to avoid future breakdown, recognizing the inevitability of change.
###Extending Value Vocabularies
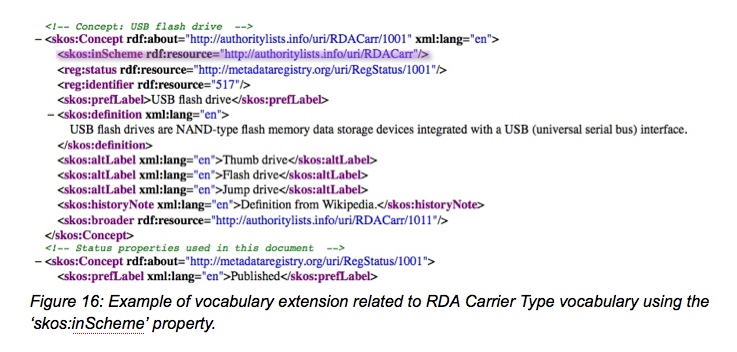
RDA value vocabularies, although extensive, show gaps in several areas, particularly in technical and media subjects. One example is the absence of the term ‘flash drive’ in the computer carrier section of the RDA Carrier Type Vocabulary (http://metadataregistry.org/concept/list/vocabulary_id/46.html). One solution for specialized libraries is to extend particular value vocabularies in their area of interest in order to meet their needs. Below is the abbreviated rdf version of a mock-up, in the OMR Sandbox, of what a concept of “USB flash drive” might look like.
##Additional resources
Dunsire, Gordon, Diane Hillmann, Jon Phipps, Karen Coyle. “A Reconsideration of Mapping in a Semantic World.” Proceedings of the International Conference on Dublin Core and Metadata Applications, 2011. Available at: http://dcpapers.dublincore.org/pubs/article/view/3622
Where to find more information on the standards and efforts described in these guidelines:
DC terms: The most recent version of the DC resides at: http://dublincore.org/documents/dcmi-terms/. The site includes both the original DC 1.1 set and the extended DCterms. Also included are links to recommended Vocabulary Encoding Schemes and Syntax Encoding Schemes, classes used for DC domain and range specifications, the DCMIType vocabulary, and some terms used in the Dublin Core Abstract Model.
FRAD: Based on FRBR, the Functional Requirements for Authority Data (FRAD) standard contains a further analysis of attributes of various entities that are the focus for authority data (persons, families, and corporate bodies, collectively called ‘agents’). FRAD was developed by the IFLA Working Group on Functional Requirements and Numbering of Authority Records (FRANAR), originally published in 2009 and available in print only (http://www.ifla.org/publications/functional-requirements-for-authority-data).
FRBR: A basic summary of the FRBR standard and its implications is available from the Library of Congress (www.loc.gov/cds/downloads/FRBR.PDF). Be aware that though still useful, some parts of the summary are outdated. A more up-to-date webcast is available from ALA: “FRBR as the Basis for RDA”, featuring Robert Maxwell (http://www.ala.org/alcts/confevents/upcoming/webinar/cat/121510). Robert Maxwell has also published a definitive guide to FRBR: “FRBR: a Guide for the Perplexed”, available from the publisher here: http://www.alastore.ala.org/detail.aspx?ID=91 or from other book outlets.
FRBRoo: (http://www.cidoc-crm.org/frbr_inro.html) From the Introduction: “The FRBRoo is a formal ontology intended to capture and represent the underlying semantics of bibliographic information and to facilitate the integration, mediation, and interchange of bibliographic and museum information.” FRBRoo is based on the CIDOC CRM work by IFLA to move FRBR into an object-oriented environment from its original entity-relationship beginnings. The CIDOC CRM site noted above also carries some useful graphical representations of the model and its working parts.
OWL: The Web Ontology Language is currently in its second edition, and a somewhat stable overview of its updated version is available from the W3C OWL site: http://www.w3.org/TR/2012/REC-owl2-overview-20121211/
RDFS: RDF Schema (RDFS) is primarily a set of classes with associated properties for the purpose of describing RDF vocabularies. The current W3C recommendation--RDF Schema 1.1 is available here: http://www.w3.org/TR/rdf-schema/ because RDA’s basic description in the RDA Registry is based on RDFS, that document is the place for further information, though not for the faint of heart.
SKOS: The Simple Knowledge Organisation System (SKOS) has been widely adopted in the knowledge organization domain, and its website (http://www.w3.org/2004/02/skos/) is a good place to start when attempting to learn more about basic SKOS and its documentation.
WEMI: A shortened form of the basic FRBR entities of Work/Expression/Manifestation/Item stack, WEMI is a collective term intended to contain all four entities.