-
*Thread Reply:* There’s a blog post about Egeria here: https://openlineage.io/blog/openlineage-egeria/
+
*Thread Reply:* There’s a blog post about Egeria here: https://openlineage.io/blog/openlineage-egeria/
openlineage.io
@@ -85830,7 +85836,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-22 10:00:56
-
*Thread Reply:* @Brad Paskewitz at Microsoft, the solution that Julien linked above, we are using the HTTP Transport (REST API) as we are consuming the OpenLineage Events and transforming them to Apache Atlas / Microsoft Purview.
+
*Thread Reply:* @Brad Paskewitz at Microsoft, the solution that Julien linked above, we are using the HTTP Transport (REST API) as we are consuming the OpenLineage Events and transforming them to Apache Atlas / Microsoft Purview.
However, there is a good deal of interest in using the kafka transport instead and that's our future roadmap.
@@ -85914,7 +85920,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-25 12:04:48
-
*Thread Reply:* Hmm, if Databricks is shutting the process down without waiting for the ListenerBus to clear, I don’t know that there’s a lot we can do. The best thing is to somehow delay the main application thread from exiting. One thing you could try is to subclass the OpenLineageSparkListener and generate a lock for each SparkListenerSQLExecutionStart and release it when the accompanying SparkListenerSQLExecutionEnd event is processed. Then, in the main application, block until all such locks are released. If you try it and it works, let us know!
+
*Thread Reply:* Hmm, if Databricks is shutting the process down without waiting for the ListenerBus to clear, I don’t know that there’s a lot we can do. The best thing is to somehow delay the main application thread from exiting. One thing you could try is to subclass the OpenLineageSparkListener and generate a lock for each SparkListenerSQLExecutionStart and release it when the accompanying SparkListenerSQLExecutionEnd event is processed. Then, in the main application, block until all such locks are released. If you try it and it works, let us know!
@@ -85940,7 +85946,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-26 05:46:35
-
*Thread Reply:* Ok thanks for the idea! I'll tell you if I try this and if it works 🤞
+
*Thread Reply:* Ok thanks for the idea! I'll tell you if I try this and if it works 🤞
@@ -85992,7 +85998,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-25 10:38:03
-
*Thread Reply:* Hey Petr. Please DM me or describe the issue here 🙂
+
*Thread Reply:* Hey Petr. Please DM me or describe the issue here 🙂
@@ -86044,7 +86050,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-27 15:25:04
-
*Thread Reply:* Command
+
*Thread Reply:* Command
spark-submit --packages "io.openlineage:openlineage_spark:0.19.+" \
--conf "spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener" \
--conf "spark.openlineage.transport.type=kafka" \
@@ -86076,7 +86082,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-27 15:25:14
-
*Thread Reply:* 23/01/27 17:29:06 ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
+ *Thread Reply:* 23/01/27 17:29:06 ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
java.lang.NullPointerException
at io.openlineage.client.transports.TransportFactory.build(TransportFactory.java:44)
at io.openlineage.spark.agent.EventEmitter.<init>(EventEmitter.java:40)
@@ -86121,7 +86127,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-27 15:25:31
-
*Thread Reply:* I would appreciate any pointers on getting started with using openlineage-spark with Kafka.
+
*Thread Reply:* I would appreciate any pointers on getting started with using openlineage-spark with Kafka.
@@ -86147,7 +86153,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-27 16:15:00
-
*Thread Reply:* Also this might seem a little elementary but the kafka topic itself, should it be hosted on the spark cluster or could it be any kafka topic?
+
*Thread Reply:* Also this might seem a little elementary but the kafka topic itself, should it be hosted on the spark cluster or could it be any kafka topic?
@@ -86173,7 +86179,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 08:37:07
-
*Thread Reply:* 👀 Could I get some help on this, please?
+
*Thread Reply:* 👀 Could I get some help on this, please?
@@ -86199,7 +86205,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 09:07:08
-
*Thread Reply:* I think any NullPointerException is clearly our bug, can you open issue on OL GitHub?
+
*Thread Reply:* I think any NullPointerException is clearly our bug, can you open issue on OL GitHub?
@@ -86229,7 +86235,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 09:30:51
-
*Thread Reply:* @Maciej Obuchowski Another interesting thing is if I use 0.19.2 version specifically, I get
+
*Thread Reply:* @Maciej Obuchowski Another interesting thing is if I use 0.19.2 version specifically, I get
23/01/30 14:28:33 INFO RddExecutionContext: RDDs are empty: skipping sending OpenLineage event
I am trying to print to console at the moment. I haven't been able to get Kafka transport type working though.
@@ -86258,7 +86264,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 09:41:12
-
*Thread Reply:* Are you getting events printed on the console though? This log should not affect you if you're running, for example Spark SQL jobs
+
*Thread Reply:* Are you getting events printed on the console though? This log should not affect you if you're running, for example Spark SQL jobs
@@ -86284,7 +86290,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 09:42:28
-
*Thread Reply:* I am trying to run a python file using pyspark. 23/01/30 14:40:49 INFO RddExecutionContext: RDDs are empty: skipping sending OpenLineage event
+
*Thread Reply:* I am trying to run a python file using pyspark. 23/01/30 14:40:49 INFO RddExecutionContext: RDDs are empty: skipping sending OpenLineage event
I see this and don't see any events on the console.
@@ -86311,7 +86317,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 09:55:41
-
*Thread Reply:* Any logs filling pattern
+
*Thread Reply:* Any logs filling pattern
log.warn("Unable to access job conf from RDD", nfe);
or
<a href="http://log.info">log.info</a>("Found job conf from RDD {}", jc);
@@ -86341,7 +86347,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 09:57:20
-
*Thread Reply:* ```23/01/30 14:40:48 INFO DAGScheduler: Submitting ShuffleMapStage 0 (PairwiseRDD[2] at reduceByKey at /tmp/spark-20487725-f49b-4587-986d-e63a61890673/statusapidemo.py:47), which has no missing parents
+
*Thread Reply:* ```23/01/30 14:40:48 INFO DAGScheduler: Submitting ShuffleMapStage 0 (PairwiseRDD[2] at reduceByKey at /tmp/spark-20487725-f49b-4587-986d-e63a61890673/statusapidemo.py:47), which has no missing parents
23/01/30 14:40:49 WARN RddExecutionContext: Unable to access job conf from RDD
java.lang.NoSuchFieldException: Field is not instance of HadoopMapRedWriteConfigUtil
at io.openlineage.spark.agent.lifecycle.RddExecutionContext.lambda$setActiveJob$0(RddExecutionContext.java:117)
@@ -86396,7 +86402,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 10:03:35
2023-01-30 10:04:14
-
*Thread Reply:* and I think I might have solution on a branch for it, just need to polish it up to release
+
*Thread Reply:* and I think I might have solution on a branch for it, just need to polish it up to release
@@ -86448,7 +86454,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 10:13:37
-
*Thread Reply:* Aah got it. I will give it a try with SQL and a jar.
+
*Thread Reply:* Aah got it. I will give it a try with SQL and a jar.
Do you have a ETA on when the python issue would be fixed?
@@ -86476,7 +86482,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 10:37:51
-
*Thread Reply:* @Maciej Obuchowski Well I run into the same errors if I run spark-submit on a jar.
+
*Thread Reply:* @Maciej Obuchowski Well I run into the same errors if I run spark-submit on a jar.
@@ -86502,7 +86508,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 10:38:44
-
*Thread Reply:* I think that has nothing to do with python
+
*Thread Reply:* I think that has nothing to do with python
@@ -86528,7 +86534,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 10:39:16
-
*Thread Reply:* BTW, which Spark version are you using?
+
*Thread Reply:* BTW, which Spark version are you using?
@@ -86554,7 +86560,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 10:41:22
-
*Thread Reply:* We are on 3.3.1
+
*Thread Reply:* We are on 3.3.1
@@ -86584,7 +86590,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 11:38:24
-
*Thread Reply:* @Maciej Obuchowski Do you have a estimated release date for the fix. Our team is specifically interested in using the Emitter to write out to Kafka.
+
*Thread Reply:* @Maciej Obuchowski Do you have a estimated release date for the fix. Our team is specifically interested in using the Emitter to write out to Kafka.
@@ -86610,7 +86616,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 11:46:30
-
*Thread Reply:* I think we plan to release somewhere in the next week
+
*Thread Reply:* I think we plan to release somewhere in the next week
@@ -86640,7 +86646,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-06 09:21:25
-
*Thread Reply:* @Susmitha Anandarao PR fixing this has been merged, release should be today
+
*Thread Reply:* @Susmitha Anandarao PR fixing this has been merged, release should be today
@@ -86699,7 +86705,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-27 18:38:40
-
*Thread Reply:* hmmm, I am not sure. perhaps @Benji Lampel can help, he’s very familiar with those operators.
+
*Thread Reply:* hmmm, I am not sure. perhaps @Benji Lampel can help, he’s very familiar with those operators.
@@ -86729,7 +86735,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-27 18:46:15
-
*Thread Reply:* @Benji Lampel any help would be appreciated!
+
*Thread Reply:* @Benji Lampel any help would be appreciated!
@@ -86755,7 +86761,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-30 09:01:34
-
*Thread Reply:* Hey Paul, the SQLCheckExtractors were written with the intent that they would be used by a provider that inherits for them - they are all treated as a sort of base class. What is the exact error message you're getting? And what is the operator code?
+
*Thread Reply:* Hey Paul, the SQLCheckExtractors were written with the intent that they would be used by a provider that inherits for them - they are all treated as a sort of base class. What is the exact error message you're getting? And what is the operator code?
Could you try this with a PostgresCheckOperator ?
(Also, only the SqlColumnCheckOperator and SqlTableCheckOperator will provide data quality facets in their output, those functions are not implementable in the other operators at this time)
@@ -86787,7 +86793,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-31 14:36:07
-
*Thread Reply:* @Benji Lampel here is the error message. i am not sure what the operator code is.
+
*Thread Reply:* @Benji Lampel here is the error message. i am not sure what the operator code is.
3-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - Traceback (most recent call last):
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/usr/lib/python3.8/threading.py", line 932, in _bootstrap_inner
@@ -86832,7 +86838,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-31 14:37:06
-
*Thread Reply:* and above that
+
*Thread Reply:* and above that
[2023-01-31, 00:32:38 UTC] {connection.py:424} ERROR - Unable to retrieve connection from secrets backend (EnvironmentVariablesBackend). Checking subsequent secrets backend.
Traceback (most recent call last):
@@ -86867,7 +86873,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-31 14:39:31
-
*Thread Reply:* sorry, i should mention we're wrapping over the CheckOperator as we're still migrating from 1.10.15 @Benji Lampel
+
*Thread Reply:* sorry, i should mention we're wrapping over the CheckOperator as we're still migrating from 1.10.15 @Benji Lampel
@@ -86893,7 +86899,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-31 15:09:51
-
*Thread Reply:* What do you mean by wrapping the CheckOperator? Like how so, exactly? Can you show me the operator code you're using in the DAG?
+
*Thread Reply:* What do you mean by wrapping the CheckOperator? Like how so, exactly? Can you show me the operator code you're using in the DAG?
@@ -86919,7 +86925,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-31 17:38:45
-
*Thread Reply:* like so
+
*Thread Reply:* like so
class CustomSQLCheckOperator(CheckOperator):
....
@@ -86948,7 +86954,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-31 17:39:30
-
*Thread Reply:* i think i found the issue though, we have our own get_hook function and so we don't follow the traditional Airflow way of setting CONN_ID which is why CONN_ID is always None and that path only gets called through OpenLineage which doesn't ever get called with our custom wrapper
+
*Thread Reply:* i think i found the issue though, we have our own get_hook function and so we don't follow the traditional Airflow way of setting CONN_ID which is why CONN_ID is always None and that path only gets called through OpenLineage which doesn't ever get called with our custom wrapper
@@ -87030,7 +87036,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-01-31 12:57:47
2023-01-31 13:26:33
-
*Thread Reply:* Thank you for this!
+
*Thread Reply:* Thank you for this!
I created a openlineage.yml file with the following data to test out the integration locally.
transport:
@@ -87130,7 +87136,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-02 14:39:29
-
*Thread Reply:* @Susmitha Anandarao It's not installed because it's large binary package. We don't want to install for every user something giant majority won't use, and it's 100x bigger than rest of the client.
+
*Thread Reply:* @Susmitha Anandarao It's not installed because it's large binary package. We don't want to install for every user something giant majority won't use, and it's 100x bigger than rest of the client.
We need to indicate this way better, and do not throw this error directly at user thought, both in docs and code.
@@ -87349,7 +87355,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-02 08:39:34
2023-02-02 08:39:59
-
*Thread Reply:* We sometimes experience this in context of very small, quick jobs
+
*Thread Reply:* We sometimes experience this in context of very small, quick jobs
@@ -87403,7 +87409,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-02 08:43:24
-
*Thread Reply:* Yes, my scenarios are dealing with quick jobs.
+
*Thread Reply:* Yes, my scenarios are dealing with quick jobs.
Good to know that we will be able to solve it with future spark versions. Thanks!
@@ -87509,7 +87515,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-03 13:24:03
-
*Thread Reply:* exciting to see the client proxy work being released by @Minkyu Park 💯
+
*Thread Reply:* exciting to see the client proxy work being released by @Minkyu Park 💯
@@ -87535,7 +87541,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-03 13:35:38
-
*Thread Reply:* This was without a doubt among the fastest release votes we’ve ever had 😉 . Thank you! You can expect the release to happen on Monday.
+
*Thread Reply:* This was without a doubt among the fastest release votes we’ve ever had 😉 . Thank you! You can expect the release to happen on Monday.
@@ -87561,7 +87567,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-03 14:02:52
-
*Thread Reply:* Lol the proxy is still in development and not ready for use
+
*Thread Reply:* Lol the proxy is still in development and not ready for use
@@ -87587,7 +87593,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-03 14:03:26
-
*Thread Reply:* Good point! Let’s make that clear in the release / docs?
+
*Thread Reply:* Good point! Let’s make that clear in the release / docs?
@@ -87617,7 +87623,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-03 14:03:33
-
*Thread Reply:* But it doesn’t block anything anyway, so happy to see the release
+
*Thread Reply:* But it doesn’t block anything anyway, so happy to see the release
@@ -87643,7 +87649,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-03 14:04:38
-
*Thread Reply:* We can celebrate that the proposal for the proxy is merged. I’m happy with that 🥳
+
*Thread Reply:* We can celebrate that the proposal for the proxy is merged. I’m happy with that 🥳
@@ -87699,7 +87705,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-06 14:47:15
-
*Thread Reply:* Hey @Daniel Joanes! thanks for the question.
+
*Thread Reply:* Hey @Daniel Joanes! thanks for the question.
I am not aware of an issue that captures this. Column-level lineage is a somewhat new facet in the spec, and implementations across the various integrations are in varying states of readiness.
@@ -87729,7 +87735,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-06 14:50:59
-
*Thread Reply:* Go for it, once it's created i'll add a watch
+
*Thread Reply:* Go for it, once it's created i'll add a watch
@@ -87759,7 +87765,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-06 14:51:13
-
*Thread Reply:* Thanks Ross!
+
*Thread Reply:* Thanks Ross!
@@ -87785,7 +87791,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-06 23:10:30
-
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1581
+
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1581
@@ -87945,7 +87951,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-09 10:50:49
-
*Thread Reply:* Thanks for requesting a release. 3 +1s from committers will authorize an immediate release.
+
*Thread Reply:* Thanks for requesting a release. 3 +1s from committers will authorize an immediate release.
@@ -87971,7 +87977,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-09 11:15:35
-
*Thread Reply:* 0.20.5 ?
+
*Thread Reply:* 0.20.5 ?
@@ -88001,7 +88007,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-09 11:28:20
-
*Thread Reply:* @Michael Robinson auth'd
+
*Thread Reply:* @Michael Robinson auth'd
@@ -88027,7 +88033,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-09 11:32:06
-
*Thread Reply:* 👍 the release is authorized
+
*Thread Reply:* 👍 the release is authorized
@@ -88126,14 +88132,14 @@
MARQUEZAPIKEY=[YOURAPIKEY]
"$ref": "#/$defs/Job"
},
"inputs": {
- "description": "The set of <strong><em>*input</em><em></strong> datasets.",
+ "description": "The set of <strong><em>*input</em></strong>* datasets.",
"type": "array",
"items": {
"$ref": "#/$defs/InputDataset"
}
},
"outputs": {
- "description": "The set of <strong></em><em>output</em>*</strong> datasets.",
+ "description": "The set of <strong><em>*output</em></strong>* datasets.",
"type": "array",
"items": {
"$ref": "#/$defs/OutputDataset"
@@ -88389,7 +88395,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-09 16:23:36
-
*Thread Reply:* I am also exploring something similar, but writing to kafka, and would want to know more on how we could add custom metadata from spark.
+
*Thread Reply:* I am also exploring something similar, but writing to kafka, and would want to know more on how we could add custom metadata from spark.
@@ -88415,7 +88421,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-10 02:23:40
-
*Thread Reply:* Hi @Avinash Pancham @Susmitha Anandarao, it's great to hear about successful experimenting on your side.
+
*Thread Reply:* Hi @Avinash Pancham @Susmitha Anandarao, it's great to hear about successful experimenting on your side.
Although Openlineage spec provides some built-in facets definition, a facet object can be anything you want (https://openlineage.io/apidocs/openapi/#tag/OpenLineage/operation/postRunEvent). The example metadata provided in this chat could be put into job or run facets I believe.
@@ -88445,7 +88451,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-10 09:09:10
-
*Thread Reply:* (I would love to see what your specs are! I’m not with Astronomer, just a community member, but I am finding that many of the customizations people are making to the spec are valuable ones that we should consider adding to core)
+
*Thread Reply:* (I would love to see what your specs are! I’m not with Astronomer, just a community member, but I am finding that many of the customizations people are making to the spec are valuable ones that we should consider adding to core)
@@ -88471,7 +88477,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-14 16:51:28
-
*Thread Reply:* Are there any examples out there of customizations already done in Spark? An example would definitely help!
+
*Thread Reply:* Are there any examples out there of customizations already done in Spark? An example would definitely help!
@@ -88497,7 +88503,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 08:43:08
-
*Thread Reply:* I think @Will Johnson might have something to add about customization
+
*Thread Reply:* I think @Will Johnson might have something to add about customization
@@ -88523,7 +88529,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 23:58:36
2023-02-15 04:52:59
2023-02-15 07:19:39
-
*Thread Reply:* @Quentin Nambot this happens because we run additional integration tests against real databases (like BigQuery) which aren't ever configured on forks, since we don't want to expose our secrets. We need to figure out how to make this experience better, but in the meantime we've pushed your code using git-push-fork-to-upstream-branch and it passes all the tests.
+
*Thread Reply:* @Quentin Nambot this happens because we run additional integration tests against real databases (like BigQuery) which aren't ever configured on forks, since we don't want to expose our secrets. We need to figure out how to make this experience better, but in the meantime we've pushed your code using git-push-fork-to-upstream-branch and it passes all the tests.
@@ -88850,7 +88856,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 07:21:49
-
*Thread Reply:* Feel free to un-draft your PR if you think it's ready for review
+
*Thread Reply:* Feel free to un-draft your PR if you think it's ready for review
@@ -88876,7 +88882,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 08:03:56
-
*Thread Reply:* Ok nice thanks 👍
+
*Thread Reply:* Ok nice thanks 👍
@@ -88902,7 +88908,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 08:04:49
-
*Thread Reply:* I think it's ready, however should I update the version somewhere?
+
*Thread Reply:* I think it's ready, however should I update the version somewhere?
@@ -88928,7 +88934,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 08:42:39
-
*Thread Reply:* @Quentin Nambot I don't think so - it's just that you opened PR as Draft , so I'm not sure if you want to add something else to it.
+
*Thread Reply:* @Quentin Nambot I don't think so - it's just that you opened PR as Draft , so I'm not sure if you want to add something else to it.
@@ -88958,7 +88964,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 08:43:36
-
*Thread Reply:* No I don't want to add anything so I opened it 👍
+
*Thread Reply:* No I don't want to add anything so I opened it 👍
@@ -89035,7 +89041,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 21:30:47
-
*Thread Reply:* You can add your own EventHandlerFactory https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/main/java/io/openlineage/spark/api/OpenLineageEventHandlerFactory.java . See the docs about extending here - https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#extending
+
*Thread Reply:* You can add your own EventHandlerFactory https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/main/java/io/openlineage/spark/api/OpenLineageEventHandlerFactory.java . See the docs about extending here - https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#extending
@@ -89085,7 +89091,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 21:32:19
-
*Thread Reply:* I have that set up already like this:
+
*Thread Reply:* I have that set up already like this:
public class LyftOpenLineageEventHandlerFactory implements OpenLineageEventHandlerFactory {
@Override
public Collection<PartialFunction<LogicalPlan, List<OutputDataset>>>
@@ -89122,7 +89128,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 21:33:35
-
*Thread Reply:* do I just add a constructor? the visitorFactory is private so I wasn't sure if that's something that was intended to change
+
*Thread Reply:* do I just add a constructor? the visitorFactory is private so I wasn't sure if that's something that was intended to change
@@ -89148,7 +89154,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 21:34:30
-
*Thread Reply:* .
+
*Thread Reply:* .
@@ -89174,7 +89180,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 21:34:49
-
*Thread Reply:* @Michael Collado
+
*Thread Reply:* @Michael Collado
@@ -89200,7 +89206,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 21:35:14
-
*Thread Reply:* The VisitorFactory is only used by the internal EventHandlerFactory. It shouldn’t be needed for your custom one
+
*Thread Reply:* The VisitorFactory is only used by the internal EventHandlerFactory. It shouldn’t be needed for your custom one
@@ -89226,7 +89232,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-15 21:35:48
-
*Thread Reply:* Have you added the file to the META-INF folder of your jar?
+
*Thread Reply:* Have you added the file to the META-INF folder of your jar?
@@ -89252,7 +89258,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 11:01:56
-
*Thread Reply:* yes, I am able to use my custom event handler factory with a list of visitors but for some reason I cant access the visitors for some commands (AlterTableAddPartitionCommand) is one
+
*Thread Reply:* yes, I am able to use my custom event handler factory with a list of visitors but for some reason I cant access the visitors for some commands (AlterTableAddPartitionCommand) is one
@@ -89278,7 +89284,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 11:02:29
-
*Thread Reply:* so even if I set up everything correctly I am unable to reach the code for that specific visitor
+
*Thread Reply:* so even if I set up everything correctly I am unable to reach the code for that specific visitor
@@ -89304,7 +89310,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 11:05:22
-
*Thread Reply:* and my assumption is I can reach other commands but not this one because the command is not defined in the BaseVisitorFactory but maybe im wrong @Michael Collado
+
*Thread Reply:* and my assumption is I can reach other commands but not this one because the command is not defined in the BaseVisitorFactory but maybe im wrong @Michael Collado
@@ -89330,7 +89336,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 15:05:19
-
*Thread Reply:* the VisitorFactory is loaded by the InternalEventHandlerFactory here. However, the createOutputDatasetQueryPlanVisitors should contain a union of everything defined by the VisitorFactory as well as your custom visitors: see this code.
+
*Thread Reply:* the VisitorFactory is loaded by the InternalEventHandlerFactory here. However, the createOutputDatasetQueryPlanVisitors should contain a union of everything defined by the VisitorFactory as well as your custom visitors: see this code.
@@ -89404,7 +89410,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 15:09:21
-
*Thread Reply:* there might be a conflict with another visitor that’s being matched against that command. Can you turn on debug logging and look for this line to see what visitor is being applied to that command?
+
*Thread Reply:* there might be a conflict with another visitor that’s being matched against that command. Can you turn on debug logging and look for this line to see what visitor is being applied to that command?
@@ -89461,7 +89467,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 16:54:46
-
*Thread Reply:* This was helpful, it works now, thank you so much Michael!
+
*Thread Reply:* This was helpful, it works now, thank you so much Michael!
@@ -89517,7 +89523,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:09:49
-
*Thread Reply:* what is the curl cmd you are running? and what endpoint are you hitting? (assuming Marquez?)
+
*Thread Reply:* what is the curl cmd you are running? and what endpoint are you hitting? (assuming Marquez?)
@@ -89543,7 +89549,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:18:28
-
*Thread Reply:* yep
+
*Thread Reply:* yep
I am running curl - X curl -X POST http://localhost:5000/api/v1/namespaces/test ^
-H 'Content-Type: application/json' ^
-d '{ownerName:"me", description:"no description"^
@@ -89578,7 +89584,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:23:08
-
*Thread Reply:* Marquez logs all supported endpoints (and methods) on start up. For example, here are all the supported methods on /api/v1/namespaces/{namespace} :
+
*Thread Reply:* Marquez logs all supported endpoints (and methods) on start up. For example, here are all the supported methods on /api/v1/namespaces/{namespace} :
marquez-api | DELETE /api/v1/namespaces/{namespace} (marquez.api.NamespaceResource)
marquez-api | GET /api/v1/namespaces/{namespace} (marquez.api.NamespaceResource)
marquez-api | PUT /api/v1/namespaces/{namespace} (marquez.api.NamespaceResource)
@@ -89608,7 +89614,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:26:23
-
*Thread Reply:* 3rd stupid question of the night
+
*Thread Reply:* 3rd stupid question of the night
Sorry kept on trying POST who knows why
@@ -89635,7 +89641,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:26:56
-
*Thread Reply:* no worries! keep the questions coming!
+
*Thread Reply:* no worries! keep the questions coming!
@@ -89661,7 +89667,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:29:46
-
*Thread Reply:* well, maybe because it’s so late on your end! get some rest!
+
*Thread Reply:* well, maybe because it’s so late on your end! get some rest!
@@ -89687,7 +89693,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:36:25
-
*Thread Reply:* Yeah but I want to see how it works
+
*Thread Reply:* Yeah but I want to see how it works
Right now I have a response 200 for the creation of the names ... but it seems that nothing occurred
nor on marquez front end (localhost:3000)
nor on the database
@@ -89716,7 +89722,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:37:13
-
*Thread Reply:* can you curl the list namespaces endpoint?
+
*Thread Reply:* can you curl the list namespaces endpoint?
@@ -89742,7 +89748,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:38:14
-
*Thread Reply:* yep : nothing changed
+
*Thread Reply:* yep : nothing changed
only default and food_delivery
@@ -89769,7 +89775,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:38:47
-
*Thread Reply:* can you post your server logs? you should see the request
+
*Thread Reply:* can you post your server logs? you should see the request
@@ -89795,7 +89801,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:40:41
-
*Thread Reply:* marquez-api | XXX.23.0.4 - - [17/Feb/2023:00:30:38 +0000] "PUT /api/v1/namespaces/ciro HTTP/1.1" 500 110 "-" "-" 7
+
*Thread Reply:* marquez-api | XXX.23.0.4 - - [17/Feb/2023:00:30:38 +0000] "PUT /api/v1/namespaces/ciro HTTP/1.1" 500 110 "-" "-" 7
marquez-api | INFO [2023-02-17 00:32:07,072] marquez.logging.LoggingMdcFilter: status: 200
@@ -89822,7 +89828,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:41:12
-
*Thread Reply:* the server is returning a 500 ?
+
*Thread Reply:* the server is returning a 500 ?
@@ -89848,7 +89854,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:41:57
-
*Thread Reply:* odd that LoggingMdcFilter is logging 200
+
*Thread Reply:* odd that LoggingMdcFilter is logging 200
@@ -89874,7 +89880,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:43:24
-
*Thread Reply:* Bit confused because now I realize that postman is returning bad request
+
*Thread Reply:* Bit confused because now I realize that postman is returning bad request
@@ -89900,7 +89906,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:43:51
-
*Thread Reply:*
+
*Thread Reply:*
@@ -89935,7 +89941,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-16 19:44:30
-
*Thread Reply:* You'll notice that I go to use 3000 in the url
+
*Thread Reply:* You'll notice that I go to use 3000 in the url
If I use 5000 I get No host
@@ -89962,7 +89968,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 01:14:50
-
*Thread Reply:* odd, the API should be using port 5000, have you followed our quickstart for Marquez?
+
*Thread Reply:* odd, the API should be using port 5000, have you followed our quickstart for Marquez?
@@ -89988,7 +89994,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 03:43:29
-
*Thread Reply:* Hello Willy
+
*Thread Reply:* Hello Willy
I am starting from scratch followin instruction from https://openlineage.io/docs/getting-started/
I am on Windows
Instead of
@@ -90038,7 +90044,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-20 03:40:48
-
*Thread Reply:* The issue is related to PostMan
+
*Thread Reply:* The issue is related to PostMan
@@ -90090,7 +90096,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 03:54:47
-
*Thread Reply:* Hi @Anirudh Shrinivason, this is a great question. We included extra fields in OpenLineage spec to contain that information:
+
*Thread Reply:* Hi @Anirudh Shrinivason, this is a great question. We included extra fields in OpenLineage spec to contain that information:
"transformationDescription": {
"type": "string",
"description": "a string representation of the transformation applied"
@@ -90125,7 +90131,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 04:02:30
-
*Thread Reply:* Thanks a lot! That is great. Is there a potential plan in the roadmap to support this for spark?
+
*Thread Reply:* Thanks a lot! That is great. Is there a potential plan in the roadmap to support this for spark?
@@ -90151,7 +90157,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 04:08:16
-
*Thread Reply:* I think there will be a growing interest in that. In general a dependency may really difficult to express if many Spark operators are used on input columns to produce output one. The simple version would be just to detect indetity operation or some kind of hashing.
+
*Thread Reply:* I think there will be a growing interest in that. In general a dependency may really difficult to express if many Spark operators are used on input columns to produce output one. The simple version would be just to detect indetity operation or some kind of hashing.
To sum up, we don't have yet a proposal on that but this seems to be a natural next step in enriching column lineage features.
@@ -90179,7 +90185,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 04:40:04
-
*Thread Reply:* Got it. Thanks! If this item potentially comes on the roadmap, then I'd be happy to work with other interested developers to help contribute! 🙂
+
*Thread Reply:* Got it. Thanks! If this item potentially comes on the roadmap, then I'd be happy to work with other interested developers to help contribute! 🙂
@@ -90205,7 +90211,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 04:43:00
-
*Thread Reply:* Great to hear that. What you could perhaps start with, is come to our monthly OpenLineage meetings and ask @Michael Robinson to put this item on discussions' list. There are many strategies to address this issue and hearing your story, usage scenario and would are you trying to achieve, would be super helpful in design and implementation phase.
+
*Thread Reply:* Great to hear that. What you could perhaps start with, is come to our monthly OpenLineage meetings and ask @Michael Robinson to put this item on discussions' list. There are many strategies to address this issue and hearing your story, usage scenario and would are you trying to achieve, would be super helpful in design and implementation phase.
@@ -90231,7 +90237,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 04:44:18
-
*Thread Reply:* Got it! The monthly meeting might be a bit hard for me to attend live, because of the time zone. But I'll try my best to make it to the next one! thanks!
+
*Thread Reply:* Got it! The monthly meeting might be a bit hard for me to attend live, because of the time zone. But I'll try my best to make it to the next one! thanks!
@@ -90257,7 +90263,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-17 09:46:22
-
*Thread Reply:* Thank you for bringing this up, @Anirudh Shrinivason. I’ll add it to the agenda of our next meeting because there might be interest from others in adding this to the roadmap.
+
*Thread Reply:* Thank you for bringing this up, @Anirudh Shrinivason. I’ll add it to the agenda of our next meeting because there might be interest from others in adding this to the roadmap.
@@ -90319,7 +90325,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-20 02:10:13
2023-02-20 03:29:07
-
*Thread Reply:* Thank You Pavel
+
*Thread Reply:* Thank You Pavel
@@ -90397,7 +90403,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-21 09:12:17
-
*Thread Reply:* We generally schedule a release every month, next one will be in the next week - is that okay @Anirudh Shrinivason?
+
*Thread Reply:* We generally schedule a release every month, next one will be in the next week - is that okay @Anirudh Shrinivason?
@@ -90423,7 +90429,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-21 11:38:50
-
*Thread Reply:* Yes, there’s one scheduled for next Wednesday, if that suits.
+
*Thread Reply:* Yes, there’s one scheduled for next Wednesday, if that suits.
@@ -90449,7 +90455,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-21 21:45:58
-
*Thread Reply:* Okay yeah sure that works. Thanks
+
*Thread Reply:* Okay yeah sure that works. Thanks
@@ -90479,7 +90485,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-01 10:12:45
-
*Thread Reply:* @Anirudh Shrinivason we’re expecting the release to happen today or tomorrow, FYI
+
*Thread Reply:* @Anirudh Shrinivason we’re expecting the release to happen today or tomorrow, FYI
@@ -90505,7 +90511,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-01 21:22:40
-
*Thread Reply:* Awesome thanks
+
*Thread Reply:* Awesome thanks
@@ -90569,7 +90575,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-23 23:44:03
-
*Thread Reply:* This is my checkponit configuration in GE.
+
*Thread Reply:* This is my checkponit configuration in GE.
```name: 'openlineagecheckpoint'
configversion: 1.0
templatename:
@@ -90632,7 +90638,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-24 11:31:05
-
*Thread Reply:* What version of GX are you running? And is this being run directly through GX or through Airflow with the operator?
+
*Thread Reply:* What version of GX are you running? And is this being run directly through GX or through Airflow with the operator?
@@ -90658,7 +90664,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-26 20:05:12
-
*Thread Reply:* I use the latest version of Great Expectations. This error occurs either directly through Great Expectations or airflow
+
*Thread Reply:* I use the latest version of Great Expectations. This error occurs either directly through Great Expectations or airflow
@@ -90684,7 +90690,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-27 09:10:00
-
*Thread Reply:* I noticed another issue in the latest version as well. Try dropping to GE version great-expectations==0.15.44 for now. That is the latest one that works for me.
+
*Thread Reply:* I noticed another issue in the latest version as well. Try dropping to GE version great-expectations==0.15.44 for now. That is the latest one that works for me.
@@ -90710,7 +90716,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-27 09:11:34
-
*Thread Reply:* You should definitely open an issue here, and you can tag me @denimalpaca in the comment
+
*Thread Reply:* You should definitely open an issue here, and you can tag me @denimalpaca in the comment
@@ -90736,7 +90742,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-27 18:07:29
-
*Thread Reply:* Thanks Benji, but I still have the same problem after I drop to great-expectations==0.15.44 , this is my requirement file
+
*Thread Reply:* Thanks Benji, but I still have the same problem after I drop to great-expectations==0.15.44 , this is my requirement file
great_expectations==0.15.44
sqlalchemy
@@ -90771,7 +90777,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-02-28 13:34:03
-
*Thread Reply:* interesting... I do think this may be a GX issue so let's see if they say anything. I can also cross post this thread to their slack
+
*Thread Reply:* interesting... I do think this may be a GX issue so let's see if they say anything. I can also cross post this thread to their slack
@@ -90823,7 +90829,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-05-01 11:47:40
-
*Thread Reply:* I know I’m responding to an older post - I’m not sure if this would work in your environment? https://aws.amazon.com/blogs/big-data/build-data-lineage-for-data-lakes-using-aws-glue-amazon-neptune-and-spline/
+
*Thread Reply:* I know I’m responding to an older post - I’m not sure if this would work in your environment? https://aws.amazon.com/blogs/big-data/build-data-lineage-for-data-lakes-using-aws-glue-amazon-neptune-and-spline/
Are you using AWS Glue with Spark jobs?
@@ -90875,7 +90881,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-05-02 15:16:14
-
*Thread Reply:* This was proposed by our AWS Solution architect but we are not seeing much improvement compared to open lineage. Have you deployed the above solution to prod?
+
*Thread Reply:* This was proposed by our AWS Solution architect but we are not seeing much improvement compared to open lineage. Have you deployed the above solution to prod?
@@ -90901,7 +90907,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-05-25 11:30:44
-
*Thread Reply:* We are currently in the research phase, so we have not deployed to prod. We have customers with thousands of existing scripts that they don’t want to rewrite to add openlineage libraries - i would imagine that if you are already integrating OpenLineage in your code, the spark listener isn’t an improvement. Our research is on magically getting lineage from existing scripts 😄
+
*Thread Reply:* We are currently in the research phase, so we have not deployed to prod. We have customers with thousands of existing scripts that they don’t want to rewrite to add openlineage libraries - i would imagine that if you are already integrating OpenLineage in your code, the spark listener isn’t an improvement. Our research is on magically getting lineage from existing scripts 😄
@@ -90962,7 +90968,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-01 10:26:22
-
*Thread Reply:* Thanks, all. The release is authorized and will be initiated as soon as possible.
+
*Thread Reply:* Thanks, all. The release is authorized and will be initiated as soon as possible.
@@ -91014,7 +91020,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-02 05:15:55
-
*Thread Reply:* GitHub has a new issue template for reporting vulnerabilities, actually. If you use a config that enables this issue template.
+
*Thread Reply:* GitHub has a new issue template for reporting vulnerabilities, actually. If you use a config that enables this issue template.
@@ -91202,7 +91208,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-02 20:04:19
-
*Thread Reply:* Hey @Paul Lee, are you seeing this happen for Async operators?
+
*Thread Reply:* Hey @Paul Lee, are you seeing this happen for Async operators?
@@ -91228,7 +91234,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-02 20:06:00
-
*Thread Reply:* might be related to this issue https://github.com/OpenLineage/OpenLineage/pull/1601
+
*Thread Reply:* might be related to this issue https://github.com/OpenLineage/OpenLineage/pull/1601
that was fixed in 0.20.6
@@ -91279,7 +91285,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 16:15:44
-
*Thread Reply:* hmm perhaps.
+
*Thread Reply:* hmm perhaps.
@@ -91305,7 +91311,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 16:15:55
-
*Thread Reply:* @Harel Shein if i want to turn off openlineage listener how do i do that? do i just remove the package?
+
*Thread Reply:* @Harel Shein if i want to turn off openlineage listener how do i do that? do i just remove the package?
@@ -91331,7 +91337,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 16:24:07
-
*Thread Reply:* meaning, you don’t want openlineage to collect any information from your Airflow deployment?
+
*Thread Reply:* meaning, you don’t want openlineage to collect any information from your Airflow deployment?
@@ -91361,7 +91367,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 16:24:50
-
*Thread Reply:* in that case, you could either remove it from your requirements file, or set OPENLINEAGE_DISABLED=True in your Airflow env vars
+
*Thread Reply:* in that case, you could either remove it from your requirements file, or set OPENLINEAGE_DISABLED=True in your Airflow env vars
@@ -91391,7 +91397,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-06 14:43:56
-
*Thread Reply:* removed it from requirements and also the backend key in airflow config. needed both
+
*Thread Reply:* removed it from requirements and also the backend key in airflow config. needed both
@@ -91482,7 +91488,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-02 23:46:08
-
*Thread Reply:* Are you seeing duplicate START events or do you see two events one that is a START and one that is COMPLETE?
+
*Thread Reply:* Are you seeing duplicate START events or do you see two events one that is a START and one that is COMPLETE?
OpenLineage's events may send partial information. You should expect to collect all events for a given RunId and merge them together to get the complete events.
@@ -91512,7 +91518,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 00:45:19
-
*Thread Reply:* Hmm...I'm seeing 2 start events for the same runnable command
+
*Thread Reply:* Hmm...I'm seeing 2 start events for the same runnable command
@@ -91538,7 +91544,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 00:45:27
-
*Thread Reply:* And 2 complete
+
*Thread Reply:* And 2 complete
@@ -91564,7 +91570,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 00:46:08
-
*Thread Reply:* I am currently only testing on parquet tables...
+
*Thread Reply:* I am currently only testing on parquet tables...
@@ -91590,7 +91596,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-03 02:31:28
-
*Thread Reply:* One of openlineage assumptions is the ability to merge lineage events in the backend to make client integrations stateless. So, it is possible that Spark can emit multiple events for the same job. However, sometimes it does not make any sense to send or collect some events, which happened to us some time ago with delta. In that case we decided to filter them and created filtering mechanism (https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/shared/src/main/java/io/openlineage/spark/agent/filters) than can be extended in case of other unwanted events being generated and sent.
+
*Thread Reply:* One of openlineage assumptions is the ability to merge lineage events in the backend to make client integrations stateless. So, it is possible that Spark can emit multiple events for the same job. However, sometimes it does not make any sense to send or collect some events, which happened to us some time ago with delta. In that case we decided to filter them and created filtering mechanism (https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/shared/src/main/java/io/openlineage/spark/agent/filters) than can be extended in case of other unwanted events being generated and sent.
@@ -91616,7 +91622,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-05 22:59:06
-
*Thread Reply:* Ahh I see...okay thanks!
+
*Thread Reply:* Ahh I see...okay thanks!
@@ -91642,7 +91648,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-07 00:05:48
-
*Thread Reply:* in general , you should build any event consumer system with at least once semantics. Even if this issue is fixed, there is a possibility of duplicates for other valid scenarios
+
*Thread Reply:* in general , you should build any event consumer system with at least once semantics. Even if this issue is fixed, there is a possibility of duplicates for other valid scenarios
@@ -91672,7 +91678,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-09 14:10:47
-
*Thread Reply:* Hi..I compared some duplicate 'START' events just now, and noticed that they are exactly the same, with the only exception of one of them having an 'environment-properties' field... Could I just quickly check if this is a bug or a feature haha?
+
*Thread Reply:* Hi..I compared some duplicate 'START' events just now, and noticed that they are exactly the same, with the only exception of one of them having an 'environment-properties' field... Could I just quickly check if this is a bug or a feature haha?
@@ -91698,7 +91704,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-10 01:18:18
-
*Thread Reply:* CC: @Paweł Leszczyński ^
+
*Thread Reply:* CC: @Paweł Leszczyński ^
@@ -91821,7 +91827,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-08 17:30:44
-
*Thread Reply:* if you can set up env variables for particular notebooks, you can set OPENLINEAGE_DISABLED=true
+
*Thread Reply:* if you can set up env variables for particular notebooks, you can set OPENLINEAGE_DISABLED=true
@@ -91976,7 +91982,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-13 17:08:53
-
*Thread Reply:* is DAG run capturing enabled starting airflow 2.5.1 ? https://github.com/apache/airflow/pull/27113
+
*Thread Reply:* is DAG run capturing enabled starting airflow 2.5.1 ? https://github.com/apache/airflow/pull/27113
@@ -92042,7 +92048,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-13 17:11:47
-
*Thread Reply:* you're right, only the change was included in 2.5.0
+
*Thread Reply:* you're right, only the change was included in 2.5.0
@@ -92072,7 +92078,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-13 17:43:15
-
*Thread Reply:* Thanks Jakub
+
*Thread Reply:* Thanks Jakub
@@ -92196,7 +92202,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-15 15:18:22
-
*Thread Reply:* I don’t see it currently on the AirflowRunFacet, but probably not a big deal to add it? @Benji Lampel wdyt?
+
*Thread Reply:* I don’t see it currently on the AirflowRunFacet, but probably not a big deal to add it? @Benji Lampel wdyt?
@@ -92424,7 +92430,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-15 15:22:00
-
*Thread Reply:* Definitely could be a good thing to have--is there not some info facet that could hold this data already? I don't see an issue with adding to the AirflowRunFacet tho (full disclosure, I'm not super familiar with this facet)
+
*Thread Reply:* Definitely could be a good thing to have--is there not some info facet that could hold this data already? I don't see an issue with adding to the AirflowRunFacet tho (full disclosure, I'm not super familiar with this facet)
@@ -92454,7 +92460,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-15 15:58:40
-
*Thread Reply:* Perhaps DocumentationJobFacet or DocumentationDatasetFacet?
+
*Thread Reply:* Perhaps DocumentationJobFacet or DocumentationDatasetFacet?
@@ -92557,7 +92563,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-18 12:09:23
-
*Thread Reply:* dbt-ol does not read from openlineage.yml so you need to pass this information in OPENLINEAGE_NAMESPACE environment variable
+
*Thread Reply:* dbt-ol does not read from openlineage.yml so you need to pass this information in OPENLINEAGE_NAMESPACE environment variable
@@ -92583,7 +92589,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-20 15:17:03
-
*Thread Reply:* Hmmm. Interesting! I thought that it used client = OpenLineageClient.from_environment(), I’ll do some testing with Kafka backends.
+
*Thread Reply:* Hmmm. Interesting! I thought that it used client = OpenLineageClient.from_environment(), I’ll do some testing with Kafka backends.
@@ -92609,7 +92615,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-20 15:22:07
-
*Thread Reply:* Thank you for the hint. I was able to make it work with specifying the env OPENLINEAGE_CONFIGto specify the yml file holding transport info and OPENLINEAGE_NAMESPACE
+
*Thread Reply:* Thank you for the hint. I was able to make it work with specifying the env OPENLINEAGE_CONFIGto specify the yml file holding transport info and OPENLINEAGE_NAMESPACE
@@ -92639,7 +92645,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-20 15:24:05
-
*Thread Reply:* Awesome! That’s exactly what I was going to test.
+
*Thread Reply:* Awesome! That’s exactly what I was going to test.
@@ -92665,7 +92671,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-20 15:25:04
-
*Thread Reply:* I think it also works if you put it in $HOME/.openlineage/openlineage.yml.
+
*Thread Reply:* I think it also works if you put it in $HOME/.openlineage/openlineage.yml.
@@ -92695,7 +92701,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-21 08:32:17
-
*Thread Reply:* @Susmitha Anandarao I might have provided misleading information. I meant that dbt-ol does not read OL namespace from openlineage.yml but from OPENLINEAGE_NAMESPACE env var instead
+
*Thread Reply:* @Susmitha Anandarao I might have provided misleading information. I meant that dbt-ol does not read OL namespace from openlineage.yml but from OPENLINEAGE_NAMESPACE env var instead
@@ -92893,7 +92899,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-23 04:25:19
-
*Thread Reply:* It should be represented by multiple datasets, unless I misunderstood what you mean by multi-table
+
*Thread Reply:* It should be represented by multiple datasets, unless I misunderstood what you mean by multi-table
@@ -92919,7 +92925,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-23 10:55:58
-
*Thread Reply:* here at Fivetran when we sync data it is generally 1 schema with multiple tables (sometimes many) so we would want to represent all of that
+
*Thread Reply:* here at Fivetran when we sync data it is generally 1 schema with multiple tables (sometimes many) so we would want to represent all of that
@@ -92945,7 +92951,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-23 11:11:25
-
*Thread Reply:* So what I understand:
+
*Thread Reply:* So what I understand:
- your single job represents synchronization of multiple tables
- you want to have precise input-output dataset lineage?
am I right?
@@ -92979,7 +92985,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-23 12:57:15
-
*Thread Reply:* Yes your statements are correct. Thanks for sharing that model, that makes sense to me
+
*Thread Reply:* Yes your statements are correct. Thanks for sharing that model, that makes sense to me
@@ -93052,7 +93058,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-27 05:26:06
-
*Thread Reply:* I think it's better to just create POJO. This is what we do in Spark integration, for example.
+
*Thread Reply:* I think it's better to just create POJO. This is what we do in Spark integration, for example.
For now, JSON Schema generator isn't flexible enough to generate custom facets from whatever schema we give it, so it would be unnecessary complexity
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-27 12:29:57
-
*Thread Reply:* Agreed, just a POJO would work. This is using Jackson, so you would use annotations as needed. You can also use a Jackson JSONNode or even Map.
+
*Thread Reply:* Agreed, just a POJO would work. This is using Jackson, so you would use annotations as needed. You can also use a Jackson JSONNode or even Map.
@@ -93165,7 +93171,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-27 17:59:28
-
*Thread Reply:* That depends on the OL consumer, but for something like SchemaDatasetFacet it seems to be okay to assume schema stays the same if not send.
+
*Thread Reply:* That depends on the OL consumer, but for something like SchemaDatasetFacet it seems to be okay to assume schema stays the same if not send.
For others, like OutputStatisticsOutputDatasetFacet you definitely can't assume that, as the data is unique to each run.
@@ -93193,7 +93199,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-27 19:05:14
-
*Thread Reply:* ok great thanks, that makes sense to me
+
*Thread Reply:* ok great thanks, that makes sense to me
@@ -93254,7 +93260,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-28 04:47:31
-
*Thread Reply:* OpenLineage API: https://openlineage.io/docs/getting-started/
+
*Thread Reply:* OpenLineage API: https://openlineage.io/docs/getting-started/
openlineage.io
@@ -93327,7 +93333,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-28 08:05:30
-
*Thread Reply:* I think it would be great to support V2SessionCatalog, and it would very much help if you created GitHub issue with more explanation and examples of it's use.
+
*Thread Reply:* I think it would be great to support V2SessionCatalog, and it would very much help if you created GitHub issue with more explanation and examples of it's use.
@@ -93353,7 +93359,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-29 02:53:37
-
*Thread Reply:* Sure thanks!
+
*Thread Reply:* Sure thanks!
@@ -93379,7 +93385,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-03-29 05:34:37
-
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1747
+
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1747
I have opened an issue here. Thanks! 🙂
@@ -93437,7 +93443,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-17 11:53:52
-
*Thread Reply:* Hi @Maciej Obuchowski Just curious, is this issue on the potential roadmap for the next Openlineage release?
+
*Thread Reply:* Hi @Maciej Obuchowski Just curious, is this issue on the potential roadmap for the next Openlineage release?
@@ -93516,7 +93522,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-03 09:32:46
-
*Thread Reply:* The blog post is a bit old and in the meantime there were changes in OpenLineage Python Client introduced.
+
*Thread Reply:* The blog post is a bit old and in the meantime there were changes in OpenLineage Python Client introduced.
May I ask if you want just to test the flow or looking for any viable Snowflake data lineage solution?
@@ -93543,7 +93549,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-03 10:47:57
-
*Thread Reply:* I believe that this will work if you change the line to client.transport.emit()
+
*Thread Reply:* I believe that this will work if you change the line to client.transport.emit()
@@ -93569,7 +93575,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-03 10:49:05
-
*Thread Reply:* (this would be in the dags/lineage folder, if memory serves)
+
*Thread Reply:* (this would be in the dags/lineage folder, if memory serves)
@@ -93595,7 +93601,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-03 10:57:23
-
*Thread Reply:* Ross is right, that should work
+
*Thread Reply:* Ross is right, that should work
@@ -93621,7 +93627,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 12:23:13
-
*Thread Reply:* This works! Thank you so much!
+
*Thread Reply:* This works! Thank you so much!
@@ -93647,7 +93653,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 12:24:40
-
*Thread Reply:* @Jakub Dardziński I want to use a viable Snowflake data lineage solution alongside a Amazon DataZone Catalog 🙂
+
*Thread Reply:* @Jakub Dardziński I want to use a viable Snowflake data lineage solution alongside a Amazon DataZone Catalog 🙂
@@ -93673,7 +93679,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 13:03:58
-
*Thread Reply:* I have been meaning to revisit that tutorial 👍
+
*Thread Reply:* I have been meaning to revisit that tutorial 👍
@@ -93740,7 +93746,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-03 15:39:46
-
*Thread Reply:* Thanks, all. The release is authorized and will be initiated within 48 hours.
+
*Thread Reply:* Thanks, all. The release is authorized and will be initiated within 48 hours.
@@ -93901,7 +93907,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 13:39:19
-
*Thread Reply:* Do you have small configuration and job to replicate this?
+
*Thread Reply:* Do you have small configuration and job to replicate this?
@@ -93927,7 +93933,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 22:21:35
-
*Thread Reply:* Yeah. For configs:
+
*Thread Reply:* Yeah. For configs:
spark.driver.bindAddress: "localhost"
spark.master: "local[**]"
spark.sql.catalogImplementation: "hive"
@@ -93963,7 +93969,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 22:23:19
-
*Thread Reply:* The issue is because of the spark.jars.packages config... spark.jars config also runs into the same issue. Because the executor tries to fetch the jar from driver for some reason even though there is no executors set...
+
*Thread Reply:* The issue is because of the spark.jars.packages config... spark.jars config also runs into the same issue. Because the executor tries to fetch the jar from driver for some reason even though there is no executors set...
@@ -93989,7 +93995,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-05 05:38:55
-
*Thread Reply:* TBH I'm not sure if we can do anything about it. Seems like just having any SparkListener which is not in Spark jars would fall under the same problems, right?
+
*Thread Reply:* TBH I'm not sure if we can do anything about it. Seems like just having any SparkListener which is not in Spark jars would fall under the same problems, right?
@@ -94015,7 +94021,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-10 06:07:11
-
*Thread Reply:* Yeah... Actually, this was because of binding the driver ip to localhost. In that case, the executor was not able to get the jar from the driver. But yeah I don't think we could have done anything from openlienage end anyway for this. Was just an interesting error to encounter lol
+
*Thread Reply:* Yeah... Actually, this was because of binding the driver ip to localhost. In that case, the executor was not able to get the jar from the driver. But yeah I don't think we could have done anything from openlienage end anyway for this. Was just an interesting error to encounter lol
@@ -94067,7 +94073,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 13:02:21
-
*Thread Reply:* In this case you would have four runevents:
+
*Thread Reply:* In this case you would have four runevents:
- a
START event on my-job where my-input is the input and my-output is the output, with a runId you generate on the client - a
COMPLETE event on my-job with the same runId from #1 - a
START event on my-job2 where the input is my-output and the output is my-final-output, with a separate runId you generate - a
COMPLETE event on my-job2 with the same runId from #3
@@ -94096,7 +94102,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 14:53:14
-
*Thread Reply:* thanks for the response. I tried it but now the UI only shows like one second and then turn to blank. I has similar issue before. It seems to me every time when I added a bad lineage, the UI stops working. I have to delete the docker image:-( Not sure whether it is MacOS M1 related issue.
+
*Thread Reply:* thanks for the response. I tried it but now the UI only shows like one second and then turn to blank. I has similar issue before. It seems to me every time when I added a bad lineage, the UI stops working. I have to delete the docker image:-( Not sure whether it is MacOS M1 related issue.
@@ -94122,7 +94128,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 16:07:06
-
*Thread Reply:* Hmmm, that's interesting. Not sure I've seen that before. If you happen to catch it in that state again, perhaps capture the contents of the lineage_events table so it can be replicated.
+
*Thread Reply:* Hmmm, that's interesting. Not sure I've seen that before. If you happen to catch it in that state again, perhaps capture the contents of the lineage_events table so it can be replicated.
@@ -94148,7 +94154,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-04 16:24:28
-
*Thread Reply:* I can fairly easy to reproduce this blank UI issue. Apparently I used the same runId for two different jobs. If I use different unId (which I should), the lineage displays correctly. Thanks again!
+
*Thread Reply:* I can fairly easy to reproduce this blank UI issue. Apparently I used the same runId for two different jobs. If I use different unId (which I should), the lineage displays correctly. Thanks again!
@@ -94213,7 +94219,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-05 05:35:02
-
*Thread Reply:* You can add https://openlineage.io/docs/spec/facets/dataset-facets/column_lineage_facet/ to your datasets.
+
*Thread Reply:* You can add https://openlineage.io/docs/spec/facets/dataset-facets/column_lineage_facet/ to your datasets.
However, I don't think you can currently do any filtering over it
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-05 13:20:20
-
*Thread Reply:* you can see a good example here, @Lq Dodo: https://github.com/MarquezProject/marquez/blob/289fa3eef967c8f7915b074325bb6f8f55480030/docker/metadata.json#L430
+
*Thread Reply:* you can see a good example here, @Lq Dodo: https://github.com/MarquezProject/marquez/blob/289fa3eef967c8f7915b074325bb6f8f55480030/docker/metadata.json#L430
@@ -94313,7 +94319,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-06 11:48:48
-
*Thread Reply:* those examples really help. I can at least build the lineage with column level info using the apis. thanks a lot! Ideally I'd like select one column from the UI and then show me the column level graph. Seems not possible.
+
*Thread Reply:* those examples really help. I can at least build the lineage with column level info using the apis. thanks a lot! Ideally I'd like select one column from the UI and then show me the column level graph. Seems not possible.
@@ -94339,7 +94345,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-06 12:46:54
-
*Thread Reply:* correct, right now there isn't column-level metadata on the lineage graph 😞
+
*Thread Reply:* correct, right now there isn't column-level metadata on the lineage graph 😞
@@ -94393,7 +94399,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-06 10:22:17
-
*Thread Reply:* something needs to trigger lineage collection, are you using some sort of scheduler / execution engine?
+
*Thread Reply:* something needs to trigger lineage collection, are you using some sort of scheduler / execution engine?
@@ -94419,7 +94425,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-06 11:26:13
-
*Thread Reply:* Nope... We currently don't have scheduling tool. Isn't it possible to use open lineage api and collect the details?
+
*Thread Reply:* Nope... We currently don't have scheduling tool. Isn't it possible to use open lineage api and collect the details?
@@ -94609,7 +94615,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-07 12:50:14
-
*Thread Reply:* E.g. do I need to update my custom operators to inherit from DefaultExtractor?
+
*Thread Reply:* E.g. do I need to update my custom operators to inherit from DefaultExtractor?
@@ -94635,7 +94641,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-07 13:18:05
-
*Thread Reply:* FWIW, I can tell some level of connectivity to my Marquez deployment is working since I can see it created the default namespace I defined in my OPENLINEAGE_NAMESPACE env var.
+
*Thread Reply:* FWIW, I can tell some level of connectivity to my Marquez deployment is working since I can see it created the default namespace I defined in my OPENLINEAGE_NAMESPACE env var.
@@ -94661,7 +94667,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-07 18:37:44
-
*Thread Reply:* hey John, it is enough to add the method to your custom operator. Perhaps something breaks inside the method. Did anything show up in the logs?
+
*Thread Reply:* hey John, it is enough to add the method to your custom operator. Perhaps something breaks inside the method. Did anything show up in the logs?
@@ -94687,7 +94693,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-07 19:03:01
-
*Thread Reply:* That’s the strange part. I’m not seeing anything to suggest that the method is ever getting called. I’m also expecting that the listener created by the plugin should at least be calling this log line when the task runs. However, I’m not seeing that either. I’m able to verify the plugin is registered using airflow plugins and have debug level logging enabled via AIRFLOW__LOGGING__LOGGING_LEVEL='DEBUG'. This is the output of airflow plugins
+
*Thread Reply:* That’s the strange part. I’m not seeing anything to suggest that the method is ever getting called. I’m also expecting that the listener created by the plugin should at least be calling this log line when the task runs. However, I’m not seeing that either. I’m able to verify the plugin is registered using airflow plugins and have debug level logging enabled via AIRFLOW__LOGGING__LOGGING_LEVEL='DEBUG'. This is the output of airflow plugins
name | macros | listeners | source
==================+================================================+==============================+=================================================
@@ -94746,7 +94752,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-11 13:09:05
-
*Thread Reply:* Figured this out. Just needed to run the airflow scheduler and trigger tasks through the DAGs vs. airflow tasks test …
+
*Thread Reply:* Figured this out. Just needed to run the airflow scheduler and trigger tasks through the DAGs vs. airflow tasks test …
@@ -94800,7 +94806,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-07 16:30:00
-
*Thread Reply:* (they are importing dagkit sdk stuff like Job, JobContext, ExecutionContext, and NodeContext.)
+
*Thread Reply:* (they are importing dagkit sdk stuff like Job, JobContext, ExecutionContext, and NodeContext.)
@@ -94826,7 +94832,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-07 18:40:39
-
*Thread Reply:* Do they run those scripts in PythonOperator? If so, they should receive some events but with no datasets extracted
+
*Thread Reply:* Do they run those scripts in PythonOperator? If so, they should receive some events but with no datasets extracted
@@ -94852,7 +94858,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-07 21:28:25
-
*Thread Reply:* How can I know that? Would it be in the scripts or the airflow configuration or...
+
*Thread Reply:* How can I know that? Would it be in the scripts or the airflow configuration or...
@@ -94878,7 +94884,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-08 07:13:56
-
*Thread Reply:* And "with no datasets extracted" that means I wouldn't have the schema of the input and output datasets? (I need the db/schema/table/column names for my purposes)
+
*Thread Reply:* And "with no datasets extracted" that means I wouldn't have the schema of the input and output datasets? (I need the db/schema/table/column names for my purposes)
@@ -94904,7 +94910,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-11 02:49:07
-
*Thread Reply:* That really depends what is the current code but in general any custom code in Airflow does not extract any extra information, especially datasets. One can write their own extractors (more in the docs)
+
*Thread Reply:* That really depends what is the current code but in general any custom code in Airflow does not extract any extra information, especially datasets. One can write their own extractors (more in the docs)
openlineage.io
@@ -94955,7 +94961,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-12 16:52:04
-
*Thread Reply:* Thanks! This is very helpful. Exactly what I needed.
+
*Thread Reply:* Thanks! This is very helpful. Exactly what I needed.
@@ -95011,7 +95017,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-12 02:30:19
-
*Thread Reply:* Currently there's no extractor implemented for MS-SQL. We try to update list of supported databases here: https://openlineage.io/docs/integrations/about/
+
*Thread Reply:* Currently there's no extractor implemented for MS-SQL. We try to update list of supported databases here: https://openlineage.io/docs/integrations/about/
openlineage.io
@@ -95297,7 +95303,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-11 17:05:35
-
*Thread Reply:* > The snowflake.connector import connect package seems to be outdated here in extract_openlineage.py and is not working for airflow.
+
*Thread Reply:* > The snowflake.connector import connect package seems to be outdated here in extract_openlineage.py and is not working for airflow.
What's the error?
> Does anyone know how to rewrite this code (e.g., with SnowflakeOperator )
@@ -95429,7 +95435,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-11 18:13:49
-
*Thread Reply:* Hi Maciej!Thank you so much for the reply! I managed to generate a working combination on Windows between the airflow example in the marquez git and the snowflake openlineage git. The only error I still get is:
+
*Thread Reply:* Hi Maciej!Thank you so much for the reply! I managed to generate a working combination on Windows between the airflow example in the marquez git and the snowflake openlineage git. The only error I still get is:
****** Log file does not exist: /opt/bitnami/airflow/logs/dag_id=etl_openlineage/run_id=manual__2023-04-10T14:12:53.764783+00:00/task_id=send_ol_events/attempt=1.log
****** Fetching from: <http://1c8bb4a78f14:8793/log/dag_id=etl_openlineage/run_id=manual__2023-04-10T14:12:53.764783+00:00/task_id=send_ol_events/attempt=1.log>
****** !!!! Please make sure that all your Airflow components (e.g. schedulers, webservers and workers) have the same 'secret_key' configured in 'webserver' section and time is synchronized on all your machines (for example with ntpd) !!!!!
@@ -95462,7 +95468,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-12 05:35:41
-
*Thread Reply:* I think it's Airflow error related to getting logs from worker
+
*Thread Reply:* I think it's Airflow error related to getting logs from worker
@@ -95488,7 +95494,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-12 05:36:07
-
*Thread Reply:* snowflake.connector is a Snowflake connector library that SnowflakeOperator uses underneath to connect to Snowflake
+
*Thread Reply:* snowflake.connector is a Snowflake connector library that SnowflakeOperator uses underneath to connect to Snowflake
@@ -95514,7 +95520,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-12 10:15:21
-
*Thread Reply:* Ah alright! Thanks for pointing that out! 🙂 Do you know how to solve it? Or do you have any recommendations on how to look for the solution?
+
*Thread Reply:* Ah alright! Thanks for pointing that out! 🙂 Do you know how to solve it? Or do you have any recommendations on how to look for the solution?
@@ -95540,7 +95546,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-12 10:19:53
-
*Thread Reply:* I have no experience with Windows, and I think it's the issue: https://github.com/apache/airflow/issues/10388
+
*Thread Reply:* I have no experience with Windows, and I think it's the issue: https://github.com/apache/airflow/issues/10388
I would try running it in Docker TBH
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-12 11:47:41
-
*Thread Reply:* Yeah I was running Airflow in Docker but this didn't work. I'll try to use my Macbook for now because I don't think there is a solution for this in the short time. Thank you so much for the support though!!
+
*Thread Reply:* Yeah I was running Airflow in Docker but this didn't work. I'll try to use my Macbook for now because I don't think there is a solution for this in the short time. Thank you so much for the support though!!
@@ -95729,7 +95735,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-13 11:19:57
-
*Thread Reply:* Very interesting!
+
*Thread Reply:* Very interesting!
@@ -95755,7 +95761,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-13 13:28:53
-
*Thread Reply:* that’s awesome 🙂
+
*Thread Reply:* that’s awesome 🙂
@@ -95807,7 +95813,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-13 08:36:01
-
*Thread Reply:* Thanks Ernie, I’m looking at Airflow as well as GE and would like to contribute back to the project as well… we’re close to getting a public preview release of our product done and then we want to help build out open lineage
+
*Thread Reply:* Thanks Ernie, I’m looking at Airflow as well as GE and would like to contribute back to the project as well… we’re close to getting a public preview release of our product done and then we want to help build out open lineage
@@ -95863,7 +95869,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-13 14:10:08
-
*Thread Reply:* The dag is basically just:
+
*Thread Reply:* The dag is basically just:
```dag = DAG(
dagid="asanaexampledag",
defaultargs=defaultargs,
@@ -95902,7 +95908,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-13 14:11:02
-
*Thread Reply:* This is the error I’m getting, seems to be coming from this line:
+
*Thread Reply:* This is the error I’m getting, seems to be coming from this line:
[2023-04-13, 17:45:33 UTC] {logging_mixin.py:115} WARNING - Exception in thread Thread-1:
Traceback (most recent call last):
File "/opt/conda/lib/python3.7/threading.py", line 926, in _bootstrap_inner
@@ -96024,7 +96030,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-13 14:12:11
-
*Thread Reply:* This is with Airflow 2.3.2 and openlineage-airflow 0.22.0
+
*Thread Reply:* This is with Airflow 2.3.2 and openlineage-airflow 0.22.0
@@ -96050,7 +96056,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-13 14:13:34
-
*Thread Reply:* Seems like it might be some issue like this with a circular structure? https://stackoverflow.com/questions/46283738/attributeerror-when-using-python-deepcopy
+
*Thread Reply:* Seems like it might be some issue like this with a circular structure? https://stackoverflow.com/questions/46283738/attributeerror-when-using-python-deepcopy
Stack Overflow
@@ -96101,7 +96107,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 08:44:36
-
*Thread Reply:* Just by quick look at it, it will definitely be fixed with Airflow 2.6, as it won't need to deepcopy anything.
+
*Thread Reply:* Just by quick look at it, it will definitely be fixed with Airflow 2.6, as it won't need to deepcopy anything.
@@ -96131,7 +96137,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 08:47:16
-
*Thread Reply:* I can't seem to reproduce the issue. I ran following example DAG with same Airflow and OL versions as yours:
+
*Thread Reply:* I can't seem to reproduce the issue. I ran following example DAG with same Airflow and OL versions as yours:
```import datetime
from airflow.lineage.entities import Table
@@ -96180,7 +96186,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 08:53:48
-
*Thread Reply:* is there any extra configuration you made possibly?
+
*Thread Reply:* is there any extra configuration you made possibly?
@@ -96206,7 +96212,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 13:02:40
-
*Thread Reply:* @John Lukenoff, I was finally able to reproduce this when passing xcom as task.output
+
*Thread Reply:* @John Lukenoff, I was finally able to reproduce this when passing xcom as task.output
looks like this was reported here and solved by this PR (not sure if this was released in 2.3.3 or later)
@@ -96281,7 +96287,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 13:06:59
-
*Thread Reply:* Ah interesting. Let me see if bumping my Airflow version resolves this. Haven’t had a chance to tinker with it much since yesterday.
+
*Thread Reply:* Ah interesting. Let me see if bumping my Airflow version resolves this. Haven’t had a chance to tinker with it much since yesterday.
@@ -96307,7 +96313,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 13:13:21
-
*Thread Reply:* I ran it against 2.4 and same dag works
+
*Thread Reply:* I ran it against 2.4 and same dag works
@@ -96333,7 +96339,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 13:15:35
-
*Thread Reply:* 👍 Looks like a fix for that issue was rolled out in 2.3.3. I’m gonna try that for now (my company has a notoriously difficult time with airflow major version updates 😅)
+
*Thread Reply:* 👍 Looks like a fix for that issue was rolled out in 2.3.3. I’m gonna try that for now (my company has a notoriously difficult time with airflow major version updates 😅)
@@ -96359,7 +96365,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-14 13:17:06
-
*Thread Reply:* 👍
+
*Thread Reply:* 👍
@@ -96385,7 +96391,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-17 12:29:09
-
*Thread Reply:* Got this working! We just monkey patched the __deepcopy__ method of the BaseOperator for now until we can get bandwidth for an airflow upgrade. Thanks for the help here!
+
*Thread Reply:* Got this working! We just monkey patched the __deepcopy__ method of the BaseOperator for now until we can get bandwidth for an airflow upgrade. Thanks for the help here!
@@ -96458,7 +96464,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-17 03:56:30
-
*Thread Reply:* This is the spark submit command:
+
*Thread Reply:* This is the spark submit command:
spark-submit --py-files /usr/local/lib/common_utils.zip,/usr/local/lib/team_utils.zip,/usr/local/lib/project_utils.zip
--conf spark.executor.cores=16
--conf spark.hadoop.fs.s3a.connection.maximum=100 --conf spark.sql.shuffle.partitions=1000
@@ -96489,7 +96495,7 @@ MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-17 04:09:57
-
*Thread Reply:* @Anirudh Shrinivason pls create an issue for this and I will look at it. Although it may be difficult to find the root cause, null pointer exception should be always avoided and this seems to be a bug.
+
*Thread Reply:* @Anirudh Shrinivason pls create an issue for this and I will look at it. Although it may be difficult to find the root cause, null pointer exception should be always avoided and this seems to be a bug.
@@ -96515,7 +96521,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-17 04:14:41
-
*Thread Reply:* Hmm yeah sure. I'll create an issue on github for this issue. Thanks!
+
*Thread Reply:* Hmm yeah sure. I'll create an issue on github for this issue. Thanks!
@@ -96541,7 +96547,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-17 05:13:54
-
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1784
+
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1784
Opened an issue here
@@ -96626,7 +96632,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-18 02:25:04
-
*Thread Reply:* Hi @Allison Suarez, CustomColumnLineageVisitor should be definitely public. I'll prepare a fix PR for that. We do have a test for custom column lineage visitors (CustomColumnLineageVisitorTestImpl), but they're in the same package. Thanks for bringing this.
+
*Thread Reply:* Hi @Allison Suarez, CustomColumnLineageVisitor should be definitely public. I'll prepare a fix PR for that. We do have a test for custom column lineage visitors (CustomColumnLineageVisitorTestImpl), but they're in the same package. Thanks for bringing this.
@@ -96652,7 +96658,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-18 03:07:11
-
*Thread Reply:* This PR should resolve problem:
+
*Thread Reply:* This PR should resolve problem:
https://github.com/OpenLineage/OpenLineage/pull/1788
@@ -96740,7 +96746,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-18 13:34:43
-
*Thread Reply:* Thank you so much @Paweł Leszczyński 🙂
+
*Thread Reply:* Thank you so much @Paweł Leszczyński 🙂
@@ -96766,7 +96772,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-18 13:35:46
-
*Thread Reply:* How does the release process work for OL? Do we have to wait a certain amount of time to get this change in a new release?
+
*Thread Reply:* How does the release process work for OL? Do we have to wait a certain amount of time to get this change in a new release?
@@ -96792,7 +96798,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-18 17:34:29
-
*Thread Reply:* @Maciej Obuchowski ^
+
*Thread Reply:* @Maciej Obuchowski ^
@@ -96818,7 +96824,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-19 01:49:33
-
*Thread Reply:* 0.22.0 was released two weeks ago, so the next schedule should be in next two weeks. We can ask @Michael Robinson his opinion on releasing 0.22.1 before that.
+
*Thread Reply:* 0.22.0 was released two weeks ago, so the next schedule should be in next two weeks. We can ask @Michael Robinson his opinion on releasing 0.22.1 before that.
@@ -96844,7 +96850,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-19 09:08:58
-
*Thread Reply:* Hi Allison 👋,
+
*Thread Reply:* Hi Allison 👋,
Anyone can request a release in the #general channel. I encourage you to go this route. You’ll need three +1s (there’s more info about the process here: https://github.com/OpenLineage/OpenLineage/blob/main/GOVERNANCE.md), but I don’t know of any reasons why we can’t do a mid-cycle release. 🙂
@@ -96875,7 +96881,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-19 16:23:20
-
*Thread Reply:* seems like we got enough +1s
+
*Thread Reply:* seems like we got enough +1s
@@ -96901,7 +96907,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-19 16:24:33
-
*Thread Reply:* We need three committers to give a +1. I’ll reach out again to see if I can recruit a third
+
*Thread Reply:* We need three committers to give a +1. I’ll reach out again to see if I can recruit a third
@@ -96931,7 +96937,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-19 16:24:55
-
*Thread Reply:* oooh
+
*Thread Reply:* oooh
@@ -96957,7 +96963,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-19 16:32:47
-
*Thread Reply:* Yeah, sorry I forgot to mention that!
+
*Thread Reply:* Yeah, sorry I forgot to mention that!
@@ -96983,7 +96989,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 05:02:46
-
*Thread Reply:* we have it now
+
*Thread Reply:* we have it now
@@ -97138,7 +97144,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:46:06
-
*Thread Reply:* The release is authorized and will be initiated within 2 business days (not including tomorrow).
+
*Thread Reply:* The release is authorized and will be initiated within 2 business days (not including tomorrow).
@@ -97246,7 +97252,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 08:57:45
-
*Thread Reply:* Hi Sai,
+
*Thread Reply:* Hi Sai,
Perhaps you could try within printing OpenLineage events into logs. This can be achieved with Spark config parameter:
spark.openlineage.transport.type
@@ -97278,7 +97284,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:18:53
-
*Thread Reply:* Hi @Paweł Leszczyński I passed this config as below, but could not see any changes in the logs. The events are getting generated sometimes like below:
+
*Thread Reply:* Hi @Paweł Leszczyński I passed this config as below, but could not see any changes in the logs. The events are getting generated sometimes like below:
23/04/20 10:00:15 INFO ConsoleTransport: {"eventType":"START","eventTime":"2023-04-20T10:00:15.085Z","run":{"runId":"ef4f46d1-d13a-420a-87c3-19fbf6ffa231","facets":{"spark.logicalPlan":{"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.22.0/integration/spark","schemaURL":"https://openlineage.io/spec/1-0-5/OpenLineage.json#/$defs/RunFacet","plan":[{"class":"org.apache.spark.sql.catalyst.plans.logical.CreateTableAsSelect","num-children":2,"name":0,"partitioning":[],"query":1,"tableSpec":null,"writeOptions":null,"ignoreIfExists":false},{"class":"org.apache.spark.sql.catalyst.analysis.ResolvedTableName","num-children":0,"catalog":null,"ident":null},{"class":"org.apache.spark.sql.catalyst.plans.logical.Project","num-children":1,"projectList":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num_children":0,"name":"workorderid","dataType":"integer","nullable":true,"metadata":{},"exprId":{"product-cl
@@ -97315,7 +97321,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:19:37
-
*Thread Reply:* Ok, great. This means the issue is related to Spark <-> Marquez connection
+
*Thread Reply:* Ok, great. This means the issue is related to Spark <-> Marquez connection
@@ -97341,7 +97347,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:20:33
2023-04-20 09:21:10
-
*Thread Reply:* please note that spark.openlineage.transport.url has to be used which is different from what you have on screenshot attached
+
*Thread Reply:* please note that spark.openlineage.transport.url has to be used which is different from what you have on screenshot attached
@@ -97393,7 +97399,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:22:40
-
*Thread Reply:* You mean instead of "spark.openlineage.host" I need to use "spark.openlineage.transport.url"?
+
*Thread Reply:* You mean instead of "spark.openlineage.host" I need to use "spark.openlineage.transport.url"?
@@ -97419,7 +97425,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:23:04
-
*Thread Reply:* yes, please give it a try
+
*Thread Reply:* yes, please give it a try
@@ -97445,7 +97451,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:23:40
-
*Thread Reply:* sure will give a try and let you know the outcome
+
*Thread Reply:* sure will give a try and let you know the outcome
@@ -97471,7 +97477,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:23:48
-
*Thread Reply:* and set spark.openlineage.transport.type to http
+
*Thread Reply:* and set spark.openlineage.transport.type to http
@@ -97497,7 +97503,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:24:04
-
*Thread Reply:* okay
+
*Thread Reply:* okay
@@ -97523,7 +97529,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:26:42
-
*Thread Reply:* does these configs suffice or I need to add anything else
+
*Thread Reply:* does these configs suffice or I need to add anything else
spark.extraListeners io.openlineage.spark.agent.OpenLineageSparkListener
spark.openlineage.consoleTransport true
@@ -97555,7 +97561,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:27:07
-
*Thread Reply:* spark.openlineage.consoleTransport true this one can be removed
+
*Thread Reply:* spark.openlineage.consoleTransport true this one can be removed
@@ -97581,7 +97587,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 09:27:33
-
*Thread Reply:* otherwise shall be OK
+
*Thread Reply:* otherwise shall be OK
@@ -97607,7 +97613,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 10:01:30
-
*Thread Reply:* I added these configs and run, but still same issue. Now I am not able to see the events in log file as well.
+
*Thread Reply:* I added these configs and run, but still same issue. Now I am not able to see the events in log file as well.
@@ -97633,7 +97639,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-20 10:04:27
-
*Thread Reply:* 23/04/20 13:51:22 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionStart
+
*Thread Reply:* 23/04/20 13:51:22 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionStart
23/04/20 13:51:22 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionEnd
Does this need any changes in the config side?
@@ -97773,7 +97779,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-24 06:49:43
-
*Thread Reply:* @Anirudh Shrinivason Thanks for linking this as it contains a clear explanation on Spark catalogs. However, I am still unable to write a failing integration test that reproduces the scenario. Could you provide an example of Spark which is failing on V2SessionCatalog and provide more details how are you trying to read/write data?
+
*Thread Reply:* @Anirudh Shrinivason Thanks for linking this as it contains a clear explanation on Spark catalogs. However, I am still unable to write a failing integration test that reproduces the scenario. Could you provide an example of Spark which is failing on V2SessionCatalog and provide more details how are you trying to read/write data?
@@ -97799,7 +97805,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-24 07:14:04
-
*Thread Reply:* Hi @Paweł Leszczyński I noticed this issue on one of our pipelines before actually. I didn't note down which pipeline the issue was occuring in unfortunately. I'll keep checking from my end to identify the spark job that ran into this error. In the meantime, I'll also try to see for which cases deltaCatalog makes use of the V2SessionCatalog to understand this better. Thanks!
+
*Thread Reply:* Hi @Paweł Leszczyński I noticed this issue on one of our pipelines before actually. I didn't note down which pipeline the issue was occuring in unfortunately. I'll keep checking from my end to identify the spark job that ran into this error. In the meantime, I'll also try to see for which cases deltaCatalog makes use of the V2SessionCatalog to understand this better. Thanks!
@@ -97825,7 +97831,7 @@
MARQUEZAPIKEY=[YOURAPIKEY]
2023-04-26 03:44:15
-
*Thread Reply:* Hi @Paweł Leszczyński
+
*Thread Reply:* Hi @Paweł Leszczyński
'''
CREATE TABLE IF NOT EXISTS TABLE_NAME (
SOME COLUMNS
@@ -97863,7 +97869,7 @@ MARQUEZ
 +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + <a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
+
+ <a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
+  +
+
+
+
+
+  + }
+
+ }
+  +
+  +
+  +
+ 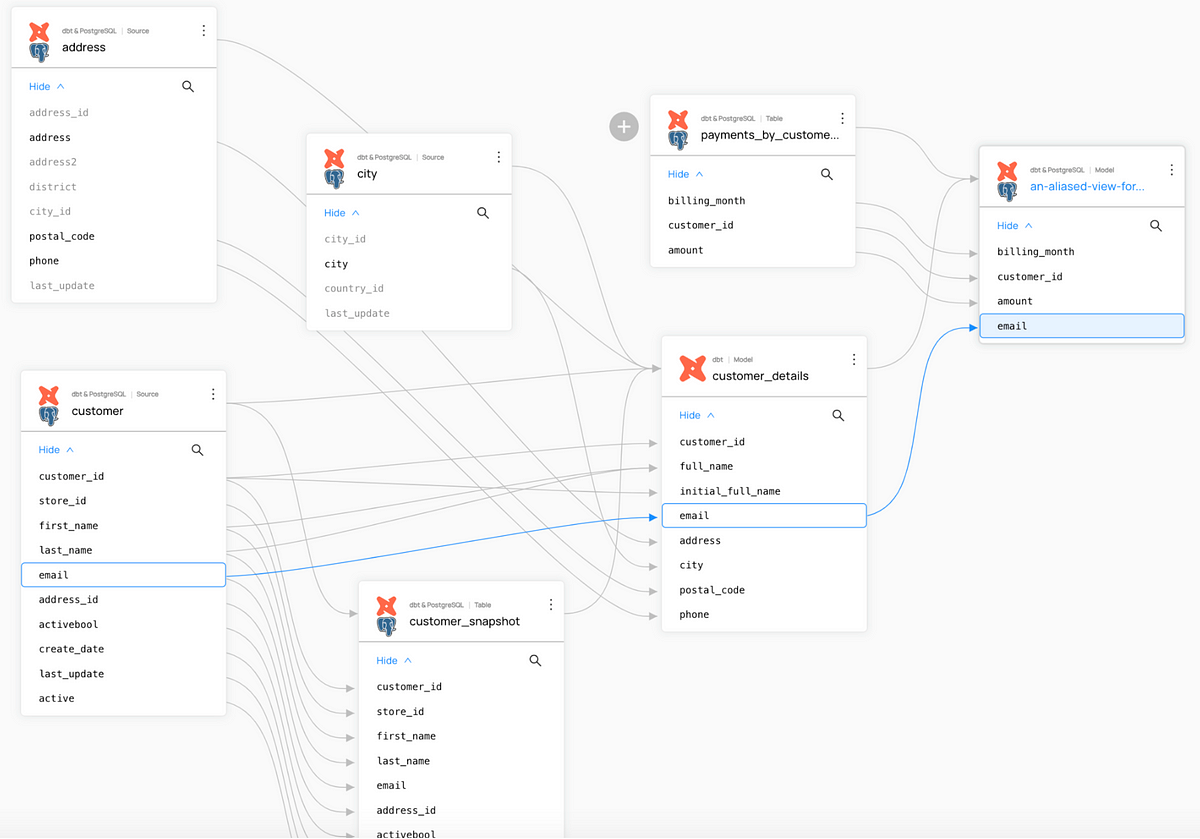 +
+  +
+  + }
+
+ }
+  +
+
+
+
+
+  + }
+
+ }
+  + }
+
+ }
+  +
+  +
+
+
+
+
+  +
+  + }
+
+ }
+  +
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+  +
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+ {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}