+
+  +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Is there a linkedin post about the Boston meetup I can share? or should i make one?
+ + + + +
+
+
+
+
+ Feel free to make one! There isn't one yet
+ + + + +
+
+
+
+
+ @Rajesh has joined the channel
+ + + +
+
+
+ New to Boston Meetup - Hello all
+ + + +One final question - should we make the dagster unit test job “required” in the ci and how can that be configured?
diff --git a/channel/dev-discuss/index.html b/channel/dev-discuss/index.html index 237ae38..26ccc1f 100644 --- a/channel/dev-discuss/index.html +++ b/channel/dev-discuss/index.html @@ -1149,11 +1149,15 @@is it time to support hudi?
@@ -2452,11 +2456,15 @@The full project history is now available at https://openlineage.github.io/slack-archives/. Check it out!
@@ -3357,6 +3365,55 @@ +
+
+
+
+
+  +
+
+
+
+
+
+
+ Feedback requested on the newsletter:
 +
@@ -4562,12 +4619,12 @@
+
@@ -4562,12 +4619,12 @@ *Thread Reply:* it’s open source, should we consider testing it out?
 +
@@ -8169,6 +8226,216 @@
+
@@ -8169,6 +8226,216 @@  +
+
+
+
+
+ *Thread Reply:* Hi All, I am one of the owners of this repo and working to update this to work with MWAA 2.8.1, with apache-airflow-providers-openlineage==1.4.0. I am facing an issue with my set-up. I am using Redshift SQL as a sample use-case for this and getting an error relating to the Default Extractor. Haven't really looked at this at much detail yet but wondering if you have thoughts? I just updated the env variables to use: AIRFLOWOPENLINEAGETRANSPORT and AIRFLOWOPENLINEAGENAMESPACE and changed operator from PostgresOperator to SQLExecuteQueryOperator.
+[2024-03-07 03:52:55,496] Failed to extract metadata using found extractor <airflow.providers.openlineage.extractors.base.DefaultExtractor object at 0x7fc4aa1e3950> - section/key [openlineage/disabled_for_operators] not found in config task_type=SQLExecuteQueryOperator airflow_dag_id=rs_source_to_staging task_id=task_insert_event_data airflow_run_id=manual__2024-03-07T03:52:11.634313+00:00
+[2024-03-07 03:52:55,498] section/key [openlineage/config_path] not found in config
+[2024-03-07 03:52:55,498] section/key [openlineage/config_path] not found in config
+[2024-03-07 03:52:55,499] Executing:
+ insert into event
+ SELECT eventid, venueid, catid, dateid, eventname, starttime::TIMESTAMP
+ FROM s3_datalake.event;
 +
+
+
+
+
+ *Thread Reply:* I'll look into it 🙂
+ + + +
+
+
+ *Thread Reply:* @Paul Wilson Villena It looks like a small mistake in the OL, that I'll fix in the next version - we missed adding a callback there, and getting the airflow configuration raises error when disabled_for_operators is not defined in the airflow.cfg file / the env variable. For now it should help to simply add the <a href="https://airflow.apache.org/docs/apache-airflow-providers-openlineage/1.4.0/configurations-ref.html#id1">[openlineage]</a> section to airflow.cfg, and set disabled_for_operators="" , or just export AIRFLOW__OPENLINEAGE__DISABLED_FOR_OPERATORS="" ,
+
+
+ *Thread Reply:* Will be released in the next provider version: https://github.com/apache/airflow/pull/37994
+ + + +
+
+
+ *Thread Reply:* Hi @Kacper Muda it seems I need to also set this: Otherwise this error persists:
+section/key [openlineage/config_path] not found in config
+os.environ["AIRFLOW__OPENLINEAGE__CONFIG_PATH"]=""
+
+
+ *Thread Reply:* Yes, sorry for missing that. I fixed in the code and forgot to mention it. If You were to not use AIRFLOW__OPENLINEAGE__TRANSPORT You'd have to set it to empty string as well, as it's missing the same fallback 🙂
*Thread Reply:* I see it too:
 +
+ Spotted!
 +
@@ -9508,12 +9775,12 @@
+
@@ -9508,12 +9775,12 @@ *Thread Reply:* a moment earlier it makes more context
 +
@@ -11870,12 +12137,12 @@
+
@@ -11870,12 +12137,12 @@ execution_date remains the same. If I run a backfill job for yesterday, then delete it and run it again, I get the same ids. I'm trying to understand the rationale behind this choice so we can determine whether it's a bug or a feature. 😉
 +
@@ -12717,6 +12984,43 @@
+
+
+
+
@@ -12717,6 +12984,43 @@
+
+
+  +
+
+
+
+
+
+
+ *Thread Reply:*
 +
@@ -14438,13 +14742,50 @@
+
@@ -14438,13 +14742,50 @@  +
+  +
+
+
+
+
+
+
+
*Thread Reply:* @Harel Shein thanks for the suggestion. Lmk if there's a better way to do this, but here's a link to Google's visualizations: https://docs.google.com/forms/d/1j1SyJH0LoRNwNS1oJy0qfnDn_NPOrQw_fMb7qwouVfU/viewanalytics. And a .csv is attached. Would you use this link on the page or link to a spreadsheet instead?
+
+
+  +
+
+
+
+
+
+
+ Thanks for any feedback on the Mailchimp version of the newsletter special issue before it goes out on Monday:
 +
@@ -15607,12 +15989,12 @@
+
@@ -15607,12 +15989,12 @@ Decathlon showed part of one of their graphs last night
 +
@@ -15680,12 +16062,12 @@
+
@@ -15680,12 +16062,12 @@ *Thread Reply:* some metrics too
 +
@@ -16764,12 +17146,12 @@
+
@@ -16764,12 +17146,12 @@ *Thread Reply:*
 +
@@ -18662,6 +19044,166 @@
+
+
+
+
@@ -18662,6 +19044,166 @@
+
+
+ *Thread Reply:* it got merged 👀
+ + + + +
+
+
+
+
+ *Thread Reply:* amazing feedback on a 10k line PR 😅
+ + + +
+
+
+ *Thread Reply:* maybe they have policy that feedback starts from 10k lines
+ + + +
+
+
+ *Thread Reply:* it wasn’t enough
+ + + +
+
+
+
+
+
+
+ *Thread Reply:* too big to review, LGTM
+ + + +I just noticed this. shared should not have a dependency on spark. 👀
 +
@@ -19635,12 +20177,12 @@
+
@@ -19635,12 +20177,12 @@ *Thread Reply:* also 🙂
 +
@@ -22571,12 +23113,12 @@
+
@@ -22571,12 +23113,12 @@ *Thread Reply:* People still love to use 2.4.8 🙂
 +
+ *Thread Reply:* not sure it did exactly what we want but probably okay for now
 +
@@ -23515,6 +24057,58 @@
+
+
+
+
@@ -23515,6 +24057,58 @@
+
+
+ *Thread Reply:* to me the risk is more to introduce vulnerabilities/backdoors in the OpenLineage released artifact through pushing a cached image that modifies the result of the build.
+ + + +
+
+
+ *Thread Reply:* The idea of saving the image signature in the repo is that you can not use a new image in the build without creating a new commit and traceability.
+ + + +
+
+
+ gotta skip today meeting. I hope to see you all next week!
+ + + +
+
+
+ The meetup I mentioned about OpenLineage/OpenTelemetry: https://x.com/J_/status/1565162740246671360 +I speak in English but other two speakers speak in Hebrew
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* the slides from my part: https://docs.google.com/presentation/d/1BLM2ocs2S64NZLzNaZz5rkrS9lHRvtr9jUIetHdiMbA/edit#slide=id.g11e446d5059_0_1055
+ + + +
+
+
+ *Thread Reply:* thanks for sharing that, that otel to ol comparison is going to be very useful for me today :)
+ + + +
+
+
+ Could use another pair of eyes on this month's newsletter draft if anyone has time today
+ + +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* LGTM 🙂
+ + + +
+
+
+ Hey, I created new Airflow AIP. It proposes instrumenting Airflow Hooks and Object Storage to collect dataset updates automatically, to allow gathering lineage from PythonOperator and custom operators. +Feel free to comment on Confluence https://cwiki.apache.org/confluence/display/AIRFLOW/AIP-62+Getting+Lineage+from+Hook+Instrumentation +or on Airflow mailing list: https://lists.apache.org/thread/5chxcp0zjcx66d3vs4qlrm8kl6l4s3m2
+ + + +
+
+
+ Hey, does anyone want to add anything here (PR that adds AWS MSK IAM transport)? It looks like it's ready to be merged.
+ + + +
+
+
+ did we miss a step in publishing 1.9.1? going https://search.maven.org/remote_content?g=io.openlineage&a=openlineage-spark&v=LATEST|here gives me the 1.8 release
+ + + +
+
+
+ *Thread Reply:* oh, this might be related to having 2 scala versions now, because I can see the 1.9.1 artifacts
+ + + +
+
+
+ *Thread Reply:* yes
+ + + +
+
+
+ *Thread Reply:* we may need to fix the docs then https://openlineage.io/docs/integrations/spark/quickstart/quickstart_databricks
+ + + +
+
+
+ *Thread Reply:* another place 🙂
+ + + +
+
+
+
+
+
+
+ *Thread Reply:* https://github.com/OpenLineage/docs/pull/299
+ + <a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
+
+
+
+
+ <a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
+
+
+
+ *Thread Reply:* thx :gh_merged:
+ + + +
+
+
+ Hi, here's a tentative agenda for next week's TSC (on Wednesday at 9:30 PT):
+ +
+
+
+ *Thread Reply:* I thought @Paweł Leszczyński wanted to present?
+ + + +
+
+
+ *Thread Reply:* What was the topic? Protobuf or built-in lineage maybe? Or the many docs improvements lately?
+ + + +
+
+
+ *Thread Reply:* I think so? https://github.com/OpenLineage/OpenLineage/pull/2272
+ + + +
+
+
+ *Thread Reply:* Imagine there are lots of folks who would be interested in a presentation on that
+ + + +
+
+
+ *Thread Reply:* I think so too 🙂
+ + + + +
+
+
+
+
+ *Thread Reply:* There two things worth presenting: circuit breaker +/or built-in lineage (once it gets merged).
+ + + +
+
+
+ *Thread Reply:* updating the agenda
+ + + +
+
+
+ is there a reason why facet objects have _schemaURL property but BaseEvent has schemaURL?
 +
+
+
+
+
+ *Thread Reply:* yeah, we use _ to avoid naming conflicts in a facet
+
+
+ *Thread Reply:* same goes for producer
+
+
+ *Thread Reply:* Facets have user defined fields. So all base fields are prefixed
+ + + +
+
+
+ *Thread Reply:* Base events do not
+ + + +
+
+
+ *Thread Reply:* it should be a made more clear… recently ran into the issue when validating OL events
+ + + +
+
+
+ *Thread Reply:* it might be another missing point but we set _producer in BaseFacet:
+def __attrs_post_init__(self) -> None:
+ self._producer = PRODUCER
+but we don’t do that for producer in BaseEvent
+
+
+ *Thread Reply:* is this supposed to be like that?
+ + + +
+
+
+ *Thread Reply:* I’m kinda lost 🙂
+ + + +
+
+
+ *Thread Reply:* We should set producer in baseevent as well
+ + + +
+
+
+ *Thread Reply:* The idea is the base event might be produced by the spark integration but the facet might be produced by iceberg library
+ + + +
+
+
+ *Thread Reply:* > The idea is the base event might be produced by the spark integration but the facet might be produced by iceberg library
+right, it doesn’t require adding _ , it just helps in making the difference
and also this reason too: +> Facets have user defined fields. So all base fields are prefixed +> Base events do not
+ + + +
+
+
+ *Thread Reply:* Since users can create custom facets with whatever fields we just tell Them that “_**” is reserved.
+ + + +
+
+
+ *Thread Reply:* So the underscore prefix is a mechanism specific to facets
+ + + +
+
+
+ *Thread Reply:* 👍
+ + + +
+
+
+ *Thread Reply:* last question:
+we don’t want to block users from setting their own _producerfield? it seems the only way now is to use openlineage.client.facet.set_producer method to override default, you can’t just do RunEvent(…, _producer='my_own')
+
+
+ *Thread Reply:* The idea is the producer identifies the code that generates the metadata. So you set it once and all the facets you generate have the same
+ + + +
+
+
+ *Thread Reply:* mhm, probably you don’t need to use several producers (at least) per Python module
+ + + +
+
+
+
+
+
+
+ *Thread Reply:* In airflow each provider should have its own for the facets they produce
+ + + +
+
+
+ *Thread Reply:* just searched for set_producer in current docs - no results 😨
+
+
+ *Thread Reply:* a number of things will get to the right track after I’m done with generating code 🙂
+ + + +
+
+
+ *Thread Reply:* Thanks for looking into that. If you can fix the doc by adding a paragraph about that, that would be helpful
+ + + +
+
+
+ *Thread Reply:* I can create an issue at least 😂
+ + + +
+
+
+ *Thread Reply:* there you go: +https://github.com/OpenLineage/docs/issues/300 +if I missed something please comment
+
+ <a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
+
+
+
+ I feel like our getting started with openlineage page is mostly a getting started with Marquez page. but I'm also not sure what should be there otherwise.
+
+
+
+ *Thread Reply:* https://openlineage.io/docs/guides/spark ?
+
+
+
+ *Thread Reply:* Unfortunately it's probably not that "quick" given the setup required..
+ + + +
+
+
+ *Thread Reply:* Maybe better? https://openlineage.io/docs/integrations/spark/quickstart/quickstart_local
+
+
+
+ *Thread Reply:* yeah, that's where I was struggling as well. should our quickstart be platform specific? that also feels strange.
+ + + + +
+
+
+
+
+ Quick question, for the spark.openlineage.facets.disabled property, why do we need to include [;] in the value? Why can't we use , to act as the delimiter? Why do we need [ and ] to enclose the string?
+
+
+ *Thread Reply:* There was some concrete reason AFAIK right @Paweł Leszczyński?
+ + + +
+
+
+ *Thread Reply:* We do have a logic that converts Spark conf entries to OpenLineageYaml without a need to understand its content. I think [] was added for this reason to know that Spark conf entry has to be translated into an array.
Initially disabled facets were just separated by ; . Why not a comma? I don't remember if there was any problem with this.
https://github.com/OpenLineage/OpenLineage/pull/1271/files -> this PR introduced it
+ +https://github.com/OpenLineage/OpenLineage/blob/1.9.1/integration/spark/app/src/main/java/io/openlineage/spark/agent/ArgumentParser.java#L152 -> this code check if spark conf value is of array type
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+  +
+
+
+
+
+ Hi team, do we have any proposal or previous discussion of Trino OpenLineage integration?
+ + + +
+
+
+ *Thread Reply:* There is old third-party integration: https://github.com/takezoe/trino-openlineage
+ +It has right idea to use EventListener, but I can't vouch if it works
+ + + +
+
+
+ *Thread Reply:* Thanks. We are investigating the integration in our org. It will be a good start point 🙂
+ + + +
+
+
+ *Thread Reply:* I think the ideal solution would be to use EventListener. So far we only have very basic integration in Airflow's TrinoOperator
+ + + +
+
+
+ *Thread Reply:* The only thing I haven't really checked out what are real possibilities for EventListener in terms of catalog details discovery, e.g. what's database connection for the catalog.
+ + + +
+
+
+ *Thread Reply:* Thanks for calling out this. We will evaluate and post some observation in the thread.
+ + + + +
+
+
+
+
+ *Thread Reply:* Thanks Peter +Hey Maciej/Jakub +Could you please share the process to follow in terms of contributing a Trino open lineage integration. (Design doc and issue ?)
+ +There was an issue for trino integration but it was closed recently. +https://github.com/OpenLineage/OpenLineage/issues/164
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* It would be great to see design doc and maybe some POC if possible. I've reopened the issue for you.
+ +If you get agreement around the design I don't think there are more formal steps needed, but maybe @Julien Le Dem has other idea
+ + + +
+
+
+ *Thread Reply:* Trino has their plugins directory btw: +https://github.com/trinodb/trino/tree/master/plugin +including event listeners like: https://github.com/trinodb/trino/tree/master/plugin/trino-mysql-event-listener
+ + + +
+
+
+ *Thread Reply:* Thanks Maciej and Jakub +Yes the integration will be done with Trino’s event listener framework that has details around query, source and destination dataset details etc.
+ +> It would be great to see design doc and maybe some POC if possible. I’ve reopened the issue for you. +Thanks for re-opening the issue. We will add the design doc and POC to the issue.
+ + + +
+
+
+ *Thread Reply:* I agree with @Maciej Obuchowski, a quick design doc followed by a POC would be great. +The integration could either live in OpenLineage or Trino but that can be discussed after the POC.
+ + + +
+
+
+ *Thread Reply:* (obviously, adding it to the trino repo would require aproval from the trino community)
+ + + + +
+
+
+
+
+ *Thread Reply:* Gentleman, we are also actively looking into this topic with the same repo from @takezoe as our base, I have submitted a PR to revive this project - it does work, the POC is there in a form of docker-compose.yaml deployment 🙂 some obvious things are missing for now (like kafka output instead of api) but I think it's a good starting point and it's compatible with latest trino and OL
+
+ <a href="https://github.com/takezoe/trino-openlineage">takezoe/trino-openlineage</a>
+
+
+
+ *Thread Reply:* Thanks for put the foundation for the implementation. Base on it, I feel @Alok would still participate and make contribute to it. How about create a design doc and list all of the possible TBDs as @Julien Le Dem suggested.
+ + + +
+
+
+ *Thread Reply:* Adding @takezoe to this thread. Thanks for your work on a Trino integration and welcome!
+ + + +
+
+
+ *Thread Reply:* throwing the CFP for the Trino conference here in case any one of the contributors want to present there https://sessionize.com/trino-fest-2024
+
+
+
+ *Thread Reply:* I'm also very happy to help with an idea for an abstract
+ + + +
+
+
+ *Thread Reply:* Hey Harel +Just FYI we are already engaged with Trino community to have a talk around Trino open lineage integration and have submitted an Abstract for review.
+ + + +
+
+
+ *Thread Reply:* once you release the integration, please add a reference about it to OpenLineage docs! +https://github.com/OpenLineage/docs
+
+
+
+ *Thread Reply:* I think it's ready for review https://github.com/trinodb/trino/pull/21265 just with API sink integration, additional features can be added at @Alok's convenience as next PRs
+
+ <a href="https://github.com/trinodb/trino">trinodb/trino</a>
+
+
+
+ Hey, there’s discrepancy between
disabled option) +
+
+
+
+
+ *Thread Reply:* I believe we should not extract or emit any open lineage events if this option is used
+ + + +
+
+
+ *Thread Reply:* I'm for option 2, don't send any event from task
+ + + +
+
+
+ *Thread Reply:* @Jakub Dardziński do you see any use case for not extracting metadata extraction but still emitting events?
+ + + +
+
+
+ *Thread Reply:* The use case AFAIK was old SnowflakeOperator bug, we wanted to disable the collection there, since it zombified the task. The events being emitted still gave information about status of the task as well as non-dataset related metadata
+ + + +
+
+
+ *Thread Reply:* but I think it's less relevant now
+ + + +
+
+
+ *Thread Reply:* ^ this and you might want to have information about task execution because OL is a backend for some task-tracking system
+ + + +
+
+
+ *Thread Reply:* Hm, I believe users don't expect us to spend time processing/extracting OL events if this configuration is used. It's the documented behaviour
+ + + +
+
+
+ *Thread Reply:* the question is if we should change docs or behaviour
+ + + +
+
+
+ *Thread Reply:* I believe the latter
+ + + +
+
+
+ *Thread Reply:* +1 behaviour
+ + + +
+
+
+
+
+
+
+ Hi, here's the
+
+
+ *Thread Reply:* Looks like a great agenda! Left a couple of comments
+ + + +
+
+
+ *Thread Reply:* @Michael Robinson will you be able to facilitate or do you need help?
+ + + +
+
+
+ *Thread Reply:* I'm also missing from the committer list, but can't comment on slides 🙂
+ + + +
+
+
+ *Thread Reply:* Sorry about that @Kacper Muda. Gave you access just now
+ + + +
+
+
+ *Thread Reply:* We probably need to add you to lists posted elsewhere... I'll check
+ + + +
+
+
+ *Thread Reply:* No worries, thanks 🙂 !
+ + + +
+
+
+ https://github.com/open-metadata/OpenMetadata/pull/15317 👀
+ + + +
+
+
+ *Thread Reply:* this is awesome
+ + + +
+
+
+ *Thread Reply:* it looks like they use temporary deployments to test...
+ + + +
+
+
+ *Thread Reply:* yeah the GitHub history is wild
+ + + +
+
+
+ Hi, I'm at the conference hotel and my earbuds won't pair with my new mac for some reason. Does the agenda look good? Want to send out the reminders soon. I'll add the OpenMetadata news!
+ + + +
+
+
+ *Thread Reply:* I think we can also add the Datahub PR?
+ + + +
+
+
+ *Thread Reply:* @Paweł Leszczyński prefers to present only the circuit breakers
+ + + +
+
+
+ *Thread Reply:* https://github.com/datahub-project/datahub/pull/9870/files
+ + + +
+
+
+ *Thread Reply:* This one?
+ + + +
+
+
+ *Thread Reply:* yes!
+ + + +
+
+
+ It's been a while since we've updated the twitter profile. Current description: "A standard api for collecting Data lineage and Metadata at runtime." What would you think of using our website's tagline: "An open framework for data lineage collection and analysis." Other ideas?
+ + + +
+
+
+ can someone grant me write access to our forked sqlparser-rs repo?
+
+
+ *Thread Reply:* @Julien Le Dem maybe?
+ + + +
+
+
+ *Thread Reply:* I should probably add the committer group to it
+ + + +
+
+
+ *Thread Reply:* I have made the committer group maintainer on this repo
+ + + +
+
+
+ https://github.com/OpenLineage/OpenLineage/pull/2514 +small but mighty 😉
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ Regarding the approved release, based on the additions it seems to me like we should make it a minor release (so 1.10.0). Any objections? Changes are here: https://github.com/OpenLineage/OpenLineage/compare/1.9.1...HEAD
+ + + +
+
+
+ We encountered a case of a START event, exceeding 2MB in Airflow. This was traced back to an operator with unusually long arguments and attributes. Further investigation revealed that our Airflow events contain redundant data across different facets, leading to unnecessary bloating of event sizes (those long attributes and args were attached three times to a single event). I proposed to remove some redundant facets and to refine the operator's attributes inclusion logic within AirflowRunFacet. I am not sure how breaking is this change, but some systems might depend on the current setup. Suggesting an immediate removal might not be the best approach, and i'd like to know your thoughts. (A similar problem exists within the Airflow provider.) +CC @Maciej Obuchowski @Willy Lulciuc @Jakub Dardziński
+ +https://github.com/OpenLineage/OpenLineage/pull/2509
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ As mentioned during yesterday's TSC, we can't get insight into DataHub's integration from the PR description in their repo. And it's a very big PR. Does anyone have any intel? PR is here: https://github.com/datahub-project/datahub/pull/9870
+
+ <a href="https://github.com/datahub-project/datahub">datahub-project/datahub</a>
+
+
+
+ Changelog PR for 1.10 is RFR: https://github.com/OpenLineage/OpenLineage/pull/2516
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ @Julien Le Dem @Paweł Leszczyński Release is failing in the Java client job due to (I think) the version of spotless: +```Could not resolve com.diffplug.spotless:spotlessplugingradle:6.21.0. + Required by: + project : > com.diffplug.spotless:com.diffplug.spotless.gradle.plugin:6.21.0
+ +++ + + +No matching variant of com.diffplug.spotless:spotlessplugingradle:6.21.0 was found. The consumer was configured to find a library for use during runtime, compatible with Java 8, packaged as a jar, and its dependencies declared externally, as well as attribute 'org.gradle.plugin.api-version' with value '8.4'```
+
+
+
+ *Thread Reply:* @Michael Robinson https://github.com/OpenLineage/OpenLineage/pull/2517
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ fix to broken main: +https://github.com/OpenLineage/OpenLineage/pull/2518
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* Thanks, just tried again
+ + + +
+
+
+ *Thread Reply:* ? +it needs approve and merge 😛
+ + + +
+
+
+ *Thread Reply:* Oh oops disregard
+ + + +
+
+
+ *Thread Reply:* different PR
+ + + +
+
+
+ *Thread Reply:* 👍
+ + + +
+
+
+ There's an issue with the Flink job on CI:
+** What went wrong:
+Could not determine the dependencies of task ':shadowJar'.
+> Could not resolve all dependencies for configuration ':runtimeClasspath'.
+ > Could not find io.**********************:**********************_sql_java:1.10.1.
+ Searched in the following locations:
+ - <https://repo.maven.apache.org/maven2/io/**********************/**********************-sql-java/1.10.1/**********************-sql-java-1.10.1.pom>
+ - <https://packages.confluent.io/maven/io/**********************/**********************-sql-java/1.10.1/**********************-sql-java-1.10.1.pom>
+ - file:/home/circleci/.m2/repository/io/**********************/**********************-sql-java/1.10.1/**********************-sql-java-1.10.1.pom
+ Required by:
+ project : > project :shared
+ project : > project :flink115
+ project : > project :flink117
+ project : > project :flink118
+
+
+ *Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/2521
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* @Jakub Dardziński still awake? 🙂
+ + + +
+
+
+ *Thread Reply:* it’s just approval bot
+ + + +
+
+
+ *Thread Reply:* created issue on how to avoid those in the future https://github.com/OpenLineage/OpenLineage/issues/2522
+ + + +
+
+
+ *Thread Reply:* https://app.circleci.com/jobs/github/OpenLineage/OpenLineage/188526 I lack emojis on this server to fully express my emotions
+ + + +
+
+
+ *Thread Reply:* https://openlineage.slack.com/archives/C065PQ4TL8K/p1710454645059659 +you might have missed that
+
+
+
+ *Thread Reply:* merge -> rebase -> problem gone
+ + + +
+
+
+ *Thread Reply:* PR to update the changelog is RFR @Jakub Dardziński @Maciej Obuchowski: https://github.com/OpenLineage/OpenLineage/pull/2526
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ https://github.com/OpenLineage/OpenLineage/pull/2520 +It’s a long-awaited PR - feel free to comment!
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+
+
+
+ https://github.com/OpenLineage/OpenLineage/blob/main/spec/facets/ParentRunFacet.json#L20
+here the format is uuid
+however if you follow logic for parent id in current dbt integration you might discover that parent run facet has assigned value of DAG’s run_id (which is not uuid)
@Julien Le Dem, what has higher priority? I think lots of people are using dbt-ol wrapper with current lineage_parent_id macro
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* It is a uuid because it should be the id of an OL run
+ + + +
+
+
+ where can I find who has write access to OL repo?
+ + + +
+
+
+ *Thread Reply:* Settings > Collaborators and teams
+ + + +
+
+
+ *Thread Reply:* thanks Michael, seems like I don’t have enough permissions to see that
+ + + +
+
+
+ Sorry, I have a dr appointment today and won’t join the meeting
+ + + +
+
+
+ *Thread Reply:* I gotta skip too. Maciej and Pawel are at the Kafka Summit
+ + + +
+
+
+ *Thread Reply:* I hope you’re fine!
+ + + +
+
+
+ *Thread Reply:* I am fine thank you 🙂
+ + + +
+
+
+ *Thread Reply:* just a visit
+ + + +
+
+
+ Should we cancel the sync today?
+ + + +
+
+
+ looking at XTable today, any thoughts on how we can collaborate with them?
+.png) +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* @Julien Le Dem @Willy Lulciuc this reminds me of some ideas we had a few years ago.. :)
+ + + +
+
+
+ *Thread Reply:* hmm.. ok. maybe not that relevant for us, at first I thought this was an abstraction for read/write on top of Iceberg/Hudi/Delta.. but I think this is more of a data sync appliance. would still be relevant for linking together synced datasets (but I don't think it's that important now)
+ + + +
+
+
+ *Thread Reply:* From the introduction https://www.confluent.io/blog/introducing-tableflow/, looks like they are using Flink for both data ingestion and compaction. It means we should at least consider to support hudi source and sink for flink lineage 🙂
+
+
+
+ A key growth metric trending in the right direction:
+ + +
+
+
+
+
+
+
+
+
+
+
+
+
+ Eyes on this PR to add OpenMetadata to the Ecosystem page would be appreciated: https://github.com/OpenLineage/docs/pull/303. TIA! @Mariusz Górski
+
+ <a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
+
+
+
+ I really want to improve this page in the docs, anyone wants to work with me on that?
+
+
+
+ *Thread Reply:* perhaps also make this part of the PR process, so when we add support for something, we remember to update the docs
+ + + +
+
+
+ *Thread Reply:* I free up next week and would love to chat… obviously, time permitting but the page needs some love ❤️
+ + + +
+
+
+ *Thread Reply:* I can verify the information once you have some PR 🙂
+ + + +
+
+
+ RFR: a PR to add DataHub to the Ecosystem page https://github.com/OpenLineage/docs/pull/304
+
+ <a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
+
+
+
+ *Thread Reply:* The description comes from the very brief README in DataHub's GH repo and a glance at the code. No other documentation or resources appear to be available.
+ + + +
+
+
+ *Thread Reply:* @Tamás Németh
+ + + +
+
+
+ Dagster is launching column-lineage support for dbt using the sqlglot parser https://github.com/dagster-io/dagster/pull/20407
+
+ <a href="https://github.com/dagster-io/dagster">dagster-io/dagster</a>
+
+
+
+ *Thread Reply:* I kinda like their approach to use post-hooks in order to enable column-level lineage so that custom macro collects information about columns, logs it and they parse the log after the execution
+
+
+ *Thread Reply:* it doesn’t force dbt docs generate step that some might not want to use
+
+
+ *Thread Reply:* but at the same time reuses DBT adapter to make additional calls to retrieve missing metadata
+ + + +
+
+
+ @Paweł Leszczyński interesting project I came across over the weekend: https://github.com/HamaWhiteGG/flink-sql-lineage
+
+
+
+ *Thread Reply:* Wow, this is something we would love to have (flink SQL support). It's great to know that people around the globe are working on the same thing and heading same direction. Great finding @Willy Lulciuc. Thanks for sharing!
+ + + +
+
+
+ *Thread Reply:* On Kafka Summit I've talked with Timo Walther from Flink SQL team and he proposed alternative approach.
+ +Flink SQL has stable (across releases) CompiledPlan JSON text representation that could be parsed, and has all the necessary info - as this is used for serializing actual execution plan both ways.
+
+
+ *Thread Reply:* As Flink SQL will convert to transformations before execution, technical speaking our existing solution has already be able to create linage info for Flink SQL apps (not including column lineage and table schemas (that can be inferred within flink table environment)). I will create Flink SQL job for e2e testing purpose.
+ + + +
+
+
+ *Thread Reply:* I am also working on Flink side for table lineage. Hopefully, new lineage features can be released in flink 1.20.
+ + + +
+
+
+ Sessions for this year's Data+AI Summit have been published. A search didn't turn up anything related to lineage, but did you know Julien and Willy's talk at last year's summit has received 4k+ views? 👀
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* seems like our talk was not accepted, but I can see 9 sessions on unity catalog 😕
+ + + +
+
+
+
+
+
+
+ finally merged 🙂
+ + + +
+
+
+ pawel-big-lebowski commented on Nov 21, 2023
+whoa
+
+
+ I’ll miss the sync today (on the way to data council)
+ + + +
+
+
+
+
+
+
+ *Thread Reply:* have fun at the conference!
+ + + +
+
+
+ OK @Maciej Obuchowski - 1 job has many stages; 1 stage has many tasks. Transitively, this means that 1 job has many tasks.
+ + + +
+
+
+ *Thread Reply:* batch or streaming one? 🙂
+ + + +
+
+
+ *Thread Reply:* Doesn't matter. It's the same concept.
+ + + +
+
+
+ Also @Paweł Leszczyński, seem Spark metrics has this:
+ +local-1711474020860.driver.LiveListenerBus.listenerProcessingTime.io.openlineage.spark.agent.OpenLineageSparkListener
+ count = 12
+ mean rate = 1.19 calls/second
+ 1-minute rate = 1.03 calls/second
+ 5-minute rate = 1.01 calls/second
+ 15-minute rate = 1.00 calls/second
+ min = 0.00 milliseconds
+ max = 1985.48 milliseconds
+ mean = 226.81 milliseconds
+ stddev = 549.12 milliseconds
+ median = 4.93 milliseconds
+ 75% <= 53.64 milliseconds
+ 95% <= 1985.48 milliseconds
+ 98% <= 1985.48 milliseconds
+ 99% <= 1985.48 milliseconds
+ 99.9% <= 1985.48 milliseconds
+
+
+ Do you think Bipan's team could potentially benefit significantly from upgrading to the latest version of openlineage-spark? https://openlineage.slack.com/archives/C01CK9T7HKR/p1711483070147019
+
+
+
+ *Thread Reply:* @Paweł Leszczyński wdyt?
+ + + +
+
+
+ *Thread Reply:* I think the issue here is that marquez is not able to properly visualize parent run events that Maciej has added recently for a Spark application
+ + + +
+
+
+ *Thread Reply:* So if they downgraded would they have a graph closer to what they want?
+ + + +
+
+
+ *Thread Reply:* I don't see parent run events there?
+ + + +
+
+
+ I'm exploring ways to improve the demo gif in the Marquez README. An improved and up-to-date demo gif could also be used elsewhere -- in the Marquez landing pages, for example, and the OL docs. Along with other improvements to the landing pages, I created a new gif that's up to date and higher-resolution, but it's large (~20 MB). +• We could put it on YouTube and link to it, but that would downgrade the user experience in other ways. +• We could host it somewhere else, but that would mean adding another tool to the stack and, depending on file size limits, could cost money. (I can't imagine it would cost but I haven't really looked into this option yet. Regardless of cost, tt seems to have the same drawbacks as YT from a UX perspective.) +• We could have GitHub host it in another repo (for free) in the Marquez or OL orgs. + ◦ It could go in the OL Docs because it's likely we'll want to use it in the docs anyway, but even if we never serve it wouldn't this create issues for local development at a minimum? I opened a PR to do this, which a PR with other improvements is waiting on, but not sure about this approach. + ◦ It could go in the unused Marquez website repo, but there's a good chance we'll forget it's there and remove or archive the repo without moving it first. + ◦ In another repo, or even a new one for stuff like this? +Anyone have an opinion or know of a better option?
+ + + +
+
+
+ *Thread Reply:* maybe make it a HTML5 video?
+ + + +
+
+
+ *Thread Reply:* https://wp-rocket.me/blog/replacing-animated-gifs-with-html5-video-for-faster-page-speed/
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* 👀
+ + + +
+
+
+ @Julien Le Dem @Harel Shein how did Data Council panel and talk go?
+ + + +
+
+
+ *Thread Reply:* Was just composing the message below :)
+ + + +
+
+
+ Some great discussions here at data council, the panel was really great and we can definitely feel energy around OpenLineage continuing to build up! 🚀 +Thanks @Julien Le Dem for organizing and shoutout to @Ernie Ostic @Sheeri Cabral (Collibra) @Eric Veleker for taking the time and coming down here and keeping pushing more and building the community! ❤️
+ + + +
+
+
+ *Thread Reply:* @Harel Shein did anyone take pictures?
+ + + +
+
+
+ *Thread Reply:* there should be plenty of pictures from the conference organizers, we'll ask for some
+ + + +
+
+
+ *Thread Reply:* Did a search and didn't see anything
+ + + +
+
+
+
+
+
+ *Thread Reply:* Speaker dinner the night before: https://www.linkedin.com/posts/datacouncil-aidatacouncil-ugcPost-7178852429705224193-De46?utmsource=share&utmmedium=memberios|https://www.linkedin.com/posts/datacouncil-aidatacouncil-ugcPost-7178852429705224193-De46?utmsource=share&utmmedium=memberios
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* Ahah. Same picture
+ + + +
+
+
+ *Thread Reply:* haha. Julien and Ernie look great while I'm explaining how to land an airplane 🛬
+ + + +
+
+
+ *Thread Reply:* Great pic!
+ + + +
+
+
+
+
+
+ *Thread Reply:* awesome! just in time for the newsletter 🙂
+ + + + +
+
+
+
+
+ *Thread Reply:* Thank you for thinking of us. Onwards and upwards.
+ + + +
+
+
+ I just find the naming conventions for hive/iceberg/hudi are not listed in the doc https://openlineage.io/docs/spec/naming/. Shall we further standardize them? Any suggestions?
+
+
+
+ *Thread Reply:* Yes. This also came up in a conversation with one of the maintainers of dbt-core, we can also pick up on a proposal to extend the naming conventions markdown to something a bit more scalable.
+ + + +
+
+
+ *Thread Reply:* What you think about this proposal? +https://github.com/OpenLineage/OpenLineage/pull/1702
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* Thanks for sharing the info. Will take a deeper look later today.
+ + + +
+
+
+ *Thread Reply:* I think this is similar topic to resource naming in ODD, might be worth to take a look for inspiration: https://github.com/opendatadiscovery/oddrn-generator
+
+
+
+ *Thread Reply:* the thing is we need to have language-agnostic way of defining those naming conventions and be able to generate code for them, similar to facets spec
+ + + +
+
+
+ *Thread Reply:* could be also an idea to have micro rest api embedded in each client, so managing naming convention would be stored there and each client (python/java) could run it as a subprocess 🤔
+ + + +
+
+
+ *Thread Reply:* we can also just write it in Rust, @Maciej Obuchowski 😁
+ + + +
+
+
+ *Thread Reply:* no real changes/additions, but starting to organize the doc for now: https://github.com/OpenLineage/OpenLineage/pull/2554
+ + + +
+
+
+ @Maciej Obuchowski we also heard some good things about the sqlglot parser. have you looked at it recently?
+
+
+
+ *Thread Reply:* I love the fact that our parser is in type safe language :)
+ + + +
+
+
+ *Thread Reply:* does it matter after all when it comes to parsing SQL? +it might be worth to run some comparisons but it may turn out that sqlglot misses most of Snowflake dialect that we currently support
+ + + +
+
+
+ *Thread Reply:* We'd miss on Java side parsing as well
+ + + +
+
+
+ *Thread Reply:* very importantly this ^
+ + + +
+
+
+ *Thread Reply:* That’s important. Yes
+ + + +
+
+
+ OpenLineage 1.11.0 release vote is now open: https://openlineage.slack.com/archives/C01CK9T7HKR/p1711980285409389
+
+
+
+ Sorry, I’ll be late to the sync
+ + + +
+
+
+ forgot to mention, but we have the TSC meeting coming up next week. we should start sourcing topics
+ + + +
+
+
+ *Thread Reply:* 1.10 and 1.11 releases +Data Council, Kafka Summit, & Boston meetup shout outs and quick recaps +Datadog poc update or demo?
+ + + +
+
+
+ *Thread Reply:* Discussion item about Trino integration next steps?
+ + + +
+
+
+ *Thread Reply:* Accenture+Confluent roundtable reminder for sure
+ + + +
+
+
+ *Thread Reply:* job to job dependencies discussion item? https://openlineage.slack.com/archives/C065PQ4TL8K/p1712153842519719
+
+
+
+ *Thread Reply:* I think it's too early for Datadog update tbh, but I like the job to job discussion. +We can make also bring up the naming library discussion that we talked about yesterday
+ + + +
+
+
+ one more thing, if we want we could also apply for a free Datadog account for OpenLineage and Marquez: https://www.datadoghq.com/partner/open-source/
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* would be nice for tests
+ + + + +
+
+
+
+
+ is there any notion of process dependencies in openlineage? i.e. if I have two airflow tasks that depend on each other, with no dataset in between, can I express that in the openlineage spec?
+ + + +
+
+
+ *Thread Reply:* AFAIK no, it doesn't aim to do reflect that +cc @Julien Le Dem
+ + + +
+
+
+ *Thread Reply:* It is not in the core spec but this could be represented as a job facet. It is probably in the airflow facet right now but we could add a more generic job dependency facet
+ + + +
+
+
+ *Thread Reply:* we do represent hierarchy though - with ParentRunFacet
+
+
+ *Thread Reply:* if we were to add some dependency facet, what would we want to model?
+ +
+
+
+ *Thread Reply:* do we also want to model something like Airflow's trigger rules? https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/dags.html#trigger-rules
+ + + +
+
+
+ *Thread Reply:* I don't think this is about hierarchy though, right? If I understand @Julian LaNeve correctly, I think it's more #2
+ + + +
+
+
+ *Thread Reply:* yeah it's less about hierarchy - definitely more about #2.
+ +assume we have a DAG that looks like this:
+Task A -> Task B -> Task C
+today, OL can capture the full set of dependencies this if we do:
+A -> (dataset 1) -> B -> (ds 2) -> C
+but it's not always the case that you have datasets between everything. my question was moreso around "how can I use OL to capture the relationship between jobs if there are no datasets in between"
+
+
+ *Thread Reply:* I had opened an issue to track this a while ago but we did not get too far in the discussion: https://github.com/OpenLineage/OpenLineage/issues/552
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* oh nice - unsurprisingly you were 2 years ahead of me 😆
+ + + +
+
+
+ *Thread Reply:* You can track the dependency both at the job level and at the run level.
+At the job level you would do something along the lines of:
+job: { facets: {
+ job_dependencies: {
+ predecessors: [
+ { namespace: , name: }, ...
+ ],
+ successors: [
+ { namespace: , name: }, ...
+ ]
+ }
+}}
+
+
+ *Thread Reply:* At the run level you could track the actual task run dependencies:
+run: { facets: {
+ run_dependencies: {
+ predecessor: [ "{run uuid}", ...],
+ successors: [...],
+ }
+}}
+
+
+ *Thread Reply:* I think the current airflow run facet contains that information in an airflow specific representation: https://github.com/apache/airflow/blob/main/airflow/providers/openlineage/plugins/facets.py
+
+ <a href="https://github.com/apache/airflow">apache/airflow</a>
+
+
+
+ *Thread Reply:* I think we should have the discussion in the ticket so that it does not get lost in the slack history
+ + + +
+
+
+ *Thread Reply:* run: { facets: {
+ run_dependencies: {
+ predecessor: [ "{run uuid}", ...],
+ successors: [...],
+ }
+}}
+I like this format, but would have full run/job identifier as ParentRunFacet
+
+
+ *Thread Reply:* For the trigger rules I wonder if this is too specific to airflow.
+ + + +
+
+
+ *Thread Reply:* But if there’s a generic way to capture this, it makes sense
+ + + +
+
+
+ Don't forget to register for this! https://events.confluent.io/roundtable-data-lineage/Accenture
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ This attempt at a SQLAlchemy was basically working, if not perfectly, the last time I played with it: https://github.com/OpenLineage/OpenLineage/pull/2088. What more do I need to do to get it to the point where it can be merged as an "experimental"/"we warned you" integration? I mean, other than make sure it's still working and clean it up? 🙂
+ + + +
+
+
+ https://docs.getdbt.com/docs/collaborate/column-level-lineage#sql-parsing
+
+
+
+ *Thread Reply:* seems like it’s only for dbt cloud
+ + + +
+
+
+ *Thread Reply:* > Column-level lineage relies on SQL parsing. +Was thinking about doing the same thing at some point
+ + + +
+
+
+ *Thread Reply:* Basically with dbt we know schemas, so we also can resolve wildcards as well
+ + + +
+
+
+ *Thread Reply:* but that requires adding capability for providing known schema into sqlparser
+ + + +
+
+
+ *Thread Reply:* that's not very hard to add afaik 🙂
+ + + +
+
+
+ *Thread Reply:* not exactly into sqlparser too
+ + + +
+
+
+ *Thread Reply:* just our parser
+ + + +
+
+
+ *Thread Reply:* yeah, our parser
+ + + +
+
+
+ *Thread Reply:* still someone has to add it :D
+ + + +
+
+
+ *Thread Reply:* some rust enthusiast probably
+ + + +
+
+
+ *Thread Reply:* 👀
+ + + +
+
+
+ *Thread Reply:* but also: dbt provides schema info only if you generate catalog.json with generate docs command
+ + + +
+
+
+ *Thread Reply:* Right now we have the dbl-ol wrapper anyway, so we can make another dbt docs command on behalf of the user too
+ + + +
+
+
+ *Thread Reply:* not sure if running commands on behalf of user is good idea, but denoting in docs that running it increases accuracy of column-level lineage is probably a good idea
+ + + +
+
+
+ *Thread Reply:* once we build it
+ + + +
+
+
+ *Thread Reply:* of course
+ + + +
+
+
+ *Thread Reply:* That depends, what are the side effects of running dbt docs?
+ + + +
+
+
+ *Thread Reply:* the other option is similar to dagster's approach - run post-hook macro that prints schema to logs and read the logs with dbt-ol wrapper
+ + + +
+
+
+ *Thread Reply:* which again won't work in dbt cloud - there catalog.json seems like the only option
+ + + +
+
+
+ *Thread Reply:* > That depends, what are the side effects of running dbt docs? +refreshing someone's documentation? 🙂
+ + + +
+
+
+ *Thread Reply:* it would be configurable imho, if someone doesn’t want column level lineage in price of additional step, it’s their choice
+ + + +
+
+
+ *Thread Reply:* yup, agreed. I'm sure we can also run dbt docs to a temp directory that we'll delete right after
+ + + +
+
+
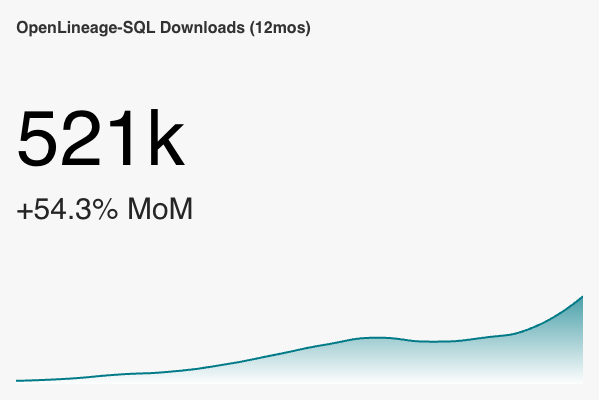
+ Some encouraging stats from Sonatype: these are Spark integration downloads (unique IPs) over the last 12 months
+ +
+
+
+ *Thread Reply:* That's an increase of 17560.5%
+ + + +
+
+
+ *Thread Reply:* https://github.com/OpenLineage/OpenLineage/releases/tag/1.11.3 +that’s a lot of notes 😮
+ + + +
+
+
+ Marquez committers: there's a committer vote open 👀
+ + + +
+
+
+ did anyone submit a CFP here? https://sessionize.com/open-source-summit-europe-2024/ +it's a linux foundation conference too
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* looks like a nice conference
+ + + +
+
+
+ *Thread Reply:* too far for me, but might be a train ride for you?
+ + + +
+
+
+ *Thread Reply:* yeah, I might submit something 🙂
+ + + +
+
+
+ *Thread Reply:* and I think there are actually direct trains to Vienna from Warsaw
+ + + +
+
+
+ Hmm @Maciej Obuchowski @Paweł Leszczyński - I see we released 1.11.3, but I don't see the artifacts in central. Are the artifacts blocked?
+ + + +
+
+
+
+
+
+ *Thread Reply:* after last release, it took me some 24h to see openlineage-flink artifact published
+ + + +
+
+
+ *Thread Reply:* I recall something about the artifacts had to be manually published from the staging area.
+ + + +
+
+
+ *Thread Reply:* @Maciej Obuchowski - can you check if the release is stuck in staging?
+ + + +
+
+
+ *Thread Reply:* I recall last time it failed because there wasn't a javadoc associated with it
+ + + +
+
+
+ *Thread Reply:* Nevermind @Paweł Leszczyński @Maciej Obuchowski - it seems like the search indexes haven't been updated.
+ + + +
+
+
+ *Thread Reply:* https://repo.maven.apache.org/maven2/io/openlineage/openlineage-spark_2.13/1.11.3/
+ + + +
+
+
+ *Thread Reply:* @Michael Robinson has to manually promote them but it's not instantaneous I believe
+ + + +
+
+
+ I'm seeing some really strange behavior with OL Spark, I'm going to give some data to help out, but these are still breadcrumbs unfortunately. 🧵
+ + + +
+
+
+ *Thread Reply:* the driver for this job is running for more than 5 hours, but the job actually finished after 20 minutes
+ + + +
+
+
+
+
+
+ *Thread Reply:* most the cpu time in those 5 hours are spent in openlineage methods
+ + + +
+
+
+
+
+
+ *Thread Reply:* it's also not reproducible 😕
+ + + +
+
+
+ *Thread Reply:* but happens "sometimes"
+ + + +
+
+
+ *Thread Reply:* DatasetIdentifier.equals?
+
+
+ *Thread Reply:* can you check what calls it?
+ + + +
+
+
+ *Thread Reply:* unfortunately, some of the stack frames are truncated by JVM
+ + + +
+
+
+
+
+
+
+
+
+ *Thread Reply:* maybe this has something to do with SymLink and the lombok implementation of .equals() ?
+ + + +
+
+
+ *Thread Reply:* and then some sort of circular dependency
+ + + +
+
+
+ *Thread Reply:* one possible place, looks like n^2 algorithm: https://github.com/OpenLineage/OpenLineage/blob/4ba93747e862e333267b46a57f02a09264[…]rk3/agent/lifecycle/plan/column/JdbcColumnLineageCollector.java
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* but is this a JDBC job?
+ + + +
+
+
+ *Thread Reply:* let me see
+ + + +
+
+
+ *Thread Reply:* I don't think so
+ + + +
+
+
+ *Thread Reply:* it's not
+ + + +
+
+
+ *Thread Reply:* ok, we don't use lang3 Pair a lot - it has to be in ColumnLevelLineageBuilder 🙂
+ + + +
+
+
+ *Thread Reply:* yes.. I'm staring at that class for a while now
+ + + +
+
+
+ *Thread Reply:* what's the rough size of the logical plan of the job?
+ + + +
+
+
+ *Thread Reply:* I'm trying to understand whether we're looking at some infinite loop
+ + + +
+
+
+ *Thread Reply:* or just something done very ineffiently
+ + + +
+
+
+ *Thread Reply:* like every input being added in this manner: +``` public void addInput(ExprId exprId, DatasetIdentifier datasetIdentifier, String attributeName) { + inputs.computeIfAbsent(exprId, k -> new LinkedList<>());
+ +Pair<DatasetIdentifier, String> input = Pair.of(datasetIdentifier, attributeName);
+
+if (!inputs.get(exprId).contains(input)) {
+ inputs.get(exprId).add(input);
+}
+}``
+it's a candidate: it has to traverse the list returned frominputs` for every CLL dependency field added
+
+
+ *Thread Reply:* it looks like we're building size N list in N^2 time:
+inputs.stream()
+ .filter(i -> i instanceof InputDatasetFieldWithIdentifier)
+ .map(i -> (InputDatasetFieldWithIdentifier) i)
+ .forEach(
+ i ->
+ context
+ .getBuilder()
+ .addInput(
+ ExprId.apply(i.exprId().exprId()),
+ new DatasetIdentifier(
+ i.datasetIdentifier().getNamespace(), i.datasetIdentifier().getName()),
+ i.field()));
+🙂
+
+
+ *Thread Reply:* ah, this isn't even used now since it's for new extension-based spark collection
+ + + +
+
+
+ *Thread Reply:* @Paweł Leszczyński this is most likely a future bug ⬆️
+ + + +
+
+
+ *Thread Reply:* I think we're still doing it now anyway:
+``` private static void extractInternalInputs(
+ LogicalPlan node,
+ ColumnLevelLineageBuilder builder,
+ List
datasetIdentifiers.stream()
+ .forEach(
+ di -> {
+ ScalaConversionUtils.fromSeq(node.output()).stream()
+ .filter(attr -> attr instanceof AttributeReference)
+ .map(attr -> (AttributeReference) attr)
+ .collect(Collectors.toList())
+ .forEach(attr -> builder.addInput(attr.exprId(), di, attr.name()));
+ });
+}```
+ + + +
+
+
+ *Thread Reply:* and that's linked list - must be pretty slow jumping all those pointers
+ + + +
+
+
+ *Thread Reply:* maybe it's that simple 🙂 +https://github.com/OpenLineage/OpenLineage/commit/306778769ae10fa190f3fd0eff7a6482fc50f57f
+ + + +
+
+
+ *Thread Reply:* There are some more funny places in CLL code, like we're iterating over list of schema fields and calling some function with name of that field :
+schema.getFields().stream()
+ .map(field -> Pair.of(field, getInputsUsedFor(field.getName())))
+then immediately iterate over it second time to get the field back from it's name:
+List<Pair<DatasetIdentifier, String>> getInputsUsedFor(String outputName) {
+ Optional<OpenLineage.SchemaDatasetFacetFields> outputField =
+ schema.getFields().stream()
+ .filter(field -> field.getName().equalsIgnoreCase(outputName))
+ .findAny();
+
+
+ *Thread Reply:* I think the time spent by the driver (5 hours) just on these methods smells like an infinite loop?
+ + + +
+
+
+ *Thread Reply:* like, as inefficient as it may be, this is a lot of time
+ + + +
+
+
+ *Thread Reply:* did it finish eventually?
+ + + +
+
+
+ *Thread Reply:* yes... but.. I wonder if something killed it somewhere?
+ + + +
+
+
+ *Thread Reply:* I mean, it can be something like 10000^3 loop 🙂
+ + + +
+
+
+ *Thread Reply:* I couldn't find anything in the logs to indicate
+ + + +
+
+
+ *Thread Reply:* and it has to do those pair comparisons
+ + + +
+
+
+ *Thread Reply:* would be easier if we could see the general size of a plan of this job - if it's something really small then I'm probably wrong
+ + + +
+
+
+ *Thread Reply:* but if there are 1000s of columns... anything can happen 🙂
+ + + +
+
+
+ *Thread Reply:* yeah.. trying to find out. I don't have that facet enabled there, and I can't find the ol events in the logs (it's writing to console, and I think they got dropped)
+ + + +
+
+
+ *Thread Reply:* DevNullTransport 🙂
+ + + +
+
+
+ *Thread Reply:* I think this might be potentially really slow too https://github.com/OpenLineage/OpenLineage/blob/50afacdf731f810354be0880c5f1fd05a1[…]park/agent/lifecycle/plan/column/ColumnLevelLineageBuilder.java
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* generally speaking, we have a similar problem here like we had with Airflow integration
+ + + +
+
+
+ *Thread Reply:* we are not holding up the job per se, but... we are holding up the spark application
+ + + +
+
+
+ *Thread Reply:* do we have a way to be defensive about that somehow, shutdown hook from spark to our thread or something
+ + + +
+
+
+ *Thread Reply:* there's no magic
+ + + +
+
+
+ *Thread Reply:* circuit breaker with timeout does not work?
+ + + +
+
+
+ *Thread Reply:* it would, but we don't turn that on by default
+ + + +
+
+
+ *Thread Reply:* also, if we do, what should be our default values?
+ + + +
+
+
+ *Thread Reply:* what would not hurt you if you enabled it, 30 seconds?
+ + + +
+
+
+ *Thread Reply:* I guess we should aim much lower with the runtime
+ + + +
+
+
+ *Thread Reply:* yeah, and make sure we emit metrics / logs when that happens
+ + + +
+
+
+ *Thread Reply:* wait, our circuit breaker right now only supports cpu & memory
+ + + +
+
+
+ *Thread Reply:* we would need to add a timeout one, right?
+ + + +
+
+
+ *Thread Reply:* ah, yes
+ + + +
+
+
+ *Thread Reply:* we've talked about it but it's not implemented yet https://github.com/OpenLineage/OpenLineage/blob/3dad978a3a76ea9bb709334f1526086f95[…]o/openlineage/client/circuitBreaker/ExecutorCircuitBreaker.java
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* and BTW, no abnormal CPU or memory usage?
+ + + +
+
+
+ *Thread Reply:* nope, not at all
+ + + +
+
+
+
+
+
+
+
+
+ *Thread Reply:* I mean, it's using 100% of one core 🙂
+ + + +
+
+
+ *Thread Reply:* it's similar to what aniruth experienced. there's something that for some type of logical plans causes recursion alike behaviour. However, I don't think it's recursion bcz it's ending at some point. If we had DebugFacet we would be able to know which logical plan nodes are involved in this.
+ + + +
+
+
+ *Thread Reply:* I'll try to get that for us
+ + + +
+
+
+ *Thread Reply:* > If we had DebugFacet we would be able to know which logical plan nodes are involved in this. +if the event would not take 1GB 🙂
+ + + +
+
+
+ *Thread Reply:* > it's similar to what aniruth experienced. there's something that for some type of logical plans causes recursion alike behaviour. However, I don't think it's recursion bcz it's ending at some point. If we had DebugFacet we would be able to know which logical plan nodes are involved in this. (edited) +what about my thesis that something is just extremely slow in column-level lineage code?
+ + + +
+
+
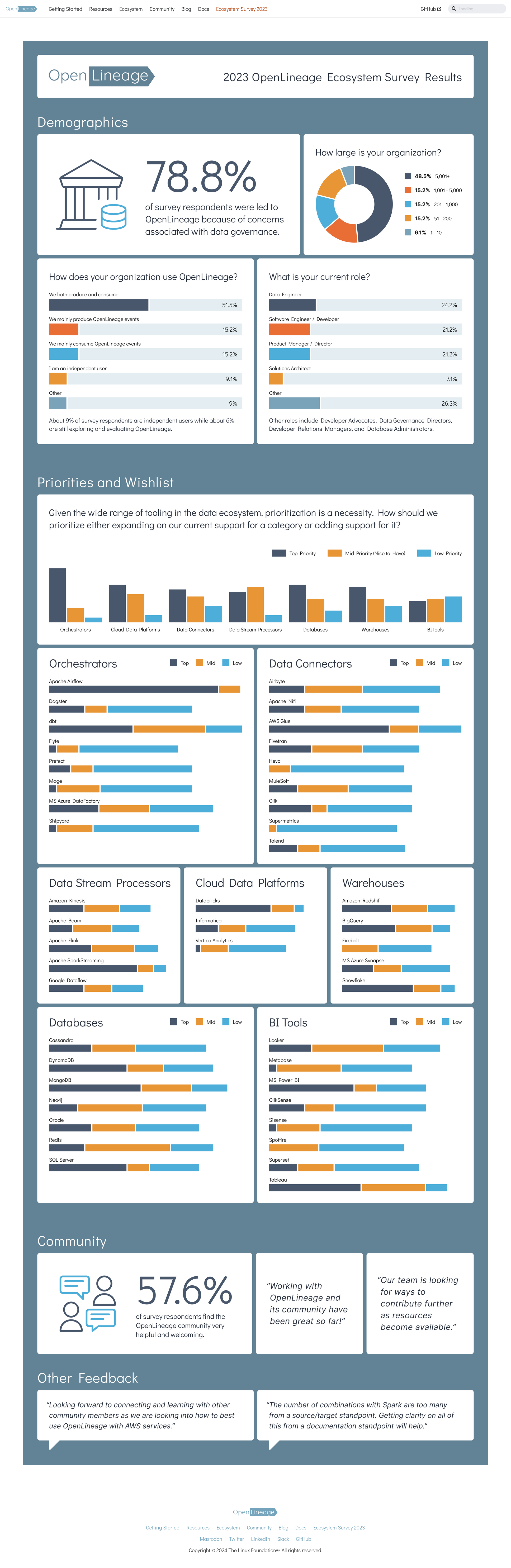
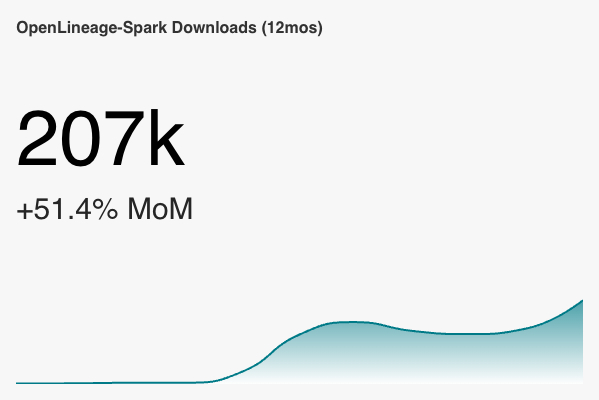
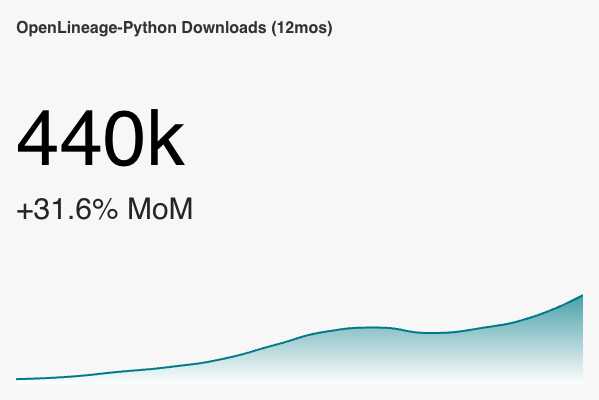
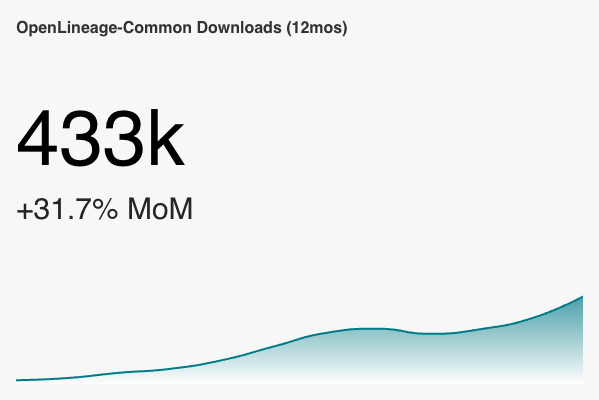
+ Some adoption metrics from Sonatype and PyPI, visualized using Preset. In Preset, you can see the number for each month (but we're out of seats on the free tier there). The big number is the downloads for the last month (February in most cases).
+ + +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+
+
+
+
+ Good news. @Paweł Leszczyński - the memory leak fixes worked. Our streaming pipelines have run through the weekend without a single OOM crash.
+ + + +
+
+
+ *Thread Reply:* @Damien Hawes Would you please point me the PR that fixes the issue?
+ + + +
+
+
+ *Thread Reply:* This was the issue: https://github.com/OpenLineage/OpenLineage/issues/2561
+ +There were two PRs:
+ +
+
+
+ *Thread Reply:* @Peter Huang ^
+ + + +
+
+
+ *Thread Reply:* @Damien Hawes any other feedback for OL with streaming pipelines you have so far?
+ + + +
+
+
+ *Thread Reply:* It generates a TON of data
+ + + +
+
+
+ *Thread Reply:* There are some optimisations that could be made:
+ +job start -> stage submitted -> task started -> task ended -> stage complete -> job end cycle fires more frequently.
+
+
+ *Thread Reply:* This has an impact on any backend using it, as the run id keeps changing. This means the parent suddenly has thousands of jobs as children.
+ + + +
+
+
+ *Thread Reply:* Our biggest pipeline generates a new event cycle every 2 minutes.
+ + + +
+
+
+ *Thread Reply:* "Too much data" is exactly what I thought 🙂 +The obvious potential issue with caching is the same issue we just fixed... potential memory leaks, and cache invalidation
+ + + +
+
+
+ *Thread Reply:* > the run id keeps changing
+In this case, that's a bug. We'd still need some wrapping event for whole streaming job though, probably other than application start
+
+
+ *Thread Reply:* on the other topic, did those problems stop? https://github.com/OpenLineage/OpenLineage/issues/2513 +with https://github.com/OpenLineage/OpenLineage/pull/2535/files
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ when talking about the naming scheme for datasets, would everyone here agree that we generally use: {scheme}://{authority}/{unique_name} ? where generally authority == namespace
+
+
+ *Thread Reply:* I think so, and if we don’t then we should
+ + + +
+
+
+ *Thread Reply:* ~which brings me to the question why construct dataset name as such~ nvm
+ + + +
+
+
+ *Thread Reply:* please feel free to chime in here too https://github.com/dbt-labs/dbt-core/issues/8725
+ + + +
+
+
+ *Thread Reply:* > where generally authority == namespace (edited)
+{scheme}://{authority} is namespace
+
+
+ *Thread Reply:* agreed
+ + + +Is it the case that Open Lineage defines the general framework but doesn’t actually enforce push or pull-based implementations, it just so happens that the reference implementation (Marquez) uses push?
@@ -8043,7 +8047,7 @@*Thread Reply:*
*Thread Reply:*
*Thread Reply:*
@@ -9685,7 +9693,7 @@*Thread Reply:*
Build on main passed (edited)
@@ -12784,6 +12796,43 @@ +
+
+
+
+
+ I added this configuration to my cluster :
@@ -12891,11 +12944,15 @@I receive this error message:
@@ -13097,11 +13154,15 @@*Thread Reply:*
@@ -13251,11 +13312,15 @@Now I have this:
@@ -13416,11 +13481,15 @@*Thread Reply:* Hi , @Luke Smith, thank you for your help, are you familiar with this error in azure databricks when you use OL?
@@ -13451,11 +13520,15 @@*Thread Reply:*
@@ -13508,11 +13581,15 @@*Thread Reply:* Successfully got a basic prefect flow working
@@ -22372,29 +22453,41 @@Hey there, I’m not sure why I’m getting below error, after I ran OPENLINEAGE_URL=<http://localhost:5000> dbt-ol run , although running this command dbt debug doesn’t show any error. Pls help.
*Thread Reply:* Actually i had to use venv that fixed above issue. However, i ran into another problem which is no jobs / datasets found in marquez:
*Thread Reply:*
@@ -24252,20 +24361,28 @@*Thread Reply:* oh got it, since its in default, i need to click on it and choose my dbt profile’s account name. thnx
@@ -24357,11 +24478,15 @@*Thread Reply:* May I know, why these highlighted ones dont have schema? FYI, I used sources in dbt.
@@ -24418,11 +24543,15 @@*Thread Reply:* I prepared this yaml file, not sure this is what u asked
@@ -27866,11 +27995,15 @@I have a dag that contains 2 tasks:
@@ -28832,11 +28965,15 @@It created 3 namespaces. One was the one that I point in the spark config property. The other 2 are the bucket that we are writing to (
I can see if i enter in one of the weird jobs generated this:
@@ -28963,11 +29108,15 @@*Thread Reply:* This job with no output is a symptom of the output not being understood. you should be able to see the facets for that job. There will be a spark_unknown facet with more information about the problem. If you put that into an issue with some more details about this job we should be able to help.
If I check the logs of marquez-web and marquez I can't see any error there
When I try to open the job fulfilments.execute_insert_into_hadoop_fs_relation_command I see this window:
*Thread Reply:* Here's what I mean:
@@ -31226,7 +31391,7 @@*Thread Reply:* This is an example Lineage event JSON I am sending.
*Thread Reply:* There are two types of failures: tests failed on stage model (relationships) and physical error in master model (no table with such name). The stage test node in Marquez does not show any indication of failures and dataset node indicates failure but without number of failed records or table name for persistent test storage. The failed master model shows in red but no details of failure. Master model tests were skipped because of model failure but UI reports "Complete".
@@ -35638,20 +35839,28 @@dbt test failures, to visualize better that error is happening, for example like that:
@@ -35823,11 +36032,15 @@ hello everyone , i'm learning Openlineage, I am trying to connect with airflow 2, is it possible? or that version is not yet released. this is currently throwing me airflow
@@ -36077,6 +36290,43 @@ +
+
+
+
+
+  +
+
+
+
+
+
+
+ *Thread Reply:* It needs to show Docker Desktop is running :
I've attached the logs and a screenshot of what I'm seeing the Spark UI. If you had a chance to take a look, it's a bit verbose but I'd appreciate a second pair of eyes on my analysis. Hopefully I got something wrong 😅
@@ -39983,11 +40253,15 @@*Thread Reply:* This is the one I wrote:
*Thread Reply:* however I can not fetch initial data when login into the endpoint
@@ -41681,11 +41959,15 @@@Kevin Mellott Hello Kevin, sorry to bother you again. I was finally able to configure Marquez in AWS using an ALB. Now I am receiving this error when calling the API
@@ -44042,11 +44328,15 @@Am i supposed to see this when I open marquez fro the first time on an empty database?
@@ -44433,11 +44723,15 @@Hi Everyone, Can someone please help me to debug this error ? Thank you very much all
@@ -49555,11 +49861,15 @@Hello everyone, I'm learning Openlineage, I finally achieved the connection between Airflow 2+ and Openlineage+Marquez. The issue is that I don't see nothing on Marquez. Do I need to modify current airflow operators?
@@ -49642,11 +49952,15 @@*Thread Reply:* Thanks, finally was my error .. I created a dummy dag to see if maybe it's an issue over the dag and now I can see something over Marquez
@@ -49824,7 +50142,7 @@happy to share the slides with you if you want 👍 here’s a PDF:
@@ -51028,11 +51350,15 @@Your periodical reminder that Github stars are one of those trivial things that make a significant difference for an OS project like ours. Have you starred us yet?
@@ -53756,11 +54082,15 @@*Thread Reply:*
@@ -53959,11 +54293,15 @@This is a similar setup as Michael had in the video.
@@ -54438,11 +54776,15 @@Hi~all, I have a question about lineage. I am now running airflow 2.3.1 and have started a latest marquez service by docker-compose. I found that using the example DAG of airflow can only see the job information, but not the lineage of the job. How can I configure it to see the lineage ?
@@ -57725,20 +58091,28 @@Hello all, after sending dbt openlineage events to Marquez, I am now looking to use the Marquez API to extract the lineage information. I am able to use python requests to call the Marquez API to get other information such as namespaces, datasets, etc., but I am a little bit confused about what I need to enter to get the lineage. I included screenshots for what the API reference shows regarding retrieving the lineage where it shows that a nodeId is required. However, this is where I seem to be having problems. It is not exactly clear where the nodeId needs to be set or what the nodeId needs to include. I would really appreciate any insights. Thank you!
@@ -57797,11 +58171,15 @@*Thread Reply:* You can do this in a few ways (that I can think of). First, by looking for a namespace, then querying for the datasets in that namespace:
@@ -57832,11 +58210,15 @@*Thread Reply:* Or you can search, if you know the name of the dataset:
@@ -60640,6 +61022,43 @@ +
+
+
+
+
+
+
+
+
+
+
+ check this out folks - marklogic datahub flow lineage into OL/marquez with jobs and runs and more. i would guess this is a pretty narrow use case but it went together really smoothly and thought i'd share sometimes it's just cool to see what people are working on
@@ -64118,11 +64578,15 @@Hi all, I have been playing around with Marquez for a hackday. I have been able to get some lineage information loaded in (using the local docker version for now). I have been trying set the location (for the link) and description information for a job (the text saying "Nothing to show here") but I haven't been able to figure out how to do this using the /lineage api. Any help would be appreciated.
Putting together some internal training for OpenLineage and highlighting some of the areas that have been useful to me on my journey with OpenLineage. Many thanks to @Michael Collado, @Maciej Obuchowski, and @Paweł Leszczyński for the continued technical support and guidance.
@@ -65257,20 +65725,28 @@hi all, really appreciate if anyone could help. I have been trying to create a poc project with openlineage with dbt. attached will be the pip list of the openlineage packages that i have. However, when i run "dbt-ol"command, it prompted as öpen as file, instead of running as a command. the regular dbt run can be executed without issue. i would want i had done wrong or if any configuration that i have missed. Thanks a lot
@@ -65649,7 +66125,7 @@./gradlew :shared:spotlessApply && ./gradlew :app:spotlessApply && ./gradlew clean build test
maybe another question for @Paweł Leszczyński: I was watching the Airflow summit talk that you and @Maciej Obuchowski did ( very nice! ). How is this exposed? I'm wondering if it shows up as an edge on the graph in Marquez? ( I guess it may be tracked as a parent run and if so probably does not show on the graph directly at this time? )
@@ -66869,11 +67349,15 @@*Thread Reply:*
@@ -68877,11 +69361,15 @@*Thread Reply:* After I send COMPLETE event with the same information I can see the dataset.
In this example I've added my-test-input on START and my-test-input2 on COMPLETE :
Here is the Marquez UI
@@ -72430,11 +72926,15 @@*Thread Reply:*
@@ -77177,11 +77677,15 @@*Thread Reply:* Apparently the value is hard coded in the code somewhere that I couldn't figure out but at-least learnt that in my Mac where this port 5000 is being held up can be freed by following the below simple step.
@@ -84818,11 +85322,15 @@But if I am not in a virtual environment, it installs the packages in my PYTHONPATH. You might try this to see if the dbt-ol script can be found in one of the directories in sys.path.
*Thread Reply:* this can help you verify that your PYTHONPATH and PATH are correct - installing an unrelated python command-line tool and seeing if you can execute it:
*Thread Reply:*
@@ -93252,11 +93768,15 @@Hi Team, I’m seeing creating data source, dataset API’s marked as deprecated . Can anyone point me how to create datasets via API calls?
@@ -94211,11 +94731,15 @@Is it possible to add column level lineage via api? Let's say I have fields A,B,C from my-input, and A,B from my-output, and B,C from my-output-s3. I want to see, filter, or query by the column name.
@@ -97313,11 +97837,15 @@23/04/20 10:00:15 INFO ConsoleTransport: {"eventType":"START","eventTime":"2023-04-20T10:00:15.085Z","run":{"runId":"ef4f46d1-d13a-420a-87c3-19fbf6ffa231","facets":{"spark.logicalPlan":{"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.22.0/integration/spark","schemaURL":"https://openlineage.io/spec/1-0-5/OpenLineage.json#/$defs/RunFacet","plan":[{"class":"org.apache.spark.sql.catalyst.plans.logical.CreateTableAsSelect","num-children":2,"name":0,"partitioning":[],"query":1,"tableSpec":null,"writeOptions":null,"ignoreIfExists":false},{"class":"org.apache.spark.sql.catalyst.analysis.ResolvedTableName","num-children":0,"catalog":null,"ident":null},{"class":"org.apache.spark.sql.catalyst.plans.logical.Project","num-children":1,"projectList":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num_children":0,"name":"workorderid","dataType":"integer","nullable":true,"metadata":{},"exprId":{"product-cl
@@ -99066,11 +99594,15 @@Hi, I'm new to Open data lineage and I'm trying to connect snowflake database with marquez using airflow and getting the error in etl_openlineage while running the airflow dag on local ubuntu environment and unable to see the marquez UI once it etl_openlineage has ran completed as success.
*Thread Reply:* What's the extract_openlineage.py file? Looks like your code?
*Thread Reply:* This is my log in airflow, can you please prvide more info over it.
@@ -99735,20 +100275,28 @@*Thread Reply:*
@@ -101255,11 +101811,15 @@I have configured Open lineage with databricks and it is sending events to Marquez as expected. I have a notebook which joins 3 tables and write the result data frame to an azure adls location. Each time I run the notebook manually, it creates two start events and two complete events for one run as shown in the screenshot. Is this something expected or I am missing something?
@@ -102859,11 +103423,15 @@I have a usecase where we are connecting to Azure sql database from databricks to extract, transform and load data to delta tables. I could see the lineage is getting build, but there is no column level lineage through its 1:1 mapping from source. Could you please check and update on this.
@@ -102977,7 +103545,7 @@*Thread Reply:* Here is the code we use.
@Paweł Leszczyński @Michael Robinson
I can see my job there but when i click on the job when its supposed to show lineage, its just an empty screen
@@ -108535,11 +109107,15 @@*Thread Reply:* ohh but if i try using the console output, it throws ClientProtocolError
@@ -108596,11 +109172,15 @@*Thread Reply:* this is the dev console in browser
@@ -108831,11 +109411,15 @@*Thread Reply:* marquez didnt get updated
@@ -109339,6 +109923,43 @@ +
+
+
+
+
+  +
+
+
+
+
+
+
+ *Thread Reply:* @Michael Robinson When we follow the documentation without changing anything and run sudo ./docker/up.sh we are seeing following errors:
@@ -110112,11 +110741,15 @@*Thread Reply:* So, I edited up.sh file and modified docker compose command by removing --log-level flag and ran sudo ./docker/up.sh and found following errors:
@@ -110147,11 +110780,15 @@*Thread Reply:* Then I copied .env.example to .env since compose needs .env file
@@ -110182,11 +110819,15 @@*Thread Reply:* I got this error:
@@ -110273,11 +110914,15 @@*Thread Reply:* @Michael Robinson Then it kind of worked but seeing following errors:
@@ -110308,11 +110953,15 @@*Thread Reply:*
@@ -110656,11 +111305,15 @@*Thread Reply:*
@@ -111536,7 +112189,7 @@*Thread Reply:* This is the event generated for above query.
this is event for view for which no lineage is being generated
Hi, I am running a job in Marquez with 180 rows of metadata but it is running for more than an hour. Is there a way to check the log on Marquez? Below is the screenshot of the job:
@@ -116278,11 +116943,15 @@*Thread Reply:* Also, yes, we have an even viewer that allows you to query the raw OL events
@@ -116339,7 +117008,7 @@*Thread Reply:*
I can now see this
@@ -117487,11 +118164,15 @@*Thread Reply:* but when i click on the job i then get this
@@ -117548,11 +118229,15 @@*Thread Reply:* @George Polychronopoulos Hi, I am facing the same issue. After adding spark conf and using the docker run command, marquez is still showing empty. Do I need to change something in the run command?
@@ -119539,11 +120224,15 @@ +
+
Expected. vs Actual.
 +
+
+
+
+
+ The OL-spark version is matching the Spark version? Is there a known issues with the Spark / OL versions ?
@@ -124345,20 +125100,28 @@*Thread Reply:* I assume the problem is somewhere there, not on the level of facet definition, since SchemaDatasetFacet looks pretty much the same and it works
*Thread Reply:*
@@ -125192,11 +125967,15 @@*Thread Reply:* I think the code here filters out those string values in the list
@@ -125426,11 +126205,15 @@ +
@@ -126744,6 +127527,130 @@
+
@@ -126744,6 +127527,130 @@  +
+
+
+
+
+ *Thread Reply:* @Paweł Leszczyński @Maciej Obuchowski +can you please approve this CI to run integration tests? +https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/9497/workflows/4a20dc95-d5d1-4ad7-967c-edb6e2538820
+ + + +
+
+
+ *Thread Reply:* @Paweł Leszczyński +only 2 spark version are sending empty +input and output +for both START and COMPLETE event
+ +++ + + +• 3.4.2 + • 3.5.0 + i can look into the above , if you guide me a bit on how to ? + should i open a new ticket for it? + please suggest how to proceed?
+
+
+
+ *Thread Reply:* this integration test case lead to finding of the above bug for spark 3.4.2 and 3.5.0 +will that be a blocker to merge this test case? +@Paweł Leszczyński @Maciej Obuchowski
+ + + +
+
+
+ *Thread Reply:* @Paweł Leszczyński @Maciej Obuchowski +any direction on the above blocker will be helpful.
+ + + +I was doing this a second ago and this ended up with Caused by: java.lang.ClassNotFoundException: io.openlineage.spark.agent.OpenLineageSparkListener not found in com.databricks.backend.daemon.driver.ClassLoaders$LibraryClassLoader@1609ed55
*Thread Reply:* Can you please share with me your json conf for the cluster ?
@@ -128901,11 +129816,15 @@*Thread Reply:* It's because in mu build file I have
@@ -128936,11 +129855,15 @@*Thread Reply:* and the one that was copied is
@@ -132181,20 +133104,28 @@Hello, I'm currently in the process of following the instructions outlined in the provided getting started guide at https://openlineage.io/getting-started/. However, I've encountered a problem while attempting to complete *Step 1* of the guide. Unfortunately, I'm encountering an internal server error at this stage. I did manage to successfully run Marquez, but it appears that there might be an issue that needs to be addressed. I have attached screen shots.
@@ -132251,11 +133182,15 @@*Thread Reply:* @Jakub Dardziński 5000 port is not taken by any other application. The logs show some errors but I am not sure what is the issue here.
@@ -134980,11 +135915,15 @@*Thread Reply:* This is the error message:
@@ -135041,11 +135980,15 @@I am trying to run Google Cloud Composer where i have added the openlineage-airflow pypi packagae as a dependency and have added the env OPENLINEAGEEXTRACTORS to point to my custom extractor. I have added a folder by name dependencies and inside that i have placed my extractor file, and the path given to OPENLINEAGEEXTRACTORS is dependencies.<filename>.<extractorclass_name>…still it fails with the exception saying No module named ‘dependencies’. Can anyone kindly help me out on correcting my mistake
@@ -135365,11 +136308,15 @@*Thread Reply:*
@@ -135427,11 +136374,15 @@*Thread Reply:*
@@ -135488,11 +136439,15 @@*Thread Reply:* https://openlineage.slack.com/files/U05QL7LN2GH/F05SUDUQEDN/screenshot_2023-09-13_at_5.31.22_pm.png
@@ -135679,7 +136634,7 @@*Thread Reply:* these are the worker pod logs…where there is no log of openlineageplugin
*Thread Reply:* this is one of the experimentation that i have did, but then i reverted it back to keeping it to dependencies.bigqueryinsertjobextractor.BigQueryInsertJobExtractor…where dependencies is a module i have created inside my dags folder
@@ -135856,11 +136815,15 @@*Thread Reply:* https://openlineage.slack.com/files/U05QL7LN2GH/F05RM6EV6DV/screenshot_2023-09-13_at_12.38.55_am.png
@@ -135891,11 +136854,15 @@*Thread Reply:* these are the logs of the triggerer pod specifically
@@ -135978,11 +136945,15 @@*Thread Reply:* these are the logs of the worker pod at startup, where it does not complain of the plugin like in triggerer, but when tasks are run on this worker…somehow it is not picking up the extractor for the operator that i have written it for
@@ -136272,11 +137243,15 @@*Thread Reply:* have changed the dags folder where i have added the init file as you suggested and then have updated the OPENLINEAGEEXTRACTORS to bigqueryinsertjob_extractor.BigQueryInsertJobExtractor…still the same thing
@@ -136502,11 +137477,15 @@*Thread Reply:* I’ve done experiment, that’s how gcs looks like
@@ -136537,11 +137516,15 @@*Thread Reply:* and env vars
@@ -137171,7 +138154,7 @@*Thread Reply:*
I am attaching the log4j, there is no openlineagecontext
*Thread Reply:* A few more pics:
@@ -143258,16 +144273,20 @@@here I am trying out the openlineage integration of spark on databricks. There is no event getting emitted from Openlineage, I see logs saying OpenLineage Event Skipped. I am attaching the Notebook that i am trying to run and the cluster logs. Kindly can someone help me on this
*Thread Reply:* @Paweł Leszczyński this is what I am getting
@@ -144858,7 +145881,7 @@*Thread Reply:* attaching the html
*Thread Reply:* @Paweł Leszczyński you are right. This is what we are doing as well, combining events with the same runId to process the information on our backend. But even so, there are several runIds without this information. I went through these events to have a better view of what was happening. As you can see from 7 runIds, only 3 were showing the "environment-properties" attribute. Some condition is not being met here, or maybe it is what @Jason Yip suspects and there's some sort of filtering of unnecessary events
@@ -146215,11 +147242,15 @@*Thread Reply:* In docker, marquez-api image is not running and exiting with the exit code 127.
@@ -146765,11 +147796,15 @@Im upgrading the version from openlineage-airflow==0.24.0 to openlineage-airflow 1.4.1 but im seeing the following error, any help is appreciated
@@ -147274,11 +148309,15 @@*Thread Reply:* I see the difference of calling in these 2 versions, current versions checks if Airflow is >2.6 then directly runs on_running but earlier version was running on separate thread. IS this what's raising this exception?
@@ -148593,7 +149632,7 @@*Thread Reply:*
@Paweł Leszczyński I tested 1.5.0, it works great now, but the environment facets is gone in START... which I very much want it.. any thoughts?
@Paweł Leszczyński I went back to 1.4.1, output does show adls location. But environment facet is gone in 1.4.1. It shows up in 1.5.0 but namespace is back to dbfs....
like ( file_name, size, modification time, creation time )
@@ -154451,11 +155494,15 @@execute_spark_script(1, "/home/haneefa/airflow/dags/saved_files/")
@@ -155287,12 +156334,12 @@ I was referring to fluentd openlineage proxy which lets users copy the event and send it to multiple backend. Fluentd has a list of out-of-the box output plugins containing BigQuery, S3, Redshift and others (https://www.fluentd.org/dataoutputs)
 +
@@ -157316,7 +158363,7 @@
+
@@ -157316,7 +158363,7 @@ *Thread Reply:* This text file contains a total of 10-11 events, including the start and completion events of one of my notebook runs. The process is simply reading from a Hive location and performing a full load to another Hive location.
 +
@@ -161188,12 +162235,12 @@
+
@@ -161188,12 +162235,12 @@ *Thread Reply:* in Admin > Plugins can you see whether you have OpenLineageProviderPlugin and if so, are there listeners?
 +
@@ -161292,7 +162339,7 @@
+
@@ -161292,7 +162339,7 @@ *Thread Reply:* Dont
*Thread Reply:*
 +
+
+
+
+
+
+
+  +
+  @@ -163600,7 +164680,7 @@
@@ -163600,7 +164680,7 @@ Do we have the functionality to search on the lineage we are getting?
 +
+ *Thread Reply:*
any suggestions on naming for Graph API sources from outlook? I pull a lot of data from email attachments with Airflow. generally I am passing a resource (email address), the mailbox, and subfolder. from there I list messages and find attachments
 +
+ Hello team I see the following issue when i install apache-airflow-providers-openlineage==1.4.0
 +
+  +
@@ -168984,12 +170064,12 @@
+
@@ -168984,12 +170064,12 @@  +
@@ -169177,6 +170257,32 @@
+
+
+
+
@@ -169177,6 +170257,32 @@
+
+
+ *Thread Reply:* @jayant joshi did deleting all volumes work for you, or did you discover another solution? We see users encountering this error from time to time, and it would be helpful to know more.
+ + + +"spark-submit --conf "spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener" --packages "io.openlineage:openlineagespark:1.7.0" --conf "spark.openlineage.transport.type=http" --conf "spark.openlineage.transport.url= http://marquez-api:5000" --conf "spark.openlineage.namespace=sparkintegration" pyspark_etl.py".
 +
@@ -169715,12 +170821,12 @@
+
@@ -169715,12 +170821,12 @@ *Thread Reply:* Find the attached localhost 5000 & 5001 port results. Note that while running same code in the jupyter notebook, I could see lineage on the Marquez UI. For running a code through spark-submit only I am facing an issue.
 +
@@ -170234,12 +171340,12 @@
+
@@ -170234,12 +171340,12 @@ *Thread Reply:* From your code, I could see marquez-api is running successfully at "http://marquez-api:5000". Find attached screenshot.
 +
@@ -170485,12 +171591,12 @@
+
@@ -170485,12 +171591,12 @@ *Thread Reply:* the quickstart guide shows this example and it produces the result with a output node in the results, But when I run this in databricks I see no output node generated.
 +
@@ -170579,12 +171685,12 @@
+
@@ -170579,12 +171685,12 @@ *Thread Reply:* as a result onkar_table as a dataset was never recorded hence lineage between mayur_table and onkar_table was not recorded as well
 +
@@ -170592,12 +171698,12 @@
+
@@ -170592,12 +171698,12 @@  +
@@ -170981,12 +172087,12 @@
+
@@ -170981,12 +172087,12 @@  +
@@ -171473,12 +172579,12 @@
+
@@ -171473,12 +172579,12 @@ Error Screenshot:
 +
@@ -171543,12 +172649,12 @@
+
@@ -171543,12 +172649,12 @@  +
@@ -171610,12 +172716,12 @@
+
@@ -171610,12 +172716,12 @@ *Thread Reply:* While composing up an open lineage docker-compose.yml. It showed the path to access jupyter lab, through the path I am accessing it. I didn't run any command externally. Find the attached screenshot.
 +
@@ -171706,12 +172812,12 @@
+
@@ -171706,12 +172812,12 @@  +
@@ -172212,12 +173318,12 @@
+
@@ -172212,12 +173318,12 @@ listeners should be there under OpenLineageProviderPlugin
 +
@@ -172408,12 +173514,12 @@
+
@@ -172408,12 +173514,12 @@ *Thread Reply:* This is the snapshot of my Plugins. I will also try with the configs which you mentioned.
 +
@@ -173078,12 +174184,12 @@
+
@@ -173078,12 +174184,12 @@  +
@@ -173091,12 +174197,12 @@
+
@@ -173091,12 +174197,12 @@  +
+  +
@@ -173417,12 +174523,12 @@
+
@@ -173417,12 +174523,12 @@  +
@@ -173484,12 +174590,12 @@
+
@@ -173484,12 +174590,12 @@  +
@@ -173549,12 +174655,12 @@
+
@@ -173549,12 +174655,12 @@ *Thread Reply:* Probably you might ask this.
 +
@@ -173615,12 +174721,12 @@
+
@@ -173615,12 +174721,12 @@  +
@@ -174651,12 +175757,12 @@
+
@@ -174651,12 +175757,12 @@  +
@@ -174912,12 +176018,12 @@
+
@@ -174912,12 +176018,12 @@ *Thread Reply:*
 +
@@ -174951,12 +176057,12 @@
+
@@ -174951,12 +176057,12 @@ *Thread Reply:*
 +
@@ -174990,12 +176096,12 @@
+
@@ -174990,12 +176096,12 @@ *Thread Reply:*
 +
@@ -175057,12 +176163,12 @@
+
@@ -175057,12 +176163,12 @@ I did an airflow backfill job which redownloaded all files from a SFTP (191 files) and each of those are a separate OL dataset. in this view I clicked on a single file, but because it is connected to the "extract" airflow task, it shows all of the files that task downloaded as well (dynamic mapped tasks in Airflow)
+ +
+
+
+
+
+ *Thread Reply:* @Matthew Paras Hi! +im still struggling with empty outputs on databricks with OL latest version.
+ +24/03/13 16:35:56 INFO PlanUtils: apply method failed with +org.apache.spark.SparkException: There is no Credential Scope. Current env: Driver
+ +Any idea on how to solve this?
+ + + +
+
+
+ *Thread Reply:* Any databricks runtime version i should test with?
+ + + + +
+
+
+
+
+ *Thread Reply:* interesting, I think we're running on 13.3 LTS - we also haven't upgraded to the official OL version, still using the patched one that I built
+ + +
+
+
+ *Thread Reply:* @Athitya Kumar can you tell us if this resolved your issue?
+ + + + +
+
+
+
+
+ *Thread Reply:* @Michael Robinson - Yup, it's resolved for event types that're already being emitted from OpenLineage - but we have some events like StageCompleted / TaskEnd etc where we don't send events currently, where we'd like to plug-in our CustomFacets
+ + +
+
+
+ *Thread Reply:* @Athitya Kumar can you store the facets somewhere (like OpenLineageContext) and send them with complete event later?
*Thread Reply:* here is an axample:
 +
@@ -178704,12 +180015,12 @@
+
@@ -178704,12 +180015,12 @@  +
@@ -179063,19 +180374,177 @@
+
@@ -179063,19 +180374,177 @@  +
-
+
- *Thread Reply:* Seems like its on OpenLineageSparkListener.onJobEnd
+```24/02/25 16:12:49 INFO PlanUtils: apply method failed with
+java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext.
+This stopped SparkContext was created at:
org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58) +sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) +sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) +sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) +java.lang.reflect.Constructor.newInstance(Constructor.java:423) +py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247) +py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) +py4j.Gateway.invoke(Gateway.java:238) +py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80) +py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69) +py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182) +py4j.ClientServerConnection.run(ClientServerConnection.java:106) +java.lang.Thread.run(Thread.java:750)
+ +The currently active SparkContext was created at:
+ +org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58) +sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) +sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) +sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) +java.lang.reflect.Constructor.newInstance(Constructor.java:423) +py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247) +py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) +py4j.Gateway.invoke(Gateway.java:238) +py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80) +py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69) +py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182) +py4j.ClientServerConnection.run(ClientServerConnection.java:106) +java.lang.Thread.run(Thread.java:750)
+ +at org.apache.spark.SparkContext.assertNotStopped(SparkContext.scala:121) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SparkSession.<init>(SparkSession.scala:113) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:962) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SQLContext$.getOrCreate(SQLContext.scala:1023) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SQLContext.getOrCreate(SQLContext.scala) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.hudi.client.common.HoodieSparkEngineContext.<init>(HoodieSparkEngineContext.java:65) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.SparkHoodieTableFileIndex.<init>(SparkHoodieTableFileIndex.scala:65) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.HoodieFileIndex.<init>(HoodieFileIndex.scala:81) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.HoodieBaseRelation.fileIndex$lzycompute(HoodieBaseRelation.scala:236) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.HoodieBaseRelation.fileIndex(HoodieBaseRelation.scala:234) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.BaseFileOnlyRelation.toHadoopFsRelation(BaseFileOnlyRelation.scala:153) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource$.resolveBaseFileOnlyRelation(DefaultSource.scala:268) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource$.createRelation(DefaultSource.scala:232) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:111) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:68) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at io.openlineage.spark.agent.lifecycle.plan.SaveIntoDataSourceCommandVisitor.apply(SaveIntoDataSourceCommandVisitor.java:140) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.plan.SaveIntoDataSourceCommandVisitor.apply(SaveIntoDataSourceCommandVisitor.java:47) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder$1.apply(AbstractQueryPlanDatasetBuilder.java:94) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder$1.apply(AbstractQueryPlanDatasetBuilder.java:85) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.util.PlanUtils.safeApply(PlanUtils.java:279) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder.lambda$apply$0(AbstractQueryPlanDatasetBuilder.java:75) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at java.util.Optional.map(Optional.java:215) ~[?:1.8.0_392]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder.apply(AbstractQueryPlanDatasetBuilder.java:67) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder.apply(AbstractQueryPlanDatasetBuilder.java:39) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.util.PlanUtils.safeApply(PlanUtils.java:279) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.lambda$null$23(OpenLineageRunEventBuilder.java:451) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) ~[?:1.8.0_392]
+at java.util.Iterator.forEachRemaining(Iterator.java:116) ~[?:1.8.0_392]
+at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_392]
+at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:150) ~[?:1.8.0_392]
+at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:173) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:485) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline$7$1.accept(ReferencePipeline.java:272) ~[?:1.8.0_392]
+at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1384) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_392]
+at java.util.stream.StreamSpliterators$WrappingSpliterator.forEachRemaining(StreamSpliterators.java:313) ~[?:1.8.0_392]
+at java.util.stream.Streams$ConcatSpliterator.forEachRemaining(Streams.java:742) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_392]
+at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:566) ~[?:1.8.0_392]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildOutputDatasets(OpenLineageRunEventBuilder.java:410) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.populateRun(OpenLineageRunEventBuilder.java:298) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildRun(OpenLineageRunEventBuilder.java:281) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildRun(OpenLineageRunEventBuilder.java:259) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.end(SparkSQLExecutionContext.java:257) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.OpenLineageSparkListener.onJobEnd(OpenLineageSparkListener.java:167) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:39) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) ~[scala-library-2.12.15.jar:?]
+at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) ~[scala-library-2.12.15.jar:?]
+at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1447) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+24/02/25 16:13:04 INFO AsyncEventQueue: Process of event SparkListenerJobEnd(23,1708877534168,JobSucceeded) by listener OpenLineageSparkListener took 15.64437991s. +24/02/25 16:13:04 ERROR JniBasedUnixGroupsMapping: error looking up the name of group 1001: No such file or directory```
+ + + +
+
+
+ Lastly, would disabling facets improve performance? eg. disabling spark.logicalPlan
*Thread Reply:* Hmm yeah I'm confused, https://github.com/OpenLineage/OpenLineage/blob/1.6.2/integration/spark/shared/src/main/java/io/openlineage/spark/agent/util/PlanUtils.java#L277 seems to indicate as you said (safeApply swallows the exception), but the job exits after on an error code (EMR marks the job as failed)
The crash stops if I remove spark.stop() or disable the OpenLineage listener so this is odd 🤔
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
@@ -179099,15 +180568,56 @@ *Thread Reply:* Disabling spark.LogicalPlan may improve performance of populating OL event. It's disabled by default in recent version (the one released yesterday). You can also use circuit breaker feature if you are worried about Ol integration affecting Spark jobs
*Thread Reply:* 24/02/25 16:12:49 INFO PlanUtils: apply method failed with -> yeah, log level is info. It would look as if you were trying to run some action after stopping spark, but you said that disabling OpenLineage listener makes it succeed. This is odd.
+
+
+ *Thread Reply:* Maybe its some race condition on shutdown logic with event listeners? It seems like the listener being enabled is causing executors to be spun up (which fails) after the Spark session is already stopped
+ +• After the stacktrace above I see ConsoleTransport log some OpenLineage event data
+• Then oddly it looks like a bunch of executors are launched after the Spark session has already been stopped
+• These executors crash on startup which is likely whats causing the Spark job to exit with an error code
+24/02/24 07:18:03 INFO ConsoleTransport: {"eventTime":"2024_02_24T07:17:05.344Z","producer":"<https://github.com/OpenLineage/OpenLineage/tree/1.6.2/integration/spark>",
+...
+24/02/24 07:18:06 INFO YarnAllocator: Will request 1 executor container(s) for ResourceProfile Id: 0, each with 4 core(s) and 27136 MB memory. with custom resources: <memory:27136, max memory:2147483647, vCores:4, max vCores:2147483647>
+24/02/24 07:18:06 INFO YarnAllocator: Submitted 1 unlocalized container requests.
+24/02/24 07:18:09 INFO YarnAllocator: Launching container container_1708758297553_0001_01_000004 on host {ip} for executor with ID 3 for ResourceProfile Id 0 with resources <memory:27136, vCores:4>
+24/02/24 07:18:09 INFO YarnAllocator: Launching executor with 21708m of heap (plus 5428m overhead/off heap) and 4 cores
+24/02/24 07:18:09 INFO YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
+24/02/24 07:18:09 INFO YarnAllocator: Completed container container_1708758297553_0001_01_000003 on host: {ip} (state: COMPLETE, exit status: 1)
+24/02/24 07:18:09 WARN YarnAllocator: Container from a bad node: container_1708758297553_0001_01_000003 on host: {ip}. Exit status: 1. Diagnostics: [2024-02-24 07:18:06.508]Exception from container-launch.
+Container id: container_1708758297553_0001_01_000003
+Exit code: 1
+Exception message: Launch container failed
+Shell error output: Nonzero exit code=1, error message='Invalid argument number'
+The new executors all fail with:
+Caused by: org.apache.spark.rpc.RpcEndpointNotFoundException: Cannot find endpoint: <spark://CoarseGrainedScheduler>@{ip}:{port}
 +
+
*Thread Reply:* This feature is going to be so useful for us! Love it!
+*Thread Reply:* The debug logs from AsyncEventQueue show OpenLineageSparkListener took 21.301411402s fwiw - I'm assuming thats abnormally long
+
- @channel
-We released OpenLineage 1.9.1, featuring:
-• Airflow: add support for JobTypeJobFacet properties #2412 @mattiabertorello
-• dbt: add support for JobTypeJobFacet properties #2411 @mattiabertorello
-• Flink: support Flink Kafka dynamic source and sink #2417 @HuangZhenQiu
-• Flink: support multi-topic Kafka Sink #2372 @pawel-big-lebowski
-• Flink: support lineage for JDBC connector #2436 @HuangZhenQiu
-• Flink: add common config gradle plugin #2461 @HuangZhenQiu
-• Java: extend circuit breaker loaded with ServiceLoader #2435 @pawel-big-lebowski
-• Spark: integration now emits intermediate, application level events wrapping entire job execution #2371 @mobuchowski
-• Spark: support built-in lineage within DataSourceV2Relation #2394 @pawel-big-lebowski
-• Spark: add support for JobTypeJobFacet properties #2410 @mattiabertorello
-• Spark: stop sending spark.LogicalPlan facet by default #2433 @pawel-big-lebowski
-• Spark/Flink/Java: circuit breaker #2407 @pawel-big-lebowski
-• Spark: add the capability to publish Scala 2.12 and 2.13 variants of openlineage-spark #2446 @d-m-h
-A large number of changes and bug fixes were also included.
-Thanks to all our contributors with a special shout-out to @Damien Hawes, who contributed >10 PRs to this release!
-Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.9.1
-Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
-Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.8.0...1.9.1
-Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
-PyPI: https://pypi.org/project/openlineage-python/
*Thread Reply:* The yarn logs also seem to indicate the listener is somehow causing the app to start up again
+2024-02-24 07:18:00,152 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl (SchedulerEventDispatcher:Event Processor): container_1708758297553_0001_01_000002 Container Transitioned from RUNNING to COMPLETED
+2024-02-24 07:18:00,155 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.allocator.AbstractContainerAllocator (SchedulerEventDispatcher:Event Processor): assignedContainer application attempt=appattempt_1708758297553_0001_000001 container=null queue=default clusterResource=<memory:54272, vCores:8> type=OFF_SWITCH requestedPartition=
+2024-02-24 07:18:00,155 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.AppSchedulingInfo (SchedulerEventDispatcher:Event Processor): Allocate Updates PendingContainers: 2 Decremented by: 1 SchedulerRequestKey{priority=0, allocationRequestId=0, containerToUpdate=null} for: appattempt_1708758297553_0001_000001
+2024-02-24 07:18:00,155 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl (SchedulerEventDispatcher:Event Processor): container_1708758297553_0001_01_000003 Container Transitioned from NEW to ALLOCATED
+Is there some logic in the listener that can create a Spark session if there is no active session?
+
+
+ *Thread Reply:* not sure of this, I couldn't find any place of that in code
+ + + +
+
+
+ *Thread Reply:* Probably another instance when doing something generic does not work with Hudi well 😶
+
+
+ *Thread Reply:* Dumb question, what info needs to be fetched from Hudi? Is this in the createRelation call? I'm surprised the logs seem to indicate Hudi table metadata seems to be being read from S3 in the listener
What would need to be implemented for proper Hudi support?
+ + + +
+
+
+ *Thread Reply:* @Max Zheng well, basically we need at least proper name and namespace for the dataset. How we do that is completely dependent on the underlying code, so probably somewhere here: https://github.com/apache/hudi/blob/3a97b01c0263c4790ffa958b865c682f40b4ada4/hudi-[…]-common/src/main/scala/org/apache/hudi/HoodieBaseRelation.scala
Most likely we don't need to do any external calls or read anything from S3. It's just done because without something that understands Hudi classes we just do the generic thing (createRelation) that has the biggest chance to work.
For example, for Iceberg we can get the data required just by getting config from their catalog config - and I think with Hudi it has to work the same way, because logically - if you're reading some table, you have to know where it is or how it's named.
+
+ <a href="https://github.com/apache/hudi">apache/hudi</a>
+
+
+
+ *Thread Reply:* That makes sense, and that info is in the hoodie.properties file that seems to be loaded based on the logs. But the events I see OL generate seem to have S3 path and S3 bucket as a the name and namespace respectively - ie. it doesn't seem to be using any of the metadata being read from Hudi?
+"outputs": [
+ {
+ "namespace": "s3://{bucket}",
+ "name": "{S3 prefix path}",
+(we'd be perfectly happy with just the S3 path/bucket - is there a way to disable createRelation or have OL treat these Hudi as raw parquet?)
+
+
+ *Thread Reply:* > But the events I see OL generate seem to have S3 path and S3 bucket as a the name and namespace respectively - ie. it doesn't seem to be using any of the metadata being read from Hudi?
+Probably yes - as I've said, the OL handling of it is just inefficient and not specific to Hudi. It's good enought that they generate something that seems to be valid dataset naming 🙂
+And, the fact it reads S3 metadata is not intended - it's just that Hudi implements createRelation this way.
++ + + +(we'd be perfectly happy with just the S3 path/bucket - is there a way to disable
+createRelationor have OL treat these Hudi as raw parquet?) + The way OpenLineage Spark integration works is by looking at Optimized Logical Plan of particular Spark job. So the solution would be to implement Hudi specific path inSaveIntoDataSourceCommandVisitoror any particular other visitor that touches on the Hudi path - or, if Hudi has their own LogicalPlan nodes, implement support for it.
+
+
+ *Thread Reply:* (sorry for answering that late @Max Zheng, I thought I had the response send and it was sitting in my draft for few days 😞 )
+ + + +
+
+
+ *Thread Reply:* Thanks for the explanation @Maciej Obuchowski
+ +I've been digging into the source code to see if I can help contribute Hudi support for OL. At least in SaveIntoDataSourceCommandVisitor it seems all I need to do is:
+```--- a/integration/spark/shared/src/main/java/io/openlineage/spark/agent/lifecycle/plan/SaveIntoDataSourceCommandVisitor.java
++++ b/integration/spark/shared/src/main/java/io/openlineage/spark/agent/lifecycle/plan/SaveIntoDataSourceCommandVisitor.java
+@@ -114,8 +114,9 @@ public class SaveIntoDataSourceCommandVisitor
+ LifecycleStateChange lifecycleStateChange =
+ (SaveMode.Overwrite == command.mode()) ? OVERWRITE : CREATE;
+This seems to work and avoids thecreateRelation` call but I still run into the same crash 🤔 so now I'm not sure if this is a Hudi issue. Do you know of any other dependencies on the output data source? I wonder if https://openlineage.slack.com/archives/C01CK9T7HKR/p1708671958295659 rdd events could be the culprit?I'm going to try and reproduce the crash without Hudi and just with parquet
+
*Thread Reply:* Oudstanding work @Damien Hawes 👏
+*Thread Reply:* Hmm reading over RDDExecutionContext it seems highly unlikely anything in that would cause this crash
-
+
+
+ *Thread Reply:* There might be other part related to reading from Hudi?
+ + + +
+
+
+ *Thread Reply:* SaveIntoDataSourceCommandVisitor only takes care about root node of whole LogicalPlan
+
+
+ *Thread Reply:* I would serialize logical plan and take a look at leaf nodes of the job that causes hang
+ + + +
+
+
+ *Thread Reply:* for simple check you can just make the dataset handler that handles them return early
+ + + +
+
+
+ *Thread Reply:* https://openlineage.slack.com/archives/C01CK9T7HKR/p1708544898883449?thread_ts=1708541527.152859&cid=C01CK9T7HKR the parsed logical plan for my test job is just the SaveIntoDataSourceCommandVisitor(though I might be mis-understanding what you mean by leaf nodes)
 +
+
*Thread Reply:* Thank you 👏👏
+*Thread Reply:* I was able to reproduce the issue with InsertIntoHadoopFsRelationCommand with aparquet write with the same job - I'm starting to suspect this is a Spark with Docker/yarn bug
 +
-
+
- Hi all, I'm working on a local Airflow-OpenLineage-Marquez integration using Airflow 2.7.3 and python 3.10. Everything seems to be installed correctly with the appropriate settings. I'm seeing events, jobs, tasks trickle into the UI. I'm using the PostgresOperator. When it's time for the SQL code to be parsed, I'm seeing the following in my Airflow logs:
-[2024-02-26, 19:43:17 UTC] {sql.py:457} INFO - Running statement: SELECT CURRENT_SCHEMA;, parameters: None
-[2024-02-26, 19:43:17 UTC] {base.py:152} WARNING - OpenLineage provider method failed to extract data from provider.
-[2024-02-26, 19:43:17 UTC] {manager.py:198} WARNING - Extractor returns non-valid metadata: None
-Can anyone give me pointers on why exactly this might be happening? I've tried also with the SQLExecuteQueryOperator, same result. I previously got a Marquez setup to work with the external OpenLineage package for Airflow with Airflow 2.6.1. But I'm struggling with this newer integrated OpenLineage version
*Thread Reply:* Without hudi read?
@@ -179286,21 +181240,19 @@
+
*Thread Reply:* Does this happen for some particular SQL but works for other?
-Also, my understanding is that it worked with openlineage-airflow on Airflow 2.6.1 (the same code)?
-What version of OL provider are you using?
*Thread Reply:* Yep, it reads json and writes out as parquet
@@ -179314,23 +181266,19 @@
+
*Thread Reply:* I've been using one toy DAG and have only tried with the two operators mentioned. Currently, my team's code doesn't use provider operators so it would not really work well with OL.
- -Yes, it worked with Airflow 2.6.1. Same code.
- -Right now, I'm using apache-airflow-providers-openlineage==1.5.0 and the other OL dependencies are at 1.9.1.
+*Thread Reply:* We're with EMR so I created an AWS support ticket to ask whether this is a known issue with YARN/Spark on Docker
@@ -179344,19 +181292,19 @@
+
*Thread Reply:* Would you want to share the SQL statement?
+*Thread Reply:* Very interesting, would be great to see if we see more data in the metrics in the next release
@@ -179370,30 +181318,19 @@
+
*Thread Reply:* It has some PII in it, but it's basically in the form of: -```DROP TABLE IF EXISTS usersmeral.keyrelations;
- -CREATE TABLE usersmeral.keyrelations AS
- -WITH -staff AS ( SELECT ...) -,enabled AS (SELECT ...) -SELECT ... -FROM public.borrowers -LEFT JOIN ...;``` -We're splitting the query with sqlparse.split() and feed it to a PostgresOperator.
+*Thread Reply:* For sure, if its on master or if you have a patch I can build the jar and run my job with it if that'd be helpful
@@ -179407,31 +181344,246 @@
+
*Thread Reply:* I thought I should share our configs in case I'm missing something: -```[openlineage] -disabled = False -disabledforoperators =
+*Thread Reply:* Not yet 😶
+ + + +
+
+
+ *Thread Reply:* After even more investigation I think I found the cause. In https://github.com/OpenLineage/OpenLineage/blob/987e5b806dc8bd6c5aab5f85c97af76a87[…]n/java/io/openlineage/spark/agent/OpenLineageSparkListener.java a SparkListenerSQLExecutionEnd event is processed after the SparkSession is stopped - I believe createSparkSQLExecutionContext is doing something weird in https://github.com/OpenLineage/OpenLineage/blob/987e5b806dc8bd6c5aab5f85c97af76a87[…]n/java/io/openlineage/spark/agent/lifecycle/ContextFactory.java at
+SparkSession sparkSession = queryExecution.sparkSession();
+I'm not sure if this is defined behavior for the session to be accessed after its stopped? After I skipped the event in onOtherEvent if the session is stopped it no longer crashes trying to spin up new executors
(I can make a Github issue + try to land a patch if you agree this seems like a bug)
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* (it might affect all events and this is just the first hit)
+ + + +
+
+
+ *Thread Reply:* @Max Zheng is the job particularly short lived? We've seen some times when for very short jobs we had the SparkSession stopped (especially if people close it manually) but it never led to any problems like this deadlock.
+ + + +
+
+
+ *Thread Reply:* I don't think job duration is related (also its not a deadlock, its causing the app to crash https://openlineage.slack.com/archives/C01CK9T7HKR/p1709143871823659?thread_ts=1708969888.804979&cid=C01CK9T7HKR) - it failed for ~ 1 hour long job and when testing still failed when I sampled the job input with df.limit(10000). It seems like it happens on jobs where events take a long time to process (like > 20s in the other thread).
I added this block to verify its being processed after the Spark context is stopped and to skip
-config_path = /opt/airflow/openlineage.yml -transport =
+```+ private boolean isSparkContextStopped() {
+This logs and no longer causes the same app to crash
+24/03/12 04:57:14 WARN OpenLineageSparkListener: SparkSession is stopped, skipping event: class org.apache.spark.sql.execution.ui.SparkListenerDriverAccumUpdates```
+
*Thread Reply:* The YAML file:
-transport:
- type: http
- url: <http://marquez:5000>
*Thread Reply:* might the crash be related to memory issue?
+ + + +
+
+
+ *Thread Reply:* ah, I see
+ + + +
+
+
+ *Thread Reply:* another question, are you explicitely stopping the sparksession/sparkcontext from within your job?
+ + + +
+
+
+ *Thread Reply:* Yep, it only happens where we explicitly stop with spark.stop()
+
+
+ *Thread Reply:* Created: https://github.com/OpenLineage/OpenLineage/issues/2513
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ Lastly, would disabling facets improve performance? eg. disabling spark.logicalPlan
+
+
+ *Thread Reply:* Disabling spark.LogicalPlan may improve performance of populating OL event. It's disabled by default in recent version (the one released yesterday). You can also use circuit breaker feature if you are worried about Ol integration affecting Spark jobs
+
+
+ *Thread Reply:* This feature is going to be so useful for us! Love it!
+ + + +
+
+
+ @channel
+We released OpenLineage 1.9.1, featuring:
+• Airflow: add support for JobTypeJobFacet properties #2412 @mattiabertorello
+• dbt: add support for JobTypeJobFacet properties #2411 @mattiabertorello
+• Flink: support Flink Kafka dynamic source and sink #2417 @HuangZhenQiu
+• Flink: support multi-topic Kafka Sink #2372 @pawel-big-lebowski
+• Flink: support lineage for JDBC connector #2436 @HuangZhenQiu
+• Flink: add common config gradle plugin #2461 @HuangZhenQiu
+• Java: extend circuit breaker loaded with ServiceLoader #2435 @pawel-big-lebowski
+• Spark: integration now emits intermediate, application level events wrapping entire job execution #2371 @mobuchowski
+• Spark: support built-in lineage within DataSourceV2Relation #2394 @pawel-big-lebowski
+• Spark: add support for JobTypeJobFacet properties #2410 @mattiabertorello
+• Spark: stop sending spark.LogicalPlan facet by default #2433 @pawel-big-lebowski
+• Spark/Flink/Java: circuit breaker #2407 @pawel-big-lebowski
+• Spark: add the capability to publish Scala 2.12 and 2.13 variants of openlineage-spark #2446 @d-m-h
+A large number of changes and bug fixes were also included.
+Thanks to all our contributors with a special shout-out to @Damien Hawes, who contributed >10 PRs to this release!
+Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.9.1
+Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
+Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.8.0...1.9.1
+Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
+PyPI: https://pypi.org/project/openlineage-python/
+
+
+ *Thread Reply:* Oudstanding work @Damien Hawes 👏
+ + + +
+
+
+ *Thread Reply:* Thank you 👏👏
+ + + + +
+
+
+
+
+ *Thread Reply:* any idea how OL releases tie into the airflow provider?
+ +I assume that a separate apache-airflow-providers-airflow release would be made in the future to incorporate the new features/fixes?
+ + + +
+
+
+ *Thread Reply:* yes, Airflow providers are released on behalf of Airflow community and different than Airflow core release
+ + + +
+
+
+ *Thread Reply:* It seems like OpenLineage Spark is still on 1.8.0? Any idea when this will be updated? Thanks!
+ + + +
+
+
+ *Thread Reply:* @Max Zheng https://openlineage.io/docs/integrations/spark/#how-to-use-the-integration
+
+
+
+ *Thread Reply:* Oh got it, didn't see the note
+The above necessitates a change in the artifact identifier for io.openlineage:openlineage-spark. After version 1.8.0, the artifact identifier has been updated. For subsequent versions, utilize: io.openlineage:openlineage_spark_${SCALA_BINARY_VERSION}:${OPENLINEAGE_SPARK_VERSION}.
+
+
+
+
+
+
+ *Thread Reply:* You're welcome.
+ + + +
+
+
+ Hi all, I'm working on a local Airflow-OpenLineage-Marquez integration using Airflow 2.7.3 and python 3.10. Everything seems to be installed correctly with the appropriate settings. I'm seeing events, jobs, tasks trickle into the UI. I'm using the PostgresOperator. When it's time for the SQL code to be parsed, I'm seeing the following in my Airflow logs:
+[2024-02-26, 19:43:17 UTC] {sql.py:457} INFO - Running statement: SELECT CURRENT_SCHEMA;, parameters: None
+[2024-02-26, 19:43:17 UTC] {base.py:152} WARNING - OpenLineage provider method failed to extract data from provider.
+[2024-02-26, 19:43:17 UTC] {manager.py:198} WARNING - Extractor returns non-valid metadata: None
+Can anyone give me pointers on why exactly this might be happening? I've tried also with the SQLExecuteQueryOperator, same result. I previously got a Marquez setup to work with the external OpenLineage package for Airflow with Airflow 2.6.1. But I'm struggling with this newer integrated OpenLineage version
+
+
+ *Thread Reply:* Does this happen for some particular SQL but works for other?
+Also, my understanding is that it worked with openlineage-airflow on Airflow 2.6.1 (the same code)?
+What version of OL provider are you using?
+
+
+ *Thread Reply:* I've been using one toy DAG and have only tried with the two operators mentioned. Currently, my team's code doesn't use provider operators so it would not really work well with OL.
+ +Yes, it worked with Airflow 2.6.1. Same code.
+ +Right now, I'm using apache-airflow-providers-openlineage==1.5.0 and the other OL dependencies are at 1.9.1.
+ + + +
+
+
+ *Thread Reply:* Would you want to share the SQL statement?
+ + + +
+
+
+ *Thread Reply:* It has some PII in it, but it's basically in the form of: +```DROP TABLE IF EXISTS usersmeral.keyrelations;
+ +CREATE TABLE usersmeral.keyrelations AS
+ +WITH +staff AS ( SELECT ...) +,enabled AS (SELECT ...) +SELECT ... +FROM public.borrowers +LEFT JOIN ...;``` +We're splitting the query with sqlparse.split() and feed it to a PostgresOperator.
+ + + +
+
+
+ *Thread Reply:* I thought I should share our configs in case I'm missing something: +```[openlineage] +disabled = False +disabledforoperators =
+ +config_path = /opt/airflow/openlineage.yml +transport =
+ +
+
+
+ *Thread Reply:* The YAML file:
+transport:
+ type: http
+ url: <http://marquez:5000>
+
+
+ *Thread Reply:* Are you running on apple silicon?
+ + + +
+
+
+ *Thread Reply:* Yep, is that the issue?
+ + + +
+
+
+ @channel +Since lineage will be the focus of a panel at Data Council Austin next month, it seems like a great opportunity to organize a meetup. Please get in touch if you might be interested in attending, presenting or hosting!
+ +
+
+
+
+
+
+
+  +
+
+
+
+
+ Hi all, I'm running into an unusual issue with OpenLineage on Databricks. When using OL 1.4.1 on a cluster that runs over 100 jobs every 30 minutes. After a couple hours, a DRIVER_NOT_RESPONDING error starts showing up in the event log with the message Driver is up but is not responsive, likely due to GC.. After a DRIVER_HEALTHY the error occurs again several minutes later. Is this a known issue that has been solved in a later release, or is there something I can do in Databricks to stop this?
+
+
+ *Thread Reply:* My guess would be that with that amount of jobs scheduled shortly the SparkListener queue grows and some internal healthcheck times out?
Maybe you could try disabling spark.logicalPlan and spark_unknown facets to see if this speeds things up.
+
+
+ *Thread Reply:* BTW, are you receiving OL events in the meantime?
+ + + +
+
+
+ *Thread Reply:* Hi @Declan Grant, can you tell us if disabling the facets worked?
+ + + +
+
+
+ *Thread Reply:* We had already tried disabling the facets, and that did not solve the issue.
+ +Here is the relevant spark config:
+spark.openlineage.transport.type console
+spark.openlineage.facets.disabled [spark_unknown;spark.logicalPlan;schema;columnLineage;dataSource]
+We are not interested in column lineage at this time.
+
+
+ *Thread Reply:* OL has been uninstalled from the cluster, so I can't immediately say whether events are received while the driver is not responding.
+ + + +
+
+
+ @channel +This month's issue of OpenLineage News is in inboxes now! Sign up to ensure you always get the latest issue. In this edition: a rundown of open issues, new docs and new videos, plus updates on the Airflow Provider, Spark integration and Flink integration (+ more).
+ +
+
+
+
+
+ Hi all, I've been trying to gather clues on how OpenLineage fetches our inputs' namespace and name from our Spark codebase. Routing to the exact logic would be very helpful for one of my usecase.
+ + + +
+
+
+ *Thread Reply:* There is no single place where the namespace is assigned to dataset as this is strictly dependending on what datasets are read. Spark, as other OpenLineage integrations, follows the naming convention -> https://openlineage.io/docs/spec/naming
+ +
+
+
+
+
+ Hi all, I'm working on propagating the parent facet from an Airflow DAG to the dbt workflows it launches, and I'm a bit puzzled by the current logic in lineageparentid. It generates an ID in the form namespace/name/run_id (which is the format that dbt-ol expects as well), but here name is actually a UUID generated from the job's metadata, and run_id is the internal Airflow task instance name (usually a concatenation of execution date + try number) instead of a UUID, like OpenLineage advises.
Instead of using this function I've made my own where name=<dag_id>.<task_id> (as this is the job name propagated in other OpenLineage events as well), and run_id = lineage_run_id(operator, task_instance) - basically using the UUID hashing logic for the run_id that is currently used for the name instead. This seems to be more OpenLineage-compliant and it allows us to link things properly.
Is there some reason that I'm missing behind the current logic? Things are even more confusing IMHO because there's also a newlineagerun_id utility that calculates the run_id simply as a random UUID, without the UUID serialization logic of lineage_run_id, so it's not clear which one I'm supposed to use.
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* FYI the function I've come up with to link things properly looks like this:
+ +```from airflow.models import BaseOperator, TaskInstance +from openlineage.airflow.macros import JOBNAMESPACE +from openlineage.airflow.plugin import lineagerunid
+ +def lineageparentid(self: BaseOperator, taskinstance: TaskInstance) -> str: + return "/".join( + [ + _JOBNAMESPACE, + f"{taskinstance.dagid}.{taskinstance.taskid}", + lineagerunid(self, task_instance), + ] + )```
+ + + +
+
+
+ *Thread Reply:* @Paweł Leszczyński @Jakub Dardziński - any thoughts here?
+ + + +
+
+
+ *Thread Reply:* newlineagerun_id is some very old util method that should be deleted imho
+ +I agree what you propose is more OL-compliant. Indeed, what we have in Airflow provider for dbt cloud integration is pretty the same you have: +https://github.com/apache/airflow/blob/main/airflow/providers/dbt/cloud/utils/openlineage.py#L132
+ +the reason for that is I think that the logic was a subject of change over time and dbt-ol script just was not updated properly
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+ <a href="https://github.com/apache/airflow">apache/airflow</a>
+
+
+
+ *Thread Reply:* @Fabio Manganiello would you mind opening an issue about this on GitHub?
+ + + +
+
+
+ *Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/2488 +there is one already 🙂 @Fabio Manganiello thank you for that!
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* Oops, should have checked first! Yes, thanks Fabio
+ + + +
+
+
+ *Thread Reply:* There is also a PR already, sent as separate message by @Fabio Manganiello. And the same fix for the provider here. Some discussion is needed about what changes can we made to the macros and whether they will be "breaking", so feel free to comment.
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+ <a href="https://github.com/apache/airflow">apache/airflow</a>
+  +
+
+
+
+
+ Hey team, +we're trying to extract certain Spark metrics with OL using custom Facets.
+ +But we're not getting SparkListenerTaskStart , SparkListenerTaskEnd event as part of custom facet.
+ +We're only able to get SparkListenerJobStart, SparkListenerJobEnd, SparkListenerSQLExecutionStart, SparkListenerSQLExecutionEnd.
+ +This is how our custom facet code looks like : +``` @Override + protected void build(SparkListenerEvent event, BiConsumer<String, ? super TestRunFacet> consumer) { + if (event instanceof SparkListenerSQLExecutionStart) { ...} +if (event instanceof SparkListenerTaskStart) { ...}
+ +}
+But when we're executing the same Spark SQL using custom listener without OL facets, we're able to get Task level metrics too:
+public class IntuitSparkMetricsListener extends SparkListener {
+ @Override
+ public void onJobStart(SparkListenerJobStart jobStart){
+ log.info("job start logging starts");
+ log.info(jobStart.toString());
}
+
+
+@Override
+public void onTaskEnd(SparkListenerTaskEnd taskEnd) {
+} +.... +}``` +Could anyone give us certain input on how to get Task level metrics in OL facet itself ? +Also, any issue due to SparkListenerEvent vs SparkListener ?
+ +cc @Athitya Kumar @Kiran Hiremath
+ + + +
+
+
+ *Thread Reply:* OpenLineageSparkListener is not listening on SparkListenerTaskStart at all. It listens to SparkListenerTaskEnd , but only to fill metrics for OutputStatisticsOutputDatasetFacet
+
+
+ *Thread Reply:* I think to do this would be a not that small change, you'd need to add handling for those methods for ExecutionContexts https://github.com/OpenLineage/OpenLineage/blob/31f8ce588526e9c7c4bc7d849699cb7ce2[…]java/io/openlineage/spark/agent/lifecycle/ExecutionContext.java and OpenLineageSparkListener itself to pass it forward.
When it comes to implementation of them in particular contexts, I would make sure they don't emit unless you have something concrete set up for them, like those metrics you've set up.
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ Hi folks, I have created a PR to address the required changes in the Airflow lineage_parent_id macro, as discussed in my previous comment (cc @Jakub Dardziński @Damien Hawes @Mattia Bertorello)
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* Hey Fabio, thanks for the PR. Please let us know if you need any help with fixing tests.
+ + + +
+
+
+ @channel +This month’s TSC meeting is next week on a new day/time: Wednesday the 13th at 9:30am PT. Please note that this will be the new day/time going forward! +On the tentative agenda: +• announcements + ◦ new integrations: DataHub and OpenMetadata + ◦ upcoming events +• recent release 1.9.1 highlights +• Scala 2.13 support in Spark overview by @Damien Hawes +• Circuit breaker in Spark & Flink @Paweł Leszczyński +• discussion items +• open discussion +More info and the meeting link can be found on the website. All are welcome! Do you have a discussion topic, use case or integration you’d like to demo? Reply here or DM me to be added to the agenda.
+
+
+
+ Hi, would it be reasonable to add a flag to skip RUNNING events for the Spark integration? https://openlineage.io/docs/integrations/spark/job-hierarchy For some jobs we're seeing AsyncEventQueue report ~20s to process each event and a lot of RUNNING events being generated
IMO this might work as an alternative to https://github.com/OpenLineage/OpenLineage/issues/2375 ? It seems like it'd be more valuable to get the START/COMPLETE events vs intermediate RUNNING events
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* Well, I think the real problem is 20s event generator. What we should do is to include timer spent on each visitor or dataset builder within debug facet. Once this is done, we could reach out to you again to let you guide us which code part leads to such scenario.
+ + + +
+
+
+ *Thread Reply:* @Maciej Obuchowski do we have an issue for this? I think we discussed it recently.
+ + + +
+
+
+ *Thread Reply:* > What we should do is to include timer spent on each visitor or dataset builder within debug facet. +I could help provide this data if that'd be helpful, how/what instrumentation should I add? If you've got a patch handy I could apply it locally, build, and collect this data from my test job
+ + + +
+
+
+ *Thread Reply:* Its also taking > 20s per event with parquet writes instead of hudi writes in my job so I don't think thats the culprit
+
+
+ *Thread Reply:* I'm working on instrumentation/metrics right now, will be ready for next release 🙂
+ + + +
+
+
+ *Thread Reply:* I did some manual timing and 90% of the latency is from buildInputDatasets https://github.com/OpenLineage/OpenLineage/blob/987e5b806dc8bd6c5aab5f85c97af76a87[…]enlineage/spark/agent/lifecycle/OpenLineageRunEventBuilder.java
Manual as in I modified:
+long startTime = System.nanoTime();
+ List<InputDataset> datasets =
+ Stream.concat(
+ buildDatasets(nodes, inputDatasetBuilders),
+ openLineageContext
+ .getQueryExecution()
+ .map(
+ qe ->
+ ScalaConversionUtils.fromSeq(qe.optimizedPlan().map(inputVisitor))
+ .stream()
+ .flatMap(Collection::stream)
+ .map(((Class<InputDataset>) InputDataset.class)::cast))
+ .orElse(Stream.empty()))
+ .collect(Collectors.toList());
+ long endTime = System.nanoTime();
+ double durationInSec = (endTime - startTime) / 1_000_000_000.0;
+ <a href="http://log.info">log.info</a>("buildInputDatasets 1: {}s", durationInSec);
+24/03/11 23:44:58 INFO OpenLineageRunEventBuilder: buildInputDatasets 1: 95.710143007s
+Is there anything I can instrument/log to narrow down further why this is so slow? buildOutputDatasets is also kind of slow at ~10s
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* @Max Zheng it's not extremely easy because sometimes QueryPlanVisitors/DatasetBuilders delegate work to other ones, but I think I'll have a relatively good solution soon: https://github.com/OpenLineage/OpenLineage/pull/2496
+ + + +
+
+
+ *Thread Reply:* Got it, should I open a Github issue to track this?
+ +For context the code is
+def load_df_with_schema(spark: SparkSession, s3_base: str):
+ schema = load_schema(spark, s3_base)
+ file_paths = get_file_paths(spark, "/".join([s3_base, "manifest.json"]))
+ return spark.read.format("json").load(
+ file_paths,
+ schema=schema,
+ mode="FAILFAST",
+ )
+And the input schema has ~250 columns
+
+
+ *Thread Reply:* the instrumentation issues are already there, but please do open issue for the slowness 👍
+ + + +
+
+
+ *Thread Reply:* and yes, it can be some degenerated example where we do something way more often than once
+ + + +
+
+
+ *Thread Reply:* Got it, I'll try to create a working reproduction and ticket it 🙂
+ + + +
+
+
+ *Thread Reply:* Created https://github.com/OpenLineage/OpenLineage/issues/2511
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+  +
+
+
+
+
+ Hi team... I am trying to emit openlineage events from a spark job. When I submit the job using spark-submit, this is what I see in console.
+ +ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
+io.openlineage.client.OpenLineageClientException: io.openlineage.spark.shaded.com.fasterxml.jackson.databind.JsonMappingException: Failed to find TransportBuilder (through reference chain: io.openlineage.client.OpenLineageYaml["transport"])
+ at io.openlineage.client.OpenLineageClientUtils.loadOpenLineageYaml(OpenLineageClientUtils.java:149)
+ at io.openlineage.spark.agent.ArgumentParser.extractOpenlineageConfFromSparkConf(ArgumentParser.java:114)
+ at io.openlineage.spark.agent.ArgumentParser.parse(ArgumentParser.java:78)
+ at io.openlineage.spark.agent.OpenLineageSparkListener.initializeContextFactoryIfNotInitialized(OpenLineageSparkListener.java:277)
+ at io.openlineage.spark.agent.OpenLineageSparkListener.onJobStart(OpenLineageSparkListener.java:110)
+ at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:37)
+ at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
+ at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
+ at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
+ at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117)
+ at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101)
+ at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
+ at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
+ at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
+ at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
+ at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
+ at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
+ at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1356)
+ at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
+Caused by: io.openlineage.spark.shaded.com.fasterxml.jackson.databind.JsonMappingException: Failed to find TransportBuilder (through reference chain: io.openlineage.client.OpenLineageYaml["transport"])
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.JsonMappingException.wrapWithPath(JsonMappingException.java:402)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.JsonMappingException.wrapWithPath(JsonMappingException.java:361)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.deser.BeanDeserializerBase.wrapAndThrow(BeanDeserializerBase.java:1853)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.deser.BeanDeserializer.vanillaDeserialize(BeanDeserializer.java:316)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.deser.BeanDeserializer.deserialize(BeanDeserializer.java:177)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.deser.DefaultDeserializationContext.readRootValue(DefaultDeserializationContext.java:323)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:4825)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3809)
+ at io.openlineage.client.OpenLineageClientUtils.loadOpenLineageYaml(OpenLineageClientUtils.java:147)
+ ... 18 more
+Caused by: java.lang.IllegalArgumentException: Failed to find TransportBuilder
+ at io.openlineage.client.transports.TransportResolver.lambda$getTransportBuilder$3(TransportResolver.java:38)
+ at java.base/java.util.Optional.orElseThrow(Optional.java:403)
+ at io.openlineage.client.transports.TransportResolver.getTransportBuilder(TransportResolver.java:37)
+ at io.openlineage.client.transports.TransportResolver.resolveTransportConfigByType(TransportResolver.java:16)
+ at io.openlineage.client.transports.TransportConfigTypeIdResolver.typeFromId(TransportConfigTypeIdResolver.java:35)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.jsontype.impl.TypeDeserializerBase._findDeserializer(TypeDeserializerBase.java:159)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.jsontype.impl.AsPropertyTypeDeserializer._deserializeTypedForId(AsPropertyTypeDeserializer.java:151)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.jsontype.impl.AsPropertyTypeDeserializer.deserializeTypedFromObject(AsPropertyTypeDeserializer.java:136)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.deser.AbstractDeserializer.deserializeWithType(AbstractDeserializer.java:263)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.deser.impl.FieldProperty.deserializeAndSet(FieldProperty.java:147)
+ at io.openlineage.spark.shaded.com.fasterxml.jackson.databind.deser.BeanDeserializer.vanillaDeserialize(BeanDeserializer.java:314)
+ ... 23 more
+Can I get any help on this?
+
+
+ *Thread Reply:* Looks like misconfigured transport. Please refer to this -> https://openlineage.io/docs/integrations/spark/configuration/transport and https://openlineage.io/docs/integrations/spark/configuration/spark_conf for more details. I think you're missing spark.openlineage.transport.type property.
+
+
+ *Thread Reply:* This is my configuration of the transport:
+conf.set("sparkscalaversion", "2.12")
+ conf.set("spark.extraListeners","io.openlineage.spark.agent.OpenLineageSparkListener")
+ conf.set("spark.openlineage.transport.type","http")
+ conf.set("spark.openlineage.transport.url","<http://localhost:8082>")
+ conf.set("spark.openlineage.transport.endpoint","/event")
+ conf.set("spark.extraListeners","io.openlineage.spark.agent.OpenLineageSparkListener")
+During spark-submit if I include
+--packages "io.openlineage:openlineage_spark:1.8.0"
+I am able to receive events.
I have already included this line in build.sbt
+libraryDependencies += "io.openlineage" % "openlineage-spark" % "1.8.0"
So I don't understand why I have to pass the packages again
+ + + +
+
+
+ *Thread Reply:* OK, the configuration is OK. I think that when using libraryDependencies you get rid of manifest from within our JAR which is used by ServiceLoader
+
+
+ *Thread Reply:* this is happening here -> https://github.com/OpenLineage/OpenLineage/blob/main/client/java/src/main/java/io/openlineage/client/transports/TransportResolver.java#L32
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* And this is the known issue related to this -> https://github.com/OpenLineage/OpenLineage/issues/1860
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* This comment -> https://github.com/OpenLineage/OpenLineage/issues/1860#issuecomment-1750536744 explains this and shows how to fix this. I am happy to help new contributors with this.
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* Thanks for the detailed reply and pointers. Will look into it.
+ + + +
+
+
+ @channel +The big redesign of Marquez Web is out now following a productive testing period and some modifications along with added features. In addition to a wholesale redesign including column lineage support, it includes a new dataset tagging feature. It's worth checking out as a consumption layer in your lineage solution. A blog post with more details is coming soon, but here are some screenshots to whet your appetite. (See the thread for a screencap of the column lineage display.) +Marquez quickstart: https://marquezproject.ai/docs/quickstart/ +The release itself: https://github.com/MarquezProject/marquez/releases/tag/0.45.0
+ +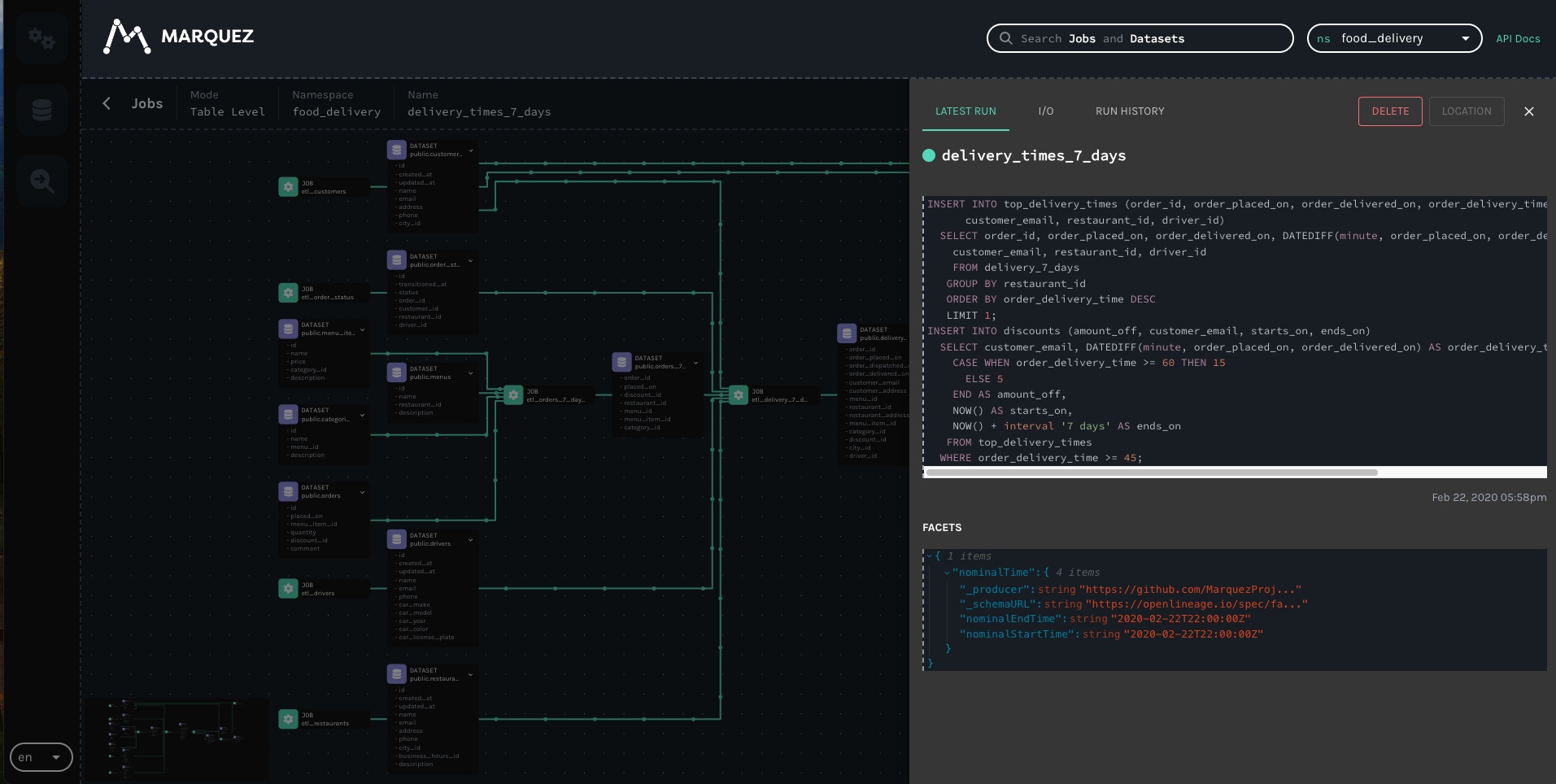 +
+
+
+
+
+
+
+ 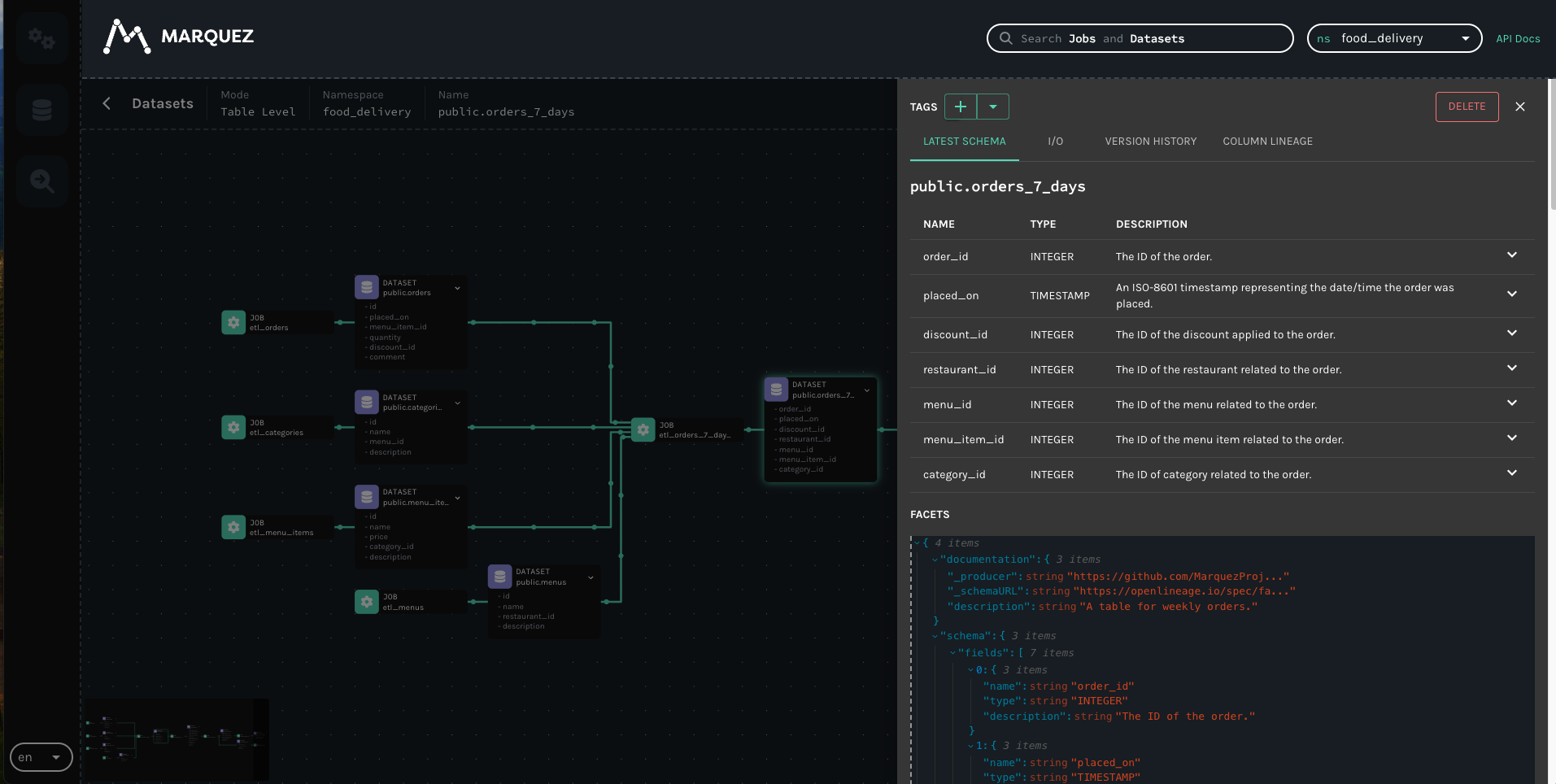 +
+
+
+
+
+
+
+ 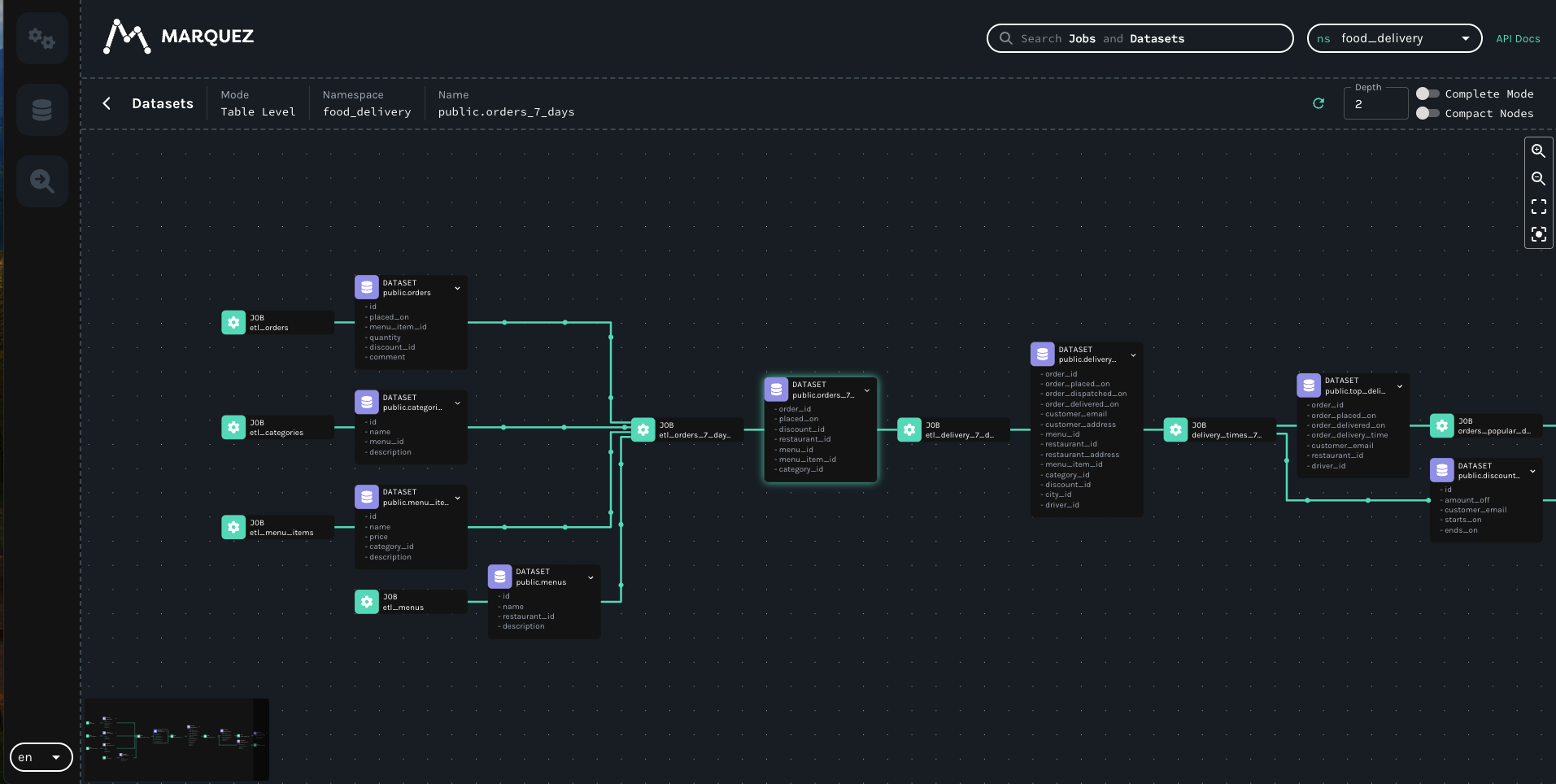 +
+
+
+
+
+
+
+  +
+
+
+
+
+ *Thread Reply:* Are those field descriptions coming from emitted events? or from a defined schema that's being added by marquez?
+ + + + +
+
+
+
+
+ *Thread Reply:* Nice work! Are there any examples of the mode being switched from Table level to Column level or do I miss understand what mode is?
+ + + +
+
+
+ *Thread Reply:* @Cory Visi Those are coming from the events. The screenshots are of the UI seeded with metadata. You can find the JSON used for this here: https://github.com/MarquezProject/marquez/blob/main/docker/metadata.json
+ + + +
+
+
+ *Thread Reply:* The three screencaps in my first message actually don't include the column lineage display feature (but there are lots of other upgrades in the release)
+ + + +
+
+
+ *Thread Reply:* column lineage view:
+ +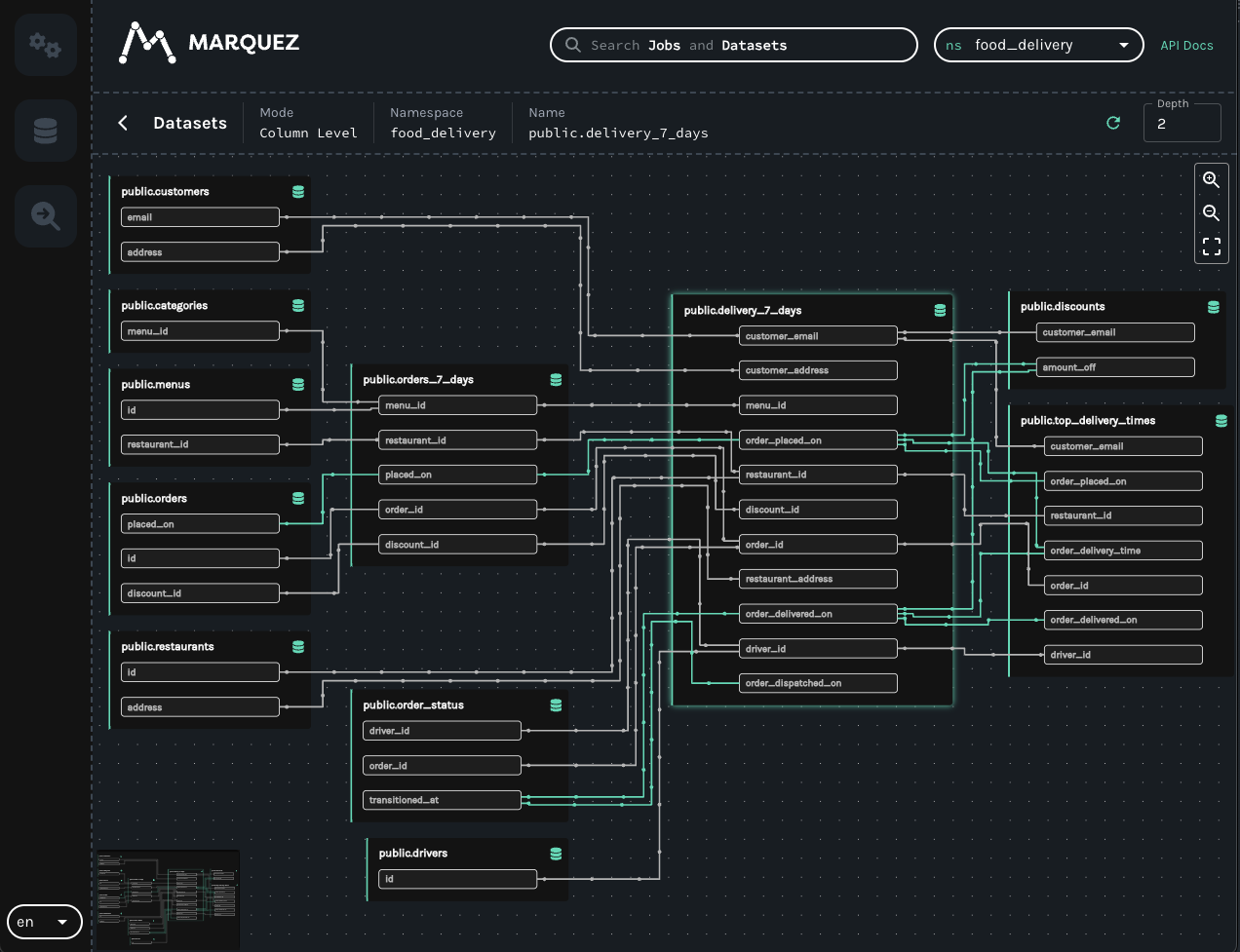 +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* Thanks, that's what I wanted to get a look at. Cheers
+ + + +
+
+
+ *Thread Reply:* @Ted McFadden what the initial 3 screencaps show is switching between the graph view and detailed views of the datasets and jobs
+ + + + +
+
+
+
+
+ *Thread Reply:* Hey with the tagging we’ve identified a slight bug - PR has been put into fix.
+ + + +
+
+
+ *Thread Reply:* The "query" section looks awesome, Congrats!!! But from the openlineage side, when is the query attribute available?
+ + + +
+
+
+ *Thread Reply:* Fantastic work!
+ + + +
+
+
+ *Thread Reply:* @Rodrigo Maia the OpenLineage spec supports this via the SQLJobFacet. See: https://github.com/OpenLineage/OpenLineage/blob/main/spec/facets/SQLJobFacet.json
+ + + + +
+
+
+
+
+ *Thread Reply:* Thanks Michael....do we have a list of which providers are known to be populating the SQL JobFacet (assuming that the solution emitting the events uses SQL and has access to it)?
+ + + +
+
+
+ *Thread Reply:* @Maciej Obuchowski or @Jakub Dardziński can add more detail, but this doc has a list of operators supported by the SQL parser.
+ + + +
+
+
+ *Thread Reply:* yeah, so basically any of the operators that is sql-compatible - SQLExecuteQueryOperator + Athena, BQ I think
+ + + +
+
+
+ *Thread Reply:* Thanks! That helps for Airflow --- do we know if any other Providers are fully supporting this powerful facet?
+ + + +
+
+
+ *Thread Reply:* whoa, powerful 😅
+I just checked sources, the only missing from above is CopyFromExternalStageToSnowflakeOperator
are you interested in some specific ones?
+ + + +
+
+
+ *Thread Reply:* and ofc you can have SQLJobFacet coming from dbt or spark as well or any other systems triggered via Airflow
+ + + +
+
+
+ *Thread Reply:* Thanks Jakub. It will be interesting to know which providers we are certain provide SQL, that are entirely independent of Airflow.
+ + + +
+
+
+ *Thread Reply:* I don’t think we have any facet-oriented docs (e.g. what produces SQLJobFacet) and if that makes sense
+ + + +
+
+
+ *Thread Reply:* Thanks. Ultimately, it's a bigger question that we've talked about before, about best ways to document and validate what things/facets you can support/consume (as a consumer) or which you support/populate as a provider.
+ + + +
+
+
+ *Thread Reply:* The doc that @Michael Robinson shared is automatically generated from Airflow code, so it should provide the best option for build-in operators. If we're talking about providers/operators outside Airflow repo, then I think @Julien Le Dem’s registry proposal would best support that need
+ + + +
+
+
+ Hey team. Is column/attribute level lineage supported for input/topic Kafka topic ports in the OpenLineage Flink listener?
+ + + +
+
+
+ *Thread Reply:* Column level lineage is currently not supported for Flink
+ + + + +
+
+
+
+
+ Is it possible to explain me "OTHER" Run State and whether we can use this to send Lineage events to check the health of a service that is running in background and triggered interval manner. +It will be really helpful, if someone can send example JSON for "OTHER" run state
+ + + + +
+
+
+ *Thread Reply:* The example idea behind other was: imagine a system that requests for compute resorouces and would like to emit OpenLineage event about request being made. That's why other can occur before start. The other idea was to put other elsewhere to provide agility for new scenarios. However, we want to restrict which event types are terminating ones and don't want other there. This is important for lineage consumers, as when they receive terminating event for a given run, they know all the events related to the run were emitted.
+
+
+ *Thread Reply:* @Paweł Leszczyński Is it possible to track the health of a service by using OpenLineage Events? Of so, How? +As an example, I have a windows service, and I want to make sure the service is up and running.
+ + + +
+
+
+ *Thread Reply:* depends on what do you mean by service. If you consider a data processing job as a service, then you can track if it successfully completes.
+ + + +
+
+
+ *Thread Reply:* I think other systems would be more suited for healthchecks, like OpenTelemetry or Datadog
+ + + + +
+
+
+
+
+ hey there, trying to configure databricks spark with the openlineage spark listener 🧵
+ + + +
+
+
+ *Thread Reply:* databricks runtime for clusters:
+14.3 LTS (includes Apache Spark 3.5.0, Scala 2.12)
+we are shipping a global init script that looks like the following:
+```#!/bin/bash
+VERSION="1.9.1"
+SCALAVERSION="2.12"
+wget -O /mnt/driver-daemon/jars/openlineage-spark$${SCALAVERSION}-$${VERSION}.jar https://repo1.maven.org/maven2/io/openlineage/openlineage-spark$${SCALAVERSION}/$${VERSION}/openlineage-spark$${SCALA_VERSION}-$${VERSION}.jar
SPARKDEFAULTSFILE="/databricks/driver/conf/00-openlineage-defaults.conf"
+ +if [[ $DBISDRIVER = "TRUE" ]]; then + cat > $SPARKDEFAULTSFILE <<- EOF + [driver] { + "spark.extraListeners" = "com.databricks.backend.daemon.driver.DBCEventLoggingListener,io.openlineage.spark.agent.OpenLineageSparkListener" + "spark.openlineage.version" = "v1" + "spark.openlineage.transport.type" = "http" + "spark.openlineage.transport.url" = "https://some.url" + "spark.openlineage.dataset.removePath.pattern" = "(\/[a-z]+[-a-zA-Z0-9]+)+(?<remove>.**)" + "spark.openlineage.namespace" = "some_namespace" + } +EOF +fi``` +with openlineage-spark 1.9.1
+ + + +
+
+
+ *Thread Reply:* getting fatal exceptions:
+24/03/07 14:14:05 ERROR DatabricksMain$DBUncaughtExceptionHandler: Uncaught exception in thread spark-listener-group-shared!
+java.lang.NoClassDefFoundError: com/databricks/sdk/scala/dbutils/DbfsUtils
+ at io.openlineage.spark.agent.facets.builder.DatabricksEnvironmentFacetBuilder.getDbfsUtils(DatabricksEnvironmentFacetBuilder.java:124)
+ at io.openlineage.spark.agent.facets.builder.DatabricksEnvironmentFacetBuilder.getDatabricksEnvironmentalAttributes(DatabricksEnvironmentFacetBuilder.java:92)
+ at io.openlineage.spark.agent.facets.builder.DatabricksEnvironmentFacetBuilder.build(DatabricksEnvironmentFacetBuilder.java:58)
+and spark driver crashing when spark runs
+
+
+ *Thread Reply:* browsing the code for 1.9.1 shows that the exception comes from trying to access the class for databricks dbfsutils here
+ +should I file a bug on github, or am I doing something very wrong here?
+ + + +
+
+
+ *Thread Reply:* Looks like something has changed in the Databricks 14 🤔
+ + + +
+
+
+ *Thread Reply:* Issue on GitHub is the right way
+ + + +
+
+
+ *Thread Reply:* thanks, opening one now with this information.
+ + + +
+
+
+ *Thread Reply:* link to issue for anyone interested, thanks again!
+ + + +
+
+
+ *Thread Reply:* Hi @Maciej Obuchowski I am having the same issue with older versions of Databricks.
+ + + +
+
+
+ *Thread Reply:* I don't think that the spark's integration is working anymore for any of the environments in Databricks and not only the version 14.
+ + + +
+
+
+ *Thread Reply:* The issue is coming from this change :
+ + + + + +
+
+
+ *Thread Reply:* @Abdallah are you willing to provide PR?
+ + + +
+
+
+ *Thread Reply:* I am having a look
+ + + +
+
+
+ *Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/2530
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+  +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* is what you sent an event for DAG or task?
+ + + +
+
+
+ *Thread Reply:* so far Marquez cannot show job hierarchy (DAG is parent to tasks) so you need click on some of the tasks in the UI to see proper view
+ + + +
+
+
+ *Thread Reply:* is this the only job listed?
+ + + +
+
+
+ *Thread Reply:* no, I can see 191 total
+ + + +
+
+
+ *Thread Reply:* what if you choose any other job that has ACustomingestionDag. prefix?
+ + + +
+
+
+ *Thread Reply:* you also have namespaces in right upper corner. datasets are probably in different namespace than Airflow jobs
+ + + +
+
+
+ *Thread Reply:* https://airflow.apache.org/docs/apache-airflow-providers-openlineage/stable/supported_classes.html
+ +this is the list of supported operators currently
+ +not all of them send dataset information, e.g. PythonOperator
+ + + + +
+
+
+
+
+ hi everyone!
+ +i configured openlineage + marquez to my Amazon managed Apache Airflow to get better insights of the DAGS. for implementation i followed the https://aws.amazon.com/blogs/big-data/automate-data-lineage-on-amazon-mwaa-with-openlineage/ guide, using helm/k8s option. +marquez is up and running i can see my DAGs and depending DAGs in jobs section, however when clicking on any of the dags in jobs list i see only one job without any dependencies. i would like to see the whole chain of tasks execution. how can i achieve this goal? please advice.
+ +additional information: +we dont have Datasets in our MWAA. +MWAA Airflow - v. 2.7.2 +Openlineage plugin.py - +from airflow.plugins_manager import AirflowPlugin +from airflow.models import Variable +import os
+ +os.environ["OPENLINEAGEURL"] = Variable.get('OPENLINEAGEURL', default_var='')
+ +class EnvVarPlugin(AirflowPlugin): + name = "envvarplugin"
+ +requirements.txt: +httplib2 +urllib3 +oauth2client +bingads +pymssql +certifi +facebook_business +mysql-connector-python +google-api-core +google-auth +google-api-python-client +apiclient +google-auth-httplib2 +google-auth-oauthlib +pymongo +pandas +numpy +pyarrow +apache-airflow-providers-openlineage
+ +Also, where can i find the meaning of Depth, complete mode, compact nodes options? i believe it is an view option?
+ +Thank you in advance for your help!
+ + +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* Jobs may not have any dependencies depending on the Airflow operator used (ex: PythonOperator). Can you provide the OL events for the job you expect to have inputs/outputs? In the Marquez Web UI, you can use the events tab:
 +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* is this what you requested?
+ + + +
+
+
+ *Thread Reply:* hello! @Willy Lulciuc could you please guide me further? what can be done to see the whole chain of DAG execution in openlineage/marquez?
+ + + +
+
+
+ *Thread Reply:* from textwrap import dedent
+import mysql.connector
+import pymongo
+import logging
+import sys
+import ast
+from airflow import DAG
+from airflow.operators.python import PythonOperator
+from airflow.operators.trigger_dagrun import TriggerDagRunOperator
+from airflow.operators.python import BranchPythonOperator
+from airflow.providers.http.operators.http import SimpleHttpOperator
+from airflow.models import Variable
+from bson.objectid import ObjectId
+we do use PythonOperator, however we are specifying task dependencies in the DAG code, example:
error_task = PythonOperator(
+891 task_id='error',
+892 python_callable=error,
+893 dag=dag,
+894 trigger_rule = "one_failed"
+895 )
+896
+897 transformed_task >> generate_dict >> api_trigger_dependent_dag >> error_task
+for this case is there a way to have detailed view in Marquez Web UI?
+
+
+ *Thread Reply:* @Jakub Berezowski hello! could you please take a look at my case and advice what can be done whenever you have time? thank you!
+ + + + +
+
+
+
+
+ Hi All, +I'm based out of Sydney and we are using the open lineage on Azure data platform. +I'm looking for some direction and support where we got struck currently on lineage creation from Spark (Azure Synapse Analytics) +PySpark not able to emit lineage when there are some complex transformations happening. +The open lineage version we currently using is v0.18 and Spark version is 3.2.
+ + + +
+
+
+ *Thread Reply:* Hi, could you provide some more details on the issue you are facing? Some debug logs, specific error message, pyspark code that causes the issue? Also, current OpenLineage version is 1.9.1 , is there any reason you are using an outdated 0.18?
+
+
+ *Thread Reply:* Thanks for the headsup. We are in process of upgrading the library and get back to you.
+ + + + +
+
+
+
+
+ Hello everyone, is there anyone who integrated AWS MWAA with Openlineage, I'm trying it but it is not working, can you give some ideas and steps if you have an experience for that?
+ + + +
+
+
+ @channel +This month's TSC meeting, open to all, is tomorrow at 9:30 PT. The updated agenda includes exciting news of new integrations and presentations by @Damien Hawes and @Paweł Leszczyński. Hope to see you there! https://openlineage.slack.com/archives/C01CK9T7HKR/p1709756566788589
+
+
+
+ Hi team.. If we are trying to send openlineage events from spark job to kafka endpoint which requires keystore and truststore related properties to be configured, how can we configure it?
+ + + +
+
+
+ *Thread Reply:* Hey, check out this docs and spark.openlineage.transport.properties.[xxx] configuration. Is this what you are looking for?
+
+
+ *Thread Reply:* Yes... Thanks
+ + + +
+
+
+ Hello all 👋! +Has anyone tried to use spark udfs with openlineage? +Does it make sense for the column-level lineage to stop working in this context?
+ + + +
+
+
+ *Thread Reply:* did you investigate if it still works on a table-level?
+ + + +
+
+
+ *Thread Reply:* (I haven’t tried it, but looking at spark UDFs it looks like there are many differences - https://medium.com/@suffyan.asad1/a-deeper-look-into-spark-user-defined-functions-537c6efc5fb3 - nothing is jumping out at me as “this is why it doesn’t work” though.
+
+
+
+ This week brought us many fixes to the Flink integration like:
+• #2507 which resolves critical issues introduced in recent release,
+• #2508 which makes JDBC dataset naming consistent with dataset naming convention and having a common code for Spark & Flink to extract dataset identifier from JDBC connection url.
+• #2512 which includes database schema in dataset identifier for JDBC integration in Flink.
+These are significant improvements and I think they should not wait for the next release cycle.
+I would like to start a vote for an immediate release.
+
+
+ *Thread Reply:* Thanks, all. The release is approved..
+ + + +
+
+
+ *Thread Reply:* Changelog PR is here: https://github.com/OpenLineage/OpenLineage/pull/2516
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ @channel +We released OpenLineage 1.10.2, featuring:
+ +Additions
+• Dagster: add new provider for version 1.6.10 #2518 @JDarDagran
+• Flink: support lineage for a hybrid source #2491 @HuangZhenQiu
+• Flink: bump Flink JDBC connector version #2472 @HuangZhenQiu
+• Java: add a OpenLineageClientUtils#loadOpenLineageJson(InputStream) and change OpenLineageClientUtils#loadOpenLineageYaml(InputStream) methods #2490 @d-m-h
+• Java: add info from the HTTP response to the client exception #2486 @davidjgoss
+• Python: add support for MSK IAM authentication with a new transport #2478 @mattiabertorello
+Removal
+• Airflow: remove redundant information from facets #2524 @kacpermuda
+Fixes
+• Airflow: proceed without rendering templates if task_instance copy fails #2492 @kacpermuda
+• Flink: fix class not found issue for Cassandra #2507 @pawel-big-lebowski
+• Flink: refine the JDBC table name #2512 @HuangZhenQiu
+• Flink: fix JDBC dataset naming #2508 @pawel-big-lebowski
+• Flink: fix failure due to missing Cassandra classes #2507 @pawel-big-lebowski
+• Flink: fix release runtime dependencies #2504 @HuangZhenQiu
+• Spark: fix the HttpTransport timeout #2475 @pawel-big-lebowski
+• Spark: prevent NPE if the context is null #2515 @pawel-big-lebowski
+• Spec: improve Cassandra lineage metadata #2479 @HuangZhenQiu
+Thanks to all the contributors with a shout out to @Maciej Obuchowski for the after-hours CI fix!
+Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.10.2
+Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
+Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.9.1...1.10.2
+Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
+PyPI: https://pypi.org/project/openlineage-python/
 +
+
+
+
+
+ Hi I am new to Openlineage. So can someone help me to understand and how exactly it is setup and how I can setup in my personal laptop and play with it to gain hands on experience
+ + + +
+
+
+ *Thread Reply:* Hey, checkout our Getting Started guide, and the whole documentation on python, java, spark etc. where you will find all the information about the setup and configuration. For Airflow>=2.7, there is a separate documentation
+ + + +
+
+
+ *Thread Reply:* I am getting this error when i am following the commands in my windows laptop: +git clone git@github.com:MarquezProject/marquez.git && cd marquez/docker +running up.sh --seed +marquez-api | WARNING 'MARQUEZCONFIG' not set, using development configuration. +seed-marquez-with-metadata | wait-for-it.sh: waiting 15 seconds for api:5000 +marquez-web | [HPM] Proxy created: /api/v1 -> http://api:5000/ +marquez-web | App listening on port 3000! +marquez-api | INFO [2024-03-18 12:45:01,702] org.eclipse.jetty.util.log: Logging initialized @1991ms to org.eclipse.jetty.util.log.Slf4jLog +marquez-api | INFO [2024-03-18 12:45:01,795] io.dropwizard.server.DefaultServerFactory: Registering jersey handler with root path prefix: / +marquez-api | INFO [2024-03-18 12:45:01,796] io.dropwizard.server.DefaultServerFactory: Registering admin handler with root path prefix: / +marquez-api | INFO [2024-03-18 12:45:01,797] io.dropwizard.assets.AssetsBundle: Registering AssetBundle with name: graphql-playground for path /graphql-playground/** +marquez-api | INFO [2024-03-18 12:45:01,807] marquez.MarquezApp: Running startup actions... +marquez-api | INFO [2024-03-18 12:45:01,842] org.flywaydb.core.internal.license.VersionPrinter: Flyway Community Edition 8.5.13 by Redgate +marquez-api | INFO [2024-03-18 12:45:01,842] org.flywaydb.core.internal.license.VersionPrinter: See what's new here: https://flywaydb.org/documentation/learnmore/releaseNotes#8.5.13 +marquez-api | INFO [2024-03-18 12:45:01,842] org.flywaydb.core.internal.license.VersionPrinter: +marquez-db | 2024-03-18 12:45:02.039 GMT [34] FATAL: password authentication failed for user "marquez" +marquez-db | 2024-03-18 12:45:02.039 GMT [34] DETAIL: Role "marquez" does not exist. +marquez-db | Connection matched pghba.conf line 100: "host all all all scram-sha-256" +marquez-api | ERROR [2024-03-18 12:45:02,046] org.apache.tomcat.jdbc.pool.ConnectionPool: Unable to create initial connections of pool. +marquez-api | ! org.postgresql.util.PSQLException: FATAL: password authentication failed for user "marquez"
+ +Do I have to do any additional setup to run marquez in local.
+ + + +
+
+
+ *Thread Reply:* I don't think OpenLineage and Marquez support windows in any way
+ + + +
+
+
+ *Thread Reply:* But another way to explore OL and Marquez is with GitPod: https://github.com/MarquezProject/marquez?tab=readme-ov-file#try-it
+ + + +
+
+
+ *Thread Reply:* Also, @GUNJAN YADU have you tried deleting all volumes and starting over?
+ + + +
+
+
+ *Thread Reply:* Volumes as in?
+ + + +
+
+
+
+
+
+ *Thread Reply:* Okay +Its password authentication failure. So do I have to do any kind of posgres setup or environment variable setup
+ + + +
+
+
+ *Thread Reply:* marquez-db | 2024-03-18 13:19:37.211 GMT [36] FATAL: password authentication failed for user "marquez" +marquez-db | 2024-03-18 13:19:37.211 GMT [36] DETAIL: Role "marquez" does not exist.
+ + + +
+
+
+ *Thread Reply:* Setup is successful
+ + + +
+
+
+ *Thread Reply:* @GUNJAN YADU can share what steps you took to make it work?
+ + + +
+
+
+ *Thread Reply:* First I cleared the volumes +Then did the steps mentioned in link you shared in git bash. +It worked then
+ + + +
+
+
+ *Thread Reply:* Ah, so you used GitPod?
+ + + +
+
+
+ *Thread Reply:* No +I haven’t. I ran all the commands in git bash
+ + + + +
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* Hi Rohan, welcome! There are a number of guides across the OpenLineage and Marquez sites. Would you please share a link to the guide you are using? Also, terminal output as well as version and system information would be helpful. The issue could be a simple config problem or more complicated, but it's impossible to say from the screenshot.
+ + + +
+
+
+ *Thread Reply:* Hi Michael Robinson,
+ +Thank you for reverting on this.
+ +The link I used for installation : https://openlineage.io/getting-started/
+ +I have attached the terminal output.
+ +Docker version : 25.0.3, build 4debf41
+
+
+
+
+
+
+ *Thread Reply:* Thanks for the details, @Rohan Doijode. Unfortunately, Windows isn't currently supported. To explore OpenLineage+Marquez on Windows we recommend using this pre-configured Marquez Gitpod environment.
+ + + +
+
+
+ *Thread Reply:* Hi @Michael Robinson,
+ +Thank you for your input.
+ +My issues has been resolved.
+ + + +
+
+
+ Hey team! Quick check - has anyone submitted or is planning to submit a CFP for this year's Airflow Summit with an OL talk? Let me know! 🚀
+ + + +
+
+
+ *Thread Reply:* https://sessionize.com/airflow-summit-2024/
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* the CFP is scheduled to close on April 17
+ + + +
+
+
+ *Thread Reply:* Yup. I was thinking about submitting one, but don't want to overlap with someone that already did 🙂
+ + + + +
+
+
+
+
+ Hey Team, We are using MWAA (AWS Managed airflow) which is on version 2.7.2. So we are making use of airflow provided openlineage packages. We have simple test DAG which uses BashOperator and we would like to use manually annotated lineage. So we have provided the inlets and outlets. But when I am run the job. I see the errors - Failed to extract metadata using found extractor <airflow.providers.openlineage.extractors.bash.BashExtractor object at 0x7f9446276190> - section/key [openlineage/disabledforoperators]. Do I need to make any configuration changes?
+ + + +
+
+
+ *Thread Reply:* hey, there’s a fix for that: https://github.com/apache/airflow/pull/37994 +not released yet.
+ +Unfortunately, before the release you need to manually set missing entries in configuration
+ + + +
+
+
+ *Thread Reply:* Thanks @Jakub Dardziński . So the temporary fix is to set disabledforoperators for the unsupported operators? If I do that, Do I get my lineage emitted for bashOperator with manually annotated information?
+ + + +
+
+
+ *Thread Reply:* I think you should set it for disabled_for_operators, config_path and transport entries (maybe you’ve set some of them already)
+
+
+ *Thread Reply:* Ok . Thanks. Yes I did them already.
+ + + +
+
+
+ *Thread Reply:* These are my configurations. Its emitting run event only. I have my manually annotated lineage defined for the bashoperator. So when I provide the disabledforoperators, I don't see any errors, But log clearly says "Skipping extraction for operator BashOperator". So I don't see the inlets & outlets info in marquez. If I don't provide disabledforoperators, it fails with error "Failed to extract metadata using found extractor <airflow.providers.openlineage.extractors.bash.BashExtractor object at 0x7f9446276190> - section/key [openlineage/disabledforoperators]". So i cannot go either way. Any workaround? or I am making some mistake?
+ + + + + +
+
+
+ *Thread Reply:* Hey @Anand Thamothara Dass, make sure to simply set the config_path , disabled_for_operators and transport to empty strings, unless you actually want to use it (f.e. leave transport as it is if it contains the configuration to the backend). Current issue is that when no variables are found the error is raised, no matter if the actual value is set - they simply need to be in configuration, even as empty string.
In your setup i seed that you included BashOperator in disabled, so that's why it's ignored.
+ + + +
+
+
+ *Thread Reply:* Hmm strange. setting to empty strings worked. When I display it in console, I am able to see all the outlets information. But when I transport it to marquez endpoint, I am able to see only run events. No dataset information are captured in Marquez. But when I build the payload myself outside Airflow and push it using postman, I am able to see the dataset information as well in marquez. So I don't know where is the issue. Its airflow or openlineage or marquez 😕
+ + + +
+
+
+ *Thread Reply:* Could you share your dag code and task logs for that operator? I think if you use BashOperator and attach inlets and outlets to it, it should work just fine. Also please share the version of Ol package you are using and the name
+ + + +
+
+
+ *Thread Reply:* @Kacper Muda - Got that fixed. {"type": "http","url":"<http://10.80.35.62:3000%7Chttp://<ip>:3000>%22,%22endpoint%22:%22api/v1/lineage%22}. Got the end point removed. {"type": "http","url":"<http://10.80.35.62:3000%7Chttp://<ip>:3000>%22}. Kept only till here. It worked. Didn't think that, v1/lineage forces only run events capture. Thanks for all the support !!!
+ + + +
+
+
+ Hi all,
+ +We are planning to use OL as Data Lineage Tool.
+ +We have data in S3 and do use AWS Kinesis. We are looking forward for guidelines to generate graphical representation over Marquez or any other compatible tool.
+ +This includes lineage on column level and metadata during ETL.
+ +Thank you in advance
+ + + +
+
+
+ Hello all, we are struggling with a spark integration with AWS Glue. We have gotten to a configuration that is not causing errors in spark, but it’s not producing any output in the S3 bucket. Can anyone help figure out what’s wrong? (code in thread)
+ + + +
+
+
+ *Thread Reply:* ```import sys +from awsglue.transforms import ** +from awsglue.utils import getResolvedOptions +from pyspark.context import SparkContext +from awsglue.context import GlueContext +from awsglue.job import Job +from pyspark.context import SparkConf +from pyspark.sql import SparkSession
+ +args = getResolvedOptions(sys.argv, ["JOBNAME"]) +print(f'the job name received is : {args["JOBNAME"]}')
+ +spark1 = SparkSession.builder.appName("OpenLineageExample").config("spark.extraListeners", "io.openlineage.spark.agent.OpenLineageSparkListener").config("spark.openlineage.transport.type", "file").config("spark.openlineage.transport.location", "
glueContext = GlueContext(spark1) +spark = glueContext.spark_session
+ +job = Job(glueContext) +job.init(args["JOB_NAME"], args)
+ +df=spark.read.format("csv").option("header","true").load("s3://<bucket>/input/Master_Extract/")
+df.write.format('csv').option('header','true').save('
+
+
+ *Thread Reply:* cc @Rodrigo Maia since I know you’ve done some AWS glue
+ + + +
+
+
+ *Thread Reply:* Several things:
+ +s3 isn't a file system. It is an object storage system. Concretely, this means when an object is written, it's immutable. If you want to update the object, you need to read it in its entirety, modify it, and then write it back.s3 protocol.
+
+
+ *Thread Reply:* (As opposed the the file protocol)
+
+
+ *Thread Reply:* OK, so the problem is we’ve set it to config(“spark.openlineage.transport.type”, “file”) +and then give it s3:// instead of a file path…..
+ +But it’s AWS Glue so we don’t have a local filesystem to save it to.
+ + + +
+
+
+ *Thread Reply:* (I also hear you that S3 isn’t an ideal place for concatenating to a logfile because you can’t concatenate)
+ + + +
+
+
+ *Thread Reply:* Unfortunately, I have zero experience with Glue.
+ +Several approaches:
+ +
+
+
+ *Thread Reply:* I appreciate some ideas for next steps
+ + + +
+
+
+ *Thread Reply:* Thank you
+ + + +
+
+
+ *Thread Reply:* did you try transport console to check if the OL setup is working? regardless of i/o, it should put something in the logs with an event.
+ + + +
+
+
+ *Thread Reply:* Assuming the log4j[2].properties file is configured to allow the io.openlineage package to log at the appropriate level.
+
+
+ *Thread Reply:* @Sheeri Cabral (Collibra), did you try to use a different transport type, as suggested by @Damien Hawes in https://openlineage.slack.com/archives/C01CK9T7HKR/p1711038046057459?thread_ts=1711026366.869199&cid=C01CK9T7HKR? And described in the docs: +https://openlineage.io/docs/integrations/spark/configuration/transport#file
+ +Or would you like for the OL spark driver to support an additional transport type (e.g. s3) to emit OpenLineage events?
+
+
+
+ *Thread Reply:* I will try different transport types, haven’t gotten a chance to yet.
+ + + +
+
+
+ *Thread Reply:* Thanks, @Sheeri Cabral (Collibra); please let us know how it goes!
+ + + + +
+
+
+
+
+ *Thread Reply:* @Sheeri Cabral (Collibra) did you tried on the other transport types by any chance?
+ + + +
+
+
+ *Thread Reply:* Sorry, with the holiday long weekend in Europe things are a bit slow. We did, and I just put a message in the #general chat https://openlineage.slack.com/archives/C01CK9T7HKR/p1712147347085319 as we are getting some errors with the spark integration.
+
+
+
+ I've been testing around with different Spark versions. Does anyone know if OpenLineage works with spark 2.4.4 (scala 2.12.10)? Ive getting a lot of errors, but ive only tried versions 1.8+
+ + + +
+
+
+ *Thread Reply:* Hi @Rodrigo Maia, OpenLineage does not officially support Spark 2.4.4. The earliest version supported is 2.4.6. See this doc for more information about the supported versions of Spark, Airflow, Dagster, dbt, and Flink.
+ + + +
+
+
+ *Thread Reply:* OpenLineage CI runs against 2.4.6 and it is passing. I wouldn't expect any breaking differences between 2.4.4 and 2.4.6, but please let us know if this is the case.
+ + + +
+
+
+ @channel +Thanks to everyone who attended our first Boston meetup, co-sponsored by Astronomer and Collibra and featuring presentations by partners at Collibra, Astronomer and DataDog, this past Tuesday at Microsoft New England. Shout out to @Sheeri Cabral (Collibra), @Jonathan Morin, and @Paweł Leszczyński for presenting and to Sheeri for co-hosting! Topics included: +• "2023 in OpenLineage," a big year that saw: + ◦ 5 new integrations, + ◦ the Airflow Provider launch, + ◦ the addition of static/"design-time" lineage in 1.0.0, + ◦ the addition of column lineage from SQL statements via the SQL parser, + ◦ and 22 releases. +• A demo of Marquez, which now supports column-level lineage in a revamped UI +• Discussion of "Why Do People Use Lineage?" by Sheeri at Collibra, covering: + ◦ differences between design and operational lineage, + ◦ use cases served such as compliance, traceability/provenance, impact analysis, migration validation, and quicker onboarding, + ◦ features of Collibra's lineage +• A demo of streaming support in the Apache Flink integration by Paweł at Astronomer, illustrating lineage from: + ◦ a Flink job reading from a Kafka topic to Postgres, + ◦ a few SQL jobs running queries in Postgres, + ◦ a Flink job taking a Postgres table and publishing it back to Kafka +• A demo of an OpenLineage integration POC at DataDog by Jonathan, covering: + ◦ Use cases served by DataDog's Data Streams Monitoring service + ◦ OpenLineage's potential role providing and standardizing cross-platform lineage for DataDog's monitoring platform. +Thanks to Microsoft for providing the space. +If you're interested in attending, presenting at, or hosting a future meetup, please reach out.
+ +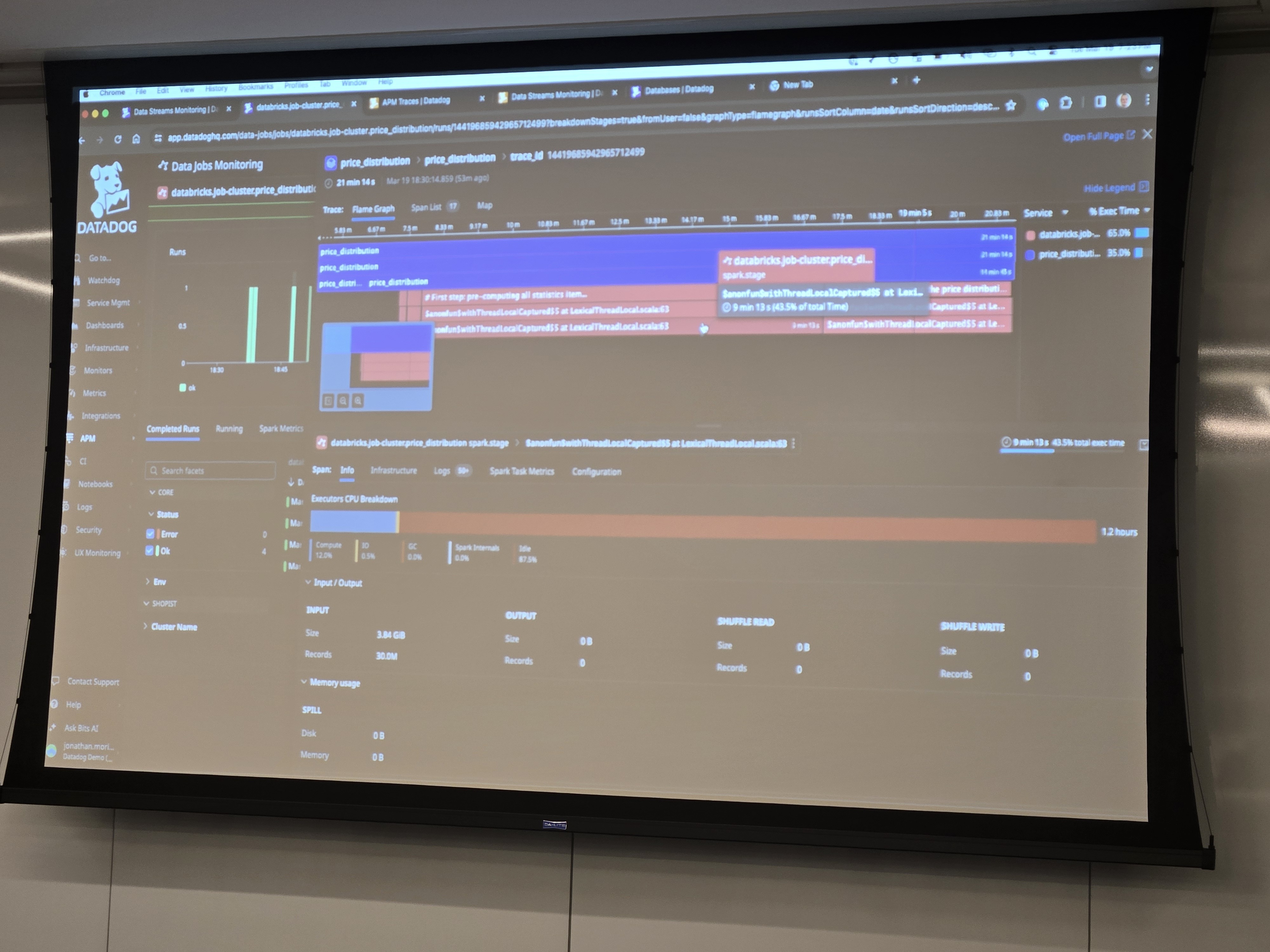 +
+
+
+
+
+
+
+ 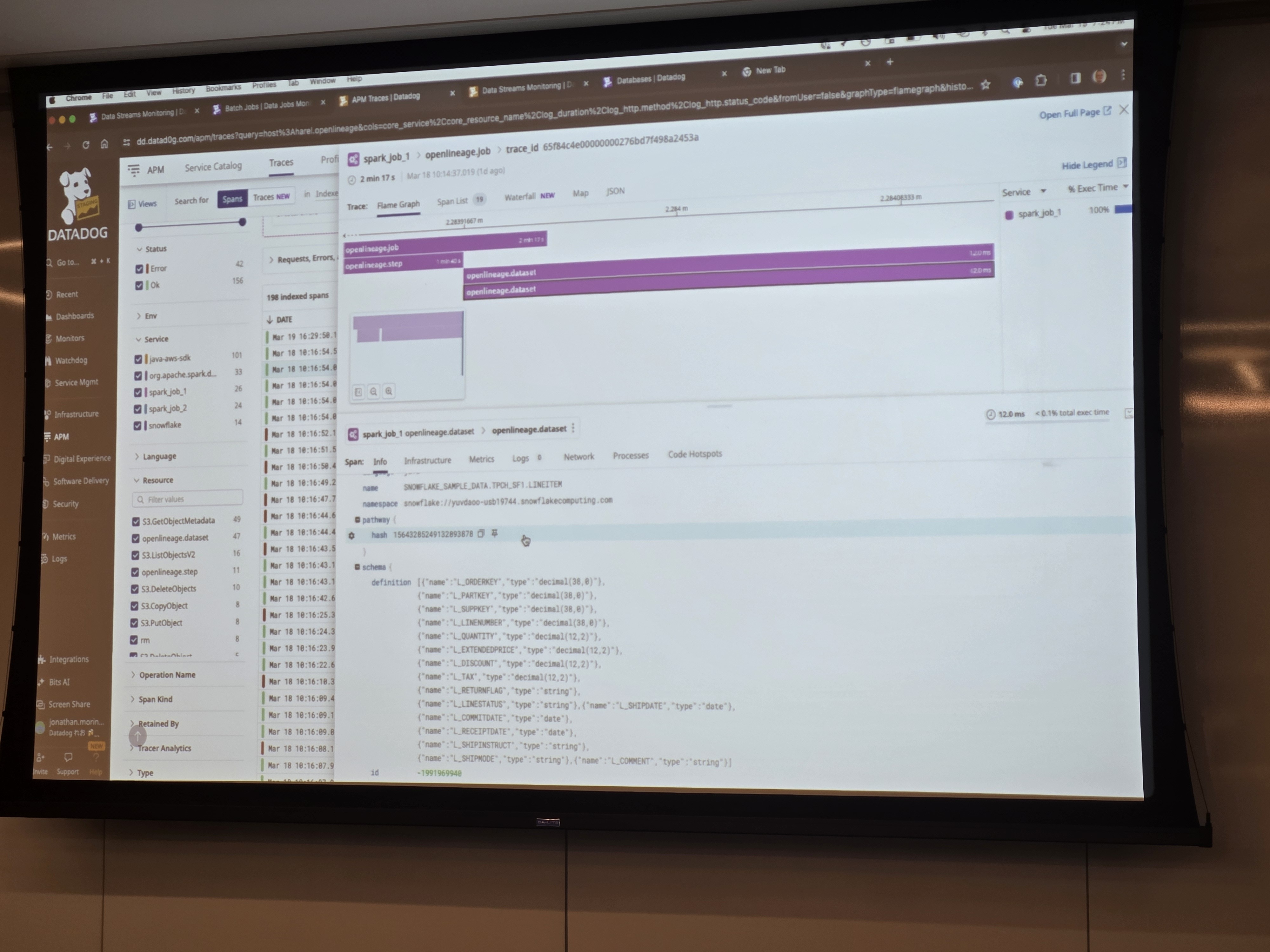 +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* Hey @Michael Robinson, was the meetup recorded?
+ + + +
+
+
+  +
+
+
+
+
+ Airflow 2.8.3 Python 3.11 +Trying to do a hello world lineage example using this simple bash operator DAG — but I don’t have anything emitting to my marquez backend. +I’m running airflow locally following docker-compose setup here. +More details in thread:
+ + + +
+
+
+ *Thread Reply:* Here is my airflow.cfg under
+```[webserver]
+expose_config = 'True'
[openlineage] +configpath = '' +transport = '{"type": "http", "url": "http://localhost:5002", "endpoint": "api/v1/lineage"}' +disabledfor_operators = ''```
+ + + +
+
+
+ *Thread Reply:* I can curl my marquez backend just fine — but yeah not seeing anything emitted by airflow
+ + + +
+
+
+ *Thread Reply:* Have I missed something in the set-up? Is there a way I can validate the config was ingested correctly?
+ + + +
+
+
+ *Thread Reply:* Can you see any logs related to OL in Airflow? Is Marquez in the same docker compose? Maybe try changing to host.docker.internal from localhost
+ + + +
+
+
+ *Thread Reply:* So I figured it out. For reference the issue was that ./config wasn’t for airflow.cfg as I had blindly interpreted it to be. Instead, setting the open lineage values as environment variables worked.
+
+
+ *Thread Reply:* Otherwise for the simple DAG with just BashOperators, I was expecting to see a similar “lineage” DAG in marquez, but I only see individual jobs. Is that expected?
+ +Formulating my question differently, does the open lineage data model assume a bipartite type graph, of Job -> Dataset -> Job -> Dataset etc always? Seems like there would be cases where you could have Job -> Job where there is no explicit “data artifact produced”?
+
+
+ *Thread Reply:* Another question — is there going to be integration with the “datasets” & inlets/outlets concept airflow now has? +E.g. I would expect the OL integration to capture this:
+ +```# [START datasetdef]
+dag1dataset = Dataset("
with DAG( + dagid="datasetproduces1", + catchup=False, + startdate=pendulum.datetime(2021, 1, 1, tz="UTC"), + schedule="@daily", + tags=["produces", "dataset-scheduled"], +) as dag1: + # [START taskoutlet] + BashOperator(outlets=[dag1dataset], taskid="producingtask1", bashcommand="sleep 5") + # [END task_outlet]``` +i.e. the outlets part. Currently it doesn’t seem to.
+ + + +
+
+
+ *Thread Reply:* OL only converts File and Table entities so far from manual inlets and outlets
+
+
+ *Thread Reply:* on the Job -> Dataset -> Job -> Dataset: OL and Marquez do not aim into reflecting Airflow DAGs. They rather focus on exposing metadata that is collected around data processing
+
+
+ *Thread Reply:* > on the Job -> Dataset -> Job -> Dataset: OL and Marquez do not aim into reflecting Airflow DAGs. They rather focus on exposing metadata that is collected around data processing
+That makes sense. I’m was just thinking through the implications and boundaries of what “lineage” is modeled. Thanks
+
+
+ Hi Team... We have a use case where we want to know when a column of the table gets updated in BIGQUERY and we have some questions related to it.
+ +
+
+
+ *Thread Reply:* For BigQuery, we use BigQuery API to get the lineage that unfortunately does not present us with column-level lineage. Adding that would be a feature.
+ +For 2. and 3. it might happen that the result you're reading is from query cache, as this was earlier executed and not changed - in that case we won't have full information yet. https://cloud.google.com/bigquery/docs/cached-results
+
+
+
+ *Thread Reply:* So, can we assume that if the query is not a duplicate one, fields outputs.facets.schema and output.namespace will not be empty? +And ignore the COMPLETE events when those fields are empty as they are not providing any new updates?
+ + + +
+
+
+ *Thread Reply:* > So, can we assume that if the query is not a duplicate one, fields outputs.facets.schema and output.namespace will not be empty? +Yes, I would assume so. +> And ignore the COMPLETE events when those fields are empty as they are not providing any new updates? +That probably depends on your use case, different jobs can access same tables/do same queries in that case.
+ + + +
+
+
+ *Thread Reply:* Okay. We wanted to know how can we determine the output datasource from the events?
+ + + +
+
+
+ Hi Team, +Currently OpenLineage Marquez use postgres db to store the meta data. Instead postgres, we want to store them on Snowflake DB. Do we have kind if inbuilt configuration in the marquez application to change the marquez database to Snowflake? If not, what will be the approach?
+ + + +
+
+
+ *Thread Reply:* The last time I looked at Marquez (July last year), Marquez was highly coupled to PostgreSQL specific functionality. It had code, particularly for the graph traversal, written in PostgreSQL's PL/pgSQL. Furthermore, it uses PostgreSQL as an OLTP database. My limited knowledge of Snowflake says that it is an OLAP database, this means that it would be a very poor fit for the application. For any migration to another database engine, it would be a large undertaking.
+ + + +
+
+
+ *Thread Reply:* Hi @Ruchira Prasad, this is not possible at the moment. Marquez splits OL events into neat relational model to allow efficient lineage queries. I don't think this would be achievable in Snowflake.
+ +As an alternative approach, you can try fluentd proxy -> https://github.com/OpenLineage/OpenLineage/tree/main/proxy/fluentd +Fluentd provides bunch of useful output plugins that let you send logs into several warehouses (https://www.fluentd.org/plugins), however I cannot find snowflake on the list.
+ +On the snowflake side, there is quickstart on how to ingest fluentd logs into it -> https://quickstarts.snowflake.com/guide/integrating_fluentd_with_snowflake/index.html#0
+ +To wrap up: if you need lineage events in Snowflake, you can consider sending events to a FluentD endpoint and then load them to Snowflake. In contrast to Marquez, you will query raw events which may be cumbersome in some cases like getting several OL events that describe a single run.
+ + + +
+
+
+ *Thread Reply:* Note that supporting (not even migrating) a backend application that can use multiple database engines comes at a huge opportunity cost, and it's not like Marquez has more contributors than it needs 🙂
+ + + +
+
+
+
+
+
+ *Thread Reply:* It doesn't have anything to do with the driver. JDBC is the driver, it defines the protocol that that communication link must abide by.
+ +Just like how ODBC is a driver, and in the .NET world, how OLE DB is a driver.
+ +It tells us nothing about the capabilities of the database. In this case, using PostgreSQL was chosen because of its capabilities, and because of those capabilities, the application code leverages more of those capabilities than just a generic read / write database. Moving all that logic from PostgreSQL PL/pgSQL to the application would (1) take a significant investment in time; (2) present bugs; (3) slow down the application response time, because you have to make many more round-trips to the database, instead of keeping the code close to the data.
+ + + +
+
+
+ *Thread Reply:* If you're still curious, and want to test things out for yourself:
+ + +
+
+
+
+
+ Hi Team,
+ +Looking for feedback on the below Problem and Proposal.
+ +We are using OpenLineage with our AWS EMR clusters to extract lineage and send it to a backend Marquez deployment (also in AWS). This is working fine and we are getting table and column level lineage.
+ +Problem: Is we are seeing: +• 15+ OpenLineage events with multiple jobs being shows in Marquez for a single Spark job in EMR. This causes confusion because team members using Marquez are unsure which "job" in Marquez to look at. +• The S3 locations are being populated in the namespace. We wanted to use namespace for teams. However, having S3 locations in the namespace in a way "pollutes" the list. +I understand the above are not issues/bugs. However, our users want us to "clean" up the Marquez UI.
+ +Proposal: One idea was to have a Lambda intercept the 10-20 raw OpenLineage events from EMR and then process -> condense them down to 1 event with the job, run, inputs, outputs. And secondly, to swap out the namespace from S3 to actual team names via a lookup we would host ourselves.
+ +While the above proposal technically could work we wanted to check with the team here if it makes sense, any caveats, alternatives others have used. Ideally, we don't want to own parsing OpenLineage events if there is an existing solution.
+ + + +
+
+
+
+
+
+
+
+
+ *Thread Reply:* Hi @Bipan Sihra, thanks for posting this -- it's exciting to hear about your use case at Amazon! I wonder if you wouldn't mind opening a GitHub issue so we can track progress on this and make sure you get answers to your questions.
+ + + +
+
+
+ *Thread Reply:* Also, would you please share the version of openlineage-spark you are on?
+ + + +
+
+
+ *Thread Reply:* Hi @Michael Robinson. Sure, I can open a Github issue.
+Also, we are currently using io.openlineage:openlineage_spark_2.12:1.9.1.
 +
+
+
+
+
+ *Thread Reply:* @Yannick Libert
+ + + +
+
+
+ *Thread Reply:* I was able to find info I needed here: https://github.com/OpenLineage/OpenLineage/discussions/597
+ + + + +
+
+
+
+
+ Hi Team, we are trying to collect lineage for a Spark job using OpenLineage(v1.8.0) and Marquez (v0.46). We can see the "Schema" details for all "Datasets" created but we can't see "Column-level" lineage and getting "Column lineage not available for the specified dataset" on Marquez UI under "COLUMN LINEAGE" tab.
+ +About Spark Job: The job reads data from few oracle tables using JDBC connections as Temp views in Spark, performs some transformations (joining & aggregations) over different steps, creating intermediate temp views and finally writing the data to HDFS location. So, it looks something like this:
+ +Read oracle tables as temp views -> transformations set1 --> creation of few more temp views from previously created temp views --> transformations set2, set3 ... --> Finally writing to hdfs(when all the temp view gets materialised in-memory to create final output dataset).
+We are getting the schema details for finally written dataset but no column-level lineage for the same. Also, while checking the json lineage data, I can see "" (blank) for "inputs" key (just before "outputs" key which contains dataset name & other details in nested key-value form). As per my understanding, this explains null value for "columnLineage" key hence no column-level lineage but unable to understand why!
Appreciate if you could share some thoughts/idea in terms of what is going wrong here as we are stuck on this point? Also, not sure we can get the column-level lineage only for datasets created from permanent Hive tables and not for temp/un-materialised views using OpenLineage & Marquez.
+ + + +
+
+
+ *Thread Reply:* My first guess would be that either some of the interaction between JDBC/views/materialization make the CLL not show, or possibly transformations - if you're doing stuff like UDFs we lose the column-level info, but it's hard to confirm without seeing events and/or some minimal reproduction
+ + + +
+
+
+ *Thread Reply:* Hi @Maciej Obuchowski, Thanks for responding on this. +We are using SparkSQL where we are reading the data from Oracle tables as temptable then running sql like queries (for transformation) on previously created temptable. +Now, let say we want to run a set of transformations, so we have written the transformation logic as sql like queryies. So, when this first query (query1) would get executed resulting in creation of temptable1, then query2 will get executed on temptable1 creating temptable2 and so on. For such use case, we have developed a custom function, this custom function will take these queries (query1, query2, ...) as input and will run iteratively and will create temptable1, temptable2,... and so on. This custom function uses RDD APIs and in-built functions like collect() along with few other scala functions. So, not sure whether usage of RDD will break the lineage or what's going wrong. +Lastly, we do have jobs where we are using direct UDFs in spark but we aren't getting CLL for those jobs also which doesn't have UDF usage. +Hope this gives some context on how we are running the job.
+ + + +
+
+
+ *Thread Reply:* Hey @Maciej Obuchowski, appreciate your help/comments on this.
+ + + + +
+
+
+
+
+ Hey everyone 👋
+ +I’m working at a carbon capture 🌍 company and we’re designing how we want to store data in our PostgreSQL database at the moment. One of the key things we’re focusing on is traceability and transparency of data, as well as ability to edit and maintain historical data. This is key as if we make an error and need to update a previous data point, we want to know everything downstream of that data point that needs to be rerun and recalculated. You might be able to guess where this is going… +• Any advice on how we should be designing our table schemas to support editing and traceability? We’re currently looking using temporal tables +• Is Open Lineage the right tool for downstream tracking and traceability? Are there any other tools we should be looking at instead? +I’m new here so hopefully I asked in the right channel. Let me know if I should be asking elsewhere!
+ + + +
+
+
+ *Thread Reply:* Hey, In my opinion, OpenLineage is the right tool for what you are describing. Together with some backend like Marquez it will allow you to visualize data flow, dependencies (upstreams, downstreams) and more 🙂
+ + + +
+
+
+ *Thread Reply:* Hi George, welcome! To add to what Kacper said, I think it also depends on what you are looking for in terms of "transparency." I guess I'm wondering exactly what you mean by this. A consumer using the OpenLineage standard (like Marquez, which we recommend in general but especially for getting started) will collect metadata about your pipelines' datasets and jobs but won't collect the data itself or support editing of your data. You're probably fully aware of this, but it's a point of confusion sometimes, and since you mentioned transparency and updating data I wanted to emphasize this. I hope this helps!
+ + + +
+
+
+ *Thread Reply:* Thanks for the thoughts folks! Yes I think my thoughts are starting to become more concrete - retaining a history of data and ensuring that you can always go back to a certain time of your data is different from understanding the downstream impact of a data change, (which is what OpenLineage seems to tackle)
+ + + + +
+
+
+
+
+ Hi team, so we're using OL v 1.3.1 on databricks, on a non termination cluster. We're seeing that the heap memory is increasing very significantly, and notice that the majority of the memory comes from OL. Any idea if we're having some memory leaks from OL? Have we seen any similar issues being reported before? Thanks!
+ + + +
+
+
+ *Thread Reply:* First idea would be to bump version 🙂
+ + + +
+
+
+ *Thread Reply:* Does it affect all the jobs or just some of them? Does it somehow correlate with amount of spark tasks a job is processing? Would you be able to test the behaviour on the jar prepared from the branch? Any other details helping to reproduce this would be nice.
+ +So many questions for the start... Happy to see you again @Anirudh Shrinivason. Can't wait looking into this next week.
+ + + +
+
+
+ *Thread Reply:* FYI - this is my experience as discussed on Tuesday @Paweł Leszczyński @Maciej Obuchowski
+ + + +
+
+
+ *Thread Reply:* Hey @Maciej Obuchowski @Paweł Leszczyński Thanks for the questions! Here are some details and clarifications I have:
+ +First idea would be to bump version Has such an issue been fixed in the later versions? So this is an already known issue with 1.3.1 version? Just curious why bumping it might resolve the issue...Does it affect all the jobs or just some of them So far, we're monitoring the heap at a cluster level... It's a shared non-termination cluster. I'll try to take a look at a job level to get some more insights.Does it somehow correlate with amount of spark tasks a job is processing This was my initial thought too, but from looking at a few of the pipelines, they seem relatively straightforward logic wise. And I don't think it's because a lot of tasks are running in parallel causing the amount of allocated objects to be very high... (Let me check back on this)Any other details helping to reproduce this would be nice. Yes! Let me try to dig a little more, and try to get back with more details...FYI - this is my experience as discussed on Tuesday Hi @Damien Hawes may I check if there is anywhere I could get some more information on your observations? Since it seems related, maybe they're the same issues?
+But all in all, I ran a high level memory analyzer, and it seemed to look like a memory leak from the OL jar... We noticed the heap size from OL almost monotonically increasing to >600mb...
+I'll try to check and do a bit more analysis before getting back with more details. :gratitudethankyou:
+
+
+ *Thread Reply:* This is what the heap dump looks like after 45 mins btw... ~11gb from openlineage out of 14gb heap
+ + +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* Nice. That's slightly different to my experience. We're running a streaming pipeline on a conventional Spark cluster (not databricks).
+ + + +
+
+
+ *Thread Reply:* OK. I've found the bug. I will create an issue for it.
+ +cc @Maciej Obuchowski @Paweł Leszczyński
+ + + +
+
+
+ *Thread Reply:* Great. I am also looking into unknown facet. I think this could be something like this -> https://github.com/OpenLineage/OpenLineage/pull/2557/files
+ + + +
+
+
+ *Thread Reply:* Not quite.
+ + + +
+
+
+ *Thread Reply:* The problem is that the UnknownEntryFacetListener accumulates state, even if the spark_unknown facet is disabled.
+
+
+ *Thread Reply:* The problem is that the code eagerly calls UnknownEntryFacetListener#apply
+
+
+ *Thread Reply:* Without checking if the facet is disabled or not.
+ + + +
+
+
+ *Thread Reply:* It only checks whether the facet is disabled or not, when it needs to add the details to the event.
+ + + +
+
+
+ *Thread Reply:* Furthermore, even if the facet is enabled, it never clears its state.
+ + + +
+
+
+ *Thread Reply:* yes, and if logical plan is spark.createDataFrame with local data, this can get huge
+
+
+ *Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/2561
+ + + +
+
+
+ *Thread Reply:* 🙇
+ + + + +
+
+
+
+
+ Hello All - I've begun my OL journey rather recently and am running into trouble getting lineage going in an airflow job. I spun up a quick flask server to accept and print the OL requests. It appears that there are no Inputs or Outputs. Is that something I have to set in my DAG? Reference code and responses are attached.
+ +
+
+
+ *Thread Reply:* hook-level lineage is not yet supported, you should you SnowflakeOperator instead
+ + + +
+
+
+
+
+
+ *Thread Reply:* you can see this is under SQLExecuteQueryOperator +without going into the details part of the implentation is on hooks side there, not the operator
+ + + + +
+
+
+
+
+ Hi team, we are collecting OpenLineage events across different jobs where the output datasources are BQ, Cassandra and Postgres. We are mostly interested in the freshness of columns across these different datasources. Using OpenLineage COMPLETE event's dataset.datasource and dataset.schema we want to understand which columns are updated at what time.
+ +We have a few questions related to BQ (as output dataset) events:
+ +
+
+
+ *Thread Reply:* > 1. How to identify if the output datasource is BQ, Cassandra or Postgres?
+The dataset namespace would contain that information: for example, the namespace for BQ would be simple bigquery and for Postgres it would be postgres://{host}:{port}
+
+
+ *Thread Reply:* > 1. Can we rely on dataset.datasource and dataset.schema for BQ table name and column names? +> 2. Even if one column is updated, do we get all the column details in dataset.schema? +> 3. If dataset.datasource or dataset.schema value is null, can we assume that no column has been updated in that event? +If talking about BigQuery Airflow operators, the known issue is BigQuery query caching. You're guaranteed to get this information if the query is running for the first time, but if the query is just reading from the cache instead of being executed, we don't get that information. That would result in a run without actual input dataset data.
+ + + +
+
+
+ *Thread Reply:* > 1. Is it possible to get columnLineage details for BQ as output datasource? +BigQuery API does not give us this information yet - we could augment the API data with SQL parser one though. It's a feature that don't exist yet though
+ + + +
+
+
+ *Thread Reply:* This is very helpful, thanks a lot @Maciej Obuchowski
+ + + + +
+
+
+
+
+ Hi all, we are trying to use dbt-ol to capture lineage. We use dbt custom aliases based on the --target flag passed in to dbt-ol run. So for example if using --target dev the model alias might be some_prefix__model_a whereas with --target prod the model alias might be model_a without any prefix. OpenLineage doesn't seem to pick up on this custom alias and sends model_a regardless in the input/output. Is this intended? I'm relatively new to this data world so it is possible I'm missing something basic here.
+
+
+ *Thread Reply:* Welcome and thanks for using OpenLineage! Someone with dbt expertise will reply soon.
+ + + +
+
+
+ *Thread Reply:* looks like it’s another entry in manifest.json : https://schemas.getdbt.com/dbt/manifest/v10.json
called alias that is not taken into consideration
+
+
+ *Thread Reply:* it needs more analysis whether and how this entry is set
+ + + +
+
+
+ *Thread Reply:* btw how do you create alias per target? I did this:
+ +-- Use the `ref` function to select from other models
+{% if target.name != 'prod' %}
+{{ config(materialized='incremental',unique_key='id',
+ on_schema_change='sync_all_columns', alias='third_model_dev'
+) }}
+{% else %}
+{{ config(materialized='incremental',unique_key='id',
+ on_schema_change='sync_all_columns', alias='third_model_prod'
+) }}
+{% endif %}
+
+select x.id, lower(y.name)
+from {{ ref('my_first_dbt_model') }} as x
+left join {{ ref('my_second_dbt_model' )}} as y
+ON x.id = y.i
+but I’m curious if that’s correct scenario to test
+ + + +
+
+
+ *Thread Reply:* thanks for looking into this @Jakub Dardziński! we are using the generatealiasname macro to control this. our macro looks very similar to this example
+ + + +
+
+
+ Is it possible to configure OL to only send OL Events for certain dags in airflow?
+ + + +
+
+
+ *Thread Reply:* it will be possible once latest version of OL provider is released with this PR: +https://github.com/apache/airflow/pull/37725
+
+ <a href="https://github.com/apache/airflow">apache/airflow</a>
+
+
+
+ *Thread Reply:* Thanks!
+ + + +
+
+
+ Is it common to see this error?
+ +
+
+
+ *Thread Reply:* seems like trim in select statements causes issues
+
+
+ @channel
+I'd like to open a vote to release OpenLineage 1.11.0, including:
+• Spark: lineage metadata extraction built-in to Spark extensions
+• Spark: change SparkPropertyFacetBuilder to support recording Spark runtime config
+• Java client: add metrics-gathering mechanism
+• Flink: support Flink 1.19.0
+• SQL: show error message when OpenLineageSql cannot find native library
+Three +1s from committers will authorize. Thanks!
+
+
+ *Thread Reply:* Thanks, all. The release is authorized and will be performed within 2 business days excluding tomorrow.
+ + + +
+
+
+ @channel +The latest issue of OpenLineage News is available now, featuring a rundown of upcoming and recent events, recent releases, updates to the Airflow Provider, open proposals, and more. +To get the newsletter directly in your inbox each month, sign up here. +openlineage.us14.list-manage.com
+
+
+
+ Hi All, We are trying transform entities according to medallian model, where each entity goes through multiple layers of data transformation and the workflow is like the data is picked from kafka channel and stored into parquet and then trasforming it to hudi tables in silver layer. so now we are trying to capture lineage data, so far we have tried with transport type console but we are not seeing the lineage data in console (we are running this job from aws glue). below are the configuration which we have added. +spark = (SparkSession.builder + .appName('samplelineage') + .config('spark.jars.packages', 'io.openlineage:openlineagespark:1.8.0') + .config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener') + .config('spark.openlineage.namespace', 'LineagePortTest') + .config('spark.openlineage.parentJobNamespace', 'LineageJobNameSpace') + .config("spark.openlineage.transport.type", "console") + .config('spark.openlineage.parentJobName', 'LineageJobName') + .getOrCreate())
+ + + +
+
+
+ *Thread Reply:* Does Spark tell your during startup that it is adding the listener?
+ +The log line should be something like "Adding io.openlineage.spark.agent.OpenLineageSparkListener"
+ + + +
+
+
+ *Thread Reply:* Additionally, ensure your log4j.properties / log4j2.properties (depending on the version of Spark that you are using) allows io.openlineage at info level
+
+
+ *Thread Reply:* I think, as usual, hudi is the problem 🙂
+ + + +
+
+
+ *Thread Reply:* or are you just not seeing any OL logs/events?
+ + + +
+
+
+ *Thread Reply:* as @Damien Hawes said, you should see Spark log
+org.apache.spark.SparkContext - Registered listener io.openlineage.spark.agent.OpenLineageSparkListener
+
+
+
+
+
+ *Thread Reply:* Also we are not seeing OL events
+ + + +
+
+
+ *Thread Reply:* do you see any errors or other logs that could be relevant to OpenLineage? +also, some simple reproduction might help
+ + + +
+
+
+ *Thread Reply:* ya we could see below logs INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionEnd
+ + + + +
+
+
+
+
+ Hi All! Im trying to set up OpenLineage with Managed Flink at AWS. but im getting this error:
+ +`"throwableInformation": "io.openlineage.client.transports.HttpTransportResponseException: code: 400, response: \n\tat io.openlineage.client.transports.HttpTransport.throwOnHttpError(HttpTransport.java:151)\n\tat`
+This is what i see in marquez. where is flink is trying to send the open lineage events
+ +items
+"message":string"The Job Result cannot be fetch..."
+"_producer":string"<https://github.com/OpenLineage>..."
+"_schemaURL":string"<https://openlineage.io/spec/fa>..."
+"stackTrace":string"org.apache.flink.util.FlinkRuntimeException: The Job Result cannot be fetched through the Job Client when in Web Submission. at org.apache.flink.client.deployment.application.WebSubmissionJobClient.getJobExecutionResult(WebSubmissionJobClient.java:92) at
Im passing the conf like this:
+ +Properties props = new Properties();
+props.put("openlineage.transport.type","http");
+props.put("openlineage.transport.url","http://<marquez-ip>:5000/api/v1/lineage");
+props.put("execution.attached","true");
+Configuration conf = ConfigurationUtils.createConfiguration(props);
+StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
+
+
+ *Thread Reply:* Hey @Francisco Morillo, which version of Marquez are you running? Streaming support was a relatively recent addition to Marquez
+ + + +
+
+
+ *Thread Reply:* So i was able to set it up working locally. Having Flink integrated with open lineage
+ + + +
+
+
+ *Thread Reply:* But once i deployed marquez in an ec2 using docker
+ + + +
+
+
+ *Thread Reply:* and have managed flink trying to emit events to openlineage i just receive the flink job event, but not the kafka source / iceberg sink
+ + + +
+
+
+ *Thread Reply:* I ran this:
+$ git clone git@github.com:MarquezProject/marquez.git && cd marquez
+
+
+ *Thread Reply:* hmmm. I see. you're probably running the latest version of marquez then, should be ok. +did you try the console transport first to see how the events look like?
+ + + +
+
+
+ *Thread Reply:* kafka source and iceberg sink should be well supported for flink
+ + + +
+
+
+ *Thread Reply:* i believe there is an issue with how the conf is passed to flink job in managed flink
+ + + +
+
+
+ *Thread Reply:* ah, that may be the case. what are you seeing in the flink job logs?
+ + + +
+
+
+ *Thread Reply:* I think setting execution.attached might not work when you set it this way
+
+
+ *Thread Reply:* is there an option to use regular flink-conf.yaml?
+
+
+ *Thread Reply:* in the flink logs im seeing the io.openlineage.client.transports.HttpTransportResponseException: code: 400, response: \n\tat.
+ +in marquez im seeing the job result cannot be fetched.
+ +we cant modify flink-conf in managed flink
+ + + +
+
+
+
+
+
+ *Thread Reply:* this is what i see at marquez at ec2
+ + + +
+
+
+ *Thread Reply:* hmmm.. I'm wondering if the issue is with Marquez processing the events or the openlineage events themselves.
+can you try with:
+props.put("openlineage.transport.type","console");
+?
+
+
+ *Thread Reply:* compared to what i see locally. Locally is the same job but just writing to localhost marquez, but im passing the openlineage conf trough env
+ + + +
+
+
+ *Thread Reply:* @Harel Shein when set to console, where will the events be printed? Cloudwatch logs?
+ + + +
+
+
+ *Thread Reply:* I think so, yes
+ + + +
+
+
+ *Thread Reply:* let me try
+ + + +
+
+
+ *Thread Reply:* the same place you're seeing your flink logs right now
+ + + +
+
+
+ *Thread Reply:* the same place you found that client exception
+ + + +
+
+
+ *Thread Reply:* I will post the events
+ + + +
+
+
+ *Thread Reply:* "logger": "io.openlineage.flink.OpenLineageFlinkJobListener", "message": "onJobSubmitted event triggered for flink-jobs-prod.kafka-iceberg-prod", "messageSchemaVersion": "1", "messageType": "INFO", "threadName": "Flink-DispatcherRestEndpoint-thread-4" }
+
+
+ *Thread Reply:* "locationInformation": "io.openlineage.flink.TransformationUtils.processLegacySinkTransformation(TransformationUtils.java:90)", "logger": "io.openlineage.flink.TransformationUtils", "message": "Processing legacy sink operator Print to System.out", "messageSchemaVersion": "1", "messageType": "INFO", "threadName": "Flink-DispatcherRestEndpoint-thread-4" }
+
+
+ *Thread Reply:* "locationInformation": "io.openlineage.flink.TransformationUtils.processLegacySinkTransformation(TransformationUtils.java:90)", "logger": "io.openlineage.flink.TransformationUtils", "message": "Processing legacy sink operator org.apache.flink.streaming.api.functions.sink.DiscardingSink@68d0a141", "messageSchemaVersion": "1", "messageType": "INFO", "threadName": "Flink-DispatcherRestEndpoint-thread-4" }
+
+
+ *Thread Reply:* "locationInformation": "io.openlineage.client.transports.ConsoleTransport.emit(ConsoleTransport.java:21)", "logger": "io.openlineage.client.transports.ConsoleTransport", "message": "{\"eventTime\":\"2024_04_02T20:07:03.30108Z\",\"producer\":\"<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\",\"schemaURL\":\"<https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent>\",\"eventType\":\"START\",\"run\":{\"runId\":\"cda9a0d2_6dfd_4db2_b3d0_f11d7b082dc0\"},\"job\":{\"namespace\":\"flink_jobs_prod\",\"name\":\"kafka-iceberg-prod\",\"facets\":{\"jobType\":{\"_producer\":\"<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\",\"_schemaURL\":\"<https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet>\",\"processingType\":\"STREAMING\",\"integration\":\"FLINK\",\"jobType\":\"JOB\"}}},\"inputs\":[{\"namespace\":\"<kafka://b-1.mskflinkopenlineage>.<>.<http://kafka.us-east-1.amazonaws.com:9092,b_3.mskflinkopenlineage.<>kafka.us_east_1.amazonaws.com:9092,b-2.mskflinkopenlineage.<>.c22.kafka.us-east-1.amazonaws.com:9092\%22,\%22name\%22:\%22temperature-samples\%22,\%22facets\%22:{\%22schema\%22:{\%22_producer\%22:\%22<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\%22,\%22_schemaURL\%22:\%22<https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet>\%22,\%22fields\%22:[{\%22name\%22:\%22sensorId\%22,\%22type\%22:\%22int\%22},{\%22name\%22:\%22room\%22,\%22type\%22:\%22string\%22},{\%22name\%22:\%22temperature\%22,\%22type\%22:\%22float\%22},{\%22name\%22:\%22sampleTime\%22,\%22type\%22:\%22long\%22}]}}|kafka.us_east_1.amazonaws.com:9092,b-3.mskflinkopenlineage.<>kafka.us-east-1.amazonaws.com:9092,b_2.mskflinkopenlineage.<>.c22.kafka.us_east_1.amazonaws.com:9092\",\"name\":\"temperature_samples\",\"facets\":{\"schema\":{\"_producer\":\"<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\",\"_schemaURL\":\"<https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet>\",\"fields\":[{\"name\":\"sensorId\",\"type\":\"int\"},{\"name\":\"room\",\"type\":\"string\"},{\"name\":\"temperature\",\"type\":\"float\"},{\"name\":\"sampleTime\",\"type\":\"long\"}]}}>}],\"outputs\":[{\"namespace\":\"<s3://iceberg-open-lineage-891377161433>\",\"name\":\"/iceberg/open_lineage.db/open_lineage_room_temperature_prod\",\"facets\":{\"schema\":{\"_producer\":\"<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\",\"_schemaURL\":\"<https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet>\",\"fields\":[{\"name\":\"room\",\"type\":\"STRING\"},{\"name\":\"temperature\",\"type\":\"FLOAT\"},{\"name\":\"sampleCount\",\"type\":\"INTEGER\"},{\"name\":\"lastSampleTime\",\"type\":\"TIMESTAMP\"}]}}}]}",
+
+
+ *Thread Reply:* locationInformation": "io.openlineage.flink.tracker.OpenLineageContinousJobTracker.startTracking(OpenLineageContinousJobTracker.java:100)", "logger": "io.openlineage.flink.tracker.OpenLineageContinousJobTracker", "message": "Starting tracking thread for jobId=de9e0d5b5d19437910975f231d5ed4b5", "messageSchemaVersion": "1", "messageType": "INFO", "threadName": "Flink-DispatcherRestEndpoint-thread-4" }
+
+
+ *Thread Reply:* "locationInformation": "io.openlineage.flink.OpenLineageFlinkJobListener.onJobExecuted(OpenLineageFlinkJobListener.java:191)", "logger": "io.openlineage.flink.OpenLineageFlinkJobListener", "message": "onJobExecuted event triggered for flink-jobs-prod.kafka-iceberg-prod", "messageSchemaVersion": "1", "messageType": "INFO", "threadName": "Flink-DispatcherRestEndpoint-thread-4" }
+
+
+ *Thread Reply:* "locationInformation": "io.openlineage.flink.tracker.OpenLineageContinousJobTracker.stopTracking(OpenLineageContinousJobTracker.java:120)", "logger": "io.openlineage.flink.tracker.OpenLineageContinousJobTracker", "message": "stop tracking", "messageSchemaVersion": "1", "messageType": "INFO", "threadName": "Flink-DispatcherRestEndpoint-thread-4" }
+
+
+ *Thread Reply:* "locationInformation": "io.openlineage.client.transports.ConsoleTransport.emit(ConsoleTransport.java:21)", "logger": "io.openlineage.client.transports.ConsoleTransport", "message": "{\"eventTime\":\"2024_04_02T20:07:04.028017Z\",\"producer\":\"<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\",\"schemaURL\":\"<https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent>\",\"eventType\":\"FAIL\",\"run\":{\"runId\":\"cda9a0d2_6dfd_4db2_b3d0_f11d7b082dc0\",\"facets\":{\"errorMessage\":{\"_producer\":\"<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\",\"_schemaURL\":\"<https://openlineage.io/spec/facets/1-0-0/ErrorMessageRunFacet.json#/$defs/ErrorMessageRunFacet>\",\"message\":\"The Job Result cannot be fetched through the Job Client when in Web Submission.\",\"programmingLanguage\":\"JAVA\",\"stackTrace\":\"org.apache.flink.util.FlinkRuntimeException: The Job Result cannot be fetched through the Job Client when in Web Submission.\\n\\tat org.apache.flink.client.deployment.application.WebSubmissionJobClient.getJobExecutionResult(WebSubmissionJobClient.java:92)\\n\\tat org.apache.flink.client.program.StreamContextEnvironment.getJobExecutionResult(StreamContextEnvironment.java:152)\\n\\tat org.apache.flink.client.program.StreamContextEnvironment.execute(StreamContextEnvironment.java:123)\\n\\tat org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1969)\\n\\tat com.amazonaws.services.msf.KafkaStreamingJob.main(KafkaStreamingJob.java:342)\\n\\tat java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\\n\\tat java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\\n\\tat java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\\n\\tat java.base/java.lang.reflect.Method.invoke(Method.java:566)\\n\\tat org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355)\\n\\tat org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)\\n\\tat org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)\\n\\tat org.apache.flink.client.deployment.application.DetachedApplicationRunner.tryExecuteJobs(DetachedApplicationRunner.java:84)\\n\\tat org.apache.flink.client.deployment.application.DetachedApplicationRunner.run(DetachedApplicationRunner.java:70)\\n\\tat org.apache.flink.runtime.webmonitor.handlers.JarRunOverrideHandler.lambda$handleRequest$3(JarRunOverrideHandler.java:239)\\n\\tat java.base/java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1700)\\n\\tat java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)\\n\\tat java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)\\n\\tat java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304)\\n\\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)\\n\\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)\\n\\tat java.base/java.lang.Thread.run(Thread.java:829)\\n\"}}},\"job\":{\"namespace\":\"flink_jobs_prod\",\"name\":\"kafka-iceberg-prod\",\"facets\":{\"jobType\":{\"_producer\":\"<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>\",\"_schemaURL\":\"<https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet>\",\"processingType\":\"STREAMING\",\"integration\":\"FLINK\",\"jobType\":\"JOB\"}}}}", "messageSchemaVersion": "1", "messageType": "INFO", "threadName": "Flink-DispatcherRestEndpoint-thread-4" }
+
+
+ *Thread Reply:* this is what i see in cloudwatch when set to console
+ + + +
+
+
+ *Thread Reply:* So its nothing to do with marquez but with openlineage and flink
+ + + +
+
+
+ *Thread Reply:* hmm.. the start event actually looks pretty good to me:
+{
+ "eventTime": "2024-04-02T20:07:03.30108Z",
+ "producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>",
+ "schemaURL": "<https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent>",
+ "eventType": "START",
+ "run": {
+ "runId": "cda9a0d2-6dfd-4db2-b3d0-f11d7b082dc0"
+ },
+ "job": {
+ "namespace": "flink-jobs-prod",
+ "name": "kafka-iceberg-prod",
+ "facets": {
+ "jobType": {
+ "_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>",
+ "_schemaURL": "<https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet>",
+ "processingType": "STREAMING",
+ "integration": "FLINK",
+ "jobType": "JOB"
+ }
+ }
+ },
+ "inputs": [
+ {
+ "namespace": "<kafka://b-1.mskflinkopenlineage>.<>.<http://kafka.us-east-1.amazonaws.com:9092,b_3.mskflinkopenlineage.<>kafka.us_east_1.amazonaws.com:9092,b-2.mskflinkopenlineage.<>.c22.kafka.us-east-1.amazonaws.com:9092|kafka.us_east_1.amazonaws.com:9092,b-3.mskflinkopenlineage.<>kafka.us-east-1.amazonaws.com:9092,b_2.mskflinkopenlineage.<>.c22.kafka.us_east_1.amazonaws.com:9092>",
+ "name": "temperature-samples",
+ "facets": {
+ "schema": {
+ "_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>",
+ "_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet>",
+ "fields": [
+ {
+ "name": "sensorId",
+ "type": "int"
+ },
+ {
+ "name": "room",
+ "type": "string"
+ },
+ {
+ "name": "temperature",
+ "type": "float"
+ },
+ {
+ "name": "sampleTime",
+ "type": "long"
+ }
+ ]
+ }
+ }
+ }
+ ],
+ "outputs": [
+ {
+ "namespace": "<s3://iceberg-open-lineage-891377161433>",
+ "name": "/iceberg/open_lineage.db/open_lineage_room_temperature_prod",
+ "facets": {
+ "schema": {
+ "_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>",
+ "_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet>",
+ "fields": [
+ {
+ "name": "room",
+ "type": "STRING"
+ },
+ {
+ "name": "temperature",
+ "type": "FLOAT"
+ },
+ {
+ "name": "sampleCount",
+ "type": "INTEGER"
+ },
+ {
+ "name": "lastSampleTime",
+ "type": "TIMESTAMP"
+ }
+ ]
+ }
+ }
+ }
+ ]
+}
+
+
+ *Thread Reply:* so with that start event should marquez be able to build the proper lineage?
+ + + +
+
+
+ *Thread Reply:* This is what i would get with flink marquez locally
+ + +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* yes, but then it looks like the flink job is failing and we're seeing this event:
+{
+ "eventTime": "2024-04-02T20:07:04.028017Z",
+ "producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>",
+ "schemaURL": "<https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent>",
+ "eventType": "FAIL",
+ "run": {
+ "runId": "cda9a0d2-6dfd-4db2-b3d0-f11d7b082dc0",
+ "facets": {
+ "errorMessage": {
+ "_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>",
+ "_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/ErrorMessageRunFacet.json#/$defs/ErrorMessageRunFacet>",
+ "message": "The Job Result cannot be fetched through the Job Client when in Web Submission.",
+ "programmingLanguage": "JAVA",
+ "stackTrace": "org.apache.flink.util.FlinkRuntimeException: The Job Result cannot be fetched through the Job Client when in Web Submission.ntat org.apache.flink.client.deployment.application.WebSubmissionJobClient.getJobExecutionResult(WebSubmissionJobClient.java:92)ntat org.apache.flink.client.program.StreamContextEnvironment.getJobExecutionResult(StreamContextEnvironment.java:152)ntat org.apache.flink.client.program.StreamContextEnvironment.execute(StreamContextEnvironment.java:123)ntat org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1969)ntat com.amazonaws.services.msf.KafkaStreamingJob.main(KafkaStreamingJob.java:342)ntat java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)ntat java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)ntat java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)ntat java.base/java.lang.reflect.Method.invoke(Method.java:566)ntat org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355)ntat org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)ntat org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)ntat org.apache.flink.client.deployment.application.DetachedApplicationRunner.tryExecuteJobs(DetachedApplicationRunner.java:84)ntat org.apache.flink.client.deployment.application.DetachedApplicationRunner.run(DetachedApplicationRunner.java:70)ntat org.apache.flink.runtime.webmonitor.handlers.JarRunOverrideHandler.lambda$handleRequest$3(JarRunOverrideHandler.java:239)ntat java.base/java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1700)ntat java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)ntat java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)ntat java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304)ntat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)ntat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)ntat java.base/java.lang.Thread.run(Thread.java:829)n"
+ }
+ }
+ },
+ "job": {
+ "namespace": "flink-jobs-prod",
+ "name": "kafka-iceberg-prod",
+ "facets": {
+ "jobType": {
+ "_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.10.2/integration/flink>",
+ "_schemaURL": "<https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet>",
+ "processingType": "STREAMING",
+ "integration": "FLINK",
+ "jobType": "JOB"
+ }
+ }
+ }
+}
+
+
+ *Thread Reply:* But the thing is that the flink job is not really failling
+ + + +
+
+
+ *Thread Reply:* interesting, would love to see what @Paweł Leszczyński / @Maciej Obuchowski / @Peter Huang think. This is beyond my depth on the flink integration 🙂
+ + + +
+
+
+ *Thread Reply:* Thanks Harel!! Yes please, it would be great to see how openlineage can work with AWS Managed flink
+ + + +
+
+
+ *Thread Reply:* Just to clarify - is this setup working with openlineage flink integration turned off? From what I understand, your job emits cool START event, than a job fails and emits FAIL event with error stacktrace The Job Result cannot be fetched through the Job Client when in Web Submission which is cool as well.
The question is: does it fail bcz of Openlineage integration or it is just Openlineage which carries stacktrace of a failed job. I couldn't see anything Openlineage related in the stacktrace.
+ + + +
+
+
+ *Thread Reply:* What do you mean with Flink integration turned off?
+ + + +
+
+
+ *Thread Reply:* the flink job is not failling but, we are receiving an openlineage event that says fail, to which we then not see the proper dag in marquez
+ + + +
+
+
+ *Thread Reply:* does openlineage work if the job is submited through web submission?
+ + + +
+
+
+ *Thread Reply:* the answer is "probably not unless you can set up execution.attached beforehand"
+
+
+ *Thread Reply:* execution.attached doesnt seem to work with job submitted through web submission.
+ + + +
+
+
+ *Thread Reply:* When setting execution attached to false, i only get the start event, but it doesnt build the dag in the job space in marquez
+ + + +
+
+
+
+
+
+ *Thread Reply:* I still see this in cloudwatch logs: locationInformation": "io.openlineage.flink.client.EventEmitter.emit(EventEmitter.java:50)", "logger": "io.openlineage.flink.client.EventEmitter", "message": "Failed to emit OpenLineage event: ", "messageSchemaVersion": "1", "messageType": "ERROR", "threadName": "Flink-DispatcherRestEndpoint-thread-1", "throwableInformation": "io.openlineage.client.transports.HttpTransportResponseException: code: 400, response: \n\tat io.openlineage.client.transports.HttpTransport.throwOnHttpError(HttpTransport.java:151)\n\tat io.openlineage.client.transports.HttpTransport.emit(HttpTransport.java:128)\n\tat io.openlineage.client.transports.HttpTransport.emit(HttpTransport.java:115)\n\tat io.openlineage.client.OpenLineageClient.emit(OpenLineageClient.java:60)\n\tat io.openlineage.flink.client.EventEmitter.emit(EventEmitter.java:48)\n\tat io.openlineage.flink.visitor.lifecycle.FlinkExecutionContext.lambda$onJobSubmitted$0(FlinkExecutionContext.java:66)\n\tat io.openlineage.client.circuitBreaker.NoOpCircuitBreaker.run(NoOpCircuitBreaker.java:27)\n\tat io.openlineage.flink.visitor.lifecycle.FlinkExecutionContext.onJobSubmitted(FlinkExecutionContext.java:59)\n\tat io.openlineage.flink.OpenLineageFlinkJobListener.start(OpenLineageFlinkJobListener.java:180)\n\tat io.openlineage.flink.OpenLineageFlinkJobListener.onJobSubmitted(OpenLineageFlinkJobListener.java:156)\n\tat org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.lambda$executeAsync$12(StreamExecutionEnvironment.java:2099)\n\tat java.base/java.util.ArrayList.forEach(ArrayList.java:1541)\n\tat org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.executeAsync(StreamExecutionEnvironment.java:2099)\n\tat org.apache.flink.client.program.StreamContextEnvironment.executeAsync(StreamContextEnvironment.java:188)\n\tat org.apache.flink.client.program.StreamContextEnvironment.execute(StreamContextEnvironment.java:119)\n\tat org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1969)\n\tat com.amazonaws.services.msf.KafkaStreamingJob.main(KafkaStreamingJob.java:345)\n\tat java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\n\tat java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\tat java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\tat java.base/java.lang.reflect.Method.invoke(Method.java:566)\n\tat org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355)\n\tat org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)\n\tat org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)\n\tat org.apache.flink.client.deployment.application.DetachedApplicationRunner.tryExecuteJobs(DetachedApplicationRunner.java:84)\n\tat org.apache.flink.client.deployment.application.DetachedApplicationRunner.run(DetachedApplicationRunner.java:70)\n\tat org.apache.flink.runtime.webmonitor.handlers.JarRunOverrideHandler.lambda$handleRequest$3(JarRunOverrideHandler.java:239)\n\tat java.base/java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1700)\n\tat java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)\n\tat java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)\n\tat java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)\n\tat java.base/java.lang.Thread.run(Thread.java:829)\n"
+
+
+ *Thread Reply:* I think it will be a limitation of our integration then, at least until https://cwiki.apache.org/confluence/display/FLINK/FLIP-314%3A+Support+Customized+Job+Lineage+Listener - the way we're integrating with Flink requires it to be able to access execution results +https://github.com/OpenLineage/OpenLineage/blob/main/integration/flink/app/src/main/java/io/openlineage/flink/OpenLineageFlinkJobListener.java#L[…]6
+ +not sure if we can somehow work around this
+ + + +
+
+
+ *Thread Reply:* with that flip we wouldnt need execution.attached?
+ + + +
+
+
+ *Thread Reply:* Nope - it would add different mechanism to integrate with Flink other than JobListener
+ + + +
+
+
+ *Thread Reply:* Could a workaround be, instead of having the http tranport, sending to kafka and have a java/python client writing the events to marquez?
+ + + +
+
+
+ *Thread Reply:* because i just tried with executtion.attached to false and with console transport, i just receive the event for start but no errors. not sure if thats the only event needed in marquez to build a dag
+ + + +
+
+
+ *Thread Reply:* also, wondering if the event actually reached marquez, why wouldnt the job dag be showned?
+ + + +
+
+
+ *Thread Reply:* its the same start event i have received when running localy
+ + + +
+
+
+ *Thread Reply:*
+ + +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* comparison of marquez receiving event from managed flink on aws (left). to marquez localhost receiving event from local flink. its the same event. however marquez in ec2 is not building dag
+ +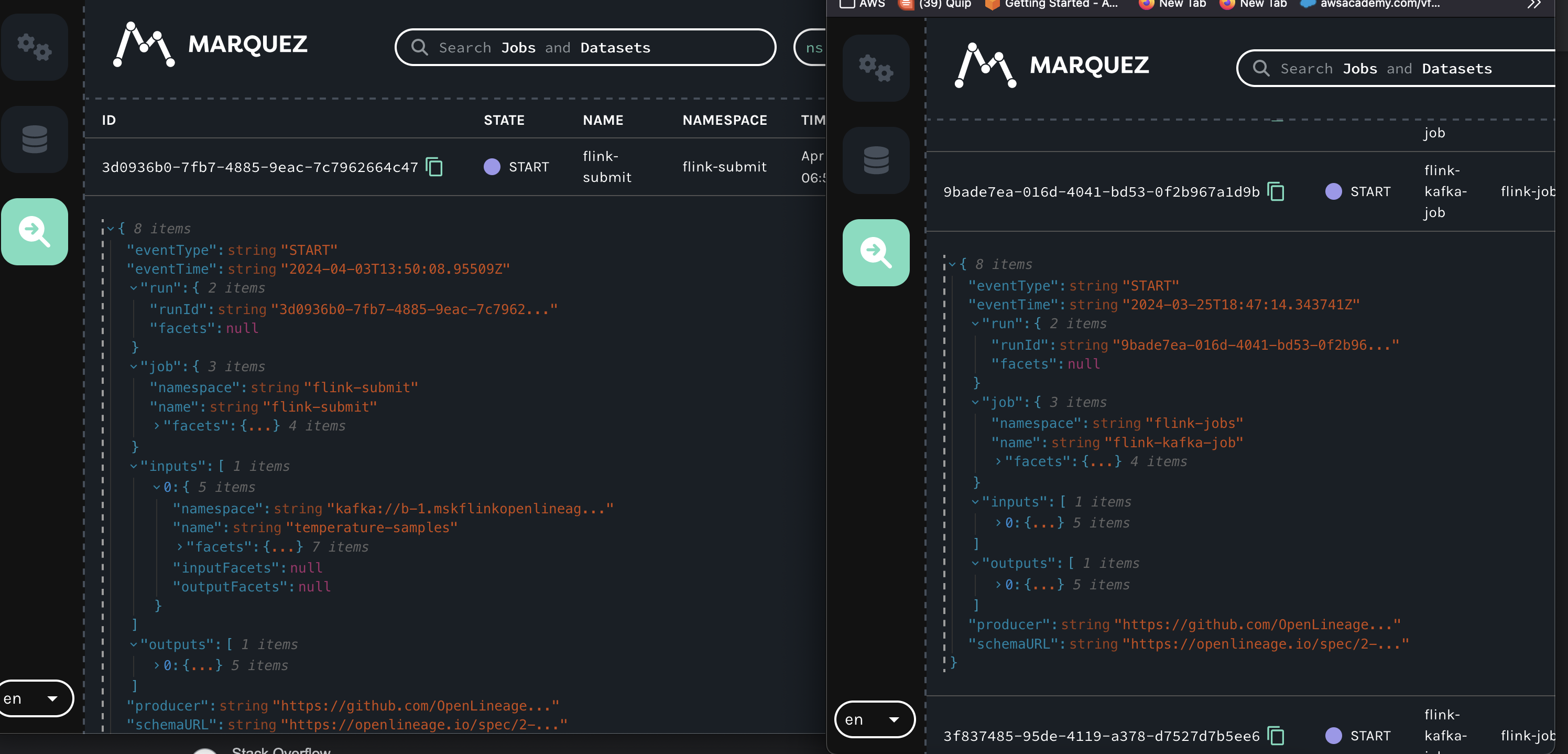 +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* @Maciej Obuchowski is there any other event needed for dag?
+ + + +
+
+
+ *Thread Reply:* > Could a workaround be, instead of having the http tranport, sending to kafka and have a java/python client writing the events to marquez?
+I think there are two problems, and the 400 is probably just the followup from the original one - maybe too long stacktrace makes Marquez reject the event?
+The original one, the attached one, is the cause why the integration tries to send the FAIL event at the first place
+
+
+ *Thread Reply:* For the error described in message "The Job Result cannot be fetched through the Job Client when in Web Submission.", I feel it is a bug in flink. Which version of flink are you using? @Francisco Morillo
+ + + +
+
+
+ *Thread Reply:* looking at implementation, it seems to be by design:
+/****
+ ** A {@link JobClient} that only allows asking for the job id of the job it is attached to.
+ **
+ ** <p>This is used in web submission, where we do not want the Web UI to have jobs blocking threads
+ ** while waiting for their completion.
+ **/
+
+
+ *Thread Reply:* Yes, looks like flink code try to fetch the Job Result for the web submission job, thus the exception is raised.
+ + + +
+
+
+ *Thread Reply:* Flink 1.15.2
+ + + +
+
+
+ *Thread Reply:* But still wouldnt marquez be able to build the dag with the start event?
+ + + +
+
+
+ *Thread Reply:* In Marquez, new dataset version is created when the run completes
+ + + +
+
+
+ *Thread Reply:* but that doesnt show as events in marquez right?
+ + + +
+
+
+ *Thread Reply:* I think that was going to be changed for streaming jobs - right @Paweł Leszczyński? - but not sure if that's already merged
+ + + +
+
+
+ *Thread Reply:* in latest marquez version?
+ + + +
+
+
+ *Thread Reply:* is this the right transport url? props.put("openlineage.transport.url","http://localhost:5000/api/v1/lineage");
+ + + +
+
+
+ *Thread Reply:* because i was able to see streaming jobs in marquez when running locally, as well as having a flink local job writing to the marquez on ec2. its as the dataset and job doesnt get created in marquez from the event
+ + + +
+
+
+ *Thread Reply:* I tried with flink 1.18 and same. i receive the start event but the job and dataset are not created in marquez
+ + + +
+
+
+ *Thread Reply:* If i try locally and set execution.attached to false it does work. So it seems that the main issue is that openlineage doesnt work with flink job submission through web ui
+ + + +
+
+
+ *Thread Reply:* From my understanding until now, set execution.attched = false mitigates the exception in flink (at least from the flink code, it is the logic). On the other hand, the question goes to when to build the dag when receive events. @Paweł Leszczyński From our org, we changed the default behavior. The flink listener will periodically send running events out. Once the lineage backend receive the running event, a new dag will be created.
+ + + +
+
+
+ *Thread Reply:* How can i configure that?
+ + + +
+
+
+ *Thread Reply:* To send periodical running event, some changes are needed in the open lineage flink lib. Let's wait for @Paweł Leszczyński for concrete plan. I am glad to create a PR for this.
+ + + +
+
+
+ *Thread Reply:* im still wondering why the dag was not created in marquez, unless there are some other events that open lineage sends for it to build the job and dataset that if submitted through webui it doesnt work. I will try to replicate in EMR
+ + + +
+
+
+ *Thread Reply:* Looking at marquez logs, im seeing this
+ +arquez.api.OpenLineageResource: Unexpected error while processing request
+! java.lang.IllegalArgumentException: namespace '<kafka://b-1.mskflinkopenlineage.fdz2z7.c22.kafka.us-east-1.amazonaws.com:9092>,b-3.mskflinkopenlineage.fdz2z7.c22.kafka.us-east-1.amazonaws.com:9092,b_2.mskflinkopenlineage.fdz2z7.c22.kafka.us_east_1.amazonaws.com:9092' must contain only letters (a-z, A-Z), numbers (0-9), underscores (_), at (@), plus (+), dashes (-), colons (:), equals (=), semicolons (;), slashes (/) or dots (.) with a maximum length of 1024 characters.
+
+
+ *Thread Reply:* can marquez work with msk?
+ + + +
+
+
+ *Thread Reply:* The graph on Marquez side should be present just after sending START event, once the START contains information about input/output datasets. Commas are the problem here and we should modify Flink integration to separate broker list by a semicolon.
+
+
+ Hi all, I've opened a PR for the dbt-ol script. We've noticed that the script doesn't transparently return/exit the exit code of the child dbt process. This makes it hard for the parent process to tell if the underlying workflow succeeded or failed - in the case of Airflow, the parent DAG will mark the job as succeeded even if it actually failed. Let me know if you have thought/comments (cc @Arnab Bhattacharyya)
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* @Sophie LY FYI
+ + + +
+
+
+ Is there a timeline for the 1.11.0 release? Now that the dbt-ol fix has been merged we may either wait for the release or temporarily point to main
+
+
+ *Thread Reply:* I think it’s going to be today or really soon. cc: @Michael Robinson
+ + + +
+
+
+ *Thread Reply:* would be great if we could fix the unknown facet memory issue in this release, I think @Paweł Leszczyński @Damien Hawes are working on it
+ + + +
+
+
+ *Thread Reply:* I think this is a critical kind of bug
+ + + +
+
+
+ *Thread Reply:* Yeah, it's a tough-to-figure-out-where-the-fix-should-be kind of bug.
+ + + +
+
+
+ *Thread Reply:* The solution is simple, at least in my mind. If spark_unknown is disabled, don't accumulate state.
+
+
+ *Thread Reply:* i think we should go first with unknown entry facet as it has bigger impact
+ + + +
+
+
+ *Thread Reply:* if there's no better fast idea, just disable that facet for now?
+ + + +
+
+
+ *Thread Reply:* It doesn't matter if the facet is disabled or not
+ + + +
+
+
+ *Thread Reply:* The UnknownEntryFacetListener still accumulates state
+
+
+ *Thread Reply:* @Damien Hawes will you be able to prepare this today/tomorrow?
+ + + +
+
+
+ *Thread Reply:* disable == comment/remove code related to it, together with UnknownEntryFacetListener 🙂
+
+
+ *Thread Reply:* I'm working on it today
+ + + +
+
+
+ *Thread Reply:* in this case 🙂
+ + + +
+
+
+ *Thread Reply:* You're proposing to rip the code out completely?
+ + + +
+
+
+ *Thread Reply:* at least for this release - I think it's better to release code without it and without memory bug, rather than having it bugged as it is
+ + + +
+
+
+ *Thread Reply:* The only place where I see it being applied is here:
+ +``` private <L extends LogicalPlan> QueryPlanVisitor<L, D> asQueryPlanVisitor(T event) { + AbstractQueryPlanDatasetBuilder<T, P, D> builder = this; + return new QueryPlanVisitor<L, D>(context) { + @Override + public boolean isDefinedAt(LogicalPlan x) { + return builder.isDefinedAt(event) && isDefinedAtLogicalPlan(x); + }
+ + @Override
+ public List<D> apply(LogicalPlan x) {
+ unknownEntryFacetListener.accept(x);
+ return builder.apply(event, (P) x);
+ }
+};
+}```
+ + + +
+
+
+ *Thread Reply:* come on, this should be few lines of change
+ + + +
+
+
+ *Thread Reply:* Inside: AbstractQueryPlanDatasetBuilder
+
+
+ *Thread Reply:* once we know what it is
+ + + +
+
+
+ *Thread Reply:* it's useful in some narrow debug cases, but the memory bug potentially impacts all
+ + + +
+
+
+ *Thread Reply:* openLineageContext
+ .getQueryExecution()
+ .filter(qe -> !FacetUtils.isFacetDisabled(openLineageContext, "spark_unknown"))
+ .flatMap(qe -> unknownEntryFacetListener.build(qe.optimizedPlan()))
+ .ifPresent(facet -> runFacetsBuilder.put("spark_unknown", facet));
+this should always clean the listener
+
+
+ *Thread Reply:* @Paweł Leszczyński - every time AbstractQueryPlanDatasetBuilder#apply is called, the UnknownEntryFacetListener is invoked
+
+
+ *Thread Reply:* the code is within OpenLineageRunEventBuilder
+
+
+ *Thread Reply:* @Paweł Leszczyński - it will only clean the listener, if spark_unknown is enabled
+
+
+ *Thread Reply:* because of that filter step
+ + + +
+
+
+ *Thread Reply:* but the listener still accumulates state, regardless of that snippet you shared
+ + + +
+
+
+ *Thread Reply:* yes, and we need to modify it to always clean
+ + + +
+
+
+ *Thread Reply:* We have a difference in understanding here, I think.
+ +spark_unknown is disabled, the UnknownEntryFacetListener still accumulates state. Your proposed change will not clean that state.spark_unknown is enabled, well, sometimes we get StackOverflow errors due to infinite recursion during serialisation.
+
+
+ *Thread Reply:* just to get a bit out from particular solution: I would love if we could either release with
+ +
+
+
+ *Thread Reply:* I think the impact of this bug is big
+ + + +
+
+
+ *Thread Reply:* My opinion is that perhaps the OpenLineageContext object needs to be extended to hold which facets are enabled / disabled.
+
+
+ *Thread Reply:* This way, things that inherit from AbstractQueryPlanDatasetBuilder can check, should they be a no-op or not
+
+
+ *Thread Reply:* Or, +```private <L extends LogicalPlan> QueryPlanVisitor<L, D> asQueryPlanVisitor(T event) { + AbstractQueryPlanDatasetBuilder<T, P, D> builder = this; + return new QueryPlanVisitor<L, D>(context) { + @Override + public boolean isDefinedAt(LogicalPlan x) { + return builder.isDefinedAt(event) && isDefinedAtLogicalPlan(x); + }
+ +@Override
+public List<D> apply(LogicalPlan x) {
+ unknownEntryFacetListener.accept(x);
+ return builder.apply(event, (P) x);
+}
+}; +}``` +This needs to be changed
+ + + +
+
+
+ *Thread Reply:* @Damien Hawes could u look at this again https://github.com/OpenLineage/OpenLineage/pull/2557/files ?
+ + + +
+
+
+ *Thread Reply:* i think clearing visitedNodes within populateRun should solve this
+
+
+ *Thread Reply:* the solution is (1) don't store logical plans, but their string representation (2) clear what you collected after populating a facet
+ + + +
+
+
+ *Thread Reply:* even if it works, I still don't really like it because we accumulate state in asQueryPlanVisitor just to clear it later
+
+
+ *Thread Reply:* It works, but I'm still annoyed that UnknownEntryFacetListener is being called in the first place
+
+
+ *Thread Reply:* also i think in case of really large plans it could be an issue still?
+ + + +
+
+
+ *Thread Reply:* why @Maciej Obuchowski?
+ + + +
+
+
+ *Thread Reply:* we've seen >20MB serialized logical plans, and that's what essentially treeString does if I understand it correctly
+
+
+ *Thread Reply:* and then the serialization can potentially still take some time...
+ + + +
+
+
+ *Thread Reply:* where did you find treeString serializes a plan?
+
+
+ *Thread Reply:* treeString is used by default toString method of TreeNode, so would be super weird if they serialized entire object within it. I couldn't find any of such code within Spark implementation
+
+
+ *Thread Reply:* I also remind you, that there is the problem with the job metrics holder as well
+ + + +
+
+
+ *Thread Reply:* That will also, eventually, cause an OOM crash
+ + + +
+
+
+ *Thread Reply:* So, I agreeUnknownEntryFacetListener code should not be called if a facet is disabled. I agree we should have another PR and fix for job metrics.
The question is: what do we want to have shipped within the next release? Do we want to get rid of static member that acumulates all the logical plans (which is cleaner approach) or just clear it once not needed anymore? I think we'll need to clear it anyway in case someone turns the unkown facet feature on.
+ + + +
+
+
+ *Thread Reply:* In my opinion, the approach for the immediate release is to clear the plans. Though, I'd like tests that prove it works.
+ + + +
+
+
+ *Thread Reply:* @Damien Hawes so let's go with Paweł's PR?
+ + + +
+
+
+ *Thread Reply:* So, prooving this helps would be great. One option would be to prepare integration test that runs something and verifies later on that private static map is empty. Another, a way nicer, would be to write a code that generates a few MB dataset reads into memory and saves into a file, and then within integration tests code runs something like https://github.com/jerolba/jmnemohistosyne to see memory consumption of classess we're interested in (not sure how difficult this is to write such thing)
+ +This could be also beneficial to prevent similar issues in future and solve job metrics issue.
+
+
+
+ *Thread Reply:* @Damien Hawes @Paweł Leszczyński would be great to clarify if you're working on it now
+ + + +
+
+
+ *Thread Reply:* as this blocks release
+ + + +
+
+
+ *Thread Reply:* fyi @Michael Robinson
+ + + +
+
+
+ *Thread Reply:* I can try to prove that the PR I propoposed brings improvement. However, if Damien wants to work on his approach targetting this release, I am happy to hand it over.
+ + + +
+
+
+ *Thread Reply:* I'm not working on it at the moment. I think Pawel's approach is fine for the time being.
+ + + +
+
+
+ *Thread Reply:* I'll focus on the JobMetricsHolder problem
+ + + +
+
+
+ *Thread Reply:* Side note: @Paweł Leszczyński @Maciej Obuchowski - are you able to give any guidance why the UnknownEntryFacetListener was implemented that way, as opposed to just examining the event in a stateless manner?
+
+
+ *Thread Reply:* OK. @Paweł Leszczyński @Maciej Obuchowski - I think I found the memory leak with JobMetricsHolder. If we receive an event like SparkListenerJobStart, but there isn't any dataset in it, it looks like we're storing the metrics, but we never get rid of them.
+
+
+
+
+
+ *Thread Reply:* > Side note: @Paweł Leszczyński @Maciej Obuchowski - are you able to give any guidance why the UnknownEntryFacetListener was implemented that way, as opposed to just examining the event in a stateless manner?
+It's one of the older parts of codebase, implemented mostly in 2021 by person no longer associated with the project... hard to tell to be honest 🙂
+
+
+ *Thread Reply:* but I think we have much more freedom to modify it, as it's not standarized or user facing feature
+ + + +
+
+
+ *Thread Reply:* to solve stageMetrics issue - should they always be a separate Map per job that's associated with jobId allowing it to be easily cleaned... but there's no jobId on SparkListenerTaskEnd
+
+
+ *Thread Reply:* Nah
+ + + +
+
+
+ *Thread Reply:* Actually
+ + + +
+
+
+ *Thread Reply:* Its simpler than that
+ + + +
+
+
+ *Thread Reply:* The bug is here:
+ +public void cleanUp(int jobId) {
+ Set<Integer> stages = jobStages.remove(jobId);
+ stages = stages == null ? Collections.emptySet() : stages;
+ stages.forEach(jobStages::remove);
+ }
+
+
+ *Thread Reply:* We remove from jobStages N + 1 times
+
+
+ *Thread Reply:* JobStages is supposed to carry a mapping from Job -> Stage
+
+
+ *Thread Reply:* and stageMetrics a mapping from Stage -> TaskMetrics
+
+
+ *Thread Reply:* ah yes
+ + + +
+
+
+ *Thread Reply:* Here, we remove the job from jobStages, and obtain the associated stages, and then we use those stages to remove from jobStages again
+ + + +
+
+
+ *Thread Reply:* It's a "huh?" moment
+ + + +
+
+
+ *Thread Reply:* The amount of logging I added, just to see this, was crazy
+ + + +
+
+
+ *Thread Reply:* public void cleanUp(int jobId) {
+ Set<Integer> stages = jobStages.remove(jobId);
+ stages = stages == null ? Collections.emptySet() : stages;
+ stages.forEach(stageMetrics::remove);
+ }
+so it's just jobStages -> stageMetrics here, right?
+
+
+ *Thread Reply:* Yup
+ + + +
+
+
+ *Thread Reply:* yeah it looks so obvious after seeing that 😄
+ + + +
+
+
+ *Thread Reply:* I even wrote a separate method to clear the stageMetrics map
+ + + +
+
+
+ *Thread Reply:* it was there since 2021 in that form 🙂
+ + + +
+
+
+ *Thread Reply:* and placed it in the same locations as the cleanUp method in the OpenLineageSparkListener
+ + + +
+
+
+ *Thread Reply:* Wrote a unit test
+ + + +
+
+
+ *Thread Reply:* It fails
+ + + +
+
+
+ *Thread Reply:* and I was like, "why?"
+ + + +
+
+
+ *Thread Reply:* Investigate further, and then I noticed this method
+ + + +
+
+
+ *Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/2565
+ + + +
+
+
+ *Thread Reply:* Has Damien's PR unblocked the release?
+ + + +
+
+
+ *Thread Reply:* No, we need one more from Paweł
+ + + +
+
+
+ *Thread Reply:* OK. Pawel's PR has been merged @Michael Robinson
+ + + +
+
+
+ *Thread Reply:* Given these developments, I'ld like to call for a release of 1.11.0 to happen today, unless there are any objections.
+ + + +
+
+
+ *Thread Reply:* Changelog PR is RFR: https://github.com/OpenLineage/OpenLineage/pull/2574
+ + + +
+
+
+ *Thread Reply:* CircleCI has problems
+ + + +
+
+
+ *Thread Reply:* ```self = <tests.conftest.DagsterRunLatestProvider object at 0x7fcd84faed60> +repositoryname = 'testrepo'
+ +def get_instance(self, repository_name: str) -> DagsterRun:
+> from dagster.core.remoterepresentation.origin import ( + ExternalJobOrigin, + ExternalRepositoryOrigin, + InProcessCodeLocationOrigin, + ) +E ImportError: cannot import name 'ExternalJobOrigin' from 'dagster.core.remoterepresentation.origin' (/home/circleci/.pyenv/versions/3.8.19/lib/python3.8/site-packages/dagster/core/remote_representation/origin.py)
+ +tests/conftest.py:140: ImportError```
+ + + +
+
+
+ *Thread Reply:* >>> from dagster.core.remote_representation.origin import (
+... ExternalJobOrigin,
+... ExternalRepositoryOrigin,
+... InProcessCodeLocationOrigin,
+... )
+Traceback (most recent call last):
+ File "<stdin>", line 1, in <module>
+ File "<frozen importlib._bootstrap>", line 1176, in _find_and_load
+ File "<frozen importlib._bootstrap>", line 1138, in _find_and_load_unlocked
+ File "<frozen importlib._bootstrap>", line 1078, in _find_spec
+ File "/home/blacklight/git_tree/OpenLineage/venv/lib/python3.11/site-packages/dagster/_module_alias_map.py", line 36, in find_spec
+ assert base_spec, f"Could not find module spec for {base_name}."
+AssertionError: Could not find module spec for dagster._core.remote_representation.
+>>> from dagster.core.host_representation.origin import (
+... ExternalJobOrigin,
+... ExternalRepositoryOrigin,
+... InProcessCodeLocationOrigin,
+... )
+>>> ExternalJobOrigin
+<class 'dagster._core.host_representation.origin.ExternalJobOrigin'>
+
+
+ *Thread Reply:* It seems that the parent module should be dagster.core.host_representation.origin, not dagster.core.remote_representation.origin
+
+
+ *Thread Reply:* did you rebase? for >=1.6.9 it’s dagster.core.remote_representation.origin, should be ok
+
+
+ *Thread Reply:* Indeed, I was just looking at https://github.com/dagster-io/dagster/pull/20323 (merged 4 weeks ago)
+
+ <a href="https://github.com/dagster-io/dagster">dagster-io/dagster</a>
+
+
+
+ *Thread Reply:* I did a pip install of the integration from main and it seems to install a previous version though:
>>> dagster.__version__
+'1.6.5'
+
+
+ *Thread Reply:* try --force-reinstall maybe
+ + + +
+
+
+ *Thread Reply:* it works fine for me, CI doesn’t crash either
+ + + +
+
+
+ *Thread Reply:* https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/10020/workflows/4d3a33b4-47ef-4cf6-b6de-1bb95611fad7/jobs/200011 (although the ImportError seems to be different from mine)
+
+
+ *Thread Reply:* huh, how didn’t I see this
+ + + +
+
+
+ *Thread Reply:* I think we should limit upper version of dagster, it’s not even really maintained
+ + + +
+
+
+ *Thread Reply:* I've also just noticed that ExternalJobOrigin and ExternalRepositoryOrigin have been renamed to RemoteJobOrigin and RemoteRepositoryOrigin on 1.7.0 - and that's apparently the version the CI installed
+
+
+ *Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/2579
+ + + + +
+
+
+
+
+ Hey 👋
+When I am running TrinoOperator on Airflow 2.7 I am getting this:
+[2024-04-03, 11:10:44 UTC] {base.py:162} WARNING - OpenLineage provider method failed to extract data from provider.
+[2024-04-03, 11:10:44 UTC] {manager.py:276} WARNING - Extractor returns non-valid metadata: None
+I've upgraded apache-airflow-providers-openlineage to 1.6.0 (maybe it is too new for Airflow 2.7 version?).
+And due to the warning I am ending with empty input/output facets... Seems that it is not capable to connect to Trino and extract table structure... When I tried on our prod Airflow version (2.6.3) and openlineage-airflow it was capable to connect and extract table structure, but not to do the column level lineage mapping.
Any input would be very helpful. +Thanks
+ + + +
+
+
+ *Thread Reply:* Tried with default version of OL plugin that comes with 2.7 Airflow (1.0.1) so result was the same
+ + + +
+
+
+ *Thread Reply:* Could you please enable DEBUG logs in Airflow and provide them?
+ + + +
+
+
+ *Thread Reply:*
+ +
+
+
+ *Thread Reply:* thanks +it seems like only the beginning of the logs. I’m assuming it fails on complete event
+ + + +
+
+
+ *Thread Reply:* I am sorry! This is the full log
+ +
+
+
+ *Thread Reply:* What I also just realised that we have our own TrinoOperator implementation, which inherits from SQLExecuteQueryOperator (same as original TrinoOperator)... So maybe inlets and outlets aren't being set due to that
+ + + +
+
+
+ *Thread Reply:* yeah, it could interfere
+ + + +
+
+
+ *Thread Reply:* But task was rather simple:
+create_table_apps_log_test = TrinoOperator(
+ task_id=f"create_table_test",
+ sql="""
+ CREATE TABLE if not exists mytable as
+ SELECT app_id, msid, instance_id from table limit 1
+ """
+)
+
+
+ *Thread Reply:* do you use some other hook to connect to Trino?
+ + + +
+
+
+ *Thread Reply:* Just checked. So we have our own hook to connect to Trino... that inherits from TrinoHook 🙄
+ + + +
+
+
+ *Thread Reply:* hard to say, you could check https://github.com/apache/airflow/blob/main/airflow/providers/trino/hooks/trino.py#L252 to see how integration collects basic information how to retrieve connection
+ + + +
+
+
+ *Thread Reply:* Just thinking why did it worked with Airflow 2.6.3 and openlineage-airflow package, seems that it was accessing Trino differently
+
+
+ *Thread Reply:* But anyways, will try to look more into it. Thanks for tips!
+ + + +
+
+
+ *Thread Reply:* please let me know your findings, it might be some bug introduced in provider package
+ + + +
+
+
+ Looking for some help with spark and the “UNCLASSIFIED_ERROR; An error occurred while calling o110.load. Cannot call methods on a stopped SparkContext.” We are not getting any openLineage data in Cloudwatch nor in sparkHistoryLogs. +(more details in thread - should I be making this into a github issue instead?)
+ + + +
+
+
+ *Thread Reply:* The python code:
import sys
+from awsglue.transforms import **
+from awsglue.utils import getResolvedOptions
+from pyspark.context import SparkContext
+from pyspark.conf import SparkConf
+from awsglue.context import GlueContext
+from awsglue.job import Job
conf = SparkConf()
+conf.set("spark.extraListeners","io.openlineage.spark.agent.OpenLineageSparkListener")\
+ .set("spark.jars.packages","io.openlineage:openlineage_spark:1.10.2")\
+ .set("spark.openlineage.version","v1")\
+ .set("spark.openlineage.namespace","OL_EXAMPLE_DN")\
+ .set("spark.openlineage.transport.type","console")
+## @params: [JOB_NAME]
+args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext.getOrCreate(conf=conf)
+glueContext = GlueContext(sc)
+spark = glueContext.spark_session
+job = Job(glueContext)
+job.init(args['JOB_NAME'], args)
+df = spark.read.format("csv").option("header","true").load("<s3-folder-path>")
+df.write.format("csv").option("header","true").save("<s3-folder-path>",mode='overwrite')
+job.commit()
+
+
+ *Thread Reply:* Nothing appears in cloudwatch, or in the sparkHistoryLogs. Here's the jr_runid file from sparkHistoryLogs - it shows that the work was done, but nothing about openlineage or where the spark session was stopped before OL could do anything:
+{
+ "Event": "SparkListenerApplicationStart",
+ "App Name": "nativespark-check_python_-jr_<jrid>",
+ "App ID": "spark-application-0",
+ "Timestamp": 0,
+ "User": "spark"
+}
+{
+ "Event": "org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart",
+ "executionId": 0,
+ "description": "load at NativeMethodAccessorImpl.java:0",
+ "details": "org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:185)\nsun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\nsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\nsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\njava.lang.reflect.Method.invoke(Method.java:498)\npy4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)\npy4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)\npy4j.Gateway.invoke(Gateway.java:282)\npy4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)\npy4j.commands.CallCommand.execute(CallCommand.java:79)\npy4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)\npy4j.ClientServerConnection.run(ClientServerConnection.java:106)\njava.lang.Thread.run(Thread.java:750)",
+ "physicalPlanDescription": "== Parsed Logical Plan ==\nGlobalLimit 1\n+- LocalLimit 1\n +- Filter (length(trim(value#7, None)) > 0)\n +- Project [value#0 AS value#7]\n +- Project [value#0]\n +- Relation [value#0] text\n\n== Analyzed Logical Plan ==\nvalue: string\nGlobalLimit 1\n+- LocalLimit 1\n +- Filter (length(trim(value#7, None)) > 0)\n +- Project [value#0 AS value#7]\n +- Project [value#0]\n +- Relation [value#0] text\n\n== Optimized Logical Plan ==\nGlobalLimit 1\n+- LocalLimit 1\n +- Filter (length(trim(value#0, None)) > 0)\n +- Relation [value#0] text\n\n== Physical Plan ==\nCollectLimit 1\n+- **(1) Filter (length(trim(value#0, None)) > 0)\n +- FileScan text [value#0] Batched: false, DataFilters: [(length(trim(value#0, None)) > 0)], Format: Text, Location: InMemoryFileIndex(1 paths)[<s3-csv-file>], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<value:string>\n",
+ "sparkPlanInfo": {
+ "nodeName": "CollectLimit",
+ "simpleString": "CollectLimit 1",
+ "children": [
+ {
+ "nodeName": "WholeStageCodegen (1)",
+ "simpleString": "WholeStageCodegen (1)",
+ "children": [
+ {
+ "nodeName": "Filter",
+ "simpleString": "Filter (length(trim(value#0, None)) > 0)",
+ "children": [
+ {
+ "nodeName": "InputAdapter",
+ "simpleString": "InputAdapter",
+ "children": [
+ {
+ "nodeName": "Scan text ",
+ "simpleString": "FileScan text [value#0] Batched: false, DataFilters: [(length(trim(value#0, None)) > 0)], Format: Text, Location: InMemoryFileIndex(1 paths)[<s3-csv-file>], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<value:string>",
+ "children": [],
+ "metadata": {
+ "Location": "InMemoryFileIndex(1 paths)[<s3-csv-file>]",
+ "ReadSchema": "struct<value:string>",
+ "Format": "Text",
+ "Batched": "false",
+ "PartitionFilters": "[]",
+ "PushedFilters": "[]",
+ "DataFilters": "[(length(trim(value#0, None)) > 0)]"
+ },
+ "metrics": [
+ {
+ "name": "number of output rows from cache",
+ "accumulatorId": 14,
+ "metricType": "sum"
+ },
+ {
+ "name": "number of files read",
+ "accumulatorId": 15,
+ "metricType": "sum"
+ },
+ {
+ "name": "metadata time",
+ "accumulatorId": 16,
+ "metricType": "timing"
+ },
+ {
+ "name": "size of files read",
+ "accumulatorId": 17,
+ "metricType": "size"
+ },
+ {
+ "name": "max size of file split",
+ "accumulatorId": 18,
+ "metricType": "size"
+ },
+ {
+ "name": "number of output rows",
+ "accumulatorId": 13,
+ "metricType": "sum"
+ }
+ ]
+ }
+ ],
+ "metadata": {},
+ "metrics": []
+ }
+ ],
+ "metadata": {},
+ "metrics": [
+ {
+ "name": "number of output rows",
+ "accumulatorId": 12,
+ "metricType": "sum"
+ }
+ ]
+ }
+ ],
+ "metadata": {},
+ "metrics": [
+ {
+ "name": "duration",
+ "accumulatorId": 11,
+ "metricType": "timing"
+ }
+ ]
+ }
+ ],
+ "metadata": {},
+ "metrics": [
+ {
+ "name": "shuffle records written",
+ "accumulatorId": 9,
+ "metricType": "sum"
+ },
+ {
+ "name": "shuffle write time",
+ "accumulatorId": 10,
+ "metricType": "nsTiming"
+ },
+ {
+ "name": "records read",
+ "accumulatorId": 7,
+ "metricType": "sum"
+ },
+ {
+ "name": "local bytes read",
+ "accumulatorId": 5,
+ "metricType": "size"
+ },
+ {
+ "name": "fetch wait time",
+ "accumulatorId": 6,
+ "metricType": "timing"
+ },
+ {
+ "name": "remote bytes read",
+ "accumulatorId": 3,
+ "metricType": "size"
+ },
+ {
+ "name": "local blocks read",
+ "accumulatorId": 2,
+ "metricType": "sum"
+ },
+ {
+ "name": "remote blocks read",
+ "accumulatorId": 1,
+ "metricType": "sum"
+ },
+ {
+ "name": "remote bytes read to disk",
+ "accumulatorId": 4,
+ "metricType": "size"
+ },
+ {
+ "name": "shuffle bytes written",
+ "accumulatorId": 8,
+ "metricType": "size"
+ }
+ ]
+ },
+ "time": 0,
+ "modifiedConfigs": {}
+}
+{
+ "Event": "SparkListenerApplicationEnd",
+ "Timestamp": 0
+}
+
+
+ *Thread Reply:* I think this is related to job.commit() that probably stops context underneath
+
+
+ *Thread Reply:* This is probably the same bug: https://github.com/OpenLineage/OpenLineage/issues/2513 but manifests differently
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* can you try without the job.commit()?
+ + + +
+
+
+ *Thread Reply:* Sure!
+ + + +
+
+
+ *Thread Reply:* BTW it makes sense that if the spark listener is disabled, that the openlineage integration shouldn’t even try. (If we removed that line, it doesn’t feel like the integration would actually work….)
+ + + +
+
+
+ *Thread Reply:* you mean removing this?
+conf.set("spark.extraListeners","io.openlineage.spark.agent.OpenLineageSparkListener")\
+if you don't set it, none of our code is actually being loaded
+
+
+ *Thread Reply:* i meant, removing the job.init and job.commit for testing purposes. glue should work without that,
+ + + +
+
+
+ *Thread Reply:* We removed job.commit, same error. Should we also remove job.init?
+ + + +
+
+
+ *Thread Reply:* Won’t removing this change the functionality? +job.init(args[‘JOB_NAME’], args)
+ + + +
+
+
+ *Thread Reply:* interesting - maybe something else stops the job explicitely underneath on Glue?
+ + + +
+
+
+ *Thread Reply:* Will have a look.
+ + + + +
+
+
+
+
+ *Thread Reply:* Hi all, +I'm working with Sheeri on this, so couple of queries,
+ +tried to set("spark.openlineage.transport.location","
+2.set("spark.openlineage.transport.type","console") the job fails with “UNCLASSIFIED_ERROR; An error occurred while calling o110.load. Cannot call methods on a stopped SparkContext.”
if we are using http as transport.type, then can we use basic auth instead of api_key?
+
+
+ *Thread Reply:* > 3. if we are using http as transport.type, then can we use basic auth instead of api_key? +Would be good to add that to HttpTransport 🙂
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* > 1. tried to set("spark.openlineage.transport.location","<
+Yeah, FileTransport does not work with object storage - it needs to be regular filesystem. I don't know if we can make it work without pulling a lot of dependencies and making it significantly more complex - but of course we'd like to see such contribution
+
+
+ *Thread Reply:* @DEEVITH NAGRAJ yes, that’s why the PoC is to have the sparklineage use the transport type of “console” - we can’t save to files in S3.
+ + + +
+
+
+ *Thread Reply:* @DEEVITH NAGRAJ if we can get it to work in console, and CloudWatch shows us openlineage data, then we can change the transport type to an API and set up fluentd to collect the data.
+ +BTW yesterday another customer got it working in console, and Roderigo from this thread also saw it working in console, so we know it does work in general 😄
+ + + +
+
+
+ *Thread Reply:* yes Sheeri, I agree we need to get it to work in the console.I dont see anything in the cloudwatch, and the error is thrown when tried to set("spark.openlineage.transport.type","console") the job fails with “UNCLASSIFIED_ERROR; An error occurred while calling o110.load. Cannot call methods on a stopped SparkContext.”
+ +do we need to specify scala version in .set("spark.jars.packages","io.openlineage:openlineagespark:1.10.2") like .set("spark.jars.packages","io.openlineage:openlineagespark_2.13:1.10.2")? is that causing the issue?
+ + + +
+
+
+ *Thread Reply:* Awesome! We’ve got it so the job succeeds when we set the transport type to “console”. Anyone have any tips on where to find it in CloudWatch? the job itself has a dozen or so different logs and we’re clicking all of them, but maybe there’s an easier way?
+ + + + +
+
+
+
+
+ Hi everyone, I've started 2 weeks ago to implement openLineage in our solution. But I've run into some problems and quite frankly I don't understand what I'm doing wrong.
+The situation is, we are using Azure Synapse with notebooks and we want to pick up the data lineage. I have found a lot of documentation about databricks in combination with Openlineage. But there is not much documentation with Synapse in combination with Openlineage. I've installed the newest library "openlineage-1.10.2" in the Synapse Apache Spark packages (so far so good). The next step I did was to configure the Apache Spark configuration, based on a blog I’ve found I filled in the following properties:
+spark.extraListeners - io.openlineage.spark.agent.OpenLineageSparkListener
+spark.openlineage.host – <https://functionapp.azurewebsites.net/api/function>
+spark.openlineage.namespace – synapse name
+spark.openlineage.url.param.code – XXXX
+spark.openlineage.version – 1
I’m not sure if the namespace is good, I think it's the name of synapse? But the moment I want to run the Synapse notebook (creating a simple dataframe) it shows me an error
+ +Py4JJavaError Traceback (most recent call last) Cell In [5], line 1 ----> 1 df = spark.read.load('<abfss://bronsedomein1@xxxxxxxx.dfs.core.windows.net/adventureworks/vendors.parquet>', format='parquet') **2** display(df)
+Py4JJavaError: An error occurred while calling o4060.load.
+: org.apache.spark.SparkException: Job aborted due to stage failure: Task serialization failed: java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext.
I can’t figure out what I’m doing wrong, does somebody have a clue?
+ +Thanks, +Mark
+ + + +
+
+
+ *Thread Reply:* this error seems unrelated to openlineage to me, can you try removing all the openlineage related properties from the config and testing this out just to rule that out?
+ + + +
+
+
+ *Thread Reply:* Hey Harel,
+ + + +
+
+
+ *Thread Reply:* Yes I removed all the related openlineage properties. And (ofcourse 😉 ) it's working fine. But the moment I fill in the Properties as mentiond above, it gives me the error.
+ + + +
+
+
+ *Thread Reply:* thanks for checking, wanted to make sure. 🙂
+ + + +
+
+
+ *Thread Reply:* can you try only setting
+spark.extraListeners = io.openlineage.spark.agent.OpenLineageSparkListener
+spark.jars.packages = io.openlineage:openlineage_spark_2.12:1.10.2
+spark.openlineage.transport.type = console
+?
+
+
+ *Thread Reply:* @Mark de Groot are you stopping the job using spark.stop() or similar command?
+
+
+
+
+
+
+
+
+ @channel + Accenture+Confluent's Open Standards for Data Lineage roundtable is happening on April 25th, featuring: +• Kai Waehner (Confluent) +• @Mandy Chessell (Egeria) +• @Julien Le Dem (OpenLineage) +• @Jens Pfau (Google Cloud) +• @Ernie Ostic (Manta/IBM) +• @Sheeri Cabral (Collibra) +• Austin Kronz (Atlan) +• @Luigi Scorzato (moderator, Accenture) +Not to be missed! Register at the link.
+
+
+
+
+  +
+
+
+
+
+ Hi everyone, +I'm trying to launch a spark job with integration with openlineage. The version of spark is 3.5.0. +The configuration used:
+ +spark.jars.packages=io.openlineage:openlineage-spark_2.12:1.10.2 +spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener +spark.openlineage.transport.url=http://marquez.dcp.svc.cluster.local:8087 +spark.openlineage.namespace=pyspark +spark.openlineage.transport.type=http +spark.openlineage.facets.disabled="[spark.logicalPlan;]" +spark.openlineage.debugFacet=enabled
+ +the spark job exits with the following error: +java.lang.NoSuchMethodError: 'org.apache.spark.sql.SQLContext org.apache.spark.sql.execution.SparkPlan.sqlContext()' + at io.openlineage.spark.agent.lifecycle.ContextFactory.createSparkSQLExecutionContext(ContextFactory.java:32) + at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$getSparkSQLExecutionContext$4(OpenLineageSparkListener.java:172) + at java.base/java.util.HashMap.computeIfAbsent(HashMap.java:1220) + at java.base/java.util.Collections$SynchronizedMap.computeIfAbsent(Collections.java:2760) + at io.openlineage.spark.agent.OpenLineageSparkListener.getSparkSQLExecutionContext(OpenLineageSparkListener.java:171) + at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:125) + at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:117) + at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:100) + at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) + at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) + at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) + at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) + at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) + at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) + at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) + at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) + at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) + at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) + at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) + at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1356) + at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96) +24/04/03 13:23:39 INFO SparkContext: SparkContext is stopping with exitCode 0. +24/04/03 13:23:39 ERROR Utils: throw uncaught fatal error in thread spark-listener-group-shared +java.lang.NoSuchMethodError: 'org.apache.spark.sql.SQLContext org.apache.spark.sql.execution.SparkPlan.sqlContext()' + at io.openlineage.spark.agent.lifecycle.ContextFactory.createSparkSQLExecutionContext(ContextFactory.java:32) + at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$getSparkSQLExecutionContext$4(OpenLineageSparkListener.java:172) + at java.base/java.util.HashMap.computeIfAbsent(HashMap.java:1220) + at java.base/java.util.Collections$SynchronizedMap.computeIfAbsent(Collections.java:2760) + at io.openlineage.spark.agent.OpenLineageSparkListener.getSparkSQLExecutionContext(OpenLineageSparkListener.java:171) + at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:125) + at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:117) + at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:100) + at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) + at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) + at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) + at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) + at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) + at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) + at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) + at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) + at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) + at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) + at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) + at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1356) + at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96) +Exception in thread "spark-listener-group-shared" java.lang.NoSuchMethodError: 'org.apache.spark.sql.SQLContext org.apache.spark.sql.execution.SparkPlan.sqlContext()' + at io.openlineage.spark.agent.lifecycle.ContextFactory.createSparkSQLExecutionContext(ContextFactory.java:32) + at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$getSparkSQLExecutionContext$4(OpenLineageSparkListener.java:172) + at java.base/java.util.HashMap.computeIfAbsent(HashMap.java:1220) + at java.base/java.util.Collections$SynchronizedMap.computeIfAbsent(Collections.java:2760) + at io.openlineage.spark.agent.OpenLineageSparkListener.getSparkSQLExecutionContext(OpenLineageSparkListener.java:171) + at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:125) + at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:117) + at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:100) + at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) + at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) + at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) + at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) + at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) + at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) + at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) + at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) + at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) + at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) + at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) + at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1356)
+ + + +
+
+
+ *Thread Reply:* Hey @Bassim EL Baroudi, what environnment are you running the Spark job? Is this some real-life production job or are you able to provide a code snippet which reproduces it?
+ + + +
+
+
+ *Thread Reply:* Do you get any OpenLineage events like START events and see this exception at the end of job or does it occur at the begining resulting in no events emitted?
+
+
+ @channel +This month’s TSC meeting is next Wednesday the 10th at 9:30am PT. +On the tentative agenda (additional items TBA): +• announcements + ◦ upcoming events including the Accenture+Confluent roundtable on 4/25 +• recent release highlights +• discussion items + ◦ supporting job-to-job, as opposed to job-dataset-job, dependencies in the spec + ◦ improving naming +• open discussion +More info and the meeting link can be found on the website. All are welcome! Do you have a discussion topic, use case or integration you’d like to demo? Reply here or DM me to be added to the agenda.
+
+
+
+ Hi! How can i pass multiple kafka brokers when using with Flink? It appears marquez doesnt allow to have namespaces with commas.
+ +namespace '
+
+
+ *Thread Reply:* Kafka dataset naming already has an open issue -> https://github.com/OpenLineage/OpenLineage/issues/560
+ +I think the problem you raised deserves a separate one. Feel free to create it. I. think we can still modify broker separator to semicolon.
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ FYI I've moved https://github.com/OpenLineage/OpenLineage/pull/2489 to https://github.com/OpenLineage/OpenLineage/pull/2578 - I mistakenly included a couple of merge commits upon git rebase --signoff. Hopefully the tests should pass now (there were a couple of macro templates that still reported the old arguments). Is it still in time to be squeezed inside 1.11.0? It's not super-crucial (for us at least), since we already have copied the code of those macros in our operators implementation, but since the same fix has already been merged on the Airflow side it'd be good to keep things in sync (cc @Maciej Obuchowski @Kacper Muda)
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* The tests are passing now
+ + + +
+
+
+ I wanted to ask if there are any roadmap to adding more support for flink sources and sinks to openlineage for example: +• Kinesis +• Hudi +• Iceberg SQL +• Flink CDC +• Opensearch +or how one can contribute to those?
+ + + +
+
+
+ *Thread Reply:* Hey, if you feel like contributing, take a look at our contributors guide 🙂
+ + + +
+
+
+ *Thread Reply:* I think most important think on Flink side is working with Flink community on implementing https://cwiki.apache.org/confluence/display/FLINK/FLIP-314%3A+Support+Customized+Job+Lineage+Listener - as this allows us to move the implementation to the dedicated connectors
+ + + + +
+
+
+
+
+ 👋 Hi everyone!
+ + + +
+
+
+ *Thread Reply:* Hello 👋
+ + + +
+
+
+ @channel
+We released OpenLineage 1.11.3, featuring a new package to support built-in lineage in Spark extensions and a telemetry mechanism in the Spark integration, among many other additions and fixes.
+Additions
+• Common: add support for SCRIPT-type jobs in BigQuery #2564 @kacpermuda
+• Spark: support for built-in lineage extraction #2272 @pawel-big-lebowski
+• Spark/Java: add support for Micrometer metrics #2496 @mobuchowski
+• Spark: add support for telemetry mechanism #2528 @mobuchowski
+• Spark: support query option on table read #2556 @mobuchowski
+• Spark: change SparkPropertyFacetBuilder to support recording Spark runtime #2523 @Ruihua98
+• Spec: add fileCount to dataset stat facets #2562 @dolfinus
+There were also many bug fixes -- please see the release notes for details.
+Thanks to all the contributors with a shout out to new contributor @dolfinus (who contributed 5 PRs to the release and already has 4 more open!) and @Maciej Obuchowski and @Jakub Dardziński for the after-hours CI fixes!
+Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.11.3
+Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
+Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.10.2...1.11.3
+Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage|https://oss.sonatype.org/#nexus-search;quick~openlineage
+PyPI: https://pypi.org/project/openlineage-python/
 +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* This is Taosheng from GitData Labs (https://gitdata.ai/) and We are building data versioning tool for responsible AL/ML:
+ +An Git-like version control file system for data lineage & data collaboration. +https://github.com/GitDataAI/jiaozifs
+
+
+
+ *Thread Reply:* hello 👋
+ + + +
+
+
+ *Thread Reply:* I came across OpenLineage on Google I would be able to contribute with our products & skills. I Was thinking maybe could start sharing some of them here, and seeing if there is something that feels like it could be interesting to co-build on/through OpenLineage and co-market together.
+ + + +
+
+
+ *Thread Reply:* Would somebody be open to discuss any open opportunities for us together?
+ + + +
+
+
+ *Thread Reply:* 👋 welcome and thanks for joining!
+ + + +
+
+
+ Hi Everyone ! Wanted to implement a cross stack data lineage across Flink and Spark but it seems that Iceberg Table gets registered asdifferent datasets in both. Spark at the top Flink at the bottom. so it doesnt get added to the same DAG. In Spark, Iceberg Table gets Database added in the name. Im seeing that @Paweł Leszczyński commited Spark/Flink Unify Dataset naming from URI objects (https://github.com/OpenLineage/OpenLineage/pull/2083/files#). So not sure what could be going on
+ + +
+
+
+
+
+
+
+ 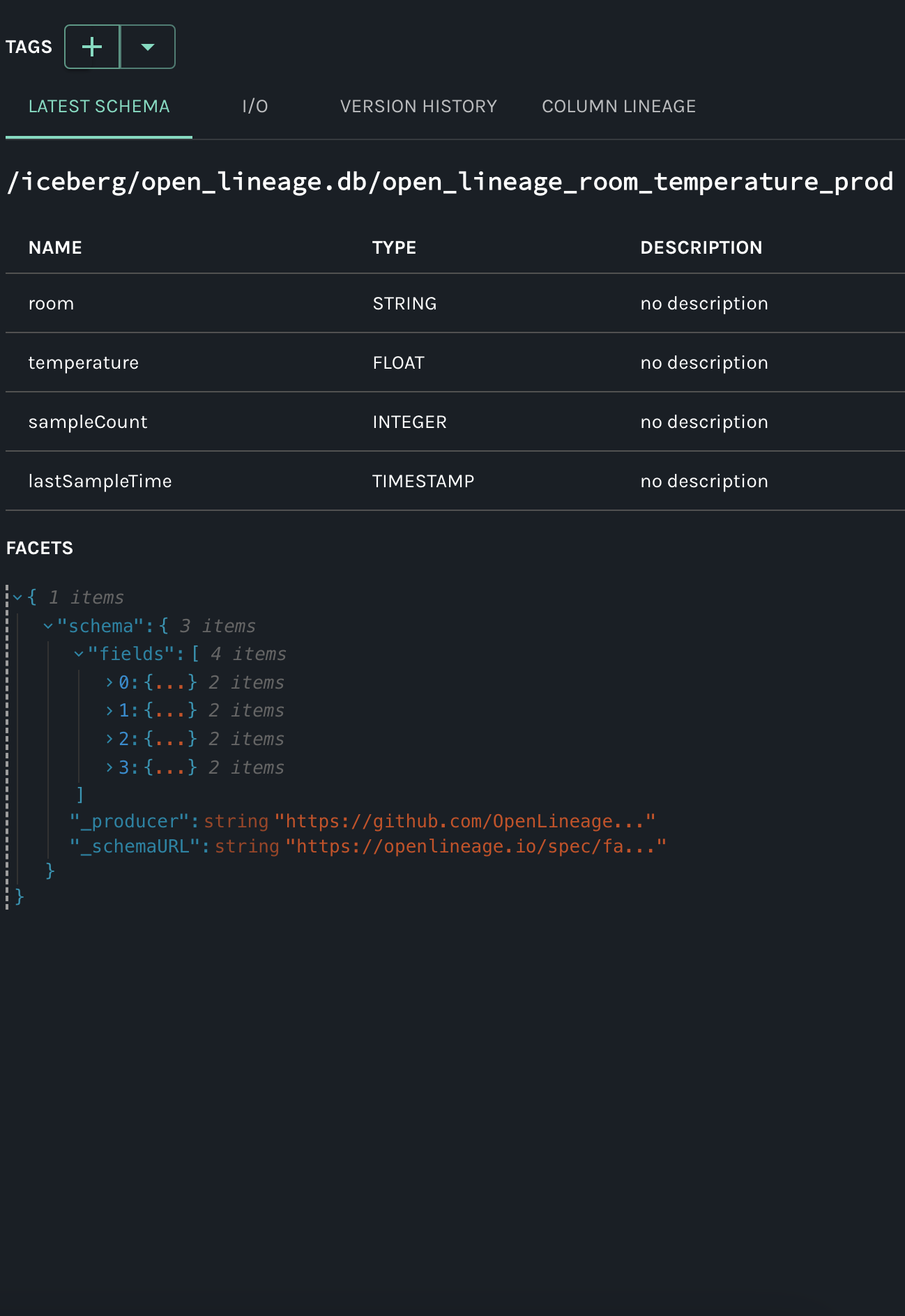 +
+
+
+
+
+
+
+ 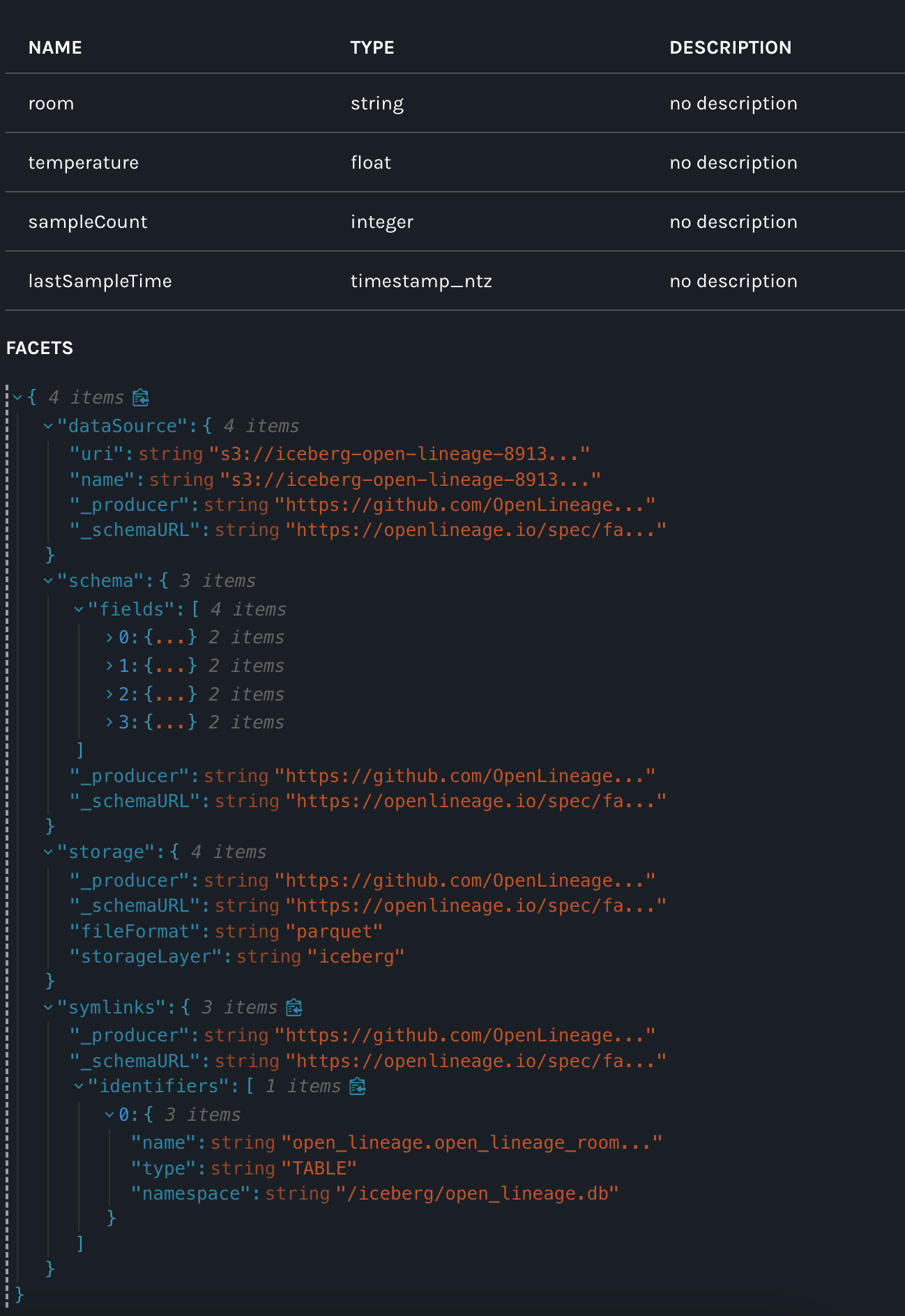 +
+
+
+
+
+
+
+
+
+
+
+
+
+ *Thread Reply:* Looks like this method https://github.com/OpenLineage/OpenLineage/blob/1.11.3/integration/spark/shared/src/main/java/io/openlineage/spark/agent/util/PathUtils.java#L164 creates name with (tb+database)
+ +In general, I would say we should add naming convention here -> https://openlineage.io/docs/spec/naming/ . I think db.table format is fine as we're using it for other sources.
IcebergSinkVisitor in Flink integration is does not seem to add symlink facet pointing to iceberg table with schema included. You can try extending it with dataset symlink facet as done for Spark.
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* How do you suggest we do so? creating a PR, extending IcebergSink Visitor or do it manually through spark as in this example https://github.com/OpenLineage/workshops/blob/main/spark/dataset_symlinks.ipynb
+
+ <a href="https://github.com/OpenLineage/workshops">OpenLineage/workshops</a>
+
+
+
+ *Thread Reply:* is there any way to create a symlink via marquez api?
+ + + +
+
+
+ *Thread Reply:* trying to figure out whats the easiest approach
+ + + +
+
+
+ *Thread Reply:* there are two possible conventions for pointing to iceberg dataset:
+• its physical location
+• namespace pointing to iceberg catalog, name pointing to schema+table
+Flink integration uses physical location only. IcebergSinkVisitor should add additional facet - dataset symlink facet
+
+
+ *Thread Reply:* just like spark integration is doing +here -> https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/main/java/io/openlineage/spark/agent/util/PathUtils.java#L86
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* I have been testing in modifying first the event that gets emitted, but in the lineage i am seeing duplicate datasets. As the physical location for flink is also different than the one spark uses
diff --git a/channel/github-discussions/index.html b/channel/github-discussions/index.html deleted file mode 100644 index 874f225..0000000 --- a/channel/github-discussions/index.html +++ /dev/null @@ -1,5997 +0,0 @@ - - - - - -
-
-
- @Julien Le Dem has joined the channel
- - - -
-
-
- /github subscribe OpenLineage/OpenLineage discussions
- - - -
-
-
- /github subscribe OpenLineage/OpenLineage discussions
- - - -✅ Subscribed to OpenLineage/OpenLineage. This channel will receive notifications for issues, pulls, commits, releases, deployments, discussions
-
-
- @Michael Robinson has joined the channel
- - - - -
-
-
-
-
- @Mike Dillion has joined the channel
- - - - -
-
-
-
-
- @jrich has joined the channel
- - - - -
-
-
-
-
- @Dev Jadhav has joined the channel
- - - - -
-
-
-
-
- @Sudhar Balaji has joined the channel
- - - - -
-
-
-
-
- @Yuanli Wang has joined the channel
- - - - -
-
-
-
-
- @Nam Nguyen has joined the channel
- - - - -
-
-
-
-
- @Glyn Bowden (HPE) has joined the channel
- - - - -
-
-
-
-
- @GTC has joined the channel
- - - -
-
-
- @Sheeri Cabral (Collibra) has joined the channel
- - - -
-
-
- Let me know if I did that wrong ^^^ It’s been a while since I modified someone else’s PR with my own commits.
- - - -
-
-
- @Harel Shein has joined the channel
- - - - -
-
-
-
-
- @Gowthaman Chinnathambi has joined the channel
- - - - -
-
-
-
-
- @jayant joshi has joined the channel
- - - -
-
-
- @tati has joined the channel
- - - - -
-
-
-
-
- @Ewan Lord has joined the channel
- - - - -
-
-
-
-
- @Josh Fischer has joined the channel
- - - - -
-
-
-
-
- @assia fellague has joined the channel
- - - -
-
-
- @Julien Le Dem has joined the channel
- - - - -
-
-
-
-
- @Jørn Hansen has joined the channel
- - - - -
-
-
-
-
- @Ananth Packkildurai has joined the channel
- - - - -
-
-
-
-
- @Harikiran Nayak has joined the channel
- - - -
-
-
- @Willy Lulciuc has joined the channel
- - - - -
-
-
-
-
- @Alagappan Sethuraman has joined the channel
- - - - -
-
-
-
-
- @Laurent Paris has joined the channel
- - - - -
-
-
-
-
- @dorzey has joined the channel
- - - - -
-
-
-
-
- @Alexander Gilfillan has joined the channel
- - - - -
-
-
-
-
- @Girish Lingappa has joined the channel
- - - - -
-
-
-
-
- @Edgar Ramírez Mondragón has joined the channel
- - - - -
-
-
-
-
- @Xinbin Huang has joined the channel
- - - - -
-
-
-
-
- @aliou has joined the channel
- - - - -
-
-
-
-
- @Arthur Wiedmer has joined the channel
- - - - -
-
-
-
-
- @Victor Shafran has joined the channel
- - - - -
-
-
-
-
- @Michael Collado has joined the channel
- - - - -
-
-
-
-
- @Ross Turk has joined the channel
- - - - -
-
-
-
-
- GitHub app is successfully upgraded in your workspace 🎉
-To receive notifications in your private channels, you need to invite the GitHub app /invite @GitHub
 -
-
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by MansurAshraf
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by jquintus
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-  -
-
-
-
-
- @Harshal Sheth has joined the channel
- - - -
-
-
- *Thread Reply:* shh don't tell anyone there's a website coming
- - - -
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc2 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc3 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.0-rc4 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc5 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc6 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by wslulciuc
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage.github.io] Pull request opened by rossturk
-
- <a href="https://github.com/OpenLineage/OpenLineage.github.io">OpenLineage/OpenLineage.github.io</a>
-
-
-
- [OpenLineage/OpenLineage.github.io] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage.github.io">OpenLineage/OpenLineage.github.io</a>
-
-
-
- [OpenLineage/website] is now public!
- -
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage.github.io] Pull request opened by rossturk
-
- <a href="https://github.com/OpenLineage/OpenLineage.github.io">OpenLineage/OpenLineage.github.io</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage.github.io] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage.github.io">OpenLineage/OpenLineage.github.io</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Issue opened by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage.github.io] Pull request opened by rossturk
-
- <a href="https://github.com/OpenLineage/OpenLineage.github.io">OpenLineage/OpenLineage.github.io</a>
-
-
-
- [OpenLineage/website] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Issue opened by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage.github.io] Pull request closed by rossturk
-
- <a href="https://github.com/OpenLineage/OpenLineage.github.io">OpenLineage/OpenLineage.github.io</a>
-
-
-
- [OpenLineage/website] Pull request opened by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Issue closed by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by rossturk
- -
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- *Thread Reply:* I think I may try to deploy this change at the same time as a blog post about today’s LFAI announcement
- - - -
-
-
- [OpenLineage/website] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request opened by rossturk
- -
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- *Thread Reply:* Thanks. I was driving
- - - -
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by fiskus
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- *Thread Reply:* I reverted this :face_palm: git push origin head
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by rossturk
- -
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request merged by rossturk
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by knxacgcg
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by knxacgcg
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-  -
-
-
-
-
- @Oleksandr Dvornik has joined the channel
- - - -
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-  -
-
-
-
-
- @Joe Regensburger has joined the channel
- - - -
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by fm100
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc7 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc7 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc7 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc8 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - 0.0.1-rc8 published by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mandy-chessell
- -
-
-
-
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/website] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/website">OpenLineage/website</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by fm100
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mstrbac
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by nizardeen
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by pomdtr
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by collado-mike
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request closed by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request ready for review by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] New release Release - OpenLineage 0.1.0 published by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by OleksandrDvornik
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue closed by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by mobuchowski
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Issue opened by julienledem
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request opened by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- [OpenLineage/OpenLineage] Pull request merged by wslulciuc
-
- <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
-
-
-
- *Thread Reply:* If anyone has any more feedback on the website, feel free to add it to https://github.com/OpenLineage/website/issues 🙂
- - - -
-
-
- *Thread Reply:* @Julien Le Dem this ones ready for 👀
- - - -
-
-
- *Thread Reply:* @Michael Collado I’ve also added you as a reviewer on the PR to get your thoughts
- - - -
-
-
- [OpenLineage/metrics] is now public!
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/metrics">OpenLineage/metrics</a>
-
-
-
- [OpenLineage/docs] is now public!
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
-
-
-
- [OpenLineage/slack-archives] is now public!
-
-
-
-
-
-
- <a href="https://github.com/OpenLineage/slack-archives">OpenLineage/slack-archives</a>
-  +
+
+
+
+
+ @Santiago Cobos has joined the channel
+ + + +
+
+
+ Some pictures from last night
diff --git a/channel/spark-support-multiple-scala-versions/index.html b/channel/spark-support-multiple-scala-versions/index.html index 3329ce6..86c6b44 100644 --- a/channel/spark-support-multiple-scala-versions/index.html +++ b/channel/spark-support-multiple-scala-versions/index.html @@ -3055,12 +3055,12 @@*Thread Reply:* We use a lot of Seq and I doubt it's the only place we'll have problems
 +
@@ -4490,12 +4490,12 @@
+
@@ -4490,12 +4490,12 @@ *Thread Reply:*
 +
@@ -5233,7 +5233,7 @@
+
@@ -5233,7 +5233,7 @@ *Thread Reply:*
*Thread Reply:* (The 2.13.2 migration is because I force Jackson to 2.13.2)
+
+
+ *Thread Reply:* https://github.com/features/packages#pricing
 +
@@ -12884,7 +12917,7 @@
+
@@ -12884,7 +12917,7 @@ *Thread Reply:* I have this reference chain
*Thread Reply:*
 +
+ *Thread Reply:* but it's the same on recent main I think. This is main build from 6 days ago https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/9160/workflows/33a4d308-d0e6-4d75-a06b-7d8ef89bb1fe and SparkIcebergIntegrationTest is present there
 +
@@ -14091,12 +14124,12 @@
+
@@ -14091,12 +14124,12 @@ *Thread Reply:*
 +
@@ -20585,12 +20618,12 @@
+
@@ -20585,12 +20618,12 @@ *Thread Reply:*
 +
@@ -22206,12 +22239,12 @@
+
@@ -22206,12 +22239,12 @@ *Thread Reply:* Aye, but I didn't want this:
 +
@@ -24436,6 +24469,466 @@
+
@@ -24436,6 +24469,466 @@  +
+
+
+
+
+ Hey team!
+ +Another discussion: I created an MSK transport; let me know what you think. +With this transport, OL users can use MSK with IAM authentication without defining a custom transport.
+ +https://github.com/OpenLineage/OpenLineage/pull/2478
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+
+
+ *Thread Reply:* would be great if you could confirm that you tested this manually
+ + + +
+
+
+ *Thread Reply:* I test it. I can show some screenshots 🙂 +I have to create a small Python script, ship everything in a docker container and run it in a machine with network connectivity to MSK 😅
+ + + +
+
+
+ *Thread Reply:* I believe you, it's just it would be too expensive time wise to have real integration tests for each of those transports, so we have to rely on people manually testing it 🙂
+ + + +
+
+
+ *Thread Reply:* Yeah you need an AWS account, some terraform code to create and destroy the MSK plus the integration test to run inside the VPC network 😅
+ +But It's makes sense to put some screenshot in the PR just to show that was tested and how.
+ + + +
+
+
+ *Thread Reply:* The only test is the IAM auth because other than that is normal Kafka
+ + + +
+
+
+ *Thread Reply:* test code +```import datetime +import uuid
+ +from openlineage.client import OpenLineageClient +from openlineage.client.run import Job, Run, RunEvent, RunState +from openlineage.client.transport import MSKIAMTransport +from openlineage.client.transport.msk_iam import MSKIAMConfig
+ +if name == "main": + import logging
+ +logging.basicConfig(level=logging.DEBUG)
+config = MSKIAMConfig(
+ config={
+ "bootstrap.servers": "b-2.xxx.c2.kafka.eu-west-2.amazonaws.com:9098,b_1.xxx.c2.kafka.eu_west_2.amazonaws.com:9098"
+ },
+ topic="my_test_topic",
+ region="eu-west-2",
+ flush=True,
+)
+transport = MSKIAMTransport(config)
+client = OpenLineageClient(transport=transport)
+event = RunEvent(
+ eventType=RunState.START,
+ eventTime=datetime.datetime.now().isoformat(),
+ run=Run(runId=str(uuid.uuid4())),
+ job=Job(namespace="kafka", name="test"),
+ producer="prod",
+ schemaURL="schema/RunEvent",
+)
+
+client.emit(event)
+client.transport.producer.flush(timeout=1)
+print("Messages sent")```
+Logs
+DEBUG:openlineage.client.transport.kafka:BRKMAIN [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/bootstrap>: Enter main broker thread
+2024-02-29T12:14:47.560285672Z DEBUG:openlineage.client.transport.kafka:CONNECT [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/bootstrap>: Received CONNECT op
+2024-02-29T12:14:47.560288447Z DEBUG:openlineage.client.transport.kafka:STATE [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/bootstrap>: Broker changed state INIT -> TRY_CONNECT
+2024-02-29T12:14:47.560291862Z DEBUG:openlineage.client.transport.kafka:BROADCAST [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: Broadcasting state change
+2024-02-29T12:14:47.560294645Z DEBUG:openlineage.client.transport.kafka:TOPIC [rdkafka#producer-1] [thrd:app]: New local topic: my_test_topic
+2024-02-29T12:14:47.560297342Z DEBUG:openlineage.client.transport.kafka:TOPPARNEW [rdkafka#producer-1] [thrd:app]: NEW my_test_topic [-1] 0x5598e047bbf0 refcnt 0x5598e047bc80 (at rd_kafka_topic_new0:472)
+2024_02_29T12:14:47.560300475Z DEBUG:openlineage.client.transport.kafka:BRKMAIN [rdkafka#producer-1] [thrd:app]: Waking up waiting broker threads after setting OAUTHBEARER token
+2024-02-29T12:14:47.560303259Z DEBUG:openlineage.client.transport.kafka:WAKEUP [rdkafka#producer-1] [thrd:app]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/bootstrap>: Wake-up: OAUTHBEARER token update
+2024-02-29T12:14:47.560306334Z DEBUG:openlineage.client.transport.kafka:WAKEUP [rdkafka#producer-1] [thrd:app]: Wake-up sent to 1 broker thread in state >= TRY_CONNECT: OAUTHBEARER token update
+2024-02-29T12:14:47.560309239Z DEBUG:openlineage.client.transport.kafka:CONNECT [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/bootstrap>: broker in state TRY_CONNECT connecting
+2024-02-29T12:14:47.560312101Z DEBUG:openlineage.client.transport.kafka:STATE [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/bootstrap>: Broker changed state TRY_CONNECT -> CONNECT
+...
+DEBUG:openlineage.client.transport.kafka:PRODUCE [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/1>: my_test_topic [0]: Produce MessageSet with 1 message(s) (349 bytes, ApiVersion 7, MsgVersion 2, MsgId 0, BaseSeq -1, PID{Invalid}, uncompressed)
+2024-02-29T12:14:48.326364842Z DEBUG:openlineage.client.transport.kafka:SEND [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/1>: Sent ProduceRequest (v7, 454 bytes @ 0, CorrId 5)
+2024-02-29T12:14:48.382471756Z DEBUG:openlineage.client.transport.kafka:RECV [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/1>: Received ProduceResponse (v7, 102 bytes, CorrId 5, rtt 55.99ms)
+2024-02-29T12:14:48.382517219Z DEBUG:openlineage.client.transport.kafka:MSGSET [rdkafka#producer-1] [thrd:sasl_ssl://b-1.xxx.c2.kafka.eu-west-2]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/1>: my_test_topic [0]: MessageSet with 1 message(s) (MsgId 0, BaseSeq -1) delivered
+2024-02-29T12:14:48.382623532Z DEBUG:openlineage.client.transport.kafka:Send message <cimpl.Message object at 0x7fb116fcde40>
+2024-02-29T12:14:48.382648622Z DEBUG:openlineage.client.transport.kafka:Amount of messages left in Kafka buffers after flush 0
+2024-02-29T12:14:48.382730647Z DEBUG:openlineage.client.transport.kafka:WAKEUP [rdkafka#producer-1] [thrd:app]: sasl_<ssl://b-1.xxx.c2.kafka.eu-west-2.amazonaws.com:9098/1>: Wake-up: flushing
+2024-02-29T12:14:48.382747018Z DEBUG:openlineage.client.transport.kafka:WAKEUP [rdkafka#producer-1] [thrd:app]: Wake-up sent to 1 broker thread in state >= UP: flushing
+2024-02-29T12:14:48.382752798Z Messages sent
+
+
+ *Thread Reply:* I copied from the Kafka transport +https://github.com/OpenLineage/OpenLineage/pull/2478#discussion_r1507361123 +and It makes sense because otherwise when python read all the file could import a library that doesn't exist in case you don't need it.
+ + + +
+
+
+ *Thread Reply:* Also It think it's better to drop the support for IMDSv1 and in any case I should implement the IMDSv2 😅 to be complete +https://github.com/OpenLineage/OpenLineage/pull/2478#discussion_r1507359486
+ + + +
+
+
+ *Thread Reply:* Hi @Kacper Muda, +Is there still something to do in this PR?
+ + + + +
+
+
+
+
+ @Rajat has joined the channel
+ + + +Is it the case that Open Lineage defines the general framework but doesn’t actually enforce push or pull-based implementations, it just so happens that the reference implementation (Marquez) uses push?
@@ -8043,7 +8047,7 @@*Thread Reply:*
*Thread Reply:*
*Thread Reply:*
@@ -9685,7 +9693,7 @@*Thread Reply:*
Build on main passed (edited)
@@ -12784,6 +12796,43 @@
+
+
+ I added this configuration to my cluster :
@@ -12891,11 +12944,15 @@I receive this error message:
@@ -13097,11 +13154,15 @@*Thread Reply:*
@@ -13251,11 +13312,15 @@Now I have this:
@@ -13416,11 +13481,15 @@*Thread Reply:* Hi , @Luke Smith, thank you for your help, are you familiar with this error in azure databricks when you use OL?
@@ -13451,11 +13520,15 @@*Thread Reply:*
@@ -13508,11 +13581,15 @@*Thread Reply:* Successfully got a basic prefect flow working
@@ -22372,29 +22453,41 @@Hey there, I’m not sure why I’m getting below error, after I ran OPENLINEAGE_URL=<http://localhost:5000> dbt-ol run , although running this command dbt debug doesn’t show any error. Pls help.
*Thread Reply:* Actually i had to use venv that fixed above issue. However, i ran into another problem which is no jobs / datasets found in marquez:
*Thread Reply:*
@@ -24252,20 +24361,28 @@*Thread Reply:* oh got it, since its in default, i need to click on it and choose my dbt profile’s account name. thnx
@@ -24357,11 +24478,15 @@*Thread Reply:* May I know, why these highlighted ones dont have schema? FYI, I used sources in dbt.
@@ -24418,11 +24543,15 @@*Thread Reply:* I prepared this yaml file, not sure this is what u asked
@@ -27866,11 +27995,15 @@I have a dag that contains 2 tasks:
@@ -28832,11 +28965,15 @@It created 3 namespaces. One was the one that I point in the spark config property. The other 2 are the bucket that we are writing to (
I can see if i enter in one of the weird jobs generated this:
@@ -28963,11 +29108,15 @@*Thread Reply:* This job with no output is a symptom of the output not being understood. you should be able to see the facets for that job. There will be a spark_unknown facet with more information about the problem. If you put that into an issue with some more details about this job we should be able to help.
If I check the logs of marquez-web and marquez I can't see any error there
When I try to open the job fulfilments.execute_insert_into_hadoop_fs_relation_command I see this window:
*Thread Reply:* Here's what I mean:
@@ -31226,7 +31391,7 @@*Thread Reply:* This is an example Lineage event JSON I am sending.
*Thread Reply:* There are two types of failures: tests failed on stage model (relationships) and physical error in master model (no table with such name). The stage test node in Marquez does not show any indication of failures and dataset node indicates failure but without number of failed records or table name for persistent test storage. The failed master model shows in red but no details of failure. Master model tests were skipped because of model failure but UI reports "Complete".
@@ -35638,20 +35839,28 @@dbt test failures, to visualize better that error is happening, for example like that:
@@ -35823,11 +36032,15 @@ hello everyone , i'm learning Openlineage, I am trying to connect with airflow 2, is it possible? or that version is not yet released. this is currently throwing me airflow
@@ -36077,6 +36290,43 @@
+
+
+
+
+
+
+ *Thread Reply:* It needs to show Docker Desktop is running :
I've attached the logs and a screenshot of what I'm seeing the Spark UI. If you had a chance to take a look, it's a bit verbose but I'd appreciate a second pair of eyes on my analysis. Hopefully I got something wrong 😅
@@ -39983,11 +40253,15 @@*Thread Reply:* This is the one I wrote:
*Thread Reply:* however I can not fetch initial data when login into the endpoint
@@ -41681,11 +41959,15 @@@Kevin Mellott Hello Kevin, sorry to bother you again. I was finally able to configure Marquez in AWS using an ALB. Now I am receiving this error when calling the API
@@ -44042,11 +44328,15 @@Am i supposed to see this when I open marquez fro the first time on an empty database?
@@ -44433,11 +44723,15 @@Hi Everyone, Can someone please help me to debug this error ? Thank you very much all
@@ -49555,11 +49861,15 @@Hello everyone, I'm learning Openlineage, I finally achieved the connection between Airflow 2+ and Openlineage+Marquez. The issue is that I don't see nothing on Marquez. Do I need to modify current airflow operators?
@@ -49642,11 +49952,15 @@*Thread Reply:* Thanks, finally was my error .. I created a dummy dag to see if maybe it's an issue over the dag and now I can see something over Marquez
@@ -49824,7 +50142,7 @@happy to share the slides with you if you want 👍 here’s a PDF:
@@ -51028,11 +51350,15 @@Your periodical reminder that Github stars are one of those trivial things that make a significant difference for an OS project like ours. Have you starred us yet?
@@ -53756,11 +54082,15 @@*Thread Reply:*
@@ -53959,11 +54293,15 @@This is a similar setup as Michael had in the video.
@@ -54438,11 +54776,15 @@Hi~all, I have a question about lineage. I am now running airflow 2.3.1 and have started a latest marquez service by docker-compose. I found that using the example DAG of airflow can only see the job information, but not the lineage of the job. How can I configure it to see the lineage ?
@@ -57725,20 +58091,28 @@Hello all, after sending dbt openlineage events to Marquez, I am now looking to use the Marquez API to extract the lineage information. I am able to use python requests to call the Marquez API to get other information such as namespaces, datasets, etc., but I am a little bit confused about what I need to enter to get the lineage. I included screenshots for what the API reference shows regarding retrieving the lineage where it shows that a nodeId is required. However, this is where I seem to be having problems. It is not exactly clear where the nodeId needs to be set or what the nodeId needs to include. I would really appreciate any insights. Thank you!
@@ -57797,11 +58171,15 @@*Thread Reply:* You can do this in a few ways (that I can think of). First, by looking for a namespace, then querying for the datasets in that namespace:
@@ -57832,11 +58210,15 @@*Thread Reply:* Or you can search, if you know the name of the dataset:
@@ -60640,6 +61022,43 @@
+
+
+
+
+
+ check this out folks - marklogic datahub flow lineage into OL/marquez with jobs and runs and more. i would guess this is a pretty narrow use case but it went together really smoothly and thought i'd share sometimes it's just cool to see what people are working on
@@ -64118,11 +64578,15 @@Hi all, I have been playing around with Marquez for a hackday. I have been able to get some lineage information loaded in (using the local docker version for now). I have been trying set the location (for the link) and description information for a job (the text saying "Nothing to show here") but I haven't been able to figure out how to do this using the /lineage api. Any help would be appreciated.
Putting together some internal training for OpenLineage and highlighting some of the areas that have been useful to me on my journey with OpenLineage. Many thanks to @Michael Collado, @Maciej Obuchowski, and @Paweł Leszczyński for the continued technical support and guidance.
@@ -65257,20 +65725,28 @@hi all, really appreciate if anyone could help. I have been trying to create a poc project with openlineage with dbt. attached will be the pip list of the openlineage packages that i have. However, when i run "dbt-ol"command, it prompted as öpen as file, instead of running as a command. the regular dbt run can be executed without issue. i would want i had done wrong or if any configuration that i have missed. Thanks a lot
@@ -65649,7 +66125,7 @@./gradlew :shared:spotlessApply && ./gradlew :app:spotlessApply && ./gradlew clean build test
maybe another question for @Paweł Leszczyński: I was watching the Airflow summit talk that you and @Maciej Obuchowski did ( very nice! ). How is this exposed? I'm wondering if it shows up as an edge on the graph in Marquez? ( I guess it may be tracked as a parent run and if so probably does not show on the graph directly at this time? )
@@ -66869,11 +67349,15 @@*Thread Reply:*
@@ -68877,11 +69361,15 @@*Thread Reply:* After I send COMPLETE event with the same information I can see the dataset.
In this example I've added my-test-input on START and my-test-input2 on COMPLETE :
Here is the Marquez UI
@@ -72430,11 +72926,15 @@*Thread Reply:*
@@ -77177,11 +77677,15 @@*Thread Reply:* Apparently the value is hard coded in the code somewhere that I couldn't figure out but at-least learnt that in my Mac where this port 5000 is being held up can be freed by following the below simple step.
@@ -84818,11 +85322,15 @@But if I am not in a virtual environment, it installs the packages in my PYTHONPATH. You might try this to see if the dbt-ol script can be found in one of the directories in sys.path.
*Thread Reply:* this can help you verify that your PYTHONPATH and PATH are correct - installing an unrelated python command-line tool and seeing if you can execute it:
*Thread Reply:*
@@ -93252,11 +93768,15 @@Hi Team, I’m seeing creating data source, dataset API’s marked as deprecated . Can anyone point me how to create datasets via API calls?
@@ -94211,11 +94731,15 @@Is it possible to add column level lineage via api? Let's say I have fields A,B,C from my-input, and A,B from my-output, and B,C from my-output-s3. I want to see, filter, or query by the column name.
@@ -97313,11 +97837,15 @@23/04/20 10:00:15 INFO ConsoleTransport: {"eventType":"START","eventTime":"2023-04-20T10:00:15.085Z","run":{"runId":"ef4f46d1-d13a-420a-87c3-19fbf6ffa231","facets":{"spark.logicalPlan":{"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.22.0/integration/spark","schemaURL":"https://openlineage.io/spec/1-0-5/OpenLineage.json#/$defs/RunFacet","plan":[{"class":"org.apache.spark.sql.catalyst.plans.logical.CreateTableAsSelect","num-children":2,"name":0,"partitioning":[],"query":1,"tableSpec":null,"writeOptions":null,"ignoreIfExists":false},{"class":"org.apache.spark.sql.catalyst.analysis.ResolvedTableName","num-children":0,"catalog":null,"ident":null},{"class":"org.apache.spark.sql.catalyst.plans.logical.Project","num-children":1,"projectList":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num_children":0,"name":"workorderid","dataType":"integer","nullable":true,"metadata":{},"exprId":{"product-cl
@@ -99066,11 +99594,15 @@Hi, I'm new to Open data lineage and I'm trying to connect snowflake database with marquez using airflow and getting the error in etl_openlineage while running the airflow dag on local ubuntu environment and unable to see the marquez UI once it etl_openlineage has ran completed as success.
*Thread Reply:* What's the extract_openlineage.py file? Looks like your code?
*Thread Reply:* This is my log in airflow, can you please prvide more info over it.
@@ -99735,20 +100275,28 @@*Thread Reply:*
@@ -101255,11 +101811,15 @@I have configured Open lineage with databricks and it is sending events to Marquez as expected. I have a notebook which joins 3 tables and write the result data frame to an azure adls location. Each time I run the notebook manually, it creates two start events and two complete events for one run as shown in the screenshot. Is this something expected or I am missing something?
@@ -102859,11 +103423,15 @@I have a usecase where we are connecting to Azure sql database from databricks to extract, transform and load data to delta tables. I could see the lineage is getting build, but there is no column level lineage through its 1:1 mapping from source. Could you please check and update on this.
@@ -102977,7 +103545,7 @@*Thread Reply:* Here is the code we use.
@Paweł Leszczyński @Michael Robinson
I can see my job there but when i click on the job when its supposed to show lineage, its just an empty screen
@@ -108535,11 +109107,15 @@*Thread Reply:* ohh but if i try using the console output, it throws ClientProtocolError
@@ -108596,11 +109172,15 @@*Thread Reply:* this is the dev console in browser
@@ -108831,11 +109411,15 @@*Thread Reply:* marquez didnt get updated
@@ -109339,6 +109923,43 @@
+
+
+
+
+
+
+ *Thread Reply:* @Michael Robinson When we follow the documentation without changing anything and run sudo ./docker/up.sh we are seeing following errors:
@@ -110112,11 +110741,15 @@*Thread Reply:* So, I edited up.sh file and modified docker compose command by removing --log-level flag and ran sudo ./docker/up.sh and found following errors:
@@ -110147,11 +110780,15 @@*Thread Reply:* Then I copied .env.example to .env since compose needs .env file
@@ -110182,11 +110819,15 @@*Thread Reply:* I got this error:
@@ -110273,11 +110914,15 @@*Thread Reply:* @Michael Robinson Then it kind of worked but seeing following errors:
@@ -110308,11 +110953,15 @@*Thread Reply:*
@@ -110656,11 +111305,15 @@*Thread Reply:*
@@ -111536,7 +112189,7 @@*Thread Reply:* This is the event generated for above query.
this is event for view for which no lineage is being generated
Hi, I am running a job in Marquez with 180 rows of metadata but it is running for more than an hour. Is there a way to check the log on Marquez? Below is the screenshot of the job:
@@ -116278,11 +116943,15 @@*Thread Reply:* Also, yes, we have an even viewer that allows you to query the raw OL events
@@ -116339,7 +117008,7 @@*Thread Reply:*
I can now see this
@@ -117487,11 +118164,15 @@*Thread Reply:* but when i click on the job i then get this
@@ -117548,11 +118229,15 @@*Thread Reply:* @George Polychronopoulos Hi, I am facing the same issue. After adding spark conf and using the docker run command, marquez is still showing empty. Do I need to change something in the run command?
@@ -119539,11 +120224,15 @@
+
Expected. vs Actual.
+
+
+ The OL-spark version is matching the Spark version? Is there a known issues with the Spark / OL versions ?
@@ -124345,20 +125100,28 @@*Thread Reply:* I assume the problem is somewhere there, not on the level of facet definition, since SchemaDatasetFacet looks pretty much the same and it works
*Thread Reply:*
@@ -125192,11 +125967,15 @@*Thread Reply:* I think the code here filters out those string values in the list
@@ -125426,11 +126205,15 @@
+
@@ -126744,6 +127527,130 @@
+
+
+ *Thread Reply:* @Paweł Leszczyński @Maciej Obuchowski +can you please approve this CI to run integration tests? +https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/9497/workflows/4a20dc95-d5d1-4ad7-967c-edb6e2538820
+ + + +
+
+
+ *Thread Reply:* @Paweł Leszczyński +only 2 spark version are sending empty +input and output +for both START and COMPLETE event
+ +++ + + +• 3.4.2 + • 3.5.0 + i can look into the above , if you guide me a bit on how to ? + should i open a new ticket for it? + please suggest how to proceed?
+
+
+
+ *Thread Reply:* this integration test case lead to finding of the above bug for spark 3.4.2 and 3.5.0 +will that be a blocker to merge this test case? +@Paweł Leszczyński @Maciej Obuchowski
+ + + +
+
+
+ *Thread Reply:* @Paweł Leszczyński @Maciej Obuchowski +any direction on the above blocker will be helpful.
+ + + +I was doing this a second ago and this ended up with Caused by: java.lang.ClassNotFoundException: io.openlineage.spark.agent.OpenLineageSparkListener not found in com.databricks.backend.daemon.driver.ClassLoaders$LibraryClassLoader@1609ed55
*Thread Reply:* Can you please share with me your json conf for the cluster ?
@@ -128901,11 +129816,15 @@*Thread Reply:* It's because in mu build file I have
@@ -128936,11 +129855,15 @@*Thread Reply:* and the one that was copied is
@@ -132181,20 +133104,28 @@Hello, I'm currently in the process of following the instructions outlined in the provided getting started guide at https://openlineage.io/getting-started/. However, I've encountered a problem while attempting to complete *Step 1* of the guide. Unfortunately, I'm encountering an internal server error at this stage. I did manage to successfully run Marquez, but it appears that there might be an issue that needs to be addressed. I have attached screen shots.
@@ -132251,11 +133182,15 @@*Thread Reply:* @Jakub Dardziński 5000 port is not taken by any other application. The logs show some errors but I am not sure what is the issue here.
@@ -134980,11 +135915,15 @@*Thread Reply:* This is the error message:
@@ -135041,11 +135980,15 @@I am trying to run Google Cloud Composer where i have added the openlineage-airflow pypi packagae as a dependency and have added the env OPENLINEAGEEXTRACTORS to point to my custom extractor. I have added a folder by name dependencies and inside that i have placed my extractor file, and the path given to OPENLINEAGEEXTRACTORS is dependencies.<filename>.<extractorclass_name>…still it fails with the exception saying No module named ‘dependencies’. Can anyone kindly help me out on correcting my mistake
@@ -135365,11 +136308,15 @@*Thread Reply:*
@@ -135427,11 +136374,15 @@*Thread Reply:*
@@ -135488,11 +136439,15 @@*Thread Reply:* https://openlineage.slack.com/files/U05QL7LN2GH/F05SUDUQEDN/screenshot_2023-09-13_at_5.31.22_pm.png
@@ -135679,7 +136634,7 @@*Thread Reply:* these are the worker pod logs…where there is no log of openlineageplugin
*Thread Reply:* this is one of the experimentation that i have did, but then i reverted it back to keeping it to dependencies.bigqueryinsertjobextractor.BigQueryInsertJobExtractor…where dependencies is a module i have created inside my dags folder
@@ -135856,11 +136815,15 @@*Thread Reply:* https://openlineage.slack.com/files/U05QL7LN2GH/F05RM6EV6DV/screenshot_2023-09-13_at_12.38.55_am.png
@@ -135891,11 +136854,15 @@*Thread Reply:* these are the logs of the triggerer pod specifically
@@ -135978,11 +136945,15 @@*Thread Reply:* these are the logs of the worker pod at startup, where it does not complain of the plugin like in triggerer, but when tasks are run on this worker…somehow it is not picking up the extractor for the operator that i have written it for
@@ -136272,11 +137243,15 @@*Thread Reply:* have changed the dags folder where i have added the init file as you suggested and then have updated the OPENLINEAGEEXTRACTORS to bigqueryinsertjob_extractor.BigQueryInsertJobExtractor…still the same thing
@@ -136502,11 +137477,15 @@*Thread Reply:* I’ve done experiment, that’s how gcs looks like
@@ -136537,11 +137516,15 @@*Thread Reply:* and env vars
@@ -137171,7 +138154,7 @@*Thread Reply:*
I am attaching the log4j, there is no openlineagecontext
*Thread Reply:* A few more pics:
@@ -143258,16 +144273,20 @@@here I am trying out the openlineage integration of spark on databricks. There is no event getting emitted from Openlineage, I see logs saying OpenLineage Event Skipped. I am attaching the Notebook that i am trying to run and the cluster logs. Kindly can someone help me on this
*Thread Reply:* @Paweł Leszczyński this is what I am getting
@@ -144858,7 +145881,7 @@*Thread Reply:* attaching the html
*Thread Reply:* @Paweł Leszczyński you are right. This is what we are doing as well, combining events with the same runId to process the information on our backend. But even so, there are several runIds without this information. I went through these events to have a better view of what was happening. As you can see from 7 runIds, only 3 were showing the "environment-properties" attribute. Some condition is not being met here, or maybe it is what @Jason Yip suspects and there's some sort of filtering of unnecessary events
@@ -146215,11 +147242,15 @@*Thread Reply:* In docker, marquez-api image is not running and exiting with the exit code 127.
@@ -146765,11 +147796,15 @@Im upgrading the version from openlineage-airflow==0.24.0 to openlineage-airflow 1.4.1 but im seeing the following error, any help is appreciated
@@ -147274,11 +148309,15 @@*Thread Reply:* I see the difference of calling in these 2 versions, current versions checks if Airflow is >2.6 then directly runs on_running but earlier version was running on separate thread. IS this what's raising this exception?
@@ -148593,7 +149632,7 @@*Thread Reply:*
@Paweł Leszczyński I tested 1.5.0, it works great now, but the environment facets is gone in START... which I very much want it.. any thoughts?
@Paweł Leszczyński I went back to 1.4.1, output does show adls location. But environment facet is gone in 1.4.1. It shows up in 1.5.0 but namespace is back to dbfs....
like ( file_name, size, modification time, creation time )
@@ -154451,11 +155494,15 @@execute_spark_script(1, "/home/haneefa/airflow/dags/saved_files/")
@@ -155287,12 +156334,12 @@ I was referring to fluentd openlineage proxy which lets users copy the event and send it to multiple backend. Fluentd has a list of out-of-the box output plugins containing BigQuery, S3, Redshift and others (https://www.fluentd.org/dataoutputs)
+
@@ -157316,7 +158363,7 @@ *Thread Reply:* This text file contains a total of 10-11 events, including the start and completion events of one of my notebook runs. The process is simply reading from a Hive location and performing a full load to another Hive location.
+
@@ -161188,12 +162235,12 @@ *Thread Reply:* in Admin > Plugins can you see whether you have OpenLineageProviderPlugin and if so, are there listeners?
+
@@ -161292,7 +162339,7 @@ *Thread Reply:* Dont
*Thread Reply:*
+
+
+
+
+
@@ -163600,7 +164680,7 @@ Do we have the functionality to search on the lineage we are getting?
+ *Thread Reply:*
any suggestions on naming for Graph API sources from outlook? I pull a lot of data from email attachments with Airflow. generally I am passing a resource (email address), the mailbox, and subfolder. from there I list messages and find attachments
+ Hello team I see the following issue when i install apache-airflow-providers-openlineage==1.4.0
+
+
@@ -168984,12 +170064,12 @@
+
@@ -169177,6 +170257,32 @@
+
+
+ *Thread Reply:* @jayant joshi did deleting all volumes work for you, or did you discover another solution? We see users encountering this error from time to time, and it would be helpful to know more.
+ + + +"spark-submit --conf "spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener" --packages "io.openlineage:openlineagespark:1.7.0" --conf "spark.openlineage.transport.type=http" --conf "spark.openlineage.transport.url= http://marquez-api:5000" --conf "spark.openlineage.namespace=sparkintegration" pyspark_etl.py".
+
@@ -169715,12 +170821,12 @@ *Thread Reply:* Find the attached localhost 5000 & 5001 port results. Note that while running same code in the jupyter notebook, I could see lineage on the Marquez UI. For running a code through spark-submit only I am facing an issue.
+
@@ -170234,12 +171340,12 @@ *Thread Reply:* From your code, I could see marquez-api is running successfully at "http://marquez-api:5000". Find attached screenshot.
+
@@ -170485,12 +171591,12 @@ *Thread Reply:* the quickstart guide shows this example and it produces the result with a output node in the results, But when I run this in databricks I see no output node generated.
+
@@ -170579,12 +171685,12 @@ *Thread Reply:* as a result onkar_table as a dataset was never recorded hence lineage between mayur_table and onkar_table was not recorded as well
+
@@ -170592,12 +171698,12 @@
+
@@ -170981,12 +172087,12 @@
+
@@ -171473,12 +172579,12 @@ Error Screenshot:
+
@@ -171543,12 +172649,12 @@
+
@@ -171610,12 +172716,12 @@ *Thread Reply:* While composing up an open lineage docker-compose.yml. It showed the path to access jupyter lab, through the path I am accessing it. I didn't run any command externally. Find the attached screenshot.
+
@@ -171706,12 +172812,12 @@
+
@@ -172212,12 +173318,12 @@ listeners should be there under OpenLineageProviderPlugin
+
@@ -172408,12 +173514,12 @@ *Thread Reply:* This is the snapshot of my Plugins. I will also try with the configs which you mentioned.
+
@@ -173078,12 +174184,12 @@
+
@@ -173091,12 +174197,12 @@
+
+
@@ -173417,12 +174523,12 @@
+
@@ -173484,12 +174590,12 @@
+
@@ -173549,12 +174655,12 @@ *Thread Reply:* Probably you might ask this.
+
@@ -173615,12 +174721,12 @@
+
@@ -174651,12 +175757,12 @@
+
@@ -174912,12 +176018,12 @@ *Thread Reply:*
+
@@ -174951,12 +176057,12 @@ *Thread Reply:*
+
@@ -174990,12 +176096,12 @@ *Thread Reply:*
+
@@ -175057,12 +176163,12 @@ I did an airflow backfill job which redownloaded all files from a SFTP (191 files) and each of those are a separate OL dataset. in this view I clicked on a single file, but because it is connected to the "extract" airflow task, it shows all of the files that task downloaded as well (dynamic mapped tasks in Airflow)
+
+
+
+ *Thread Reply:* @Matthew Paras Hi! +im still struggling with empty outputs on databricks with OL latest version.
+ +24/03/13 16:35:56 INFO PlanUtils: apply method failed with +org.apache.spark.SparkException: There is no Credential Scope. Current env: Driver
+ +Any idea on how to solve this?
+ + + +
+
+
+ *Thread Reply:* Any databricks runtime version i should test with?
+ + + +
+
+
+ *Thread Reply:* interesting, I think we're running on 13.3 LTS - we also haven't upgraded to the official OL version, still using the patched one that I built
+ + +
+
+
+ *Thread Reply:* @Athitya Kumar can you tell us if this resolved your issue?
+ + + +
+
+
+ *Thread Reply:* @Michael Robinson - Yup, it's resolved for event types that're already being emitted from OpenLineage - but we have some events like StageCompleted / TaskEnd etc where we don't send events currently, where we'd like to plug-in our CustomFacets
+ + +
+
+
+ *Thread Reply:* @Athitya Kumar can you store the facets somewhere (like OpenLineageContext) and send them with complete event later?
*Thread Reply:* here is an axample:
+
@@ -178704,12 +180015,12 @@
+
@@ -179063,19 +180374,177 @@
+
- *Thread Reply:* Seems like its on OpenLineageSparkListener.onJobEnd
+```24/02/25 16:12:49 INFO PlanUtils: apply method failed with
+java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext.
+This stopped SparkContext was created at:
org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58) +sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) +sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) +sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) +java.lang.reflect.Constructor.newInstance(Constructor.java:423) +py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247) +py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) +py4j.Gateway.invoke(Gateway.java:238) +py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80) +py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69) +py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182) +py4j.ClientServerConnection.run(ClientServerConnection.java:106) +java.lang.Thread.run(Thread.java:750)
+ +The currently active SparkContext was created at:
+ +org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58) +sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) +sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) +sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) +java.lang.reflect.Constructor.newInstance(Constructor.java:423) +py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247) +py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) +py4j.Gateway.invoke(Gateway.java:238) +py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80) +py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69) +py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182) +py4j.ClientServerConnection.run(ClientServerConnection.java:106) +java.lang.Thread.run(Thread.java:750)
+ +at org.apache.spark.SparkContext.assertNotStopped(SparkContext.scala:121) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SparkSession.<init>(SparkSession.scala:113) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:962) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SQLContext$.getOrCreate(SQLContext.scala:1023) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.sql.SQLContext.getOrCreate(SQLContext.scala) ~[spark-sql_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.hudi.client.common.HoodieSparkEngineContext.<init>(HoodieSparkEngineContext.java:65) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.SparkHoodieTableFileIndex.<init>(SparkHoodieTableFileIndex.scala:65) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.HoodieFileIndex.<init>(HoodieFileIndex.scala:81) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.HoodieBaseRelation.fileIndex$lzycompute(HoodieBaseRelation.scala:236) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.HoodieBaseRelation.fileIndex(HoodieBaseRelation.scala:234) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.BaseFileOnlyRelation.toHadoopFsRelation(BaseFileOnlyRelation.scala:153) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource$.resolveBaseFileOnlyRelation(DefaultSource.scala:268) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource$.createRelation(DefaultSource.scala:232) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:111) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:68) ~[hudi-spark-bundle.jar:0.12.2-amzn-0]
+at io.openlineage.spark.agent.lifecycle.plan.SaveIntoDataSourceCommandVisitor.apply(SaveIntoDataSourceCommandVisitor.java:140) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.plan.SaveIntoDataSourceCommandVisitor.apply(SaveIntoDataSourceCommandVisitor.java:47) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder$1.apply(AbstractQueryPlanDatasetBuilder.java:94) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder$1.apply(AbstractQueryPlanDatasetBuilder.java:85) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.util.PlanUtils.safeApply(PlanUtils.java:279) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder.lambda$apply$0(AbstractQueryPlanDatasetBuilder.java:75) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at java.util.Optional.map(Optional.java:215) ~[?:1.8.0_392]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder.apply(AbstractQueryPlanDatasetBuilder.java:67) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.api.AbstractQueryPlanDatasetBuilder.apply(AbstractQueryPlanDatasetBuilder.java:39) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.util.PlanUtils.safeApply(PlanUtils.java:279) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.lambda$null$23(OpenLineageRunEventBuilder.java:451) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) ~[?:1.8.0_392]
+at java.util.Iterator.forEachRemaining(Iterator.java:116) ~[?:1.8.0_392]
+at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_392]
+at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:150) ~[?:1.8.0_392]
+at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:173) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:485) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline$7$1.accept(ReferencePipeline.java:272) ~[?:1.8.0_392]
+at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1384) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_392]
+at java.util.stream.StreamSpliterators$WrappingSpliterator.forEachRemaining(StreamSpliterators.java:313) ~[?:1.8.0_392]
+at java.util.stream.Streams$ConcatSpliterator.forEachRemaining(Streams.java:742) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_392]
+at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) ~[?:1.8.0_392]
+at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:1.8.0_392]
+at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:566) ~[?:1.8.0_392]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildOutputDatasets(OpenLineageRunEventBuilder.java:410) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.populateRun(OpenLineageRunEventBuilder.java:298) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildRun(OpenLineageRunEventBuilder.java:281) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildRun(OpenLineageRunEventBuilder.java:259) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.end(SparkSQLExecutionContext.java:257) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at io.openlineage.spark.agent.OpenLineageSparkListener.onJobEnd(OpenLineageSparkListener.java:167) ~[io.openlineage_openlineage-spark-1.6.2.jar:1.6.2]
+at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:39) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) ~[scala-library-2.12.15.jar:?]
+at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) ~[scala-library-2.12.15.jar:?]
+at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1447) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96) ~[spark-core_2.12-3.3.1-amzn-0.1.jar:3.3.1-amzn-0.1]
+24/02/25 16:13:04 INFO AsyncEventQueue: Process of event SparkListenerJobEnd(23,1708877534168,JobSucceeded) by listener OpenLineageSparkListener took 15.64437991s. +24/02/25 16:13:04 ERROR JniBasedUnixGroupsMapping: error looking up the name of group 1001: No such file or directory```
+ + + +
+
+
+ Lastly, would disabling facets improve performance? eg. disabling spark.logicalPlan
*Thread Reply:* Hmm yeah I'm confused, https://github.com/OpenLineage/OpenLineage/blob/1.6.2/integration/spark/shared/src/main/java/io/openlineage/spark/agent/util/PlanUtils.java#L277 seems to indicate as you said (safeApply swallows the exception), but the job exits after on an error code (EMR marks the job as failed)
The crash stops if I remove spark.stop() or disable the OpenLineage listener so this is odd 🤔
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
@@ -179099,15 +180568,56 @@ *Thread Reply:* Disabling spark.LogicalPlan may improve performance of populating OL event. It's disabled by default in recent version (the one released yesterday). You can also use circuit breaker feature if you are worried about Ol integration affecting Spark jobs
*Thread Reply:* 24/02/25 16:12:49 INFO PlanUtils: apply method failed with -> yeah, log level is info. It would look as if you were trying to run some action after stopping spark, but you said that disabling OpenLineage listener makes it succeed. This is odd.
+
+
+ *Thread Reply:* Maybe its some race condition on shutdown logic with event listeners? It seems like the listener being enabled is causing executors to be spun up (which fails) after the Spark session is already stopped
+ +• After the stacktrace above I see ConsoleTransport log some OpenLineage event data
+• Then oddly it looks like a bunch of executors are launched after the Spark session has already been stopped
+• These executors crash on startup which is likely whats causing the Spark job to exit with an error code
+24/02/24 07:18:03 INFO ConsoleTransport: {"eventTime":"2024_02_24T07:17:05.344Z","producer":"<https://github.com/OpenLineage/OpenLineage/tree/1.6.2/integration/spark>",
+...
+24/02/24 07:18:06 INFO YarnAllocator: Will request 1 executor container(s) for ResourceProfile Id: 0, each with 4 core(s) and 27136 MB memory. with custom resources: <memory:27136, max memory:2147483647, vCores:4, max vCores:2147483647>
+24/02/24 07:18:06 INFO YarnAllocator: Submitted 1 unlocalized container requests.
+24/02/24 07:18:09 INFO YarnAllocator: Launching container container_1708758297553_0001_01_000004 on host {ip} for executor with ID 3 for ResourceProfile Id 0 with resources <memory:27136, vCores:4>
+24/02/24 07:18:09 INFO YarnAllocator: Launching executor with 21708m of heap (plus 5428m overhead/off heap) and 4 cores
+24/02/24 07:18:09 INFO YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
+24/02/24 07:18:09 INFO YarnAllocator: Completed container container_1708758297553_0001_01_000003 on host: {ip} (state: COMPLETE, exit status: 1)
+24/02/24 07:18:09 WARN YarnAllocator: Container from a bad node: container_1708758297553_0001_01_000003 on host: {ip}. Exit status: 1. Diagnostics: [2024-02-24 07:18:06.508]Exception from container-launch.
+Container id: container_1708758297553_0001_01_000003
+Exit code: 1
+Exception message: Launch container failed
+Shell error output: Nonzero exit code=1, error message='Invalid argument number'
+The new executors all fail with:
+Caused by: org.apache.spark.rpc.RpcEndpointNotFoundException: Cannot find endpoint: <spark://CoarseGrainedScheduler>@{ip}:{port}
+
*Thread Reply:* This feature is going to be so useful for us! Love it!
+*Thread Reply:* The debug logs from AsyncEventQueue show OpenLineageSparkListener took 21.301411402s fwiw - I'm assuming thats abnormally long
+
- @channel
-We released OpenLineage 1.9.1, featuring:
-• Airflow: add support for JobTypeJobFacet properties #2412 @mattiabertorello
-• dbt: add support for JobTypeJobFacet properties #2411 @mattiabertorello
-• Flink: support Flink Kafka dynamic source and sink #2417 @HuangZhenQiu
-• Flink: support multi-topic Kafka Sink #2372 @pawel-big-lebowski
-• Flink: support lineage for JDBC connector #2436 @HuangZhenQiu
-• Flink: add common config gradle plugin #2461 @HuangZhenQiu
-• Java: extend circuit breaker loaded with ServiceLoader #2435 @pawel-big-lebowski
-• Spark: integration now emits intermediate, application level events wrapping entire job execution #2371 @mobuchowski
-• Spark: support built-in lineage within DataSourceV2Relation #2394 @pawel-big-lebowski
-• Spark: add support for JobTypeJobFacet properties #2410 @mattiabertorello
-• Spark: stop sending spark.LogicalPlan facet by default #2433 @pawel-big-lebowski
-• Spark/Flink/Java: circuit breaker #2407 @pawel-big-lebowski
-• Spark: add the capability to publish Scala 2.12 and 2.13 variants of openlineage-spark #2446 @d-m-h
-A large number of changes and bug fixes were also included.
-Thanks to all our contributors with a special shout-out to @Damien Hawes, who contributed >10 PRs to this release!
-Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.9.1
-Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
-Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.8.0...1.9.1
-Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
-PyPI: https://pypi.org/project/openlineage-python/
*Thread Reply:* The yarn logs also seem to indicate the listener is somehow causing the app to start up again
+2024-02-24 07:18:00,152 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl (SchedulerEventDispatcher:Event Processor): container_1708758297553_0001_01_000002 Container Transitioned from RUNNING to COMPLETED
+2024-02-24 07:18:00,155 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.allocator.AbstractContainerAllocator (SchedulerEventDispatcher:Event Processor): assignedContainer application attempt=appattempt_1708758297553_0001_000001 container=null queue=default clusterResource=<memory:54272, vCores:8> type=OFF_SWITCH requestedPartition=
+2024-02-24 07:18:00,155 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.AppSchedulingInfo (SchedulerEventDispatcher:Event Processor): Allocate Updates PendingContainers: 2 Decremented by: 1 SchedulerRequestKey{priority=0, allocationRequestId=0, containerToUpdate=null} for: appattempt_1708758297553_0001_000001
+2024-02-24 07:18:00,155 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl (SchedulerEventDispatcher:Event Processor): container_1708758297553_0001_01_000003 Container Transitioned from NEW to ALLOCATED
+Is there some logic in the listener that can create a Spark session if there is no active session?
+
+
+ *Thread Reply:* not sure of this, I couldn't find any place of that in code
+ + + +
+
+
+ *Thread Reply:* Probably another instance when doing something generic does not work with Hudi well 😶
+
+
+ *Thread Reply:* Dumb question, what info needs to be fetched from Hudi? Is this in the createRelation call? I'm surprised the logs seem to indicate Hudi table metadata seems to be being read from S3 in the listener
What would need to be implemented for proper Hudi support?
+ + + +
+
+
+ *Thread Reply:* @Max Zheng well, basically we need at least proper name and namespace for the dataset. How we do that is completely dependent on the underlying code, so probably somewhere here: https://github.com/apache/hudi/blob/3a97b01c0263c4790ffa958b865c682f40b4ada4/hudi-[…]-common/src/main/scala/org/apache/hudi/HoodieBaseRelation.scala
Most likely we don't need to do any external calls or read anything from S3. It's just done because without something that understands Hudi classes we just do the generic thing (createRelation) that has the biggest chance to work.
For example, for Iceberg we can get the data required just by getting config from their catalog config - and I think with Hudi it has to work the same way, because logically - if you're reading some table, you have to know where it is or how it's named.
+
+ <a href="https://github.com/apache/hudi">apache/hudi</a>
+
+
+
+ *Thread Reply:* That makes sense, and that info is in the hoodie.properties file that seems to be loaded based on the logs. But the events I see OL generate seem to have S3 path and S3 bucket as a the name and namespace respectively - ie. it doesn't seem to be using any of the metadata being read from Hudi?
+"outputs": [
+ {
+ "namespace": "s3://{bucket}",
+ "name": "{S3 prefix path}",
+(we'd be perfectly happy with just the S3 path/bucket - is there a way to disable createRelation or have OL treat these Hudi as raw parquet?)
+
+
+ *Thread Reply:* > But the events I see OL generate seem to have S3 path and S3 bucket as a the name and namespace respectively - ie. it doesn't seem to be using any of the metadata being read from Hudi?
+Probably yes - as I've said, the OL handling of it is just inefficient and not specific to Hudi. It's good enought that they generate something that seems to be valid dataset naming 🙂
+And, the fact it reads S3 metadata is not intended - it's just that Hudi implements createRelation this way.
++ + + +(we'd be perfectly happy with just the S3 path/bucket - is there a way to disable
+createRelationor have OL treat these Hudi as raw parquet?) + The way OpenLineage Spark integration works is by looking at Optimized Logical Plan of particular Spark job. So the solution would be to implement Hudi specific path inSaveIntoDataSourceCommandVisitoror any particular other visitor that touches on the Hudi path - or, if Hudi has their own LogicalPlan nodes, implement support for it.
+
+
+ *Thread Reply:* (sorry for answering that late @Max Zheng, I thought I had the response send and it was sitting in my draft for few days 😞 )
+ + + +
+
+
+ *Thread Reply:* Thanks for the explanation @Maciej Obuchowski
+ +I've been digging into the source code to see if I can help contribute Hudi support for OL. At least in SaveIntoDataSourceCommandVisitor it seems all I need to do is:
+```--- a/integration/spark/shared/src/main/java/io/openlineage/spark/agent/lifecycle/plan/SaveIntoDataSourceCommandVisitor.java
++++ b/integration/spark/shared/src/main/java/io/openlineage/spark/agent/lifecycle/plan/SaveIntoDataSourceCommandVisitor.java
+@@ -114,8 +114,9 @@ public class SaveIntoDataSourceCommandVisitor
+ LifecycleStateChange lifecycleStateChange =
+ (SaveMode.Overwrite == command.mode()) ? OVERWRITE : CREATE;
+This seems to work and avoids thecreateRelation` call but I still run into the same crash 🤔 so now I'm not sure if this is a Hudi issue. Do you know of any other dependencies on the output data source? I wonder if https://openlineage.slack.com/archives/C01CK9T7HKR/p1708671958295659 rdd events could be the culprit?I'm going to try and reproduce the crash without Hudi and just with parquet
+
*Thread Reply:* Oudstanding work @Damien Hawes 👏
+*Thread Reply:* Hmm reading over RDDExecutionContext it seems highly unlikely anything in that would cause this crash
-
+
+
+ *Thread Reply:* There might be other part related to reading from Hudi?
+ + + +
+
+
+ *Thread Reply:* SaveIntoDataSourceCommandVisitor only takes care about root node of whole LogicalPlan
+
+
+ *Thread Reply:* I would serialize logical plan and take a look at leaf nodes of the job that causes hang
+ + + +
+
+
+ *Thread Reply:* for simple check you can just make the dataset handler that handles them return early
+ + + +
+
+
+ *Thread Reply:* https://openlineage.slack.com/archives/C01CK9T7HKR/p1708544898883449?thread_ts=1708541527.152859&cid=C01CK9T7HKR the parsed logical plan for my test job is just the SaveIntoDataSourceCommandVisitor(though I might be mis-understanding what you mean by leaf nodes)
+
*Thread Reply:* Thank you 👏👏
+*Thread Reply:* I was able to reproduce the issue with InsertIntoHadoopFsRelationCommand with aparquet write with the same job - I'm starting to suspect this is a Spark with Docker/yarn bug
+
- Hi all, I'm working on a local Airflow-OpenLineage-Marquez integration using Airflow 2.7.3 and python 3.10. Everything seems to be installed correctly with the appropriate settings. I'm seeing events, jobs, tasks trickle into the UI. I'm using the PostgresOperator. When it's time for the SQL code to be parsed, I'm seeing the following in my Airflow logs:
-[2024-02-26, 19:43:17 UTC] {sql.py:457} INFO - Running statement: SELECT CURRENT_SCHEMA;, parameters: None
-[2024-02-26, 19:43:17 UTC] {base.py:152} WARNING - OpenLineage provider method failed to extract data from provider.
-[2024-02-26, 19:43:17 UTC] {manager.py:198} WARNING - Extractor returns non-valid metadata: None
-Can anyone give me pointers on why exactly this might be happening? I've tried also with the SQLExecuteQueryOperator, same result. I previously got a Marquez setup to work with the external OpenLineage package for Airflow with Airflow 2.6.1. But I'm struggling with this newer integrated OpenLineage version
*Thread Reply:* Without hudi read?
@@ -179286,21 +181240,19 @@
+
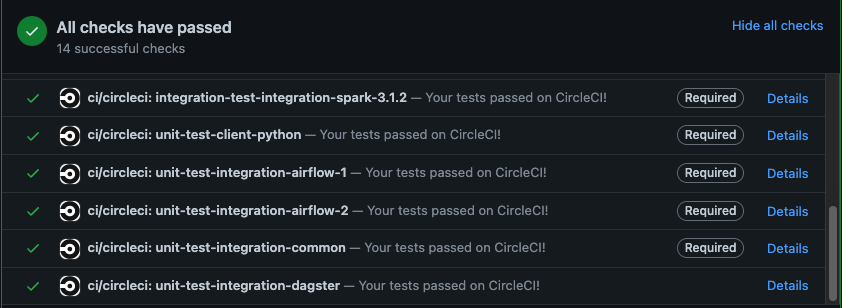 +
+  +
+  +
+  +
+  + }
+
+ }
+  +
+  + }
+
+ }
+  +
+  +
+  +
+  +
+  +
+  + }
+
+ }
+  + }
+
+ }
+ 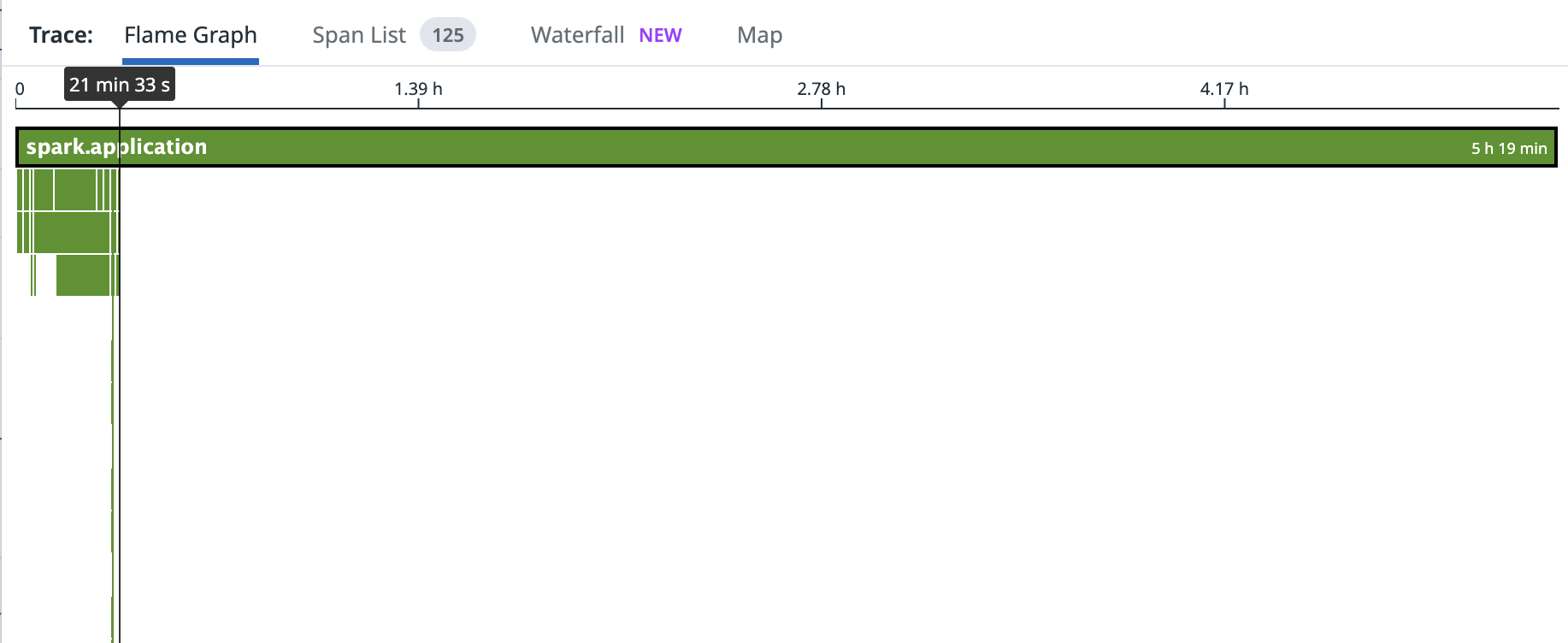 +
+ 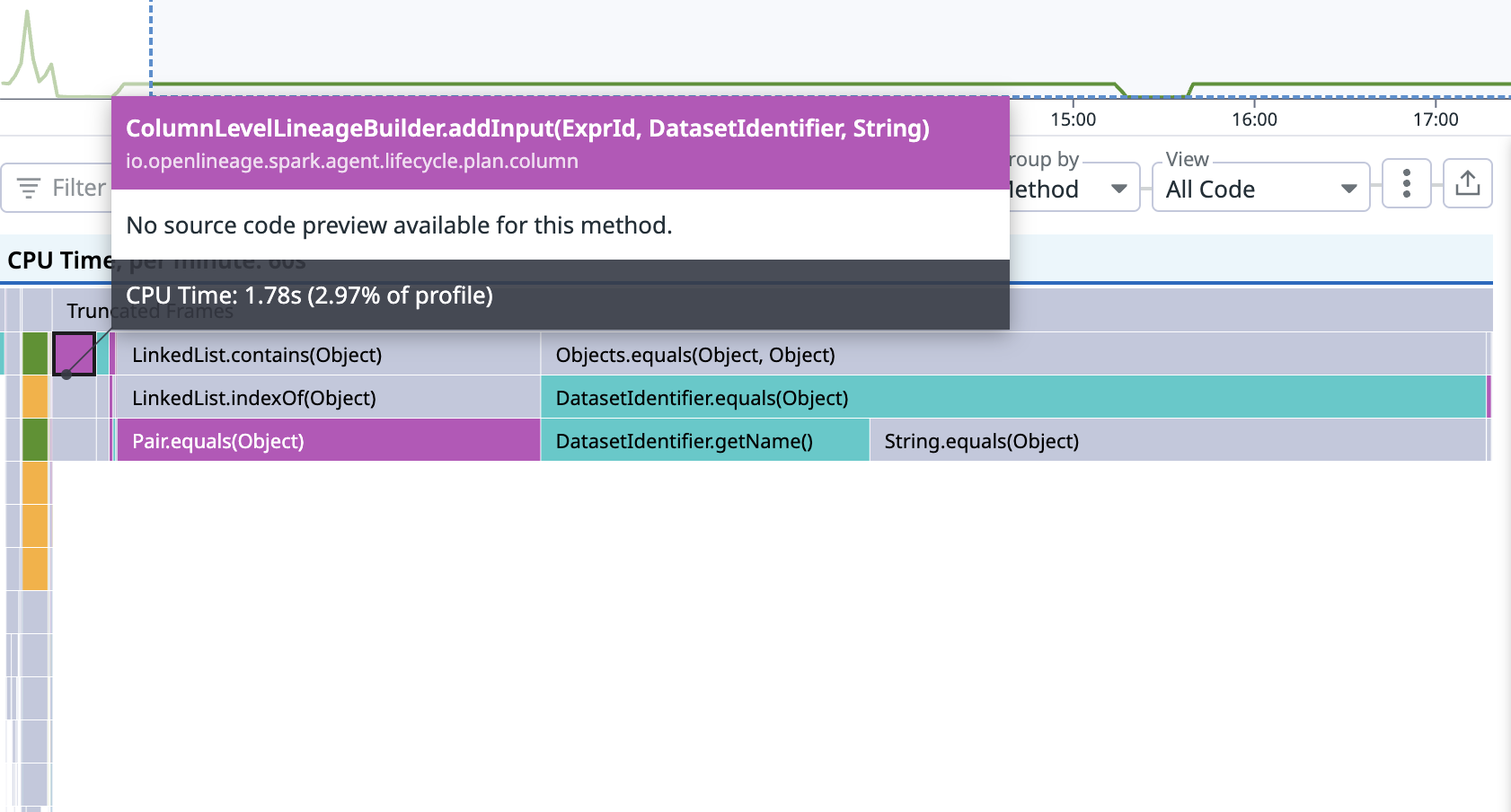 +
+ 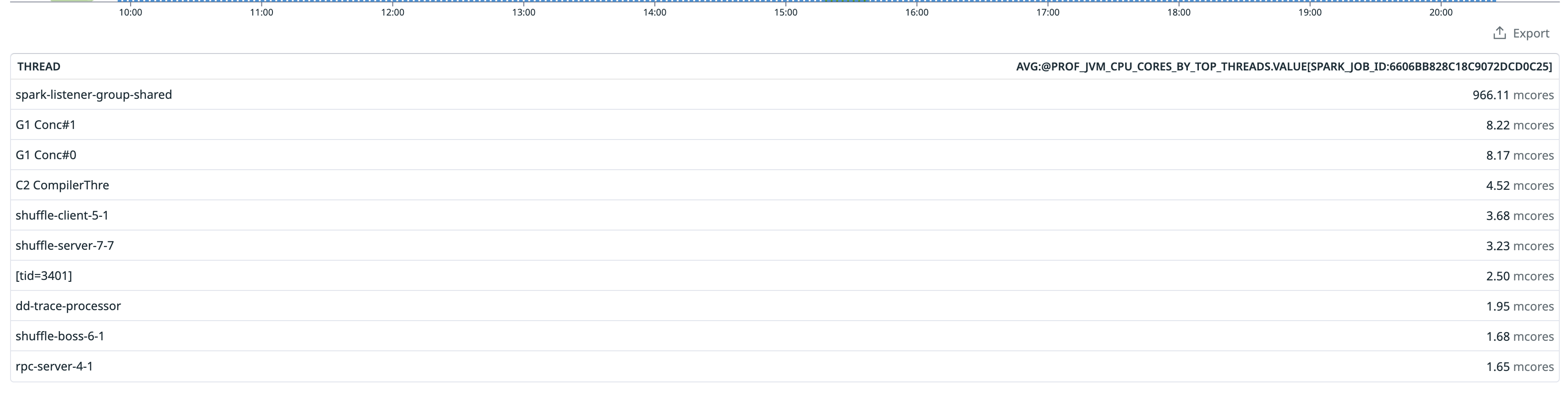 +
+ 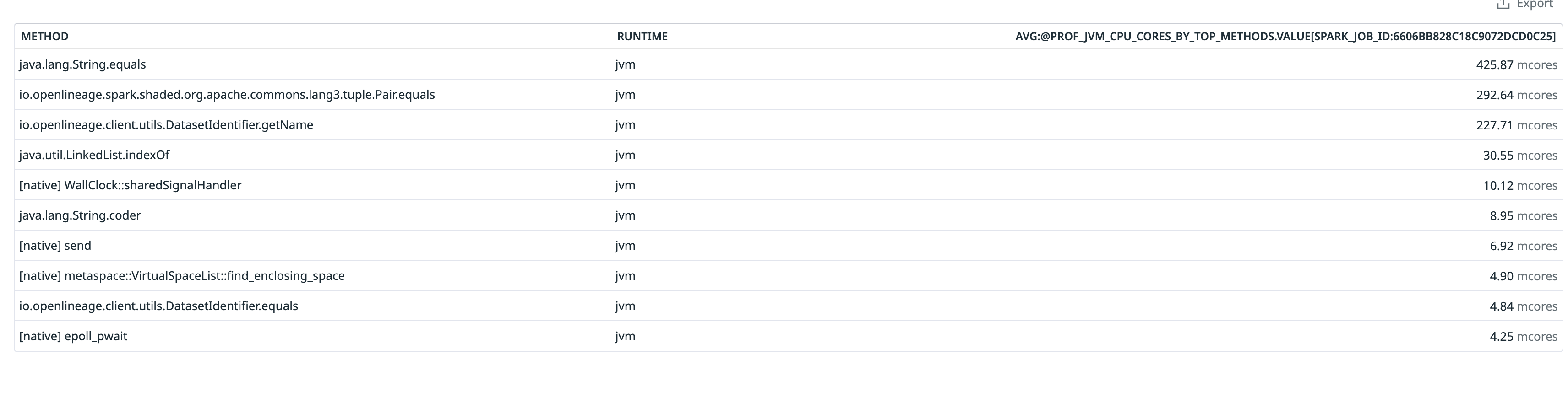 +
+  +
+ 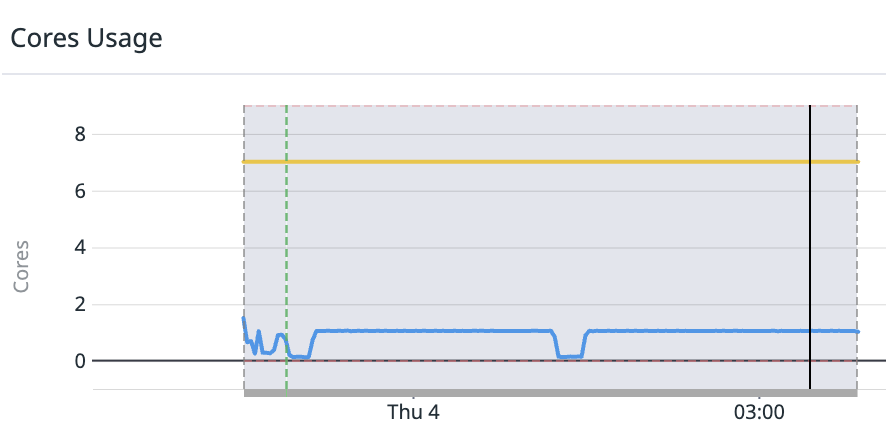 +
+ 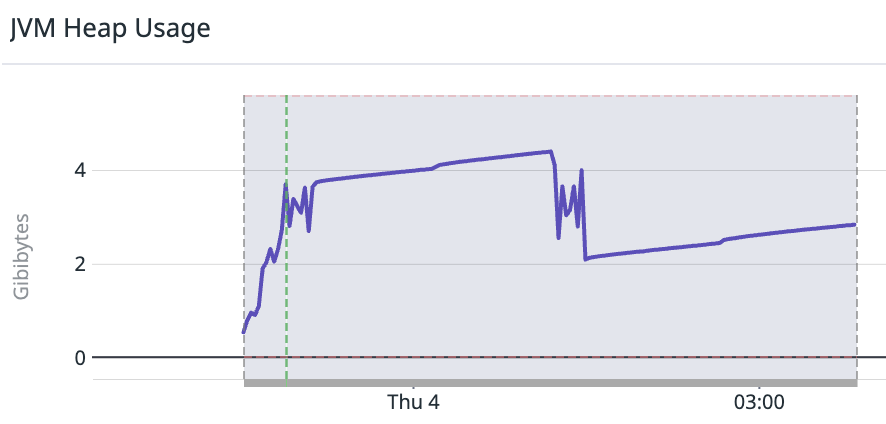 +
+ 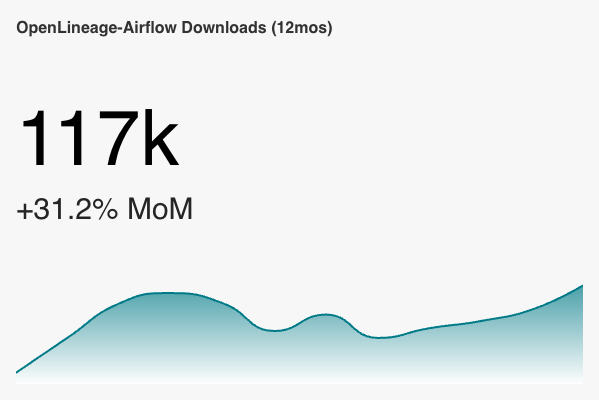 +
+  +
+ 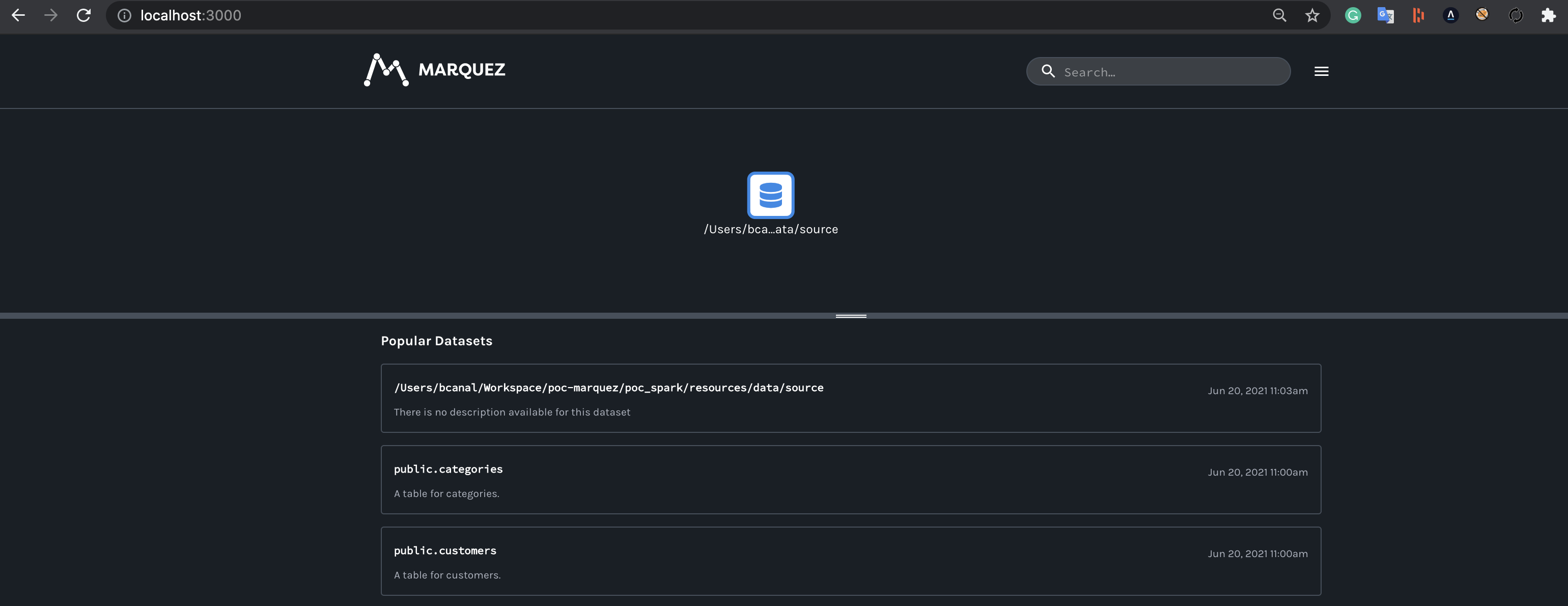 +
+  +
+  +
+ 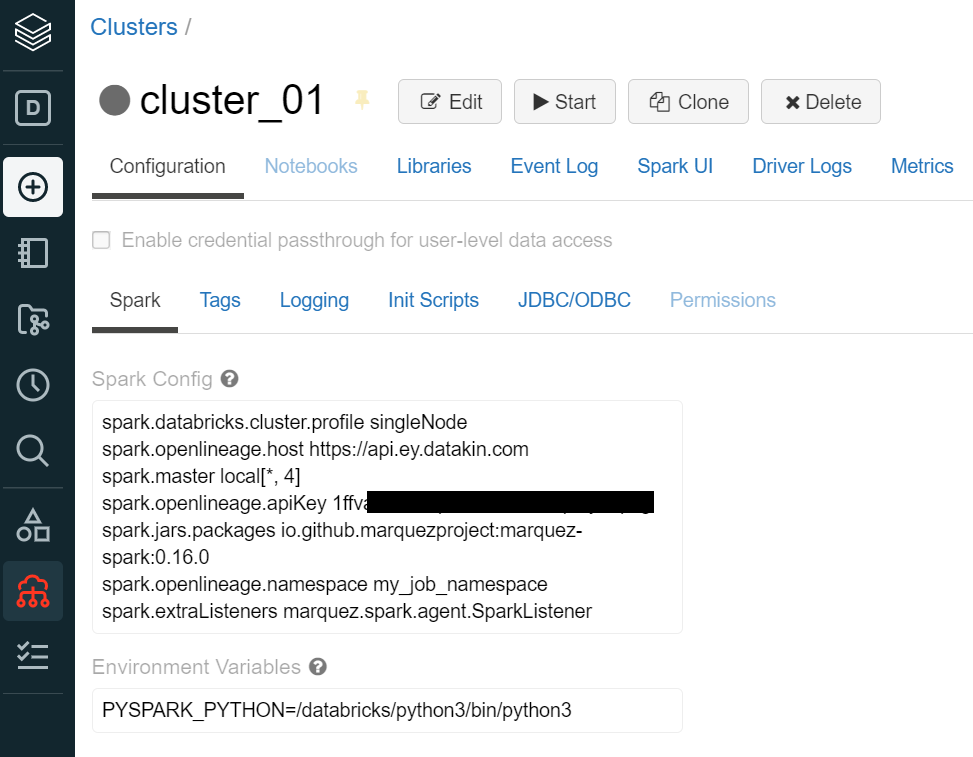 +
+ 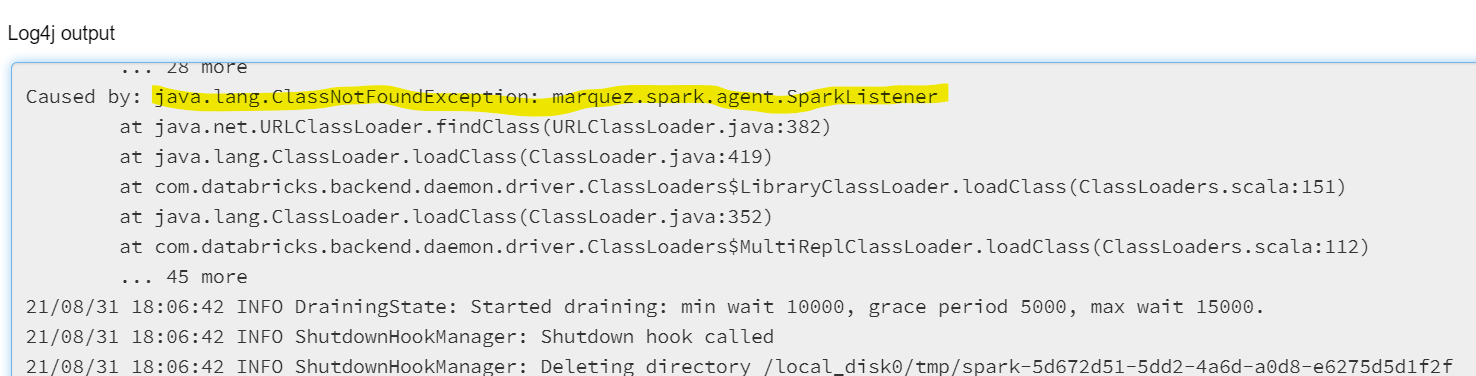 +
+  +
+ 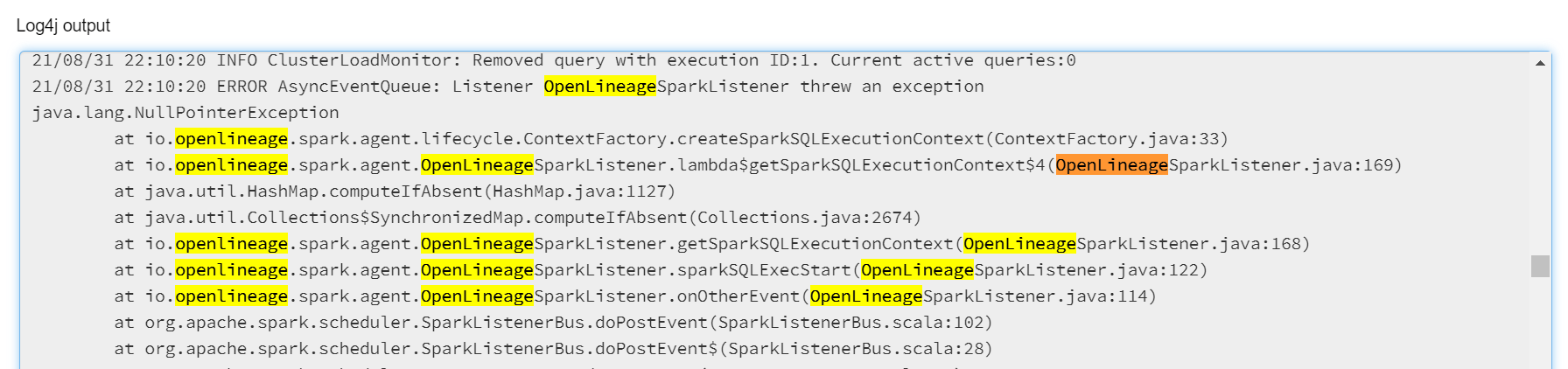 +
+ 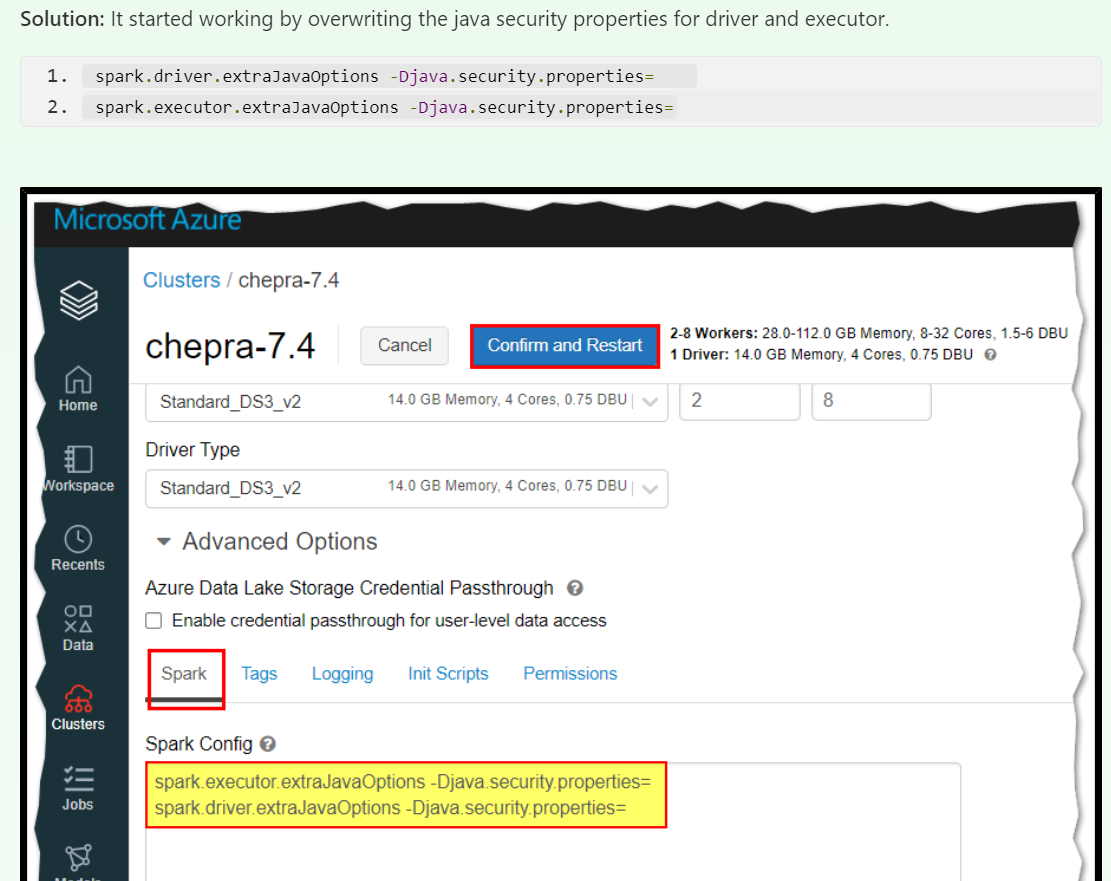 +
+  +
+ 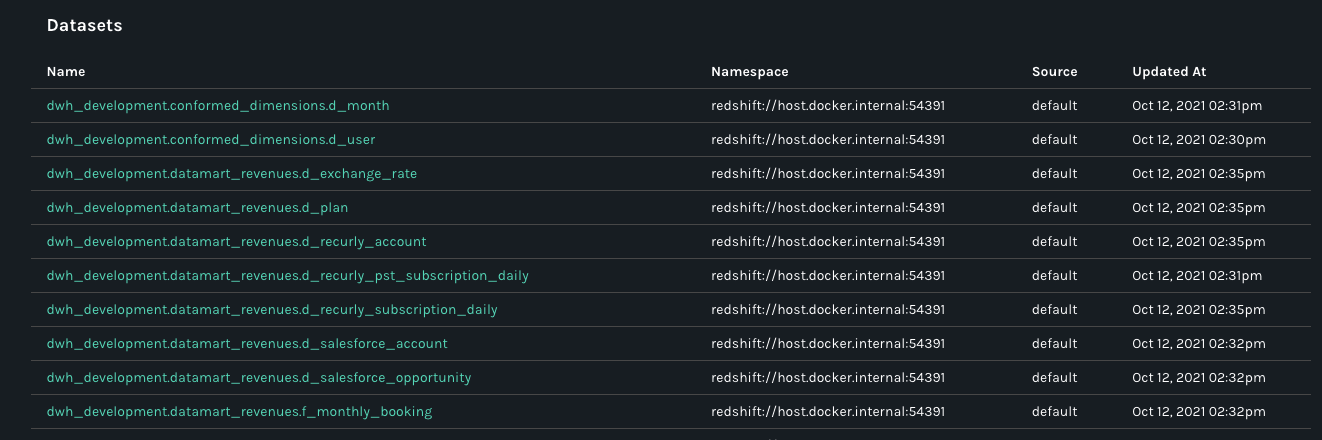 +
+ 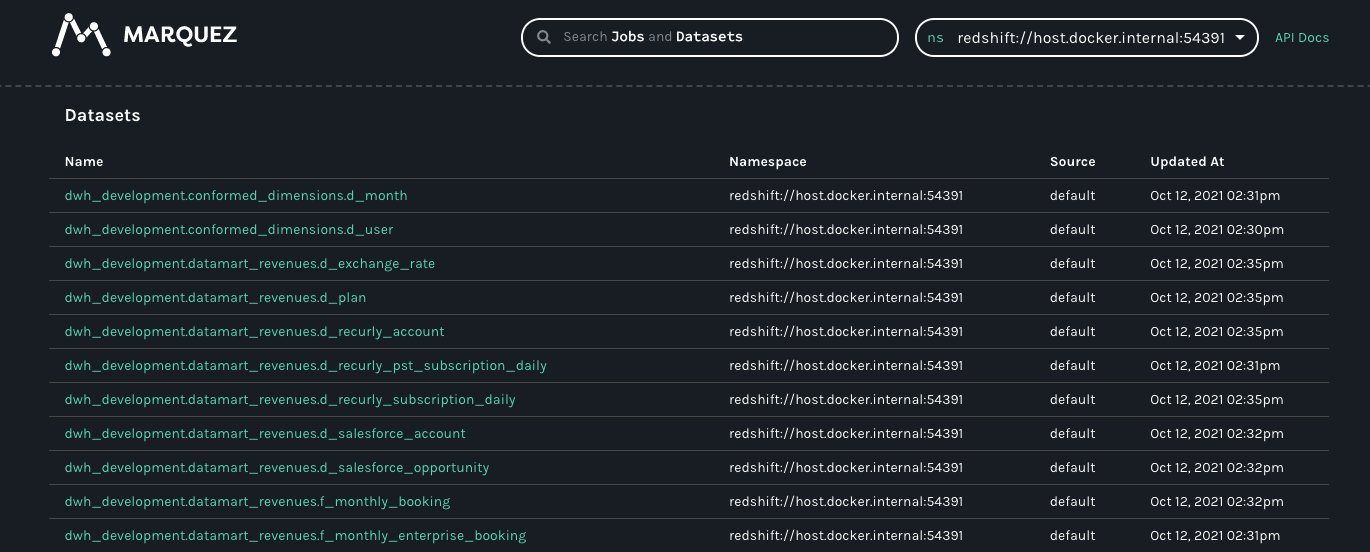 +
+ 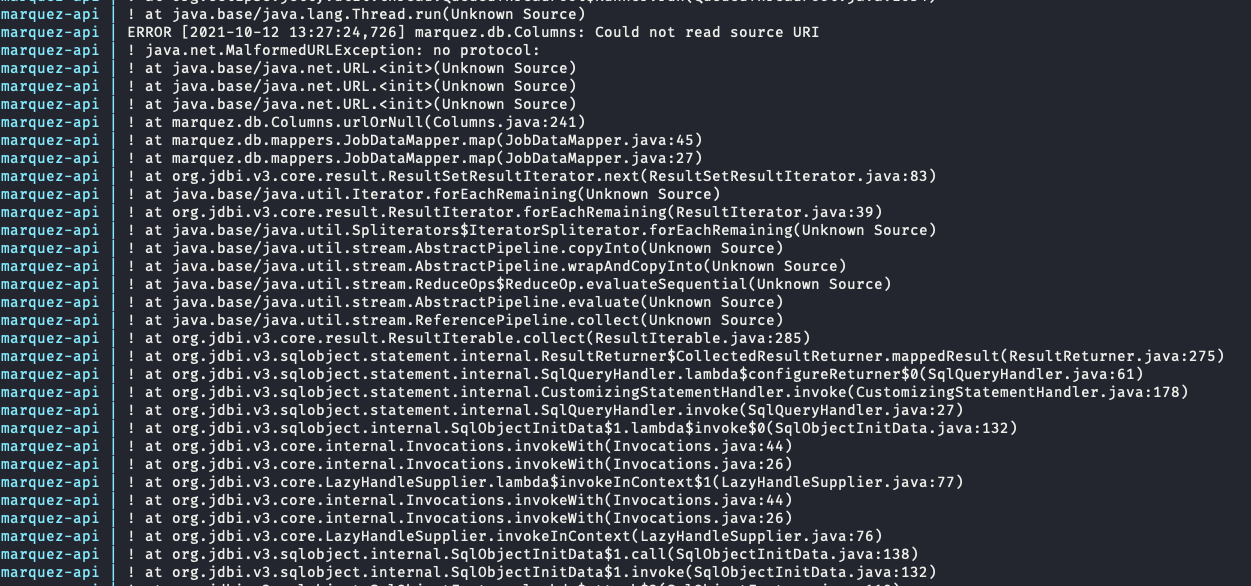 +
+ 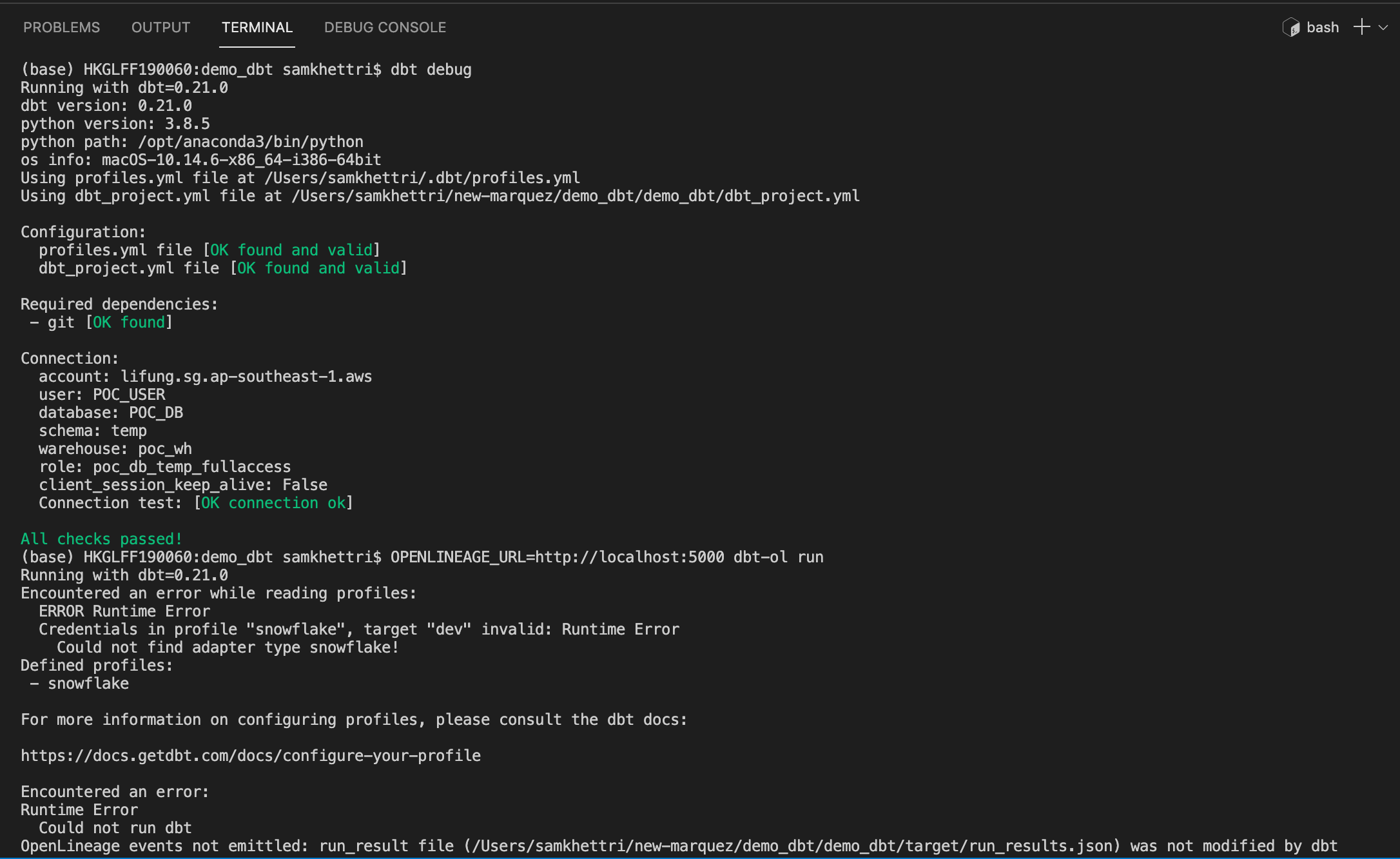 +
+ 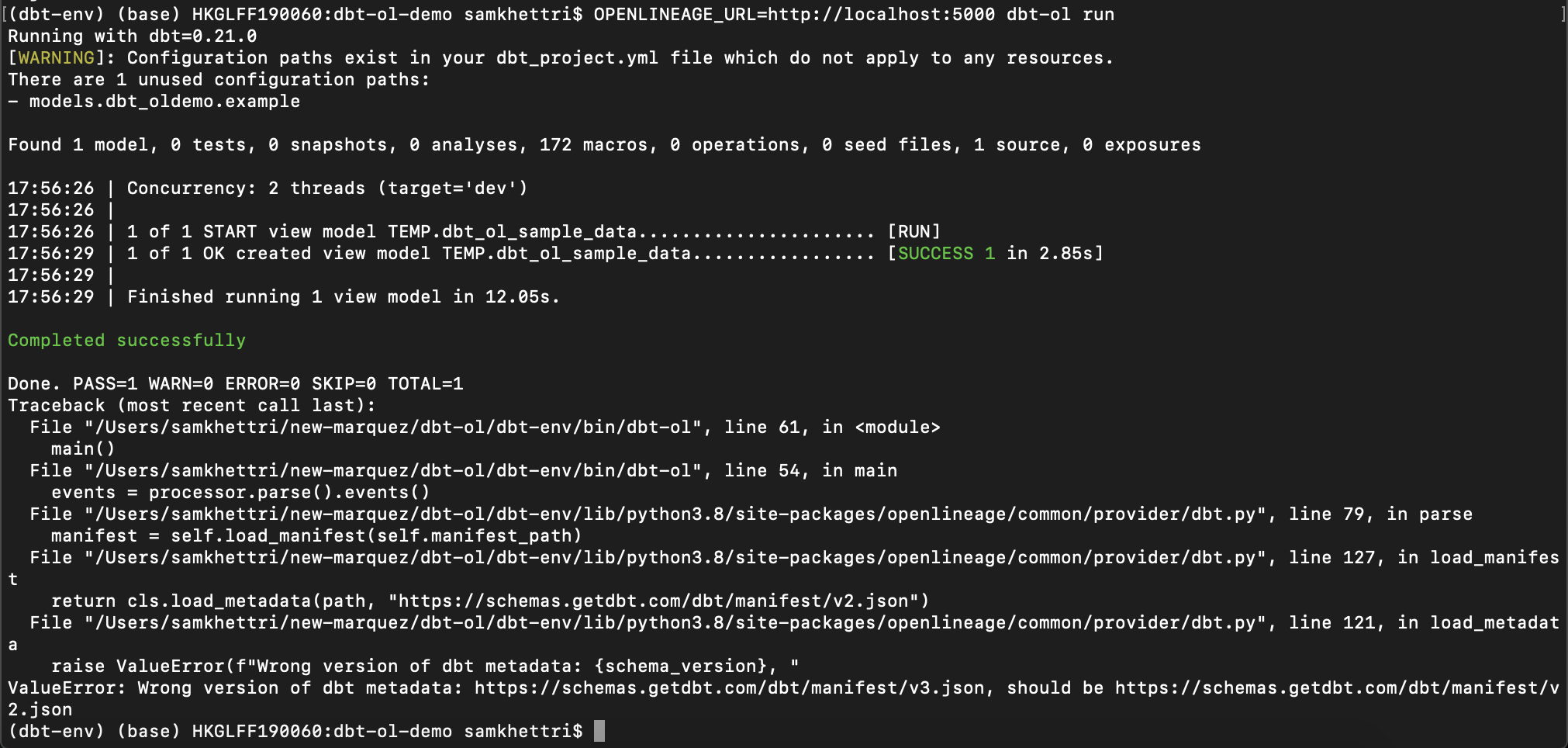 +
+  +
+ 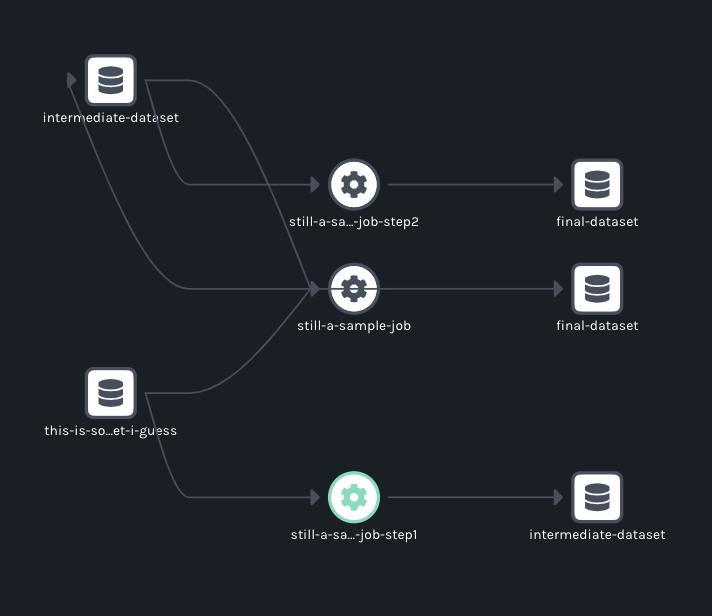 +
+ 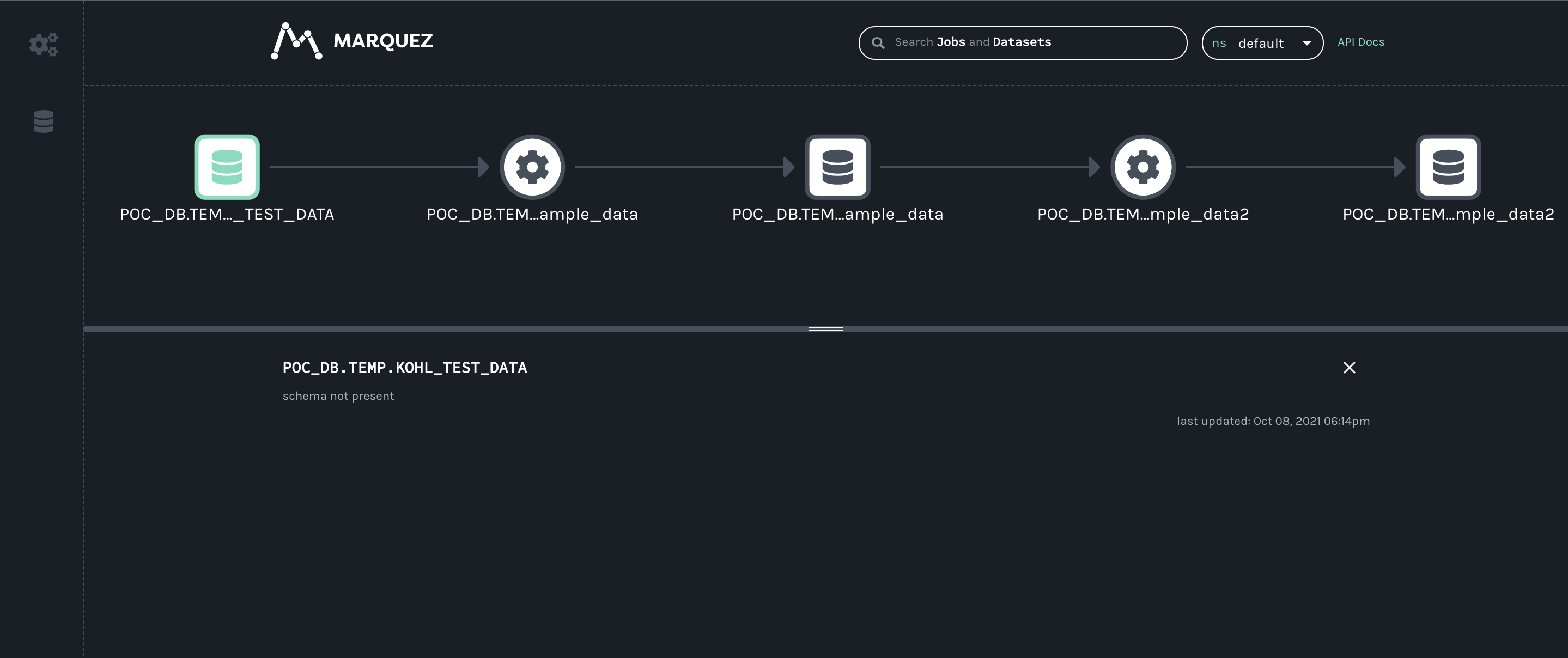 +
+  +
+  +
+ 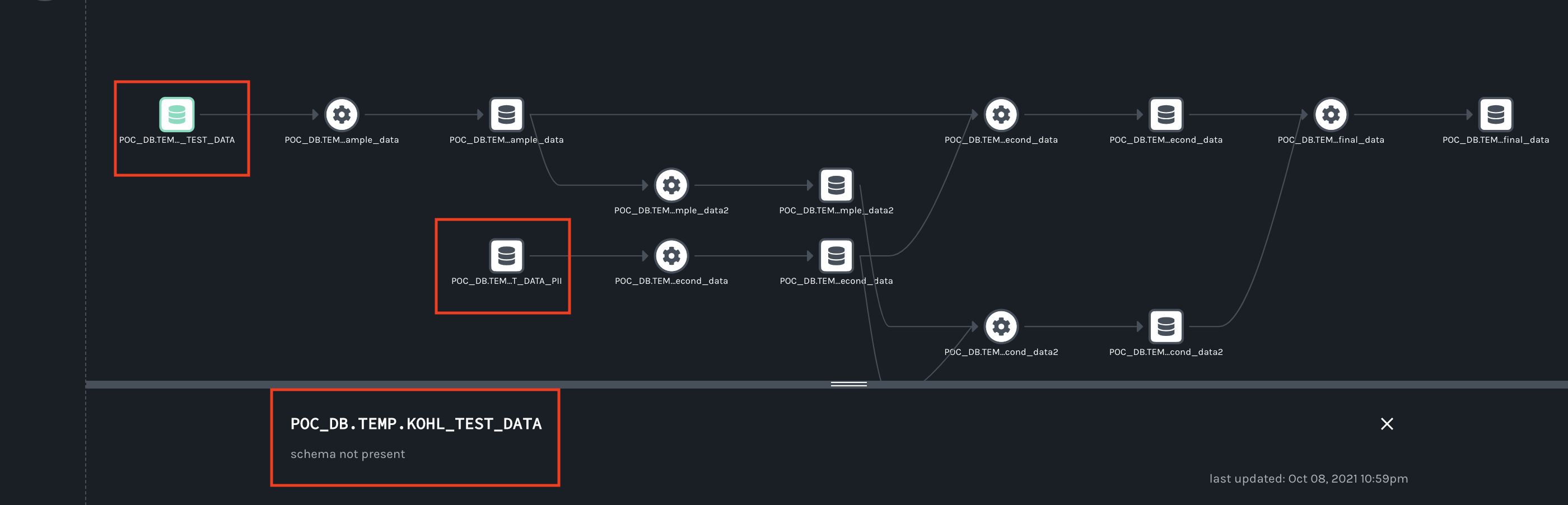 +
+ 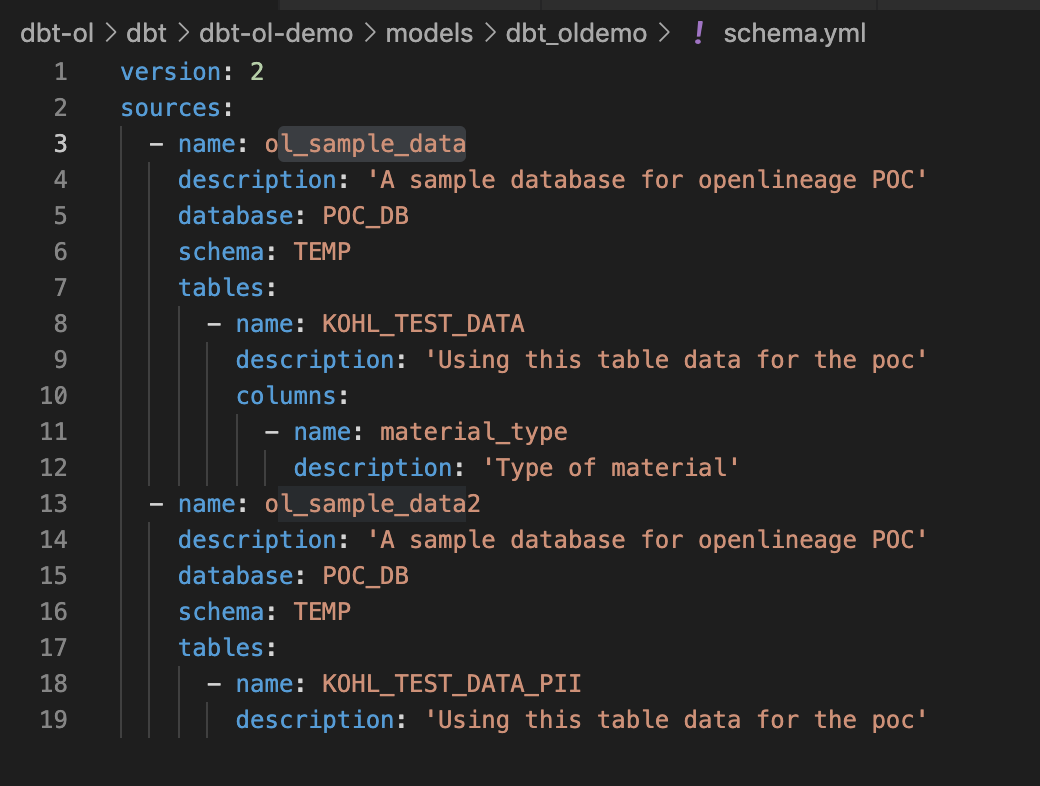 +
+ 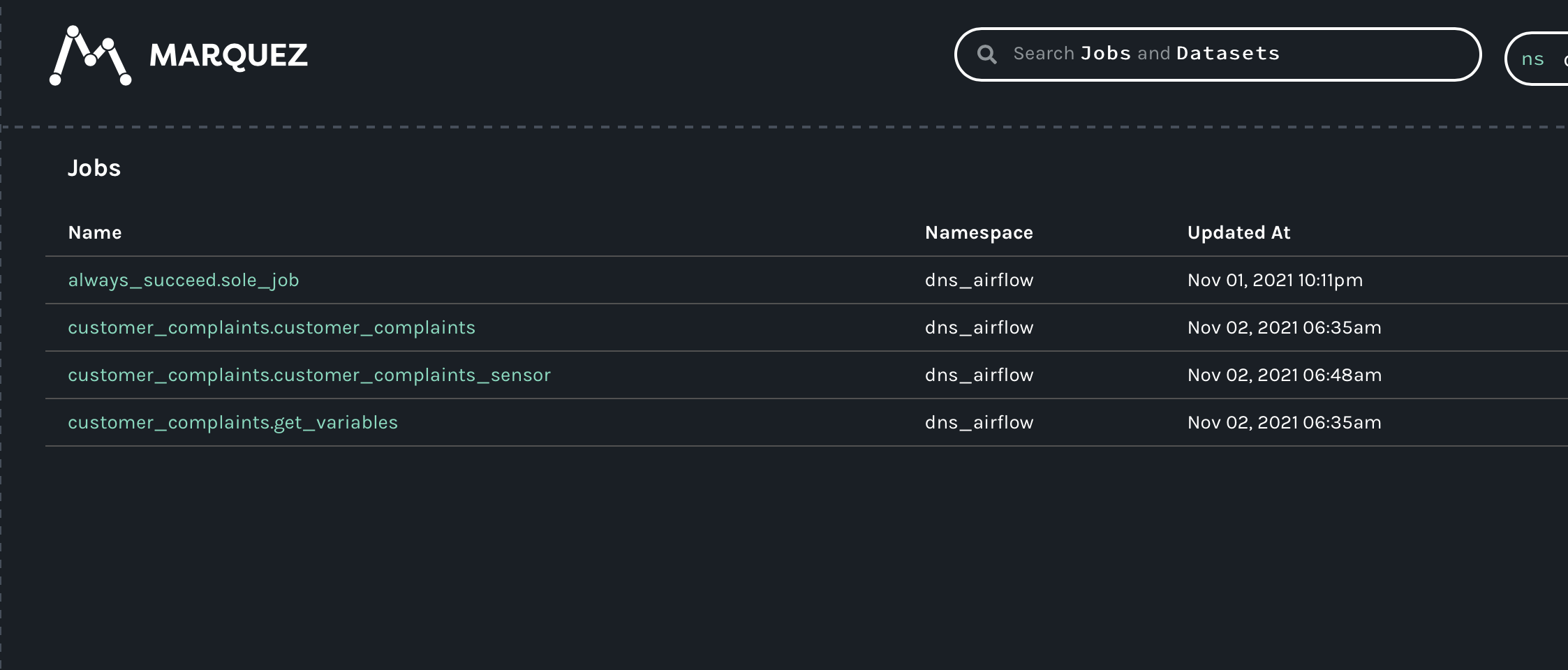 +
+ 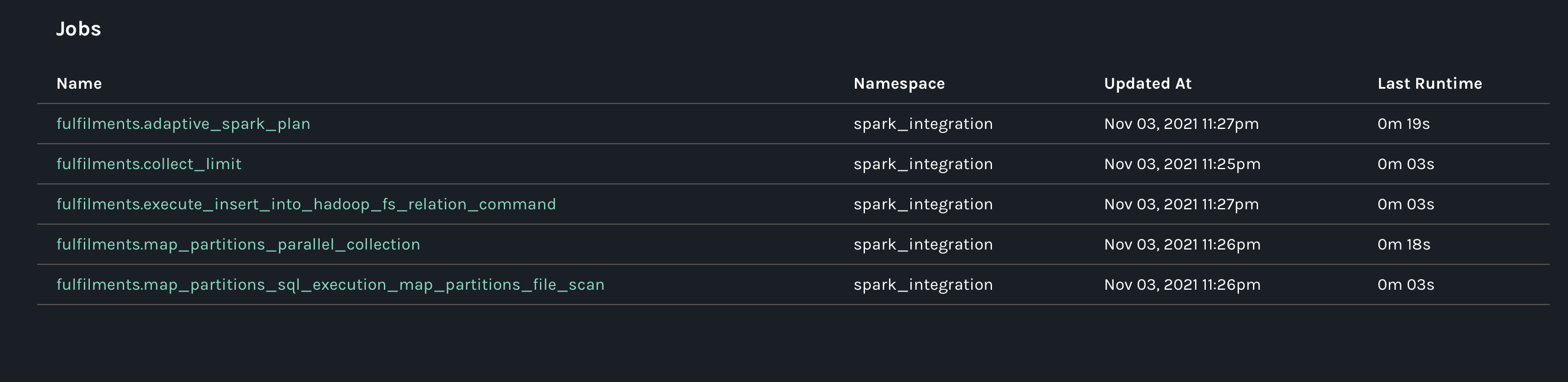 +
+  +
+  +
+ 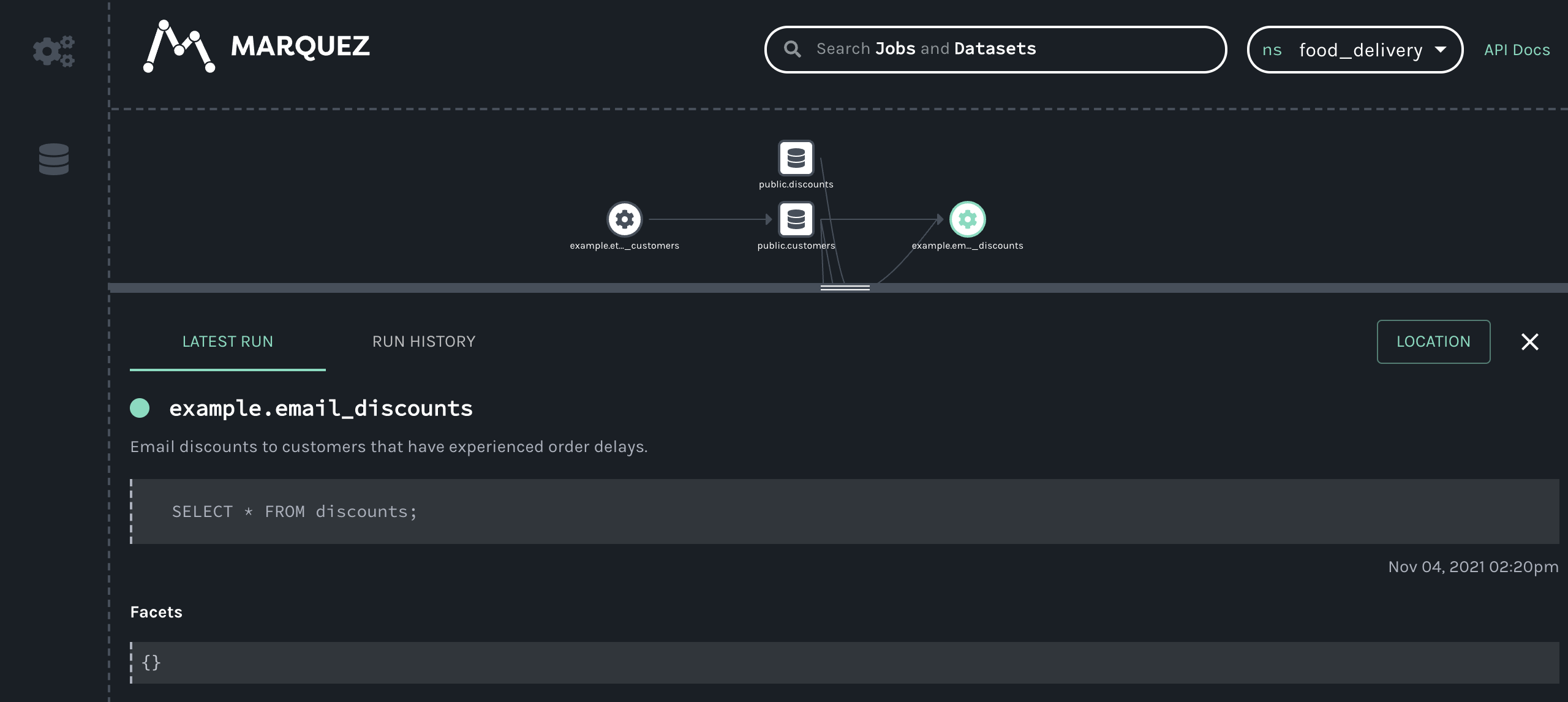 +
+ 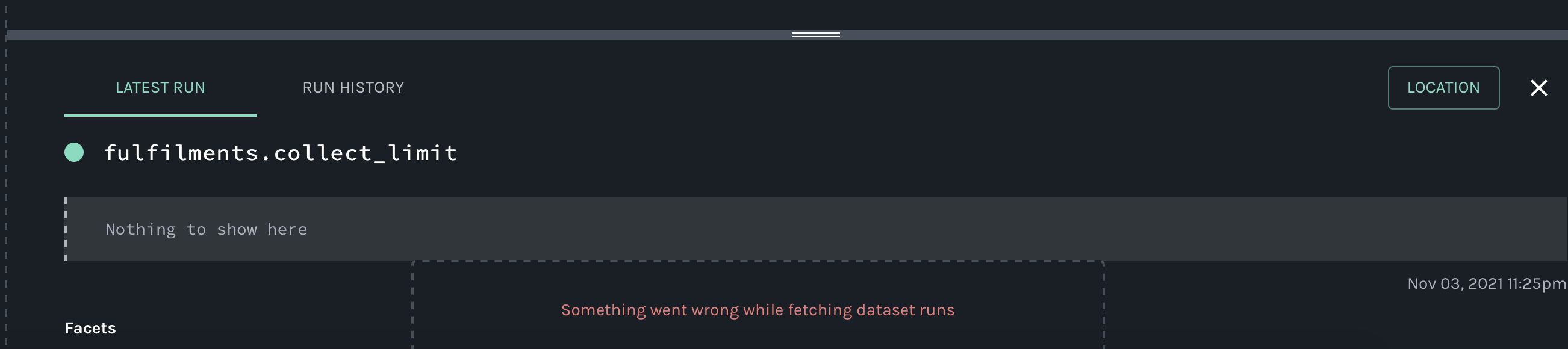 +
+  +
+  +
+  +
+  +
+ 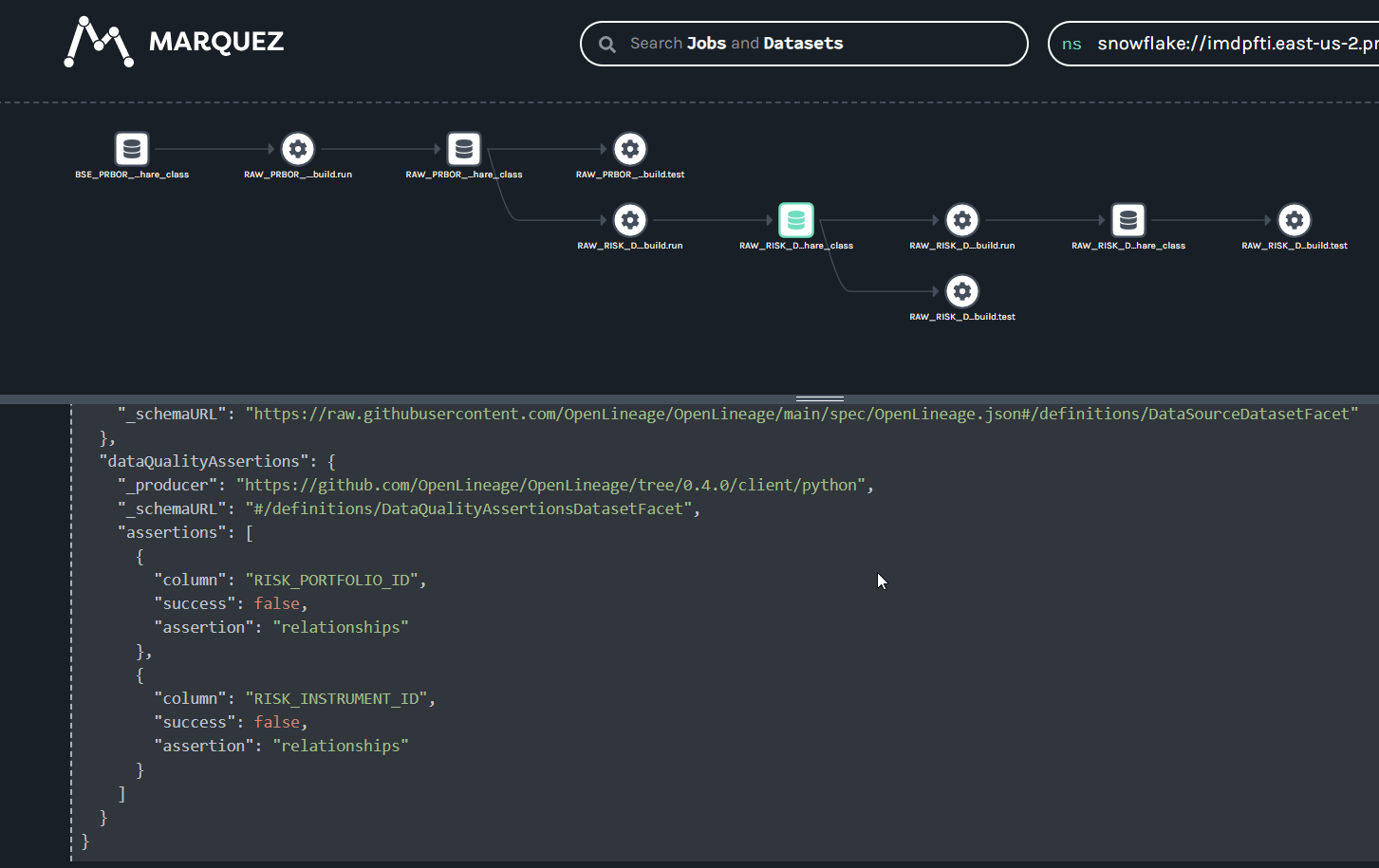 +
+ 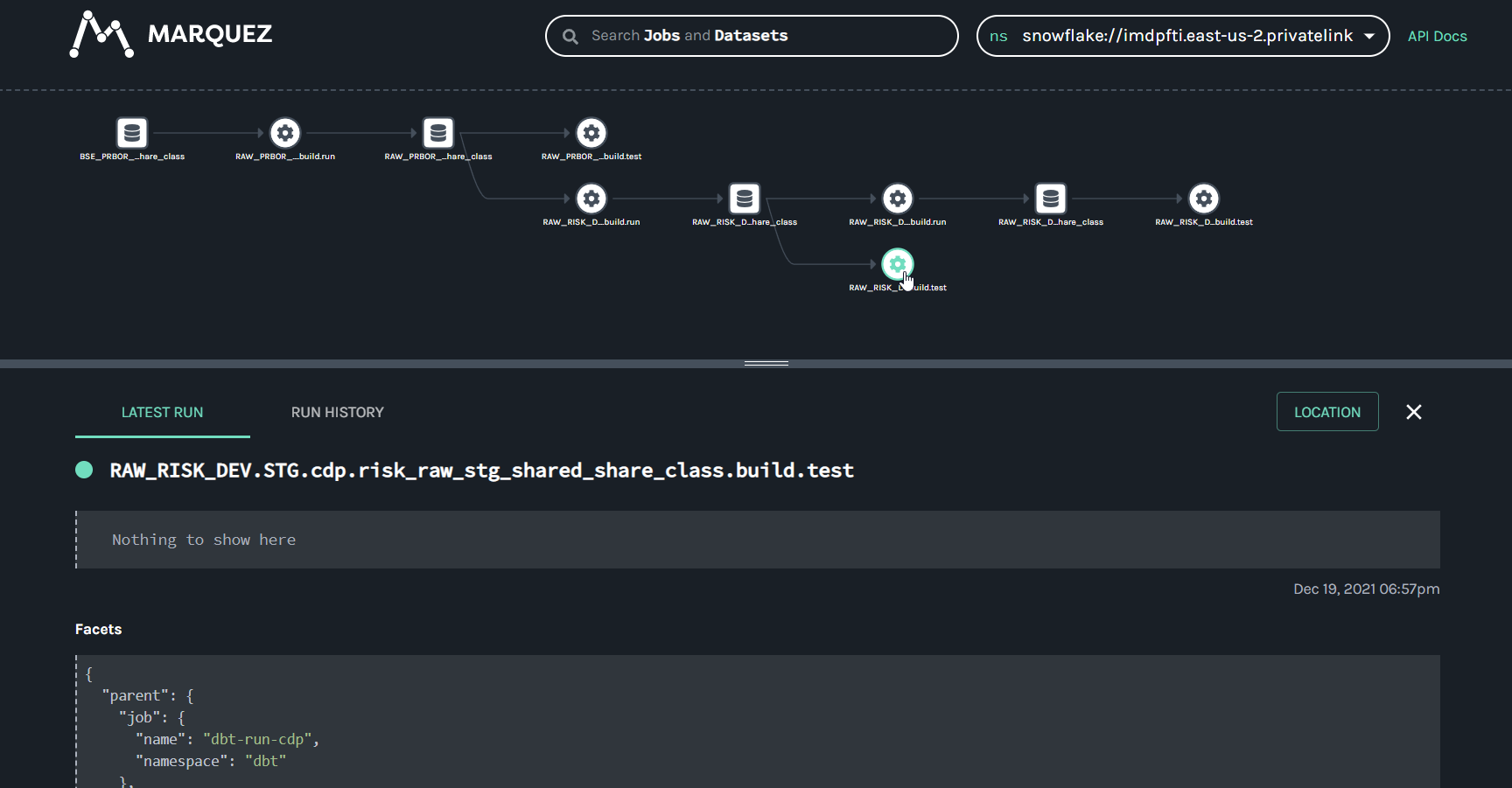 +
+ 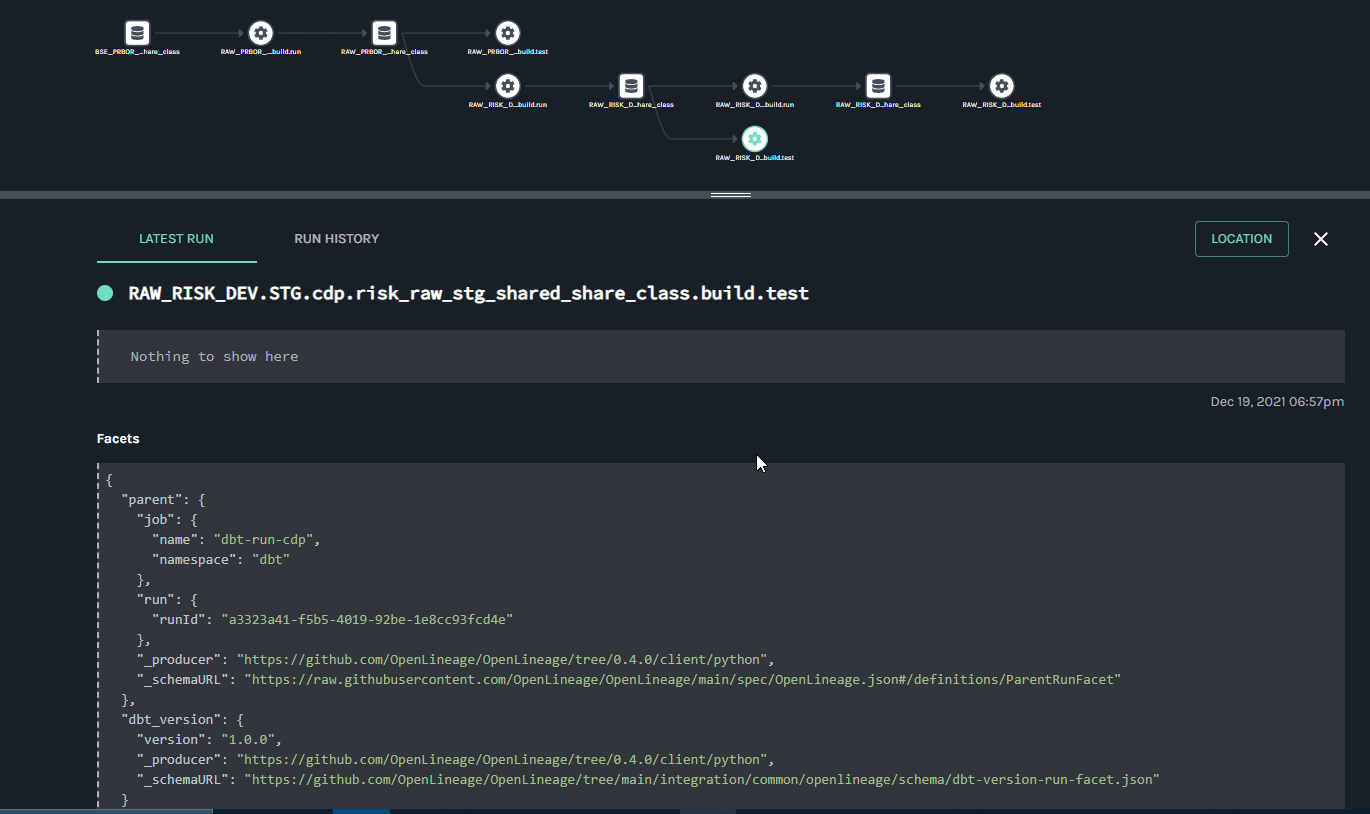 +
+ 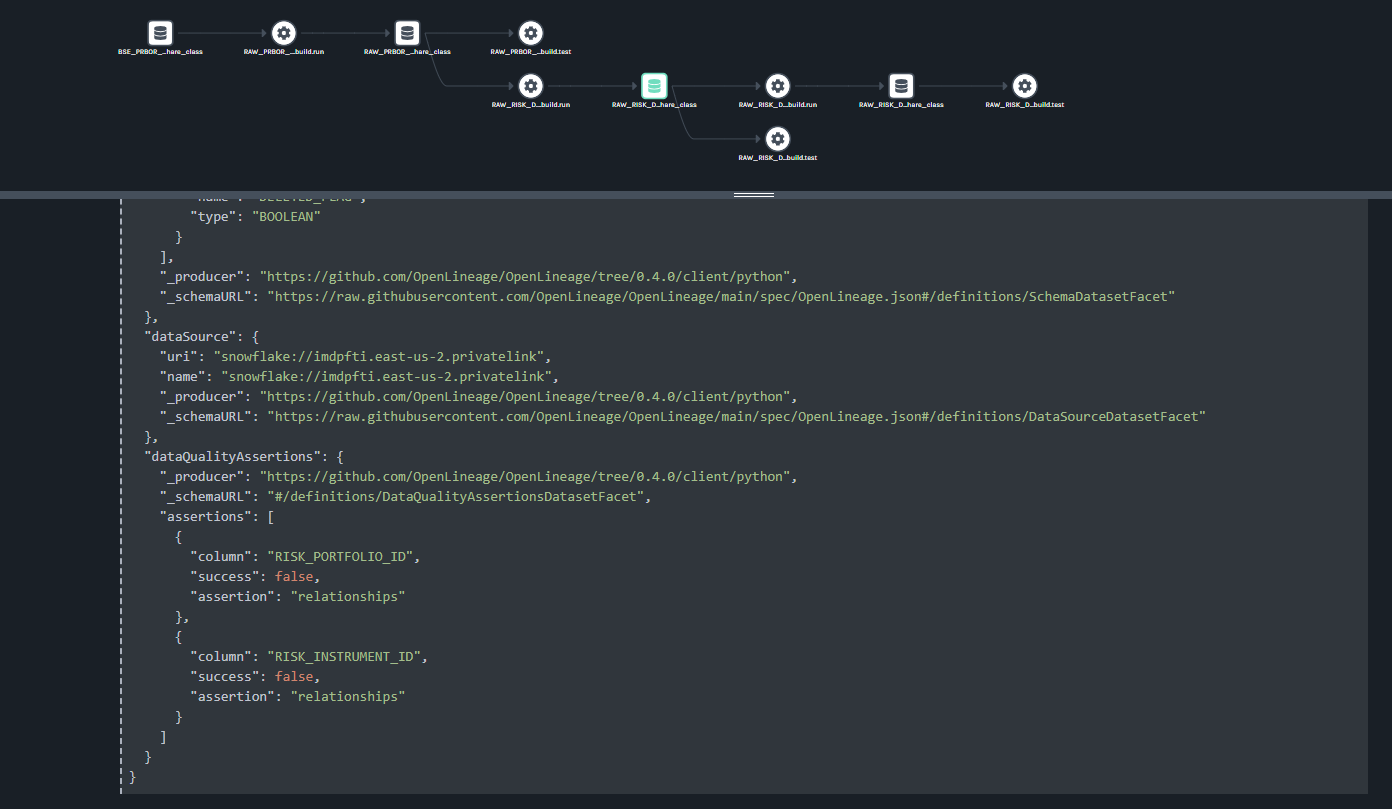 +
+ 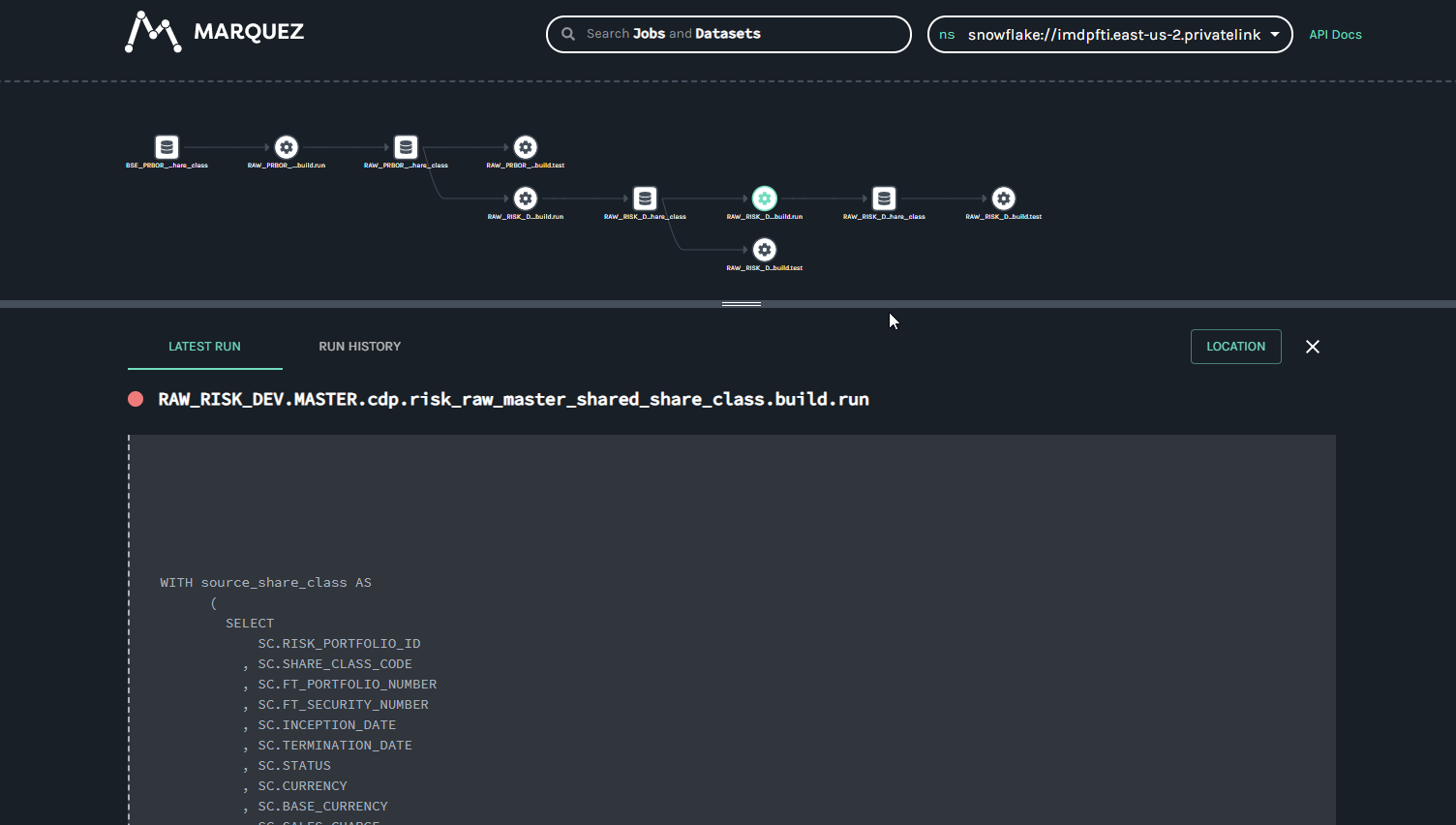 +
+ 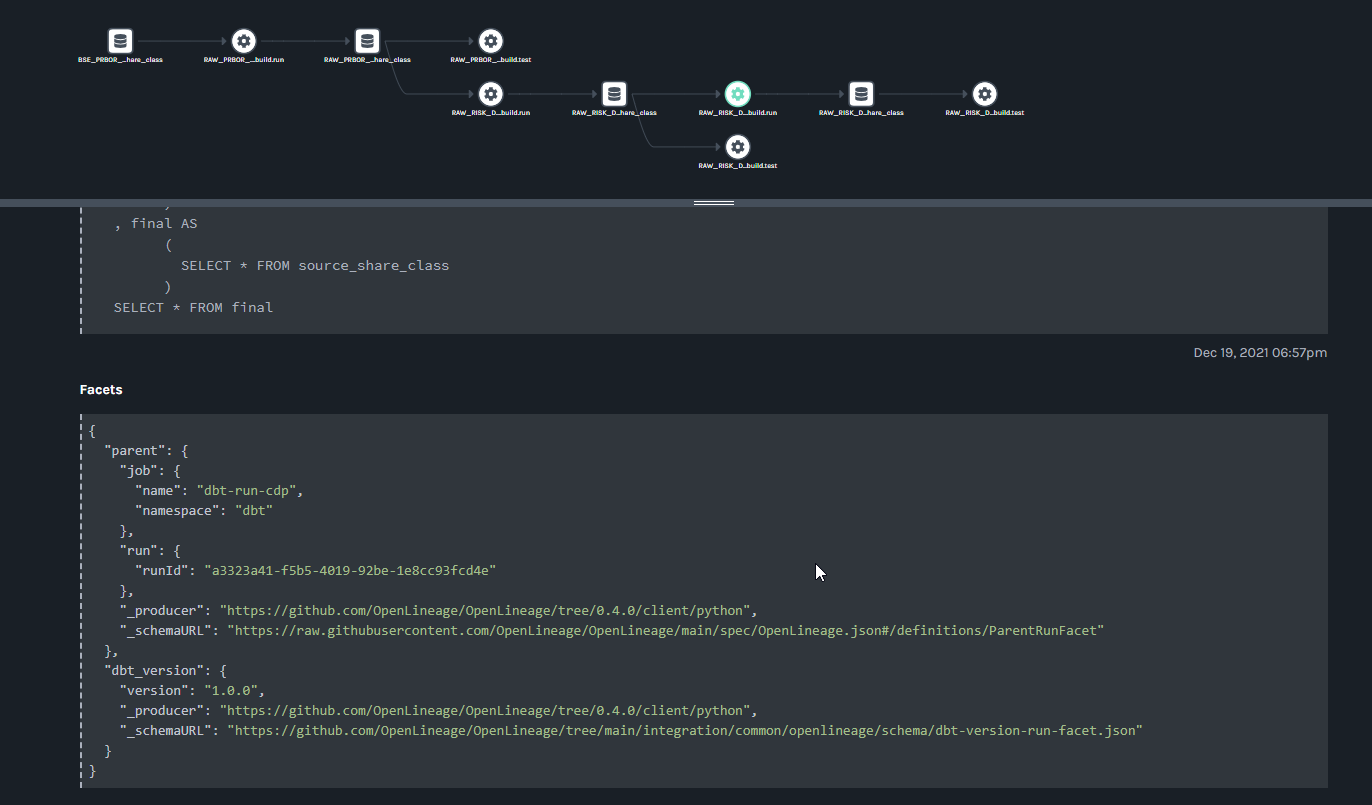 +
+ 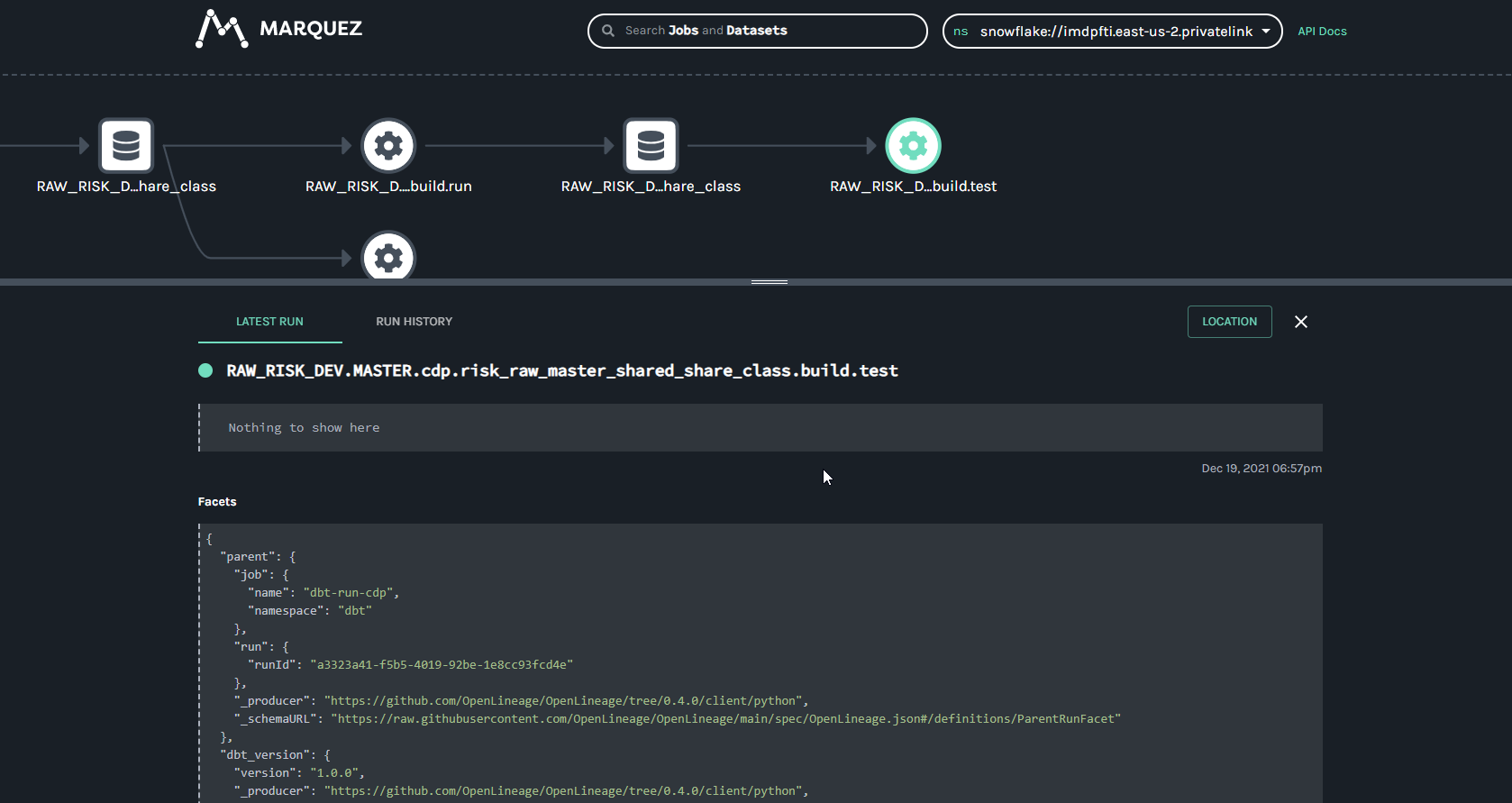 +
+ 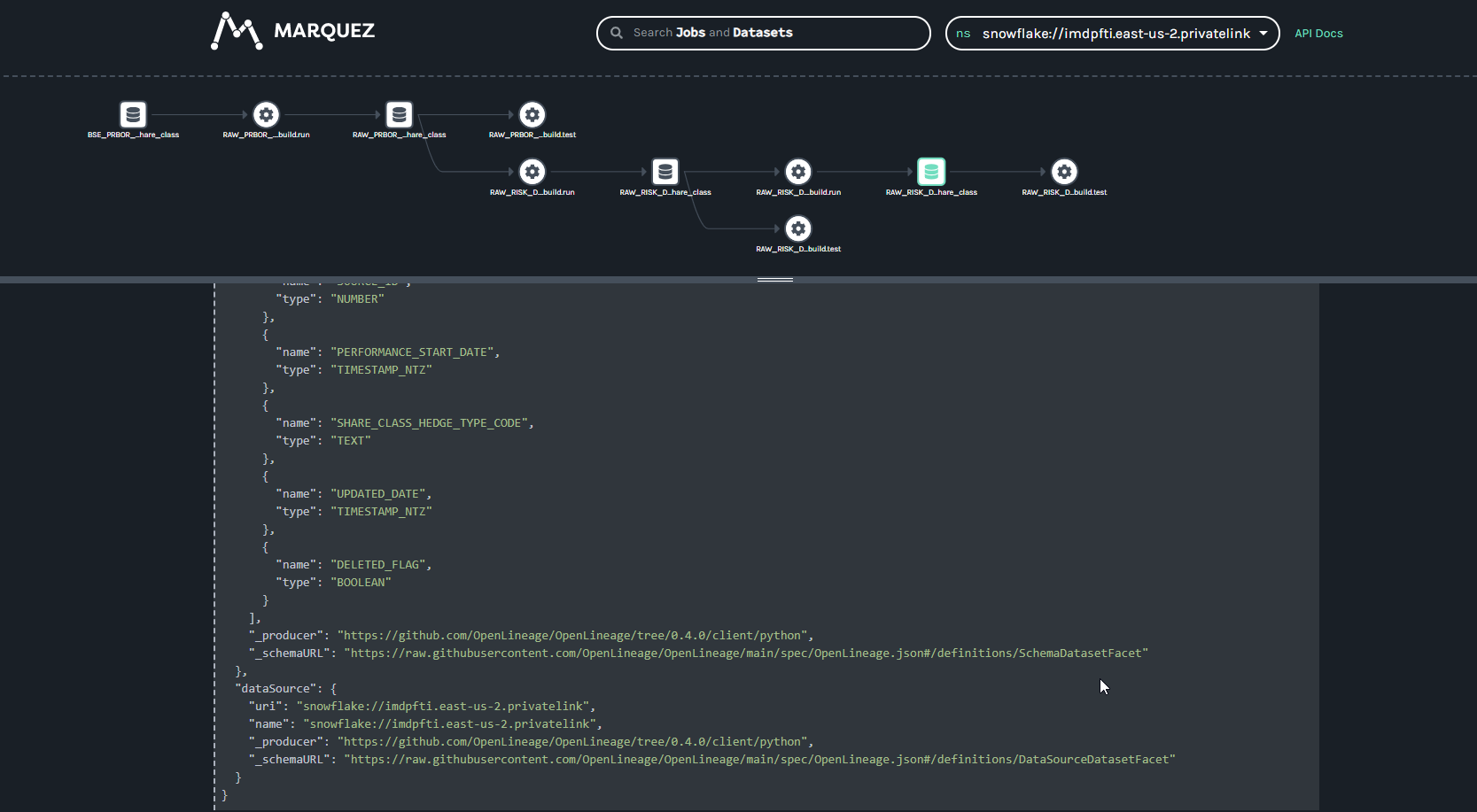 +
+  +
+ 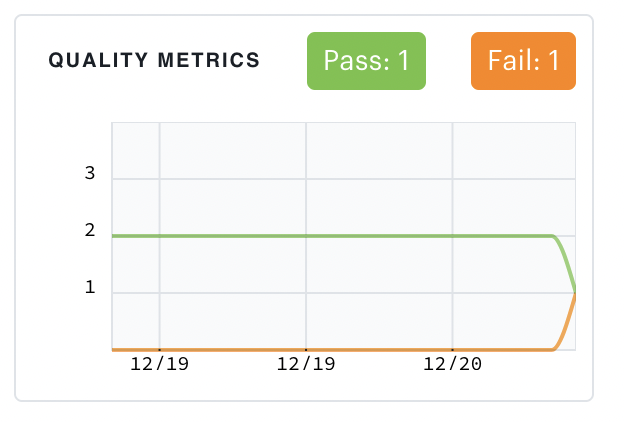 +
+  +
+  +
+  +
+  +
+ 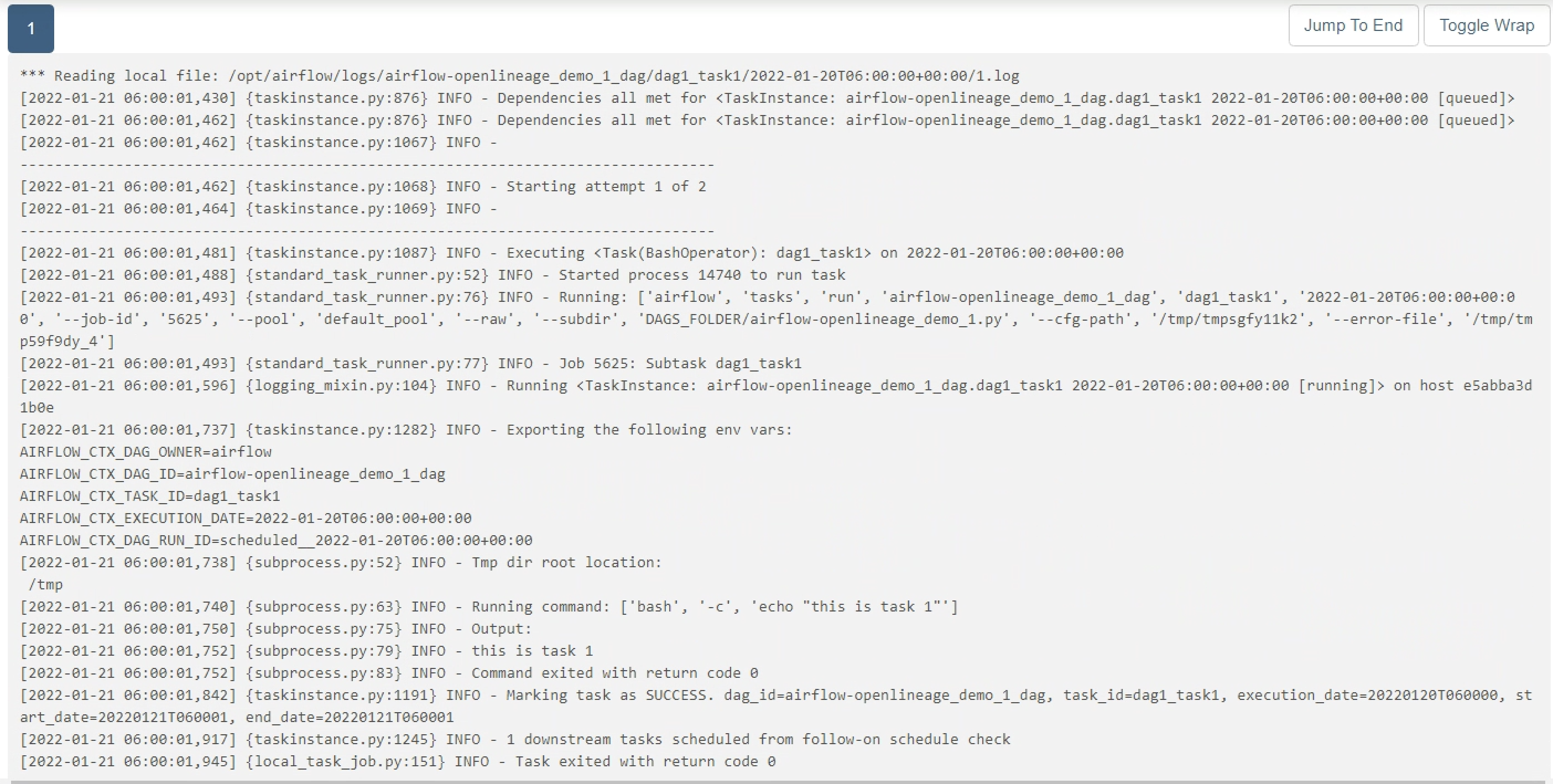 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ 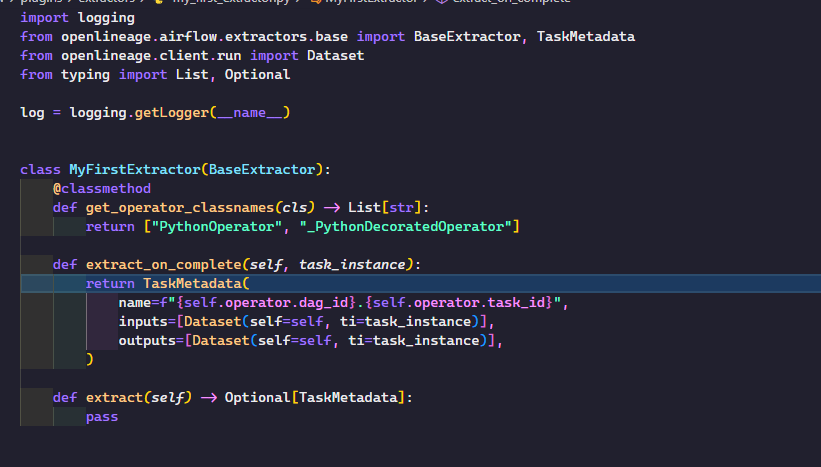 +
+  +
+ 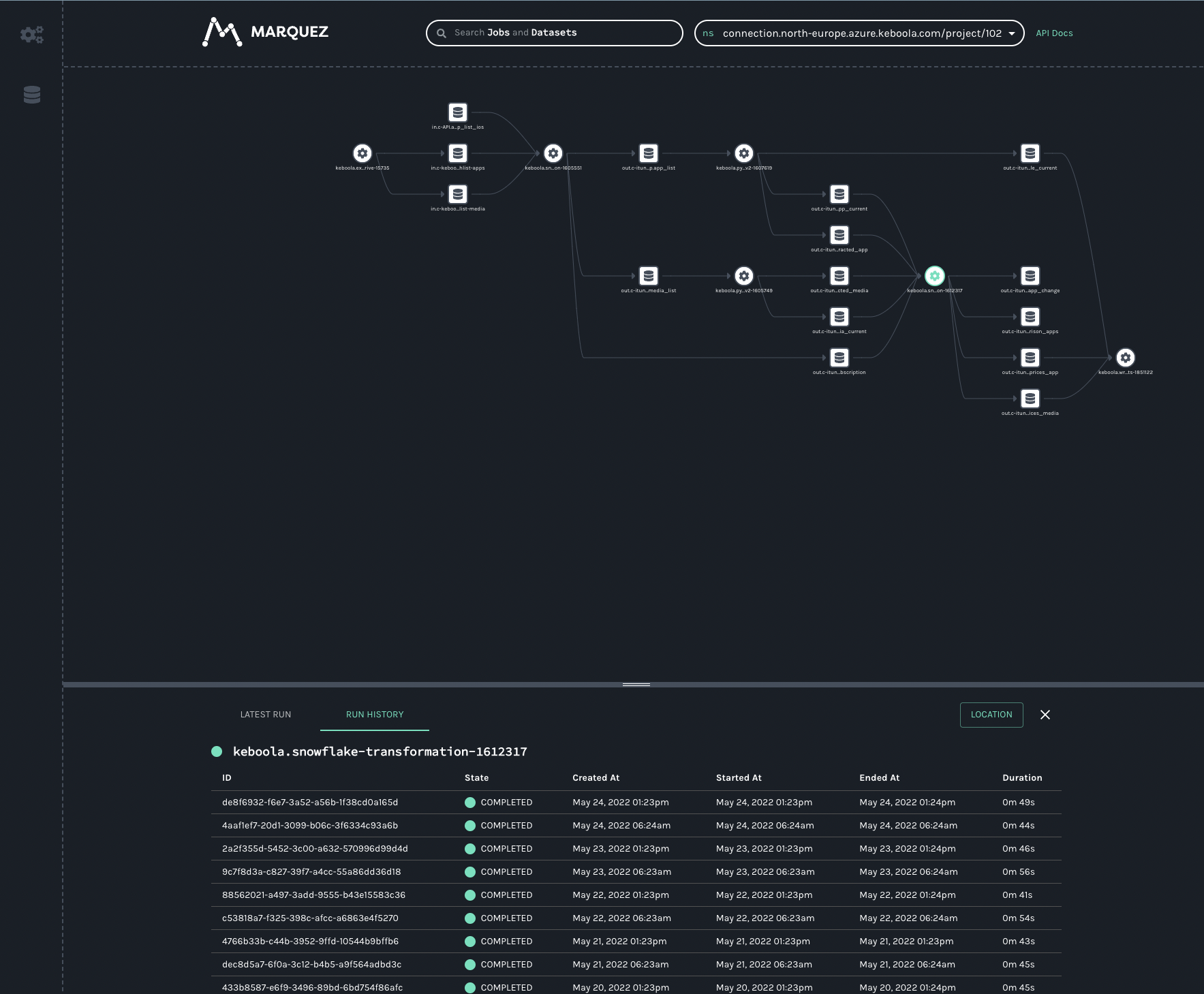 +
+  +
+ 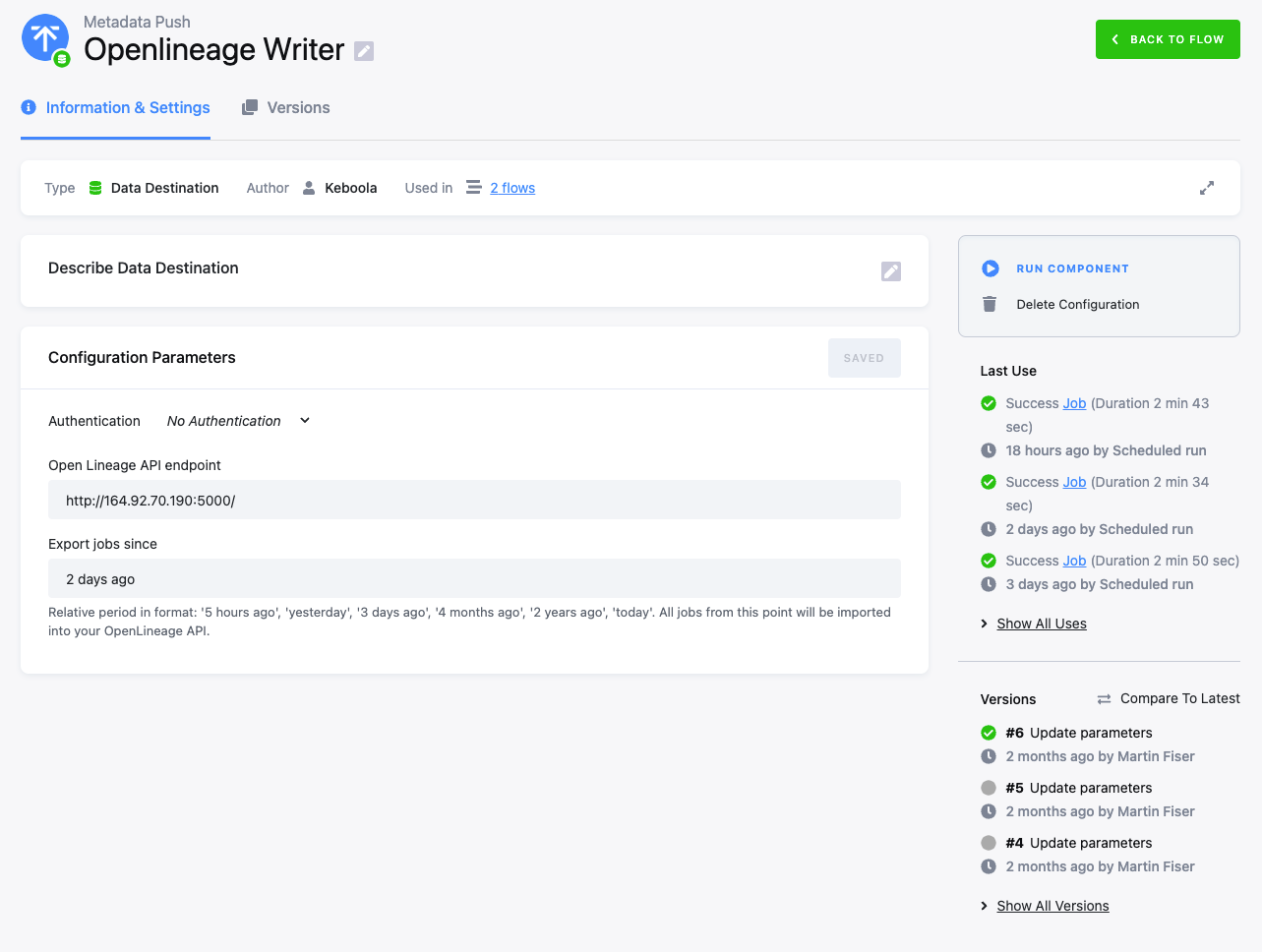 +
+ 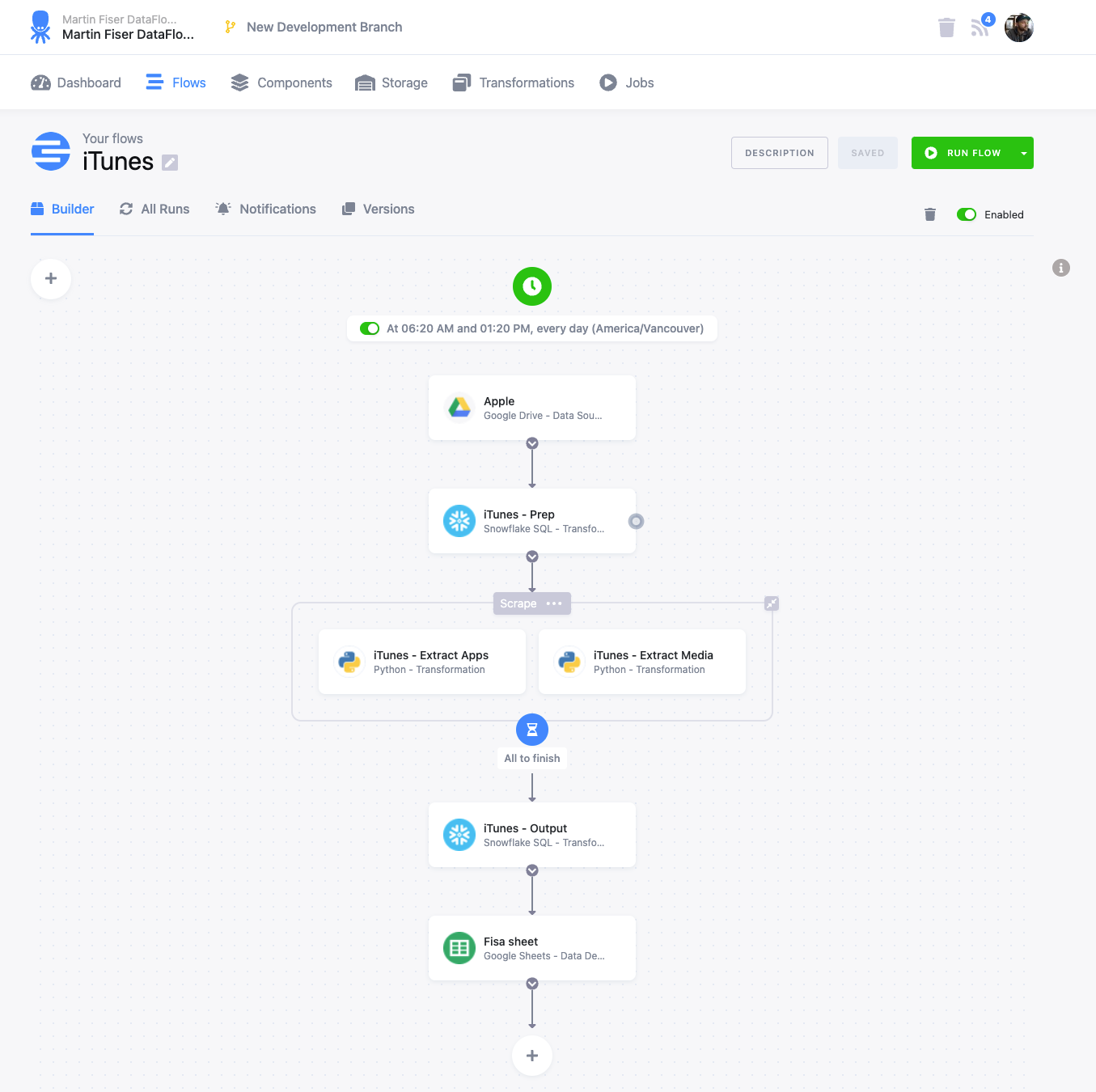 +
+  +
+  +
+  +
+ 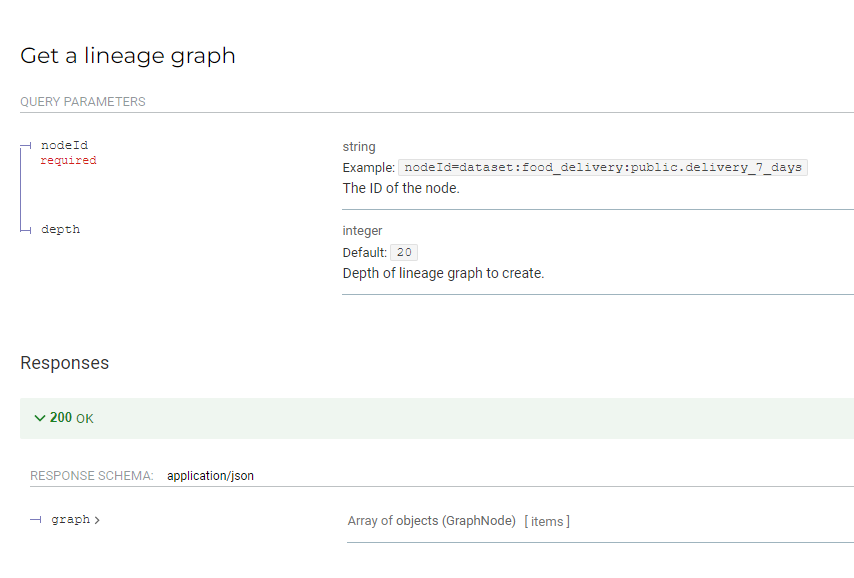 +
+ 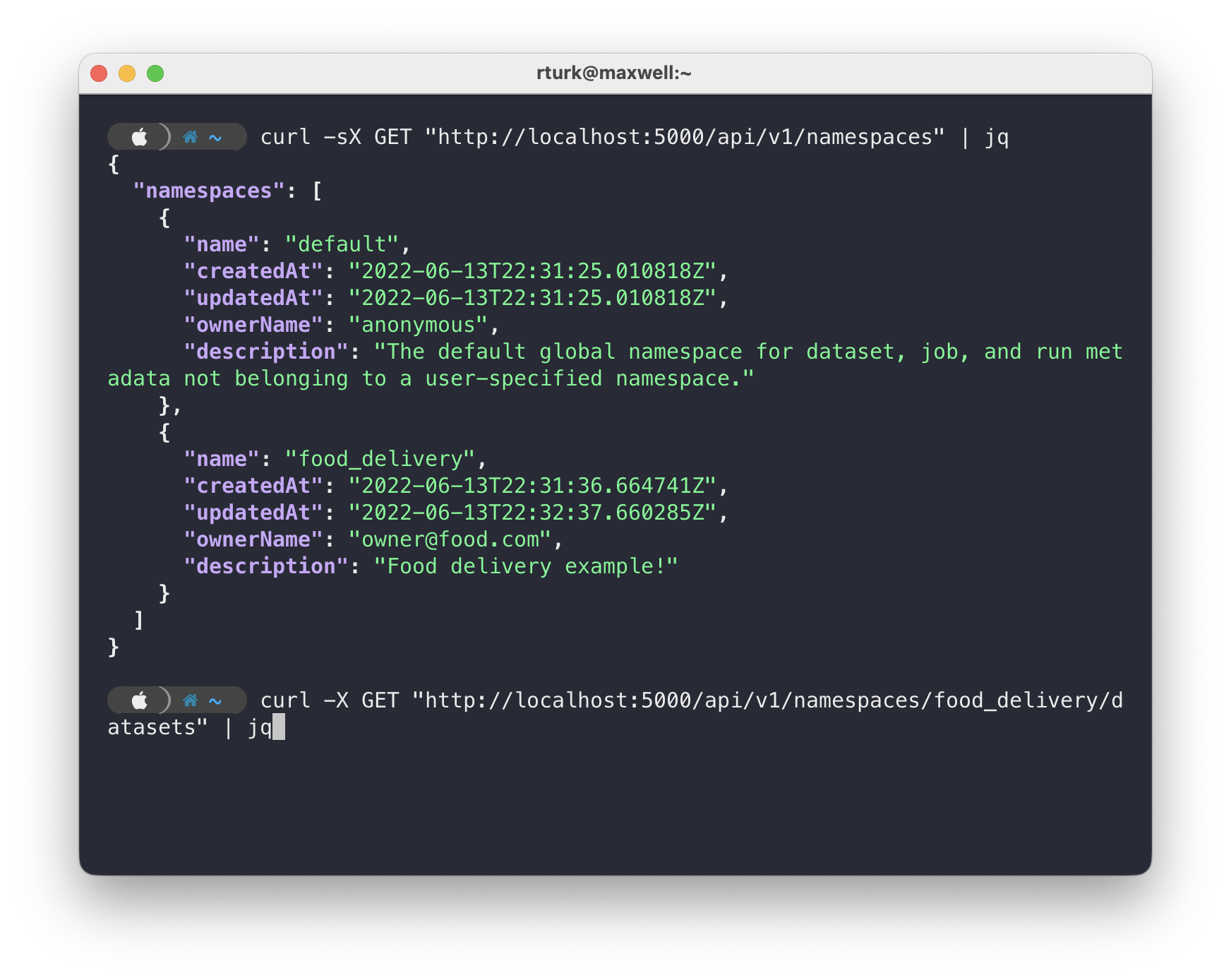 +
+ 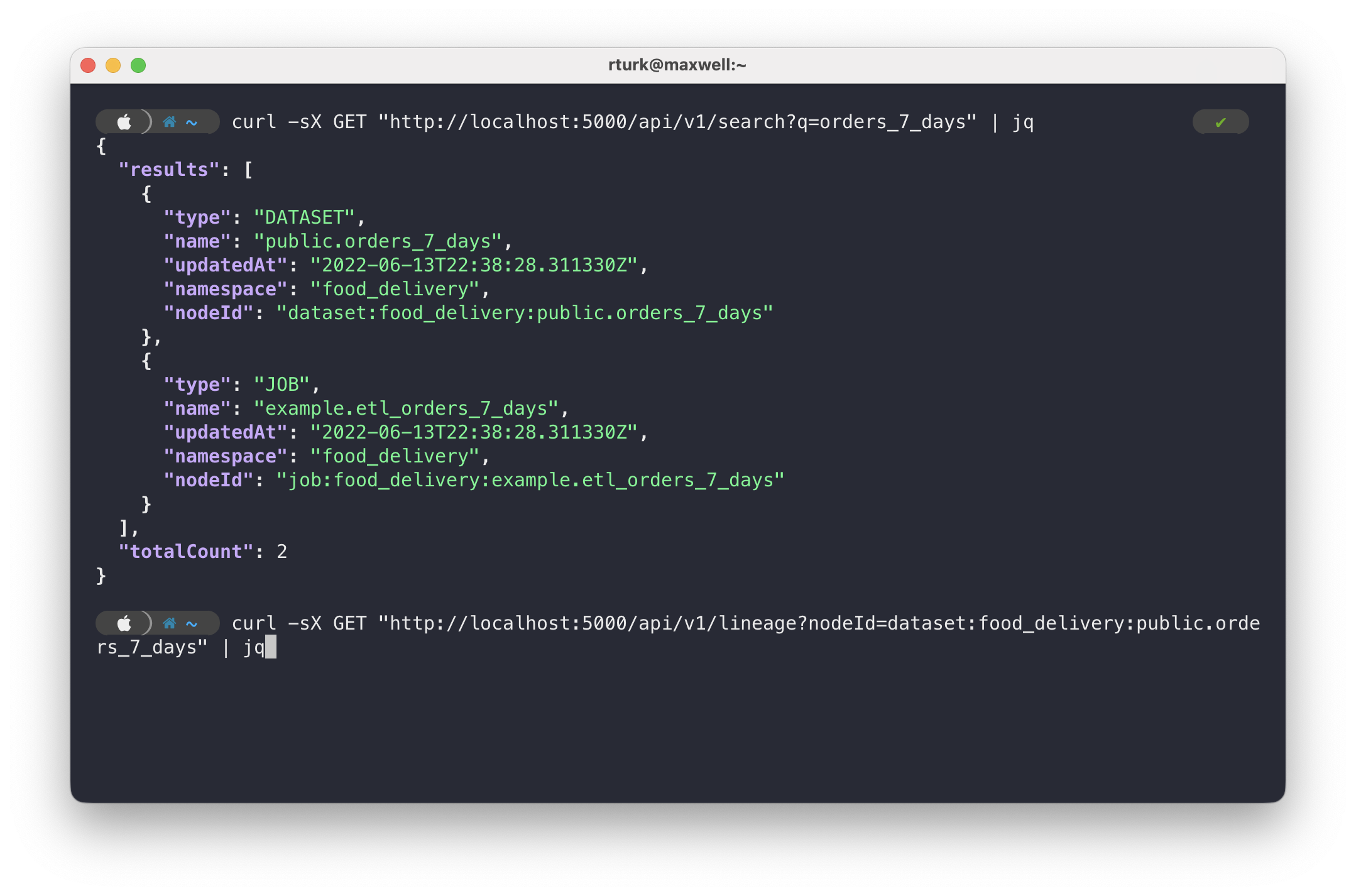 +
+  +
+  +
+  +
+  +
+ 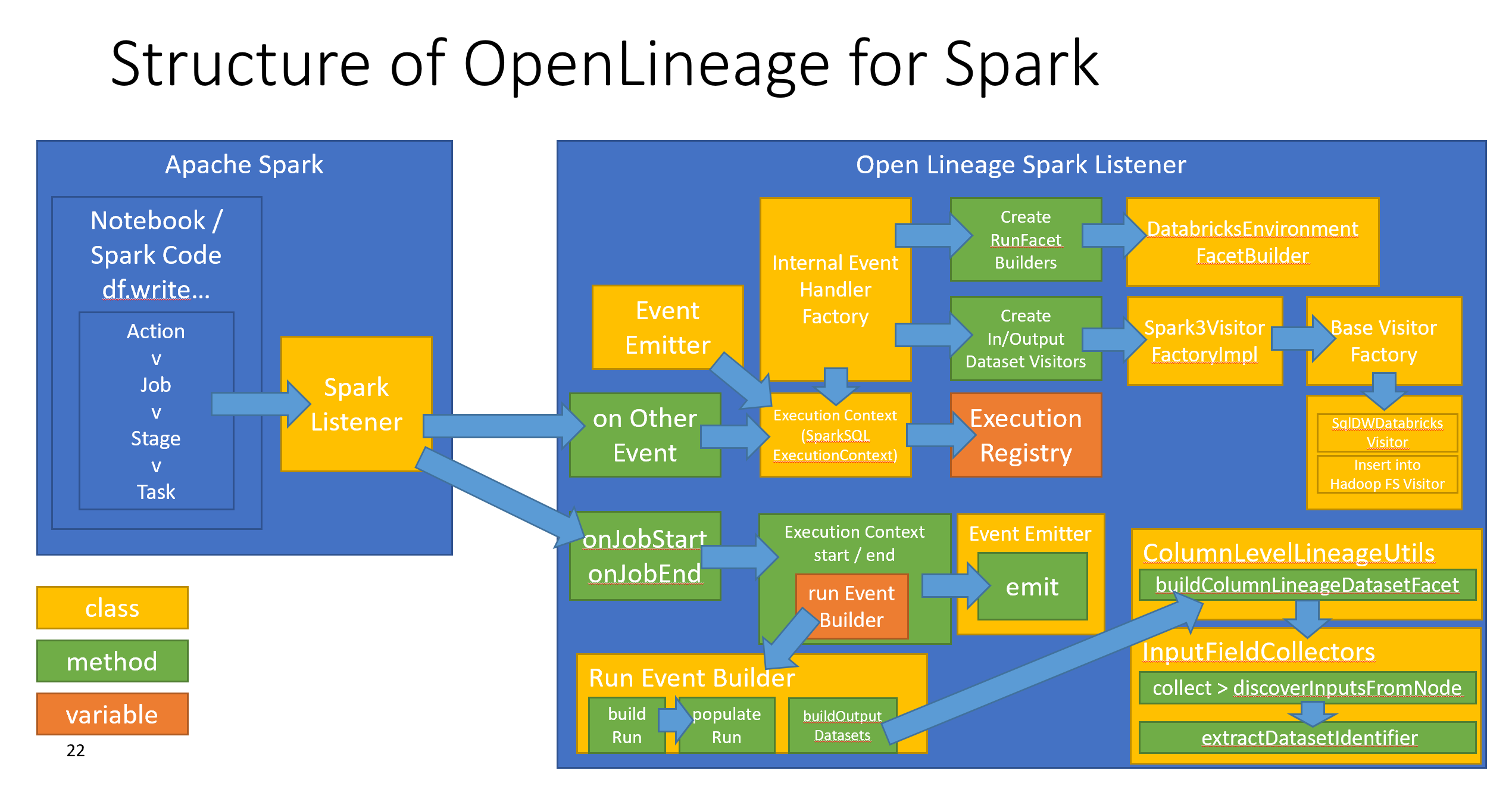 +
+  +
+  +
+ 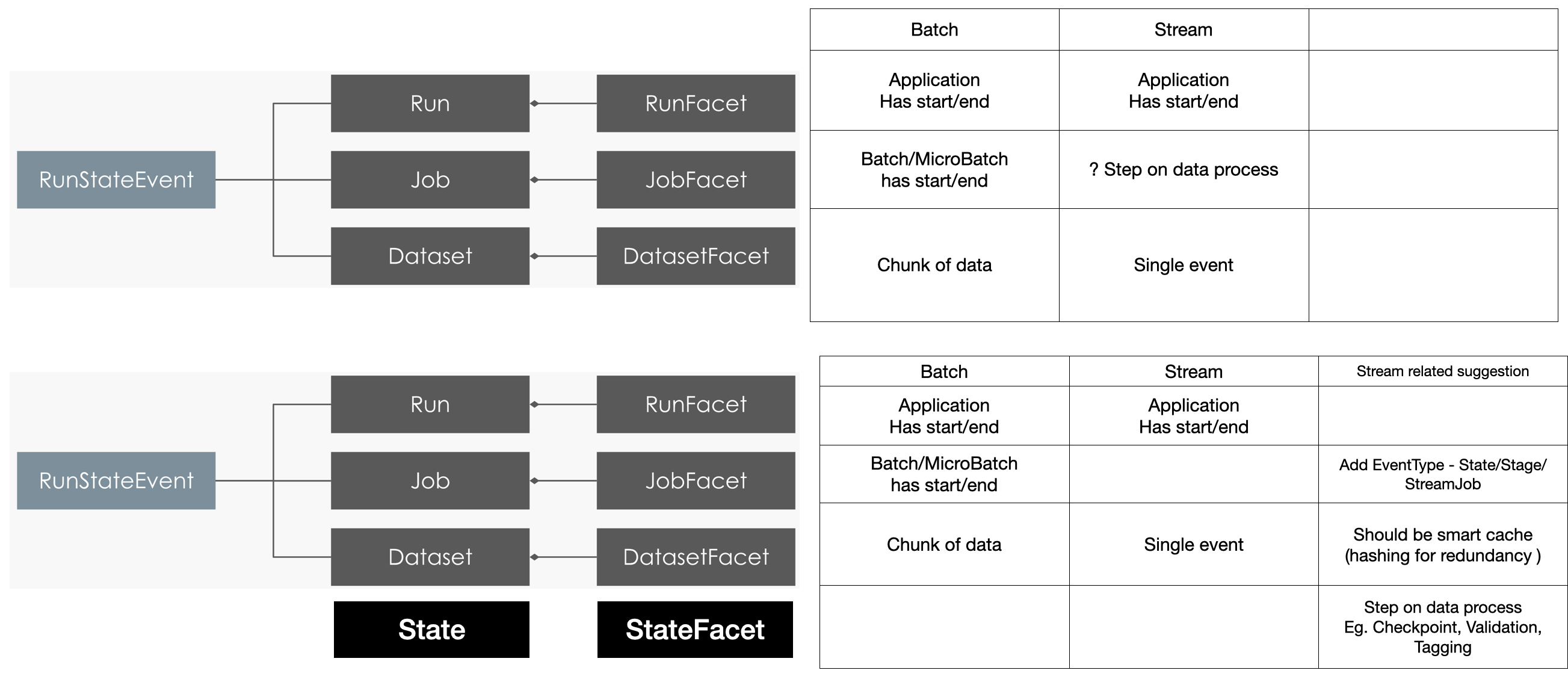 +
+ 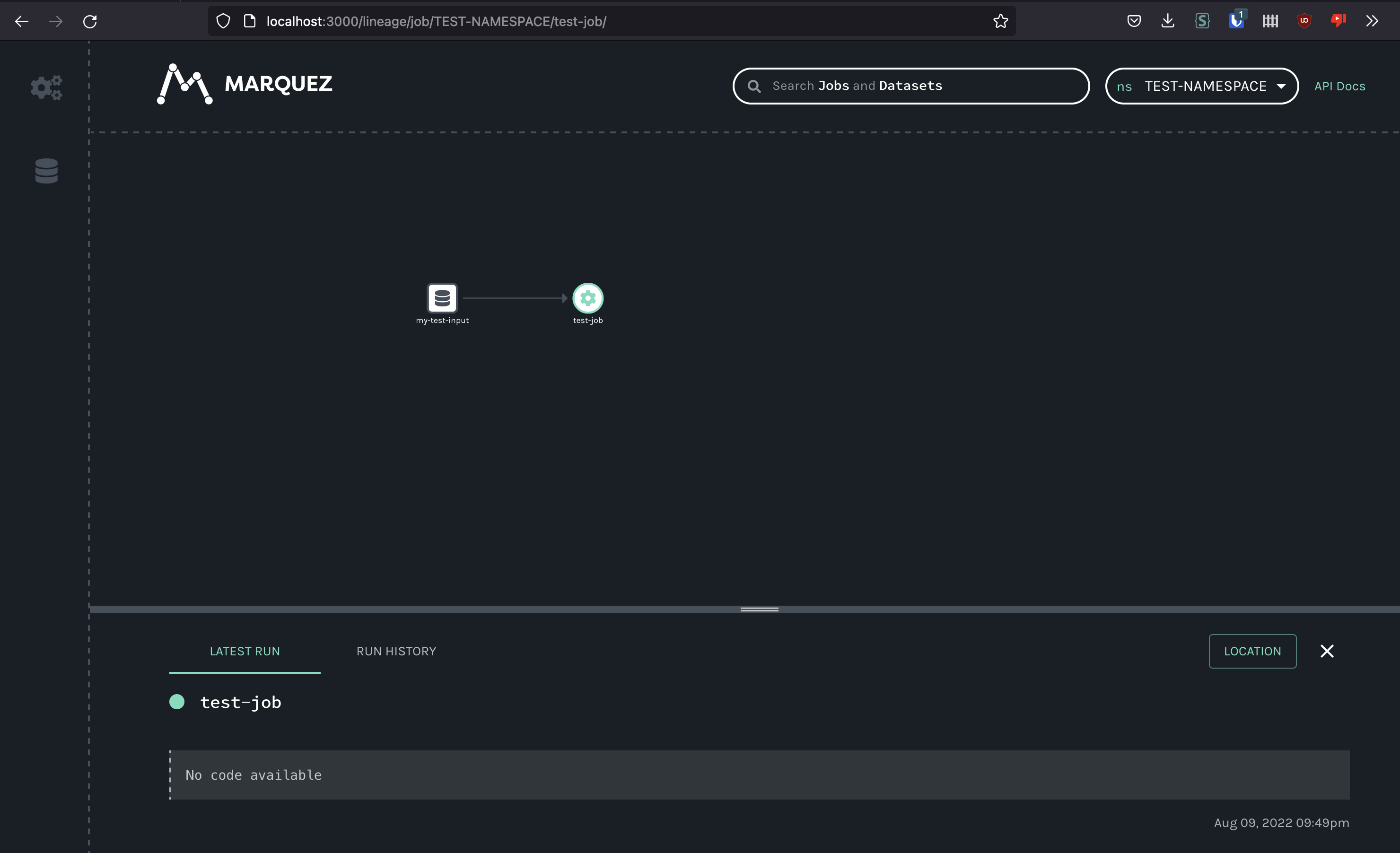 +
+ 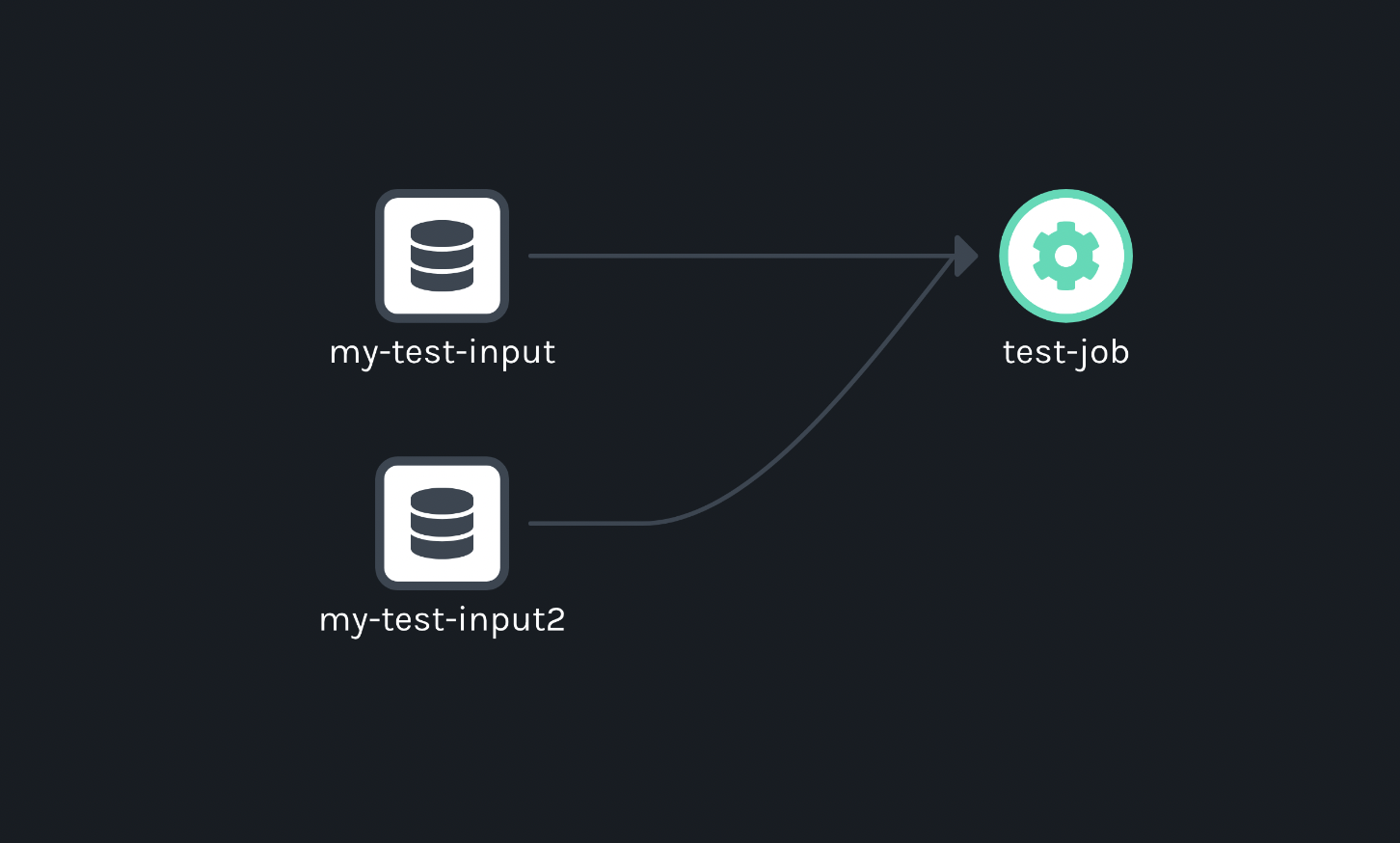 +
+  +
+ 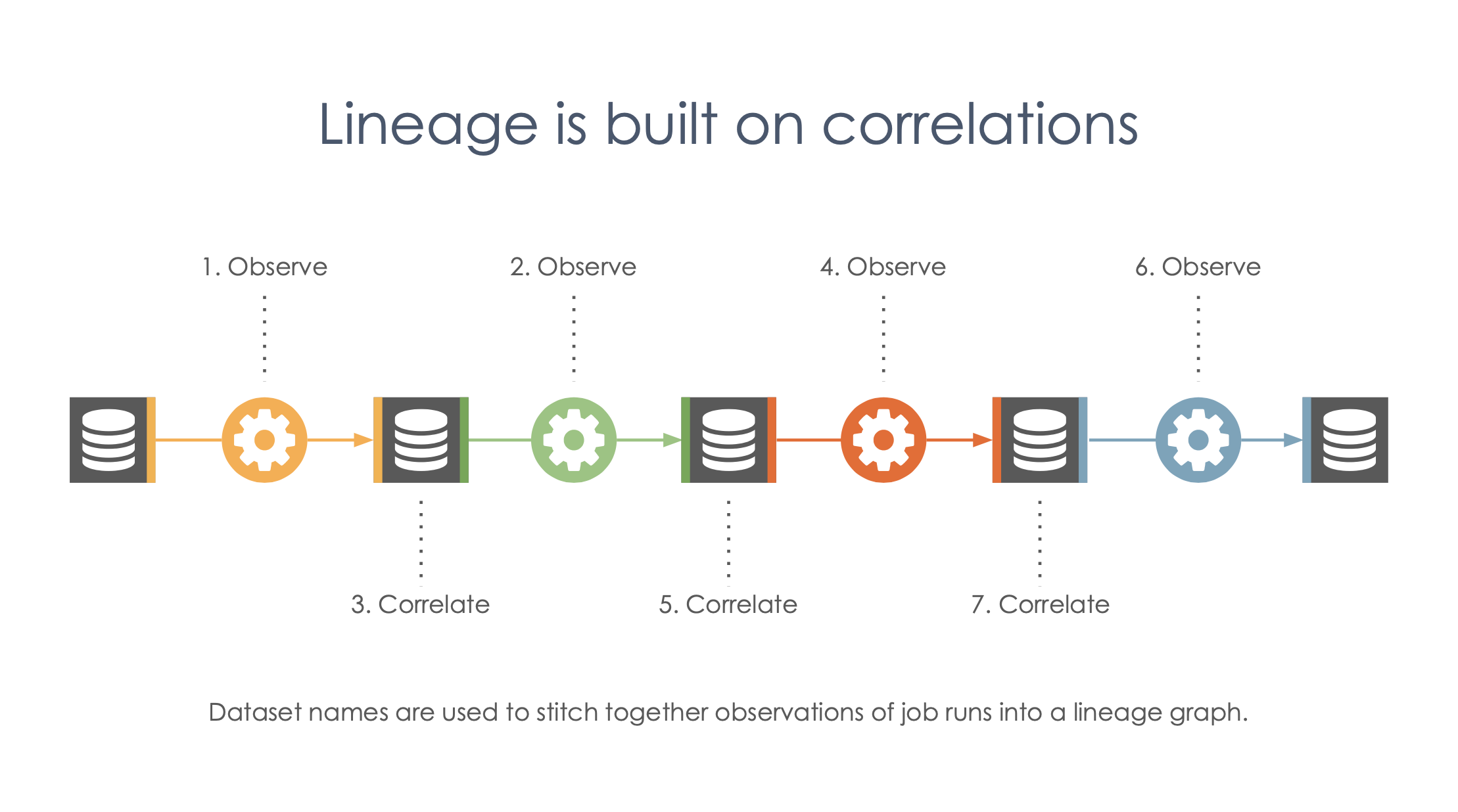 +
+  +
+  +
+  +
+  +
+  +
+ 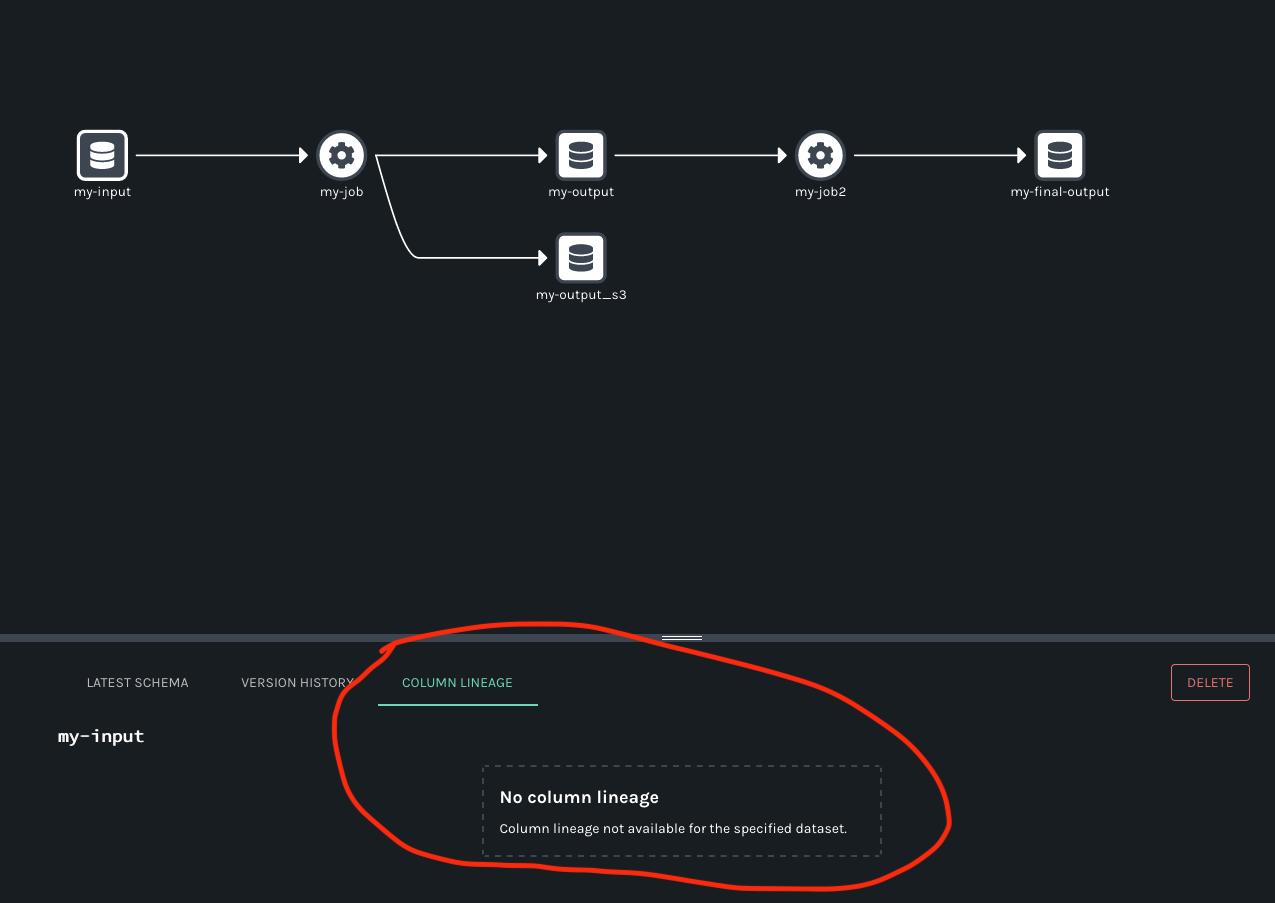 +
+ 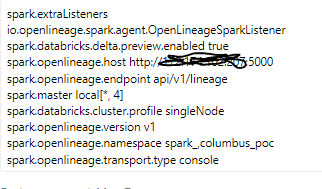 +
+ 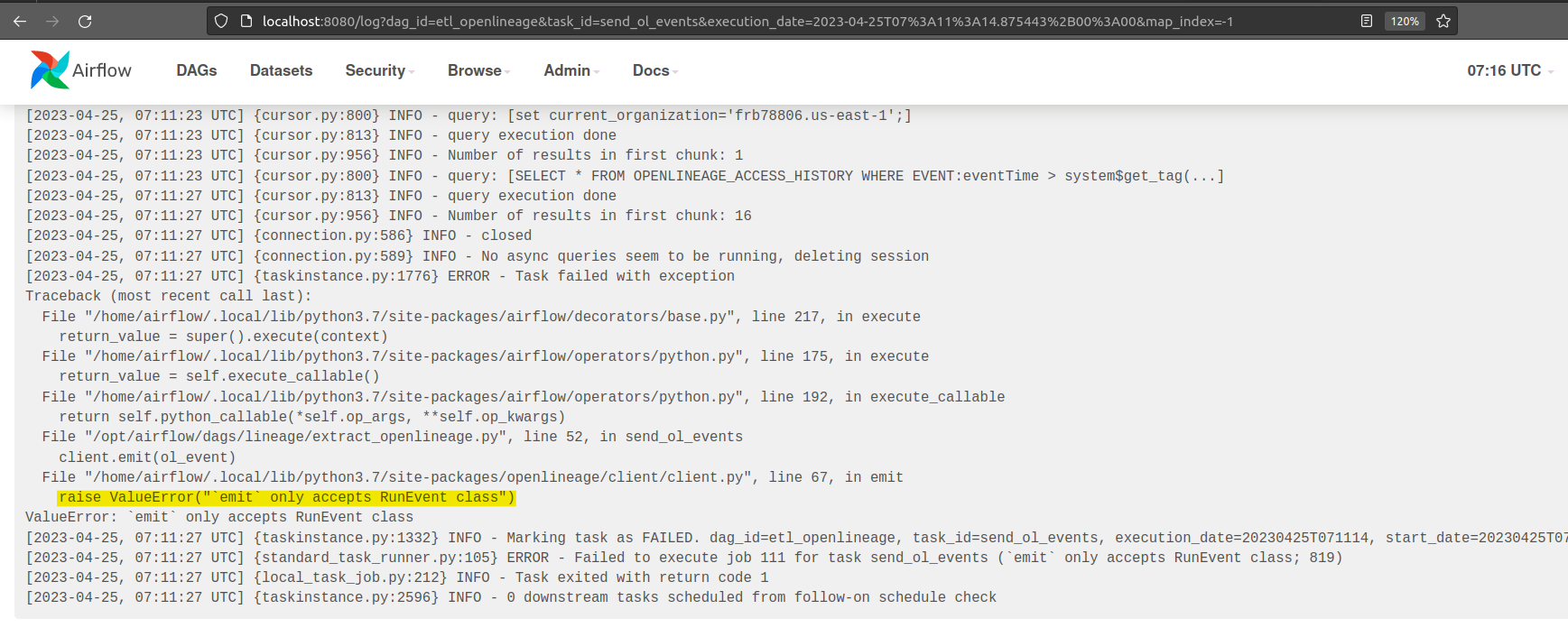 +
+ 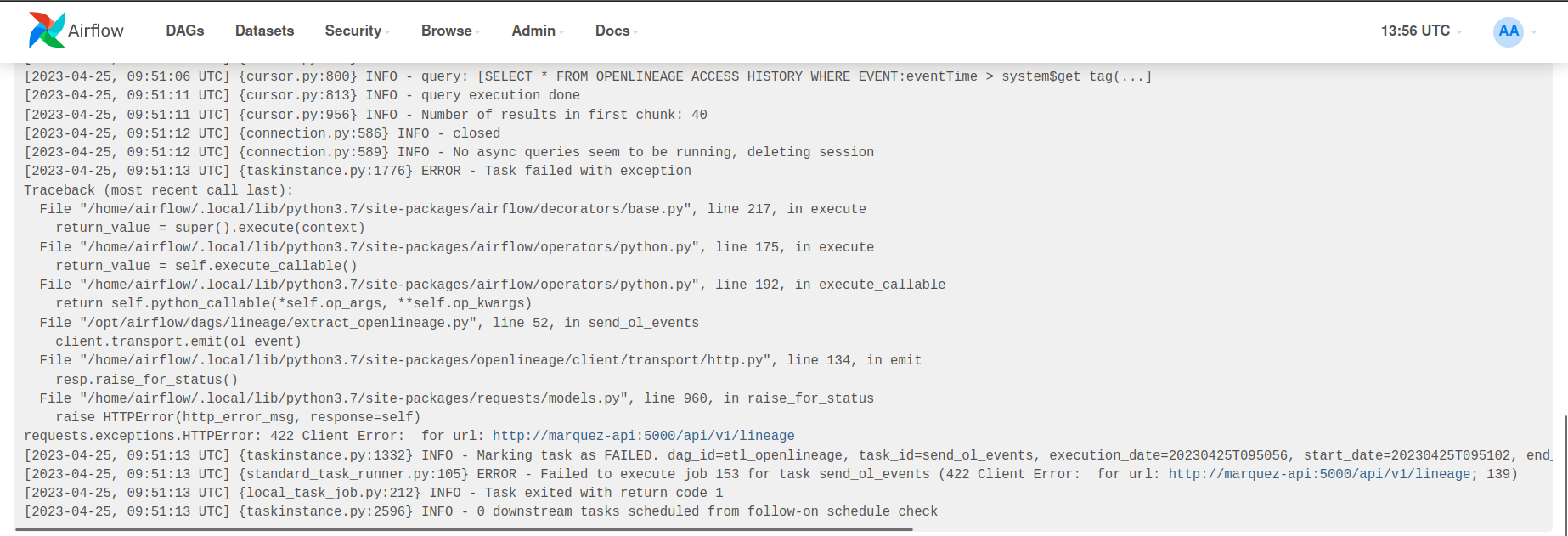 +
+  +
+ 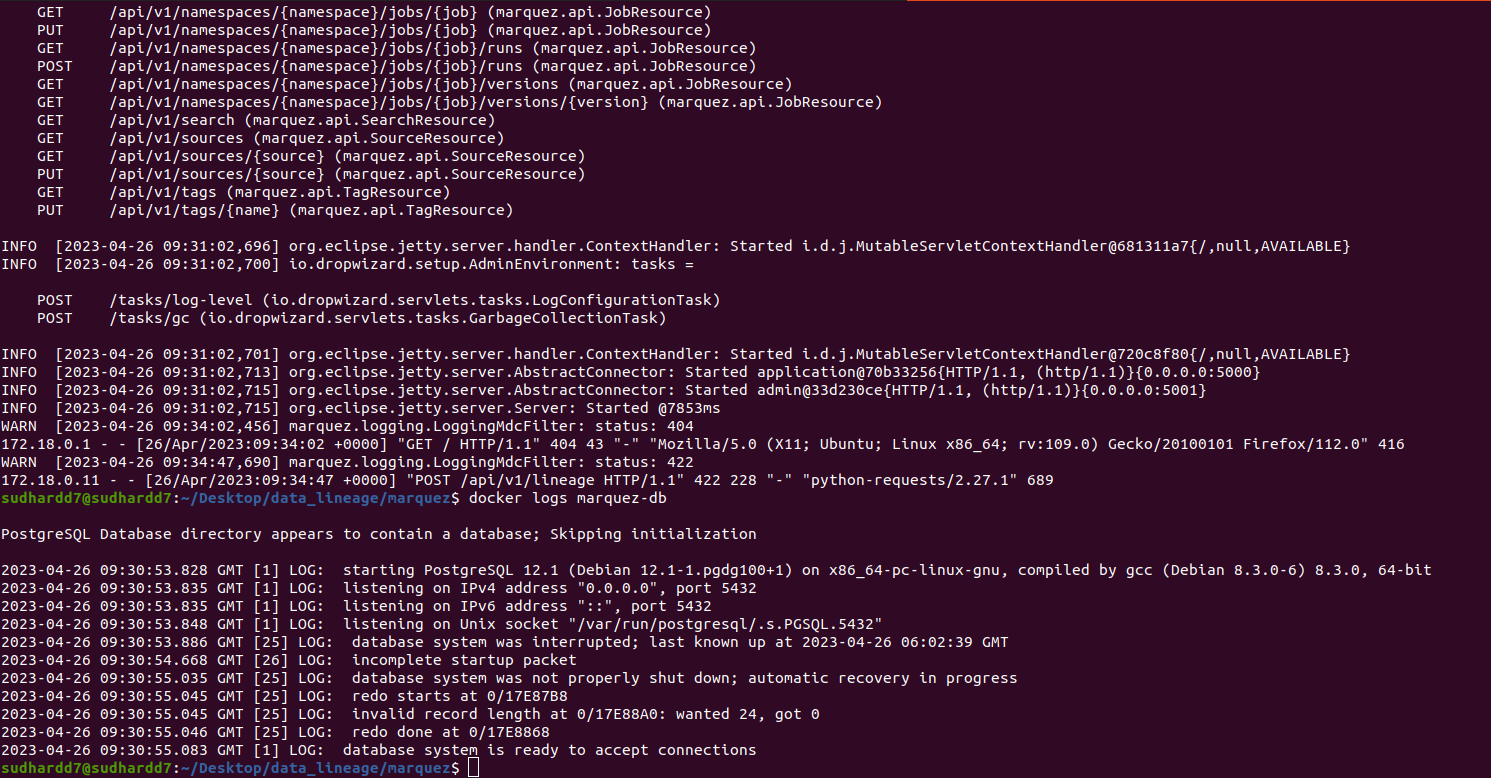 +
+ 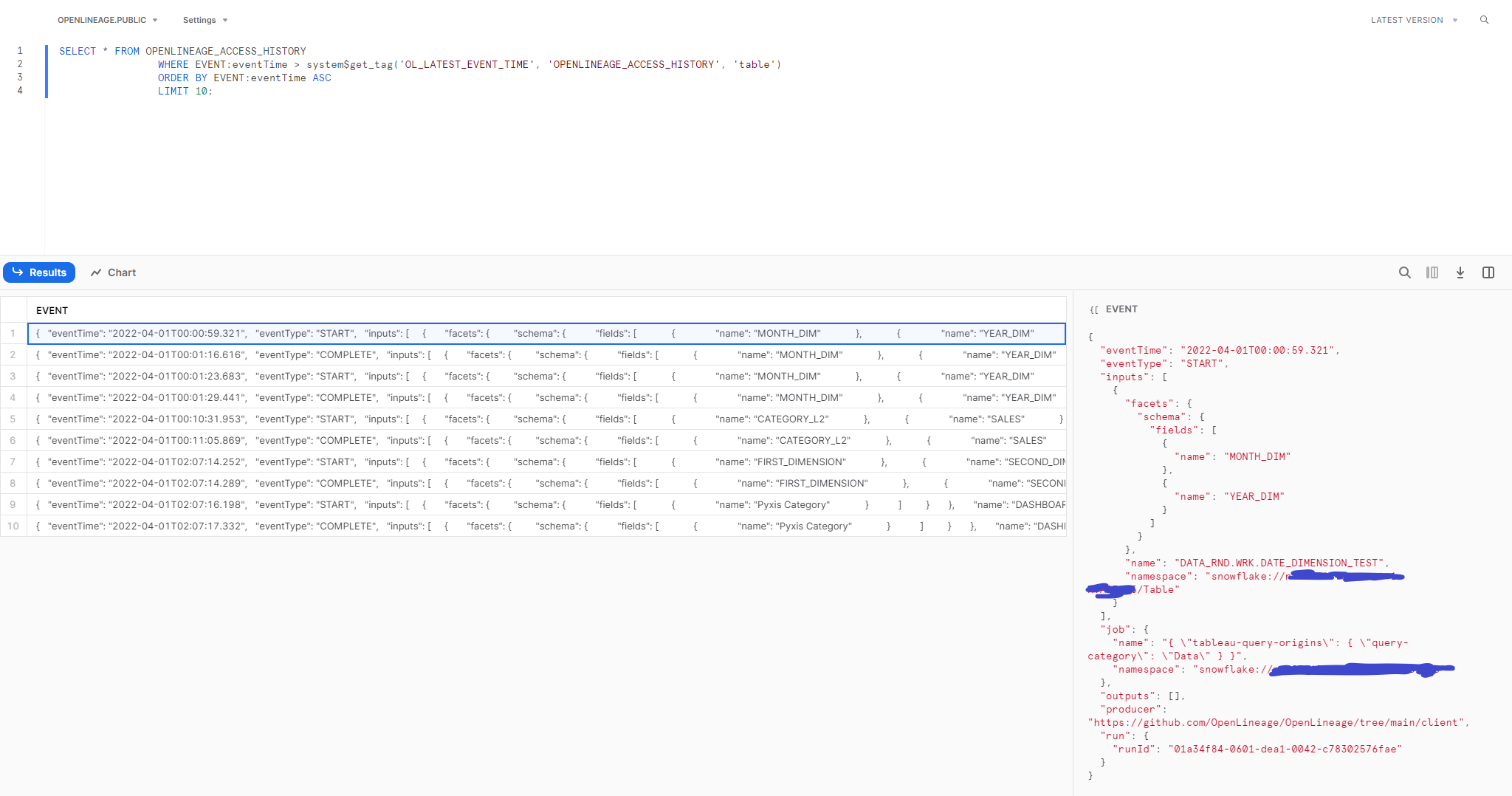 +
+  +
+ 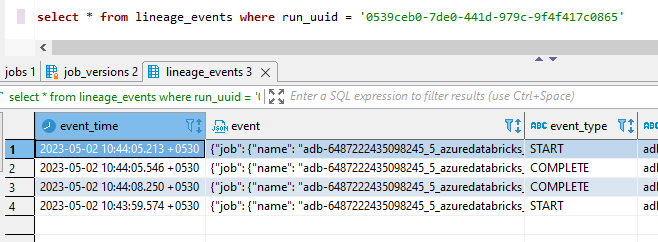 +
+  +
+ 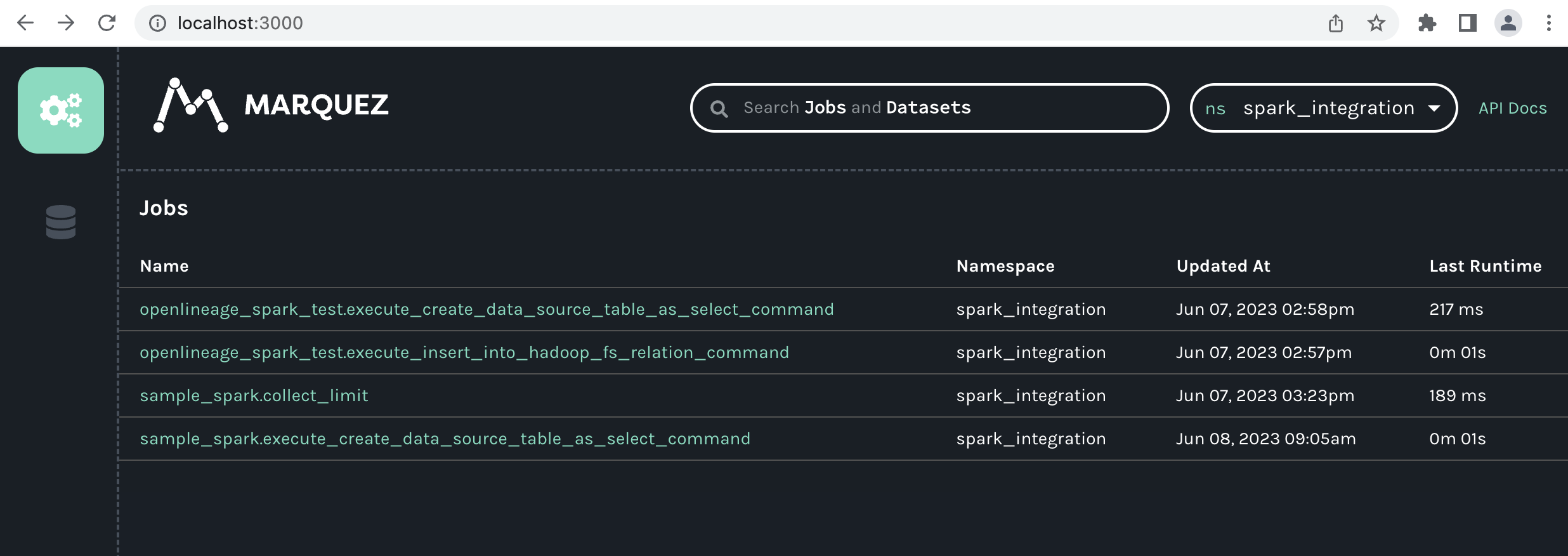 +
+ 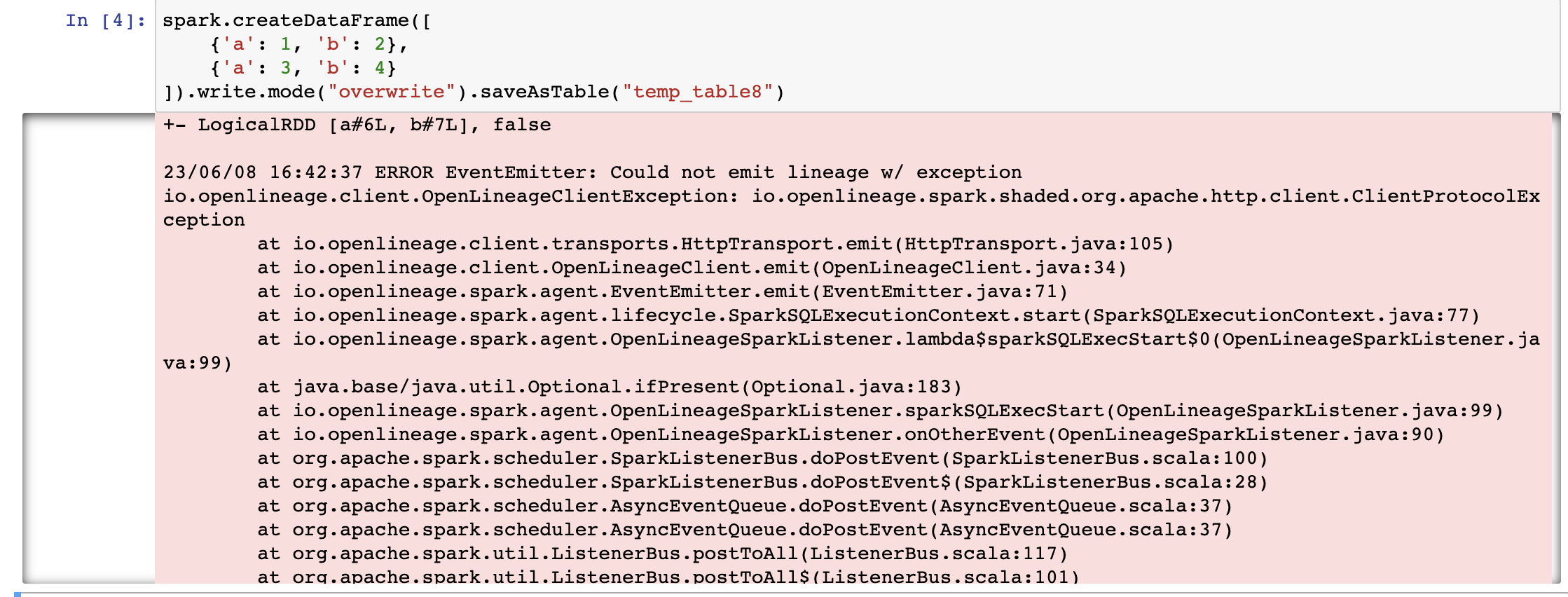 +
+  +
+ 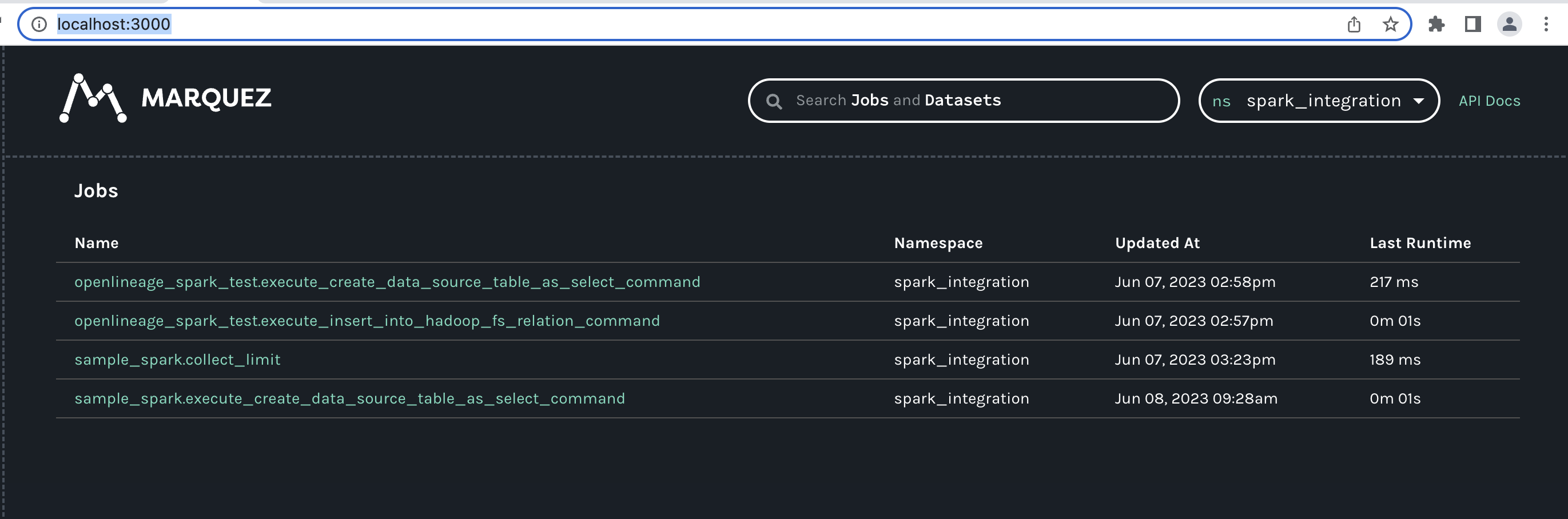 +
+ 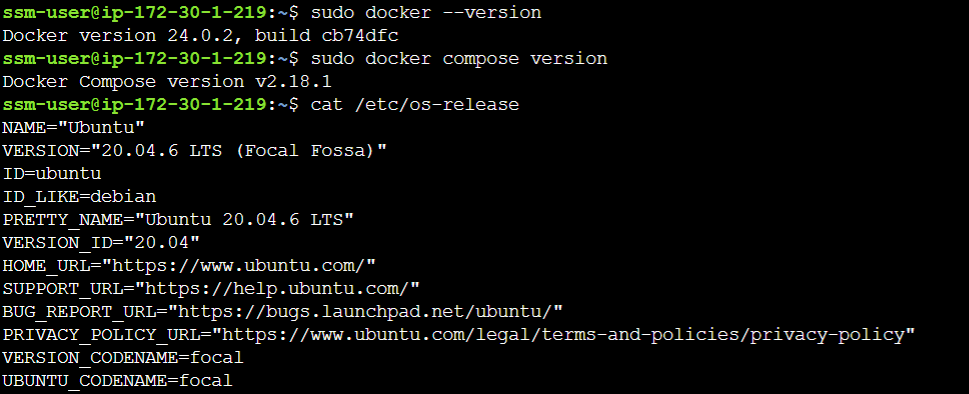 +
+ 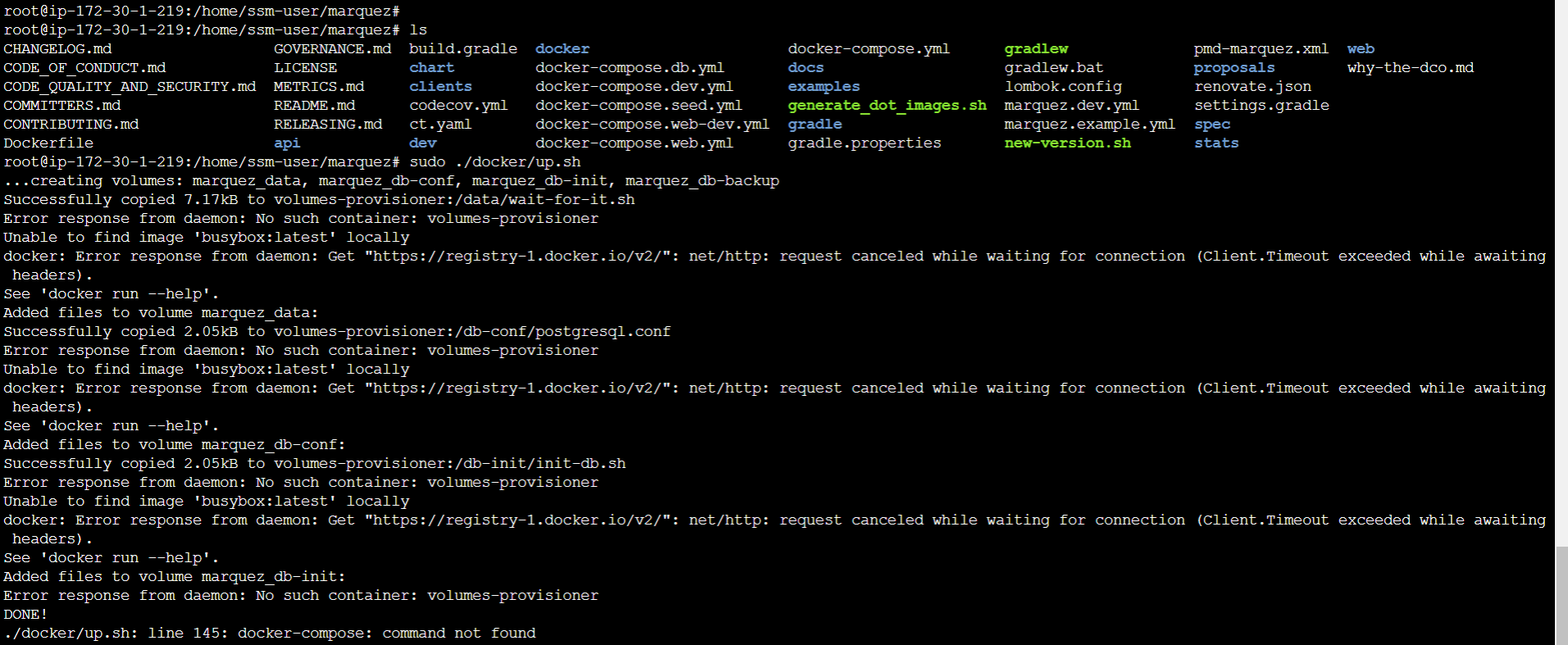 +
+ 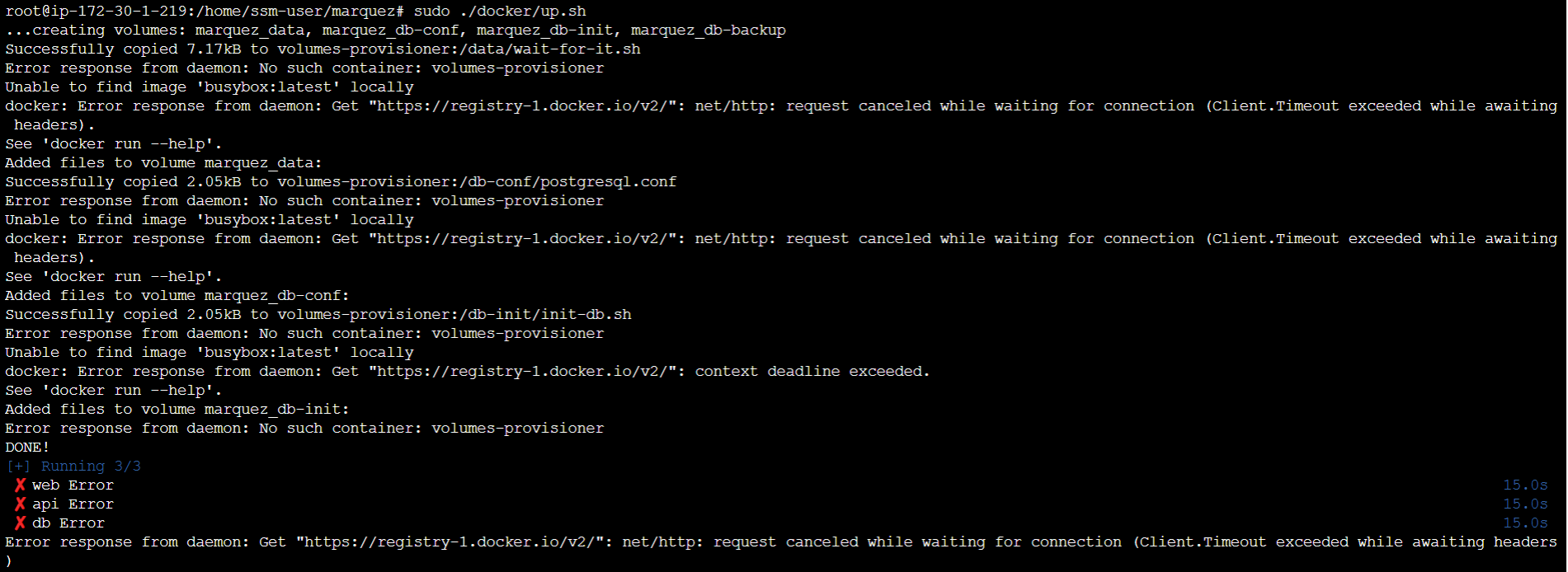 +
+  +
+ 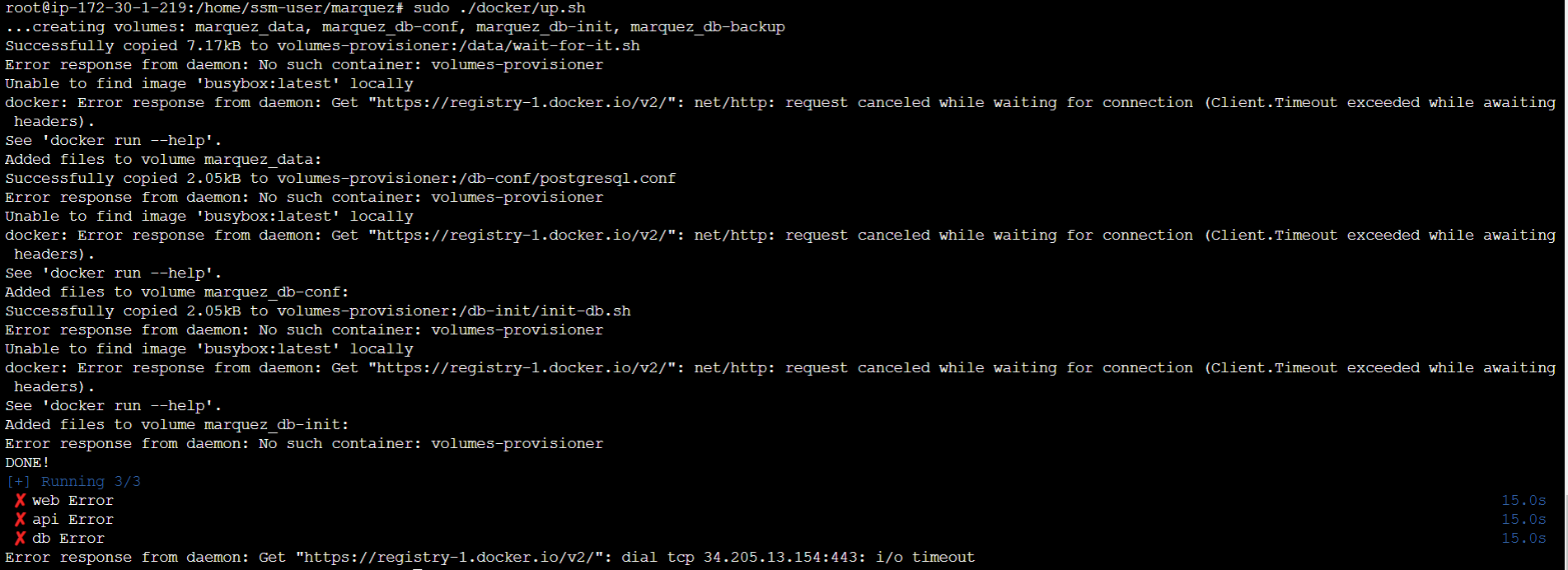 +
+ 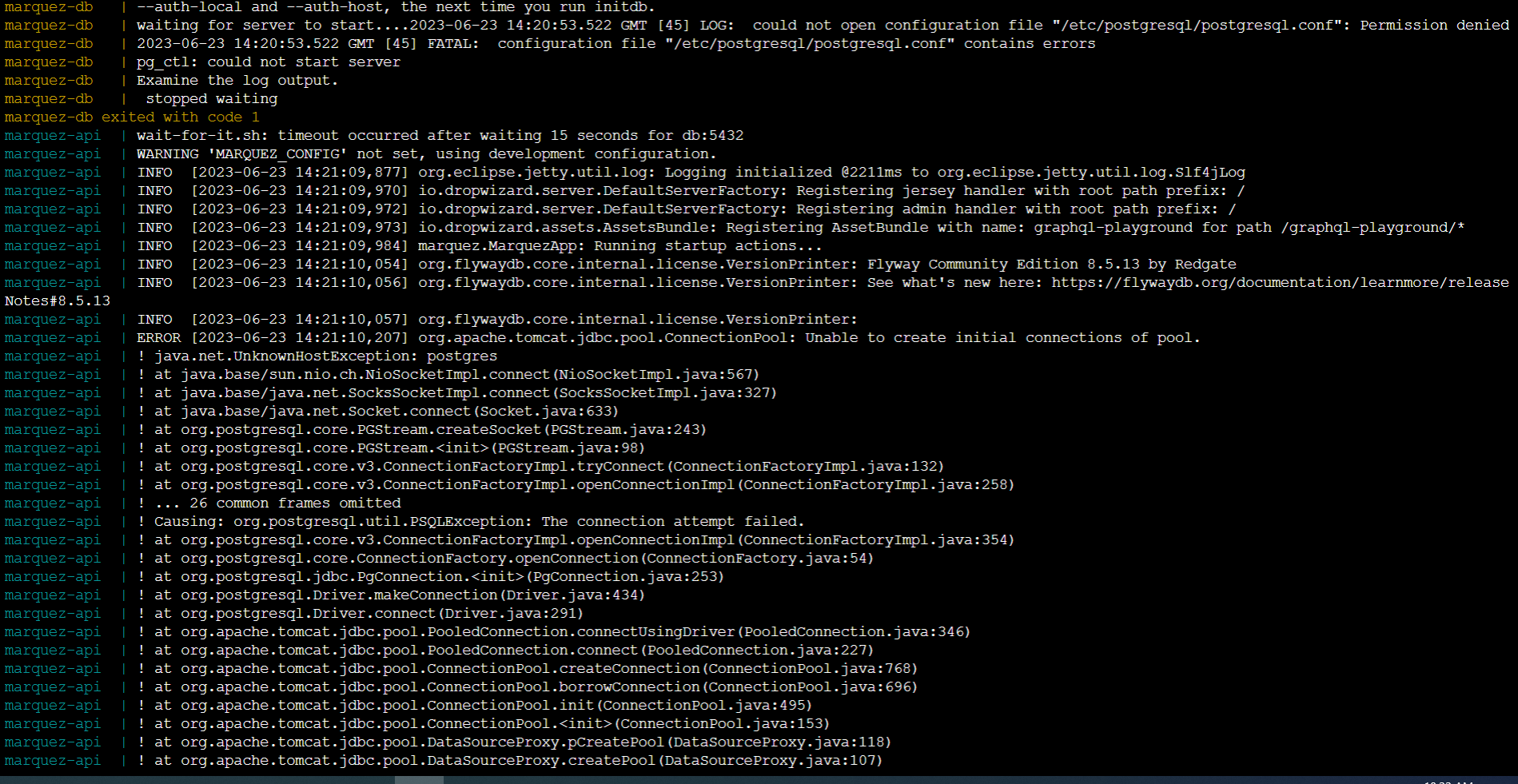 +
+ 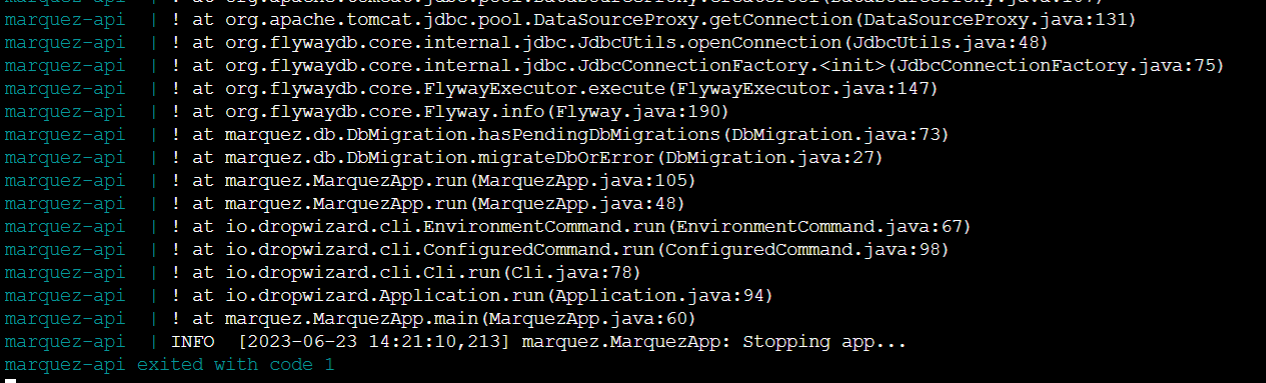 +
+ 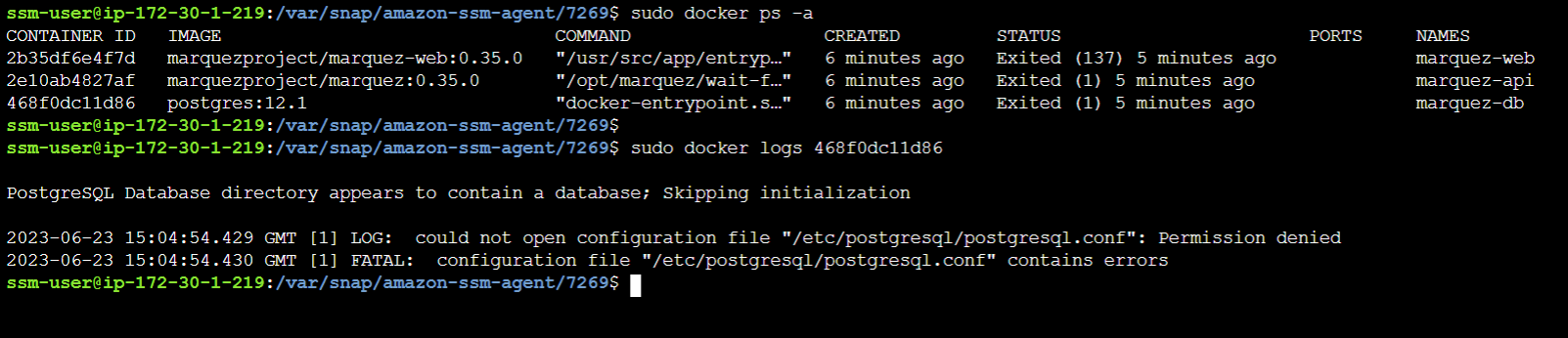 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ 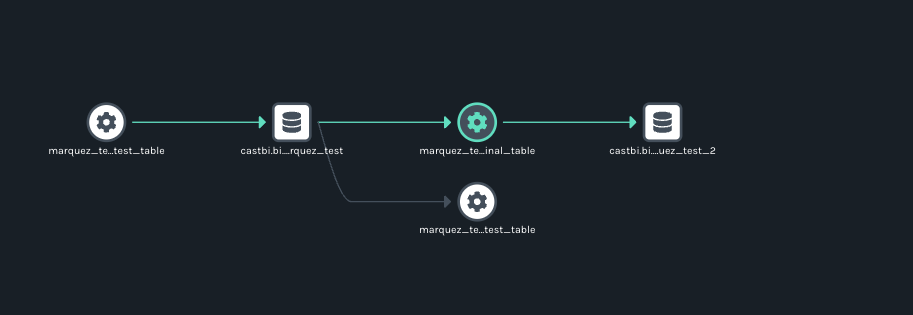 +
+ 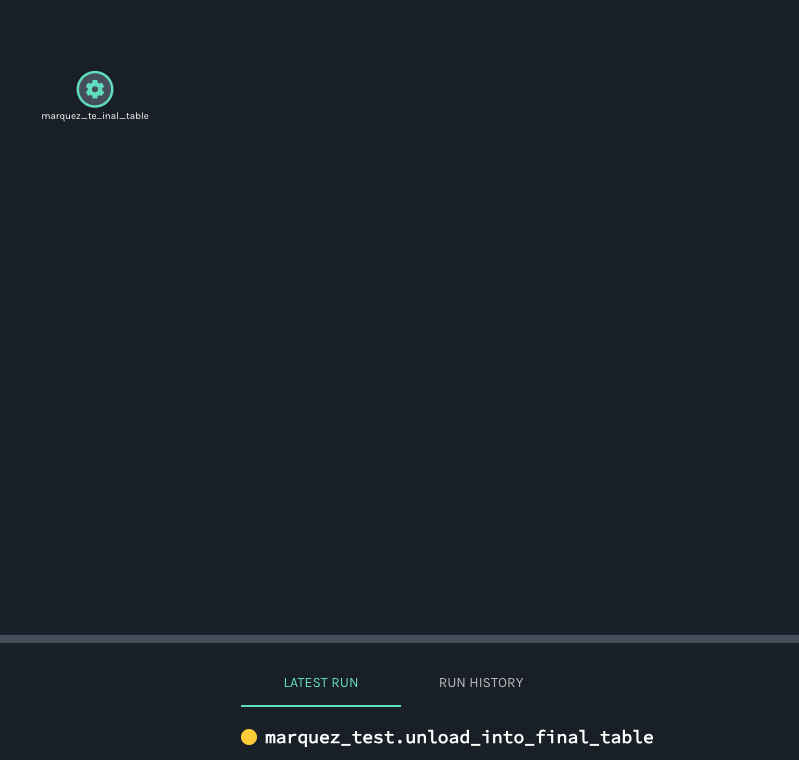 +
+  +
+ 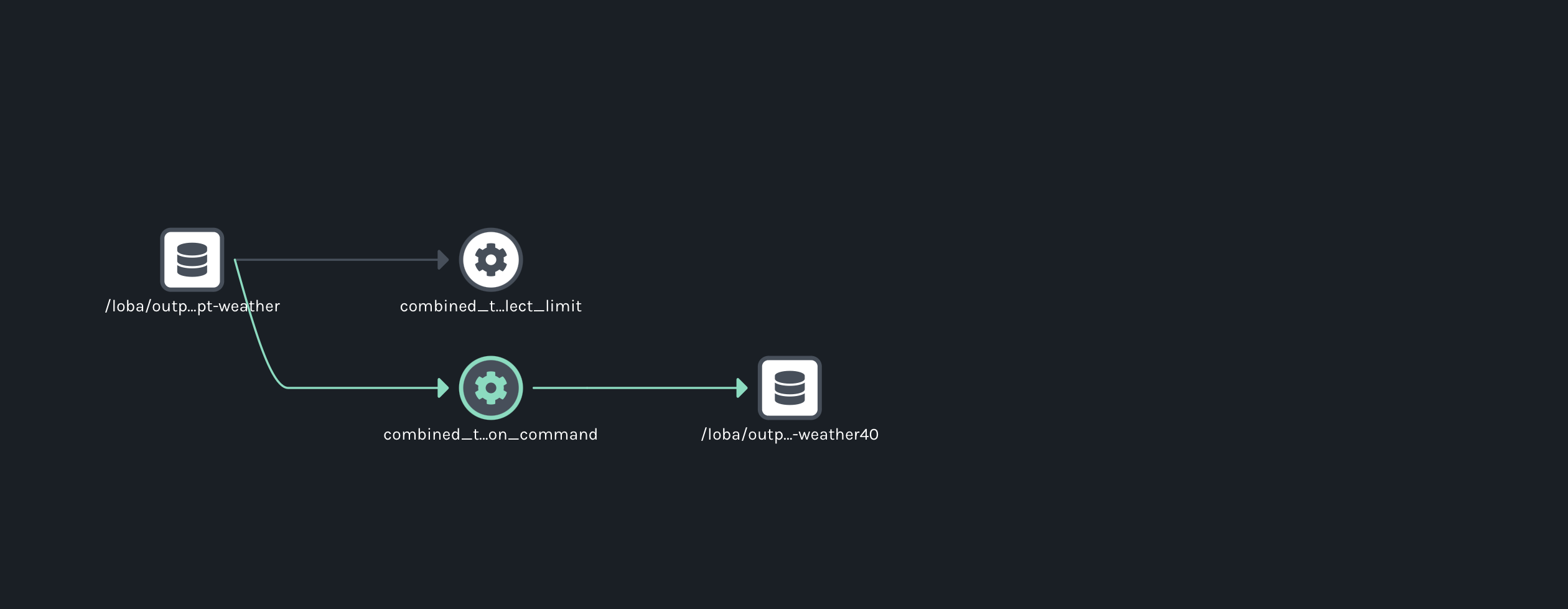 +
+  +
+  +
+ 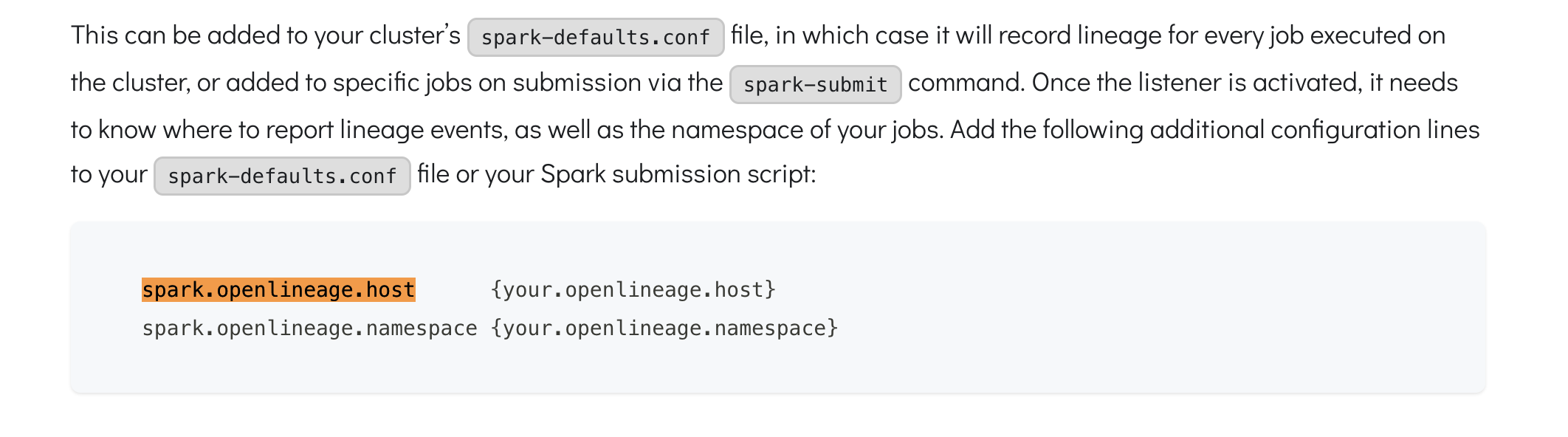 +
+  +
+  +
+  +
+  +
+ 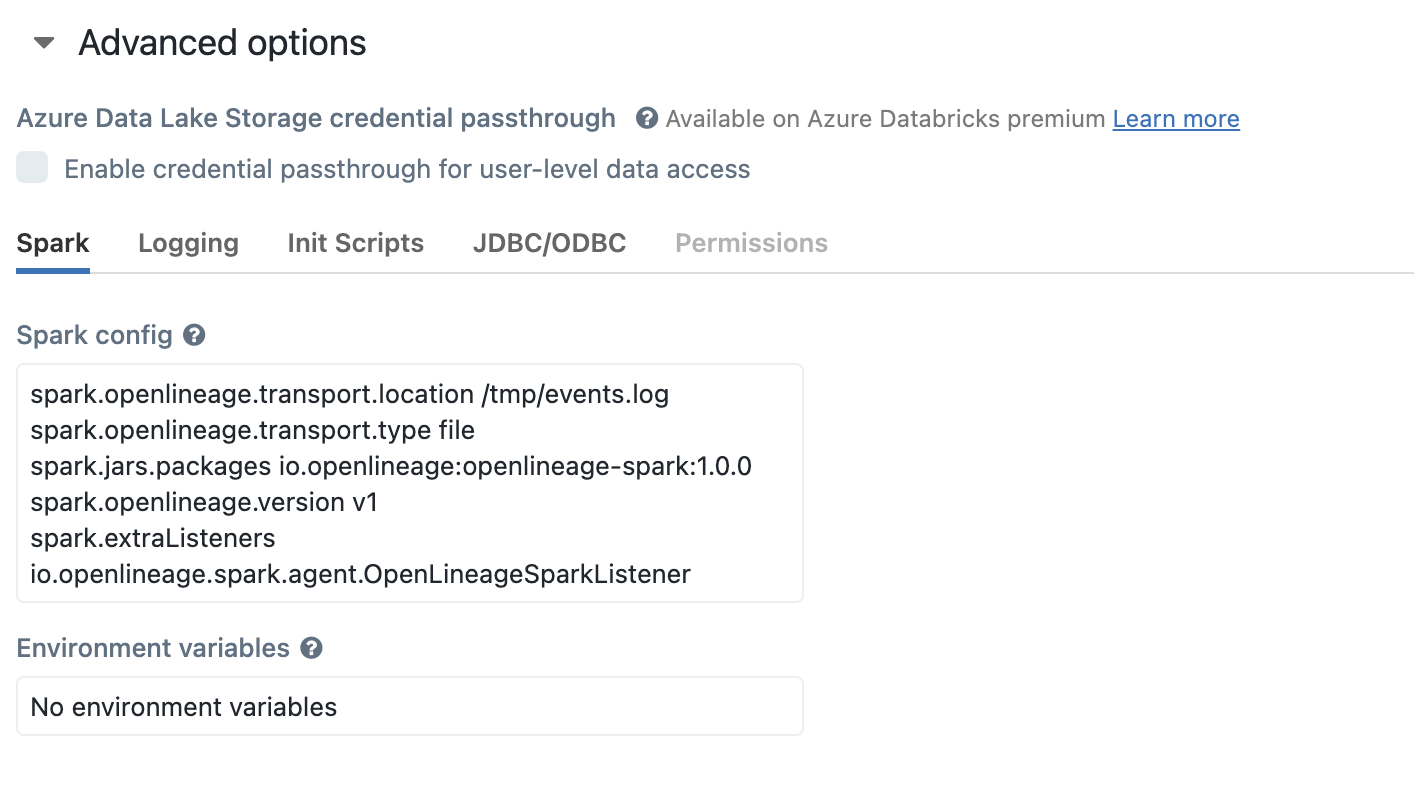 +
+ 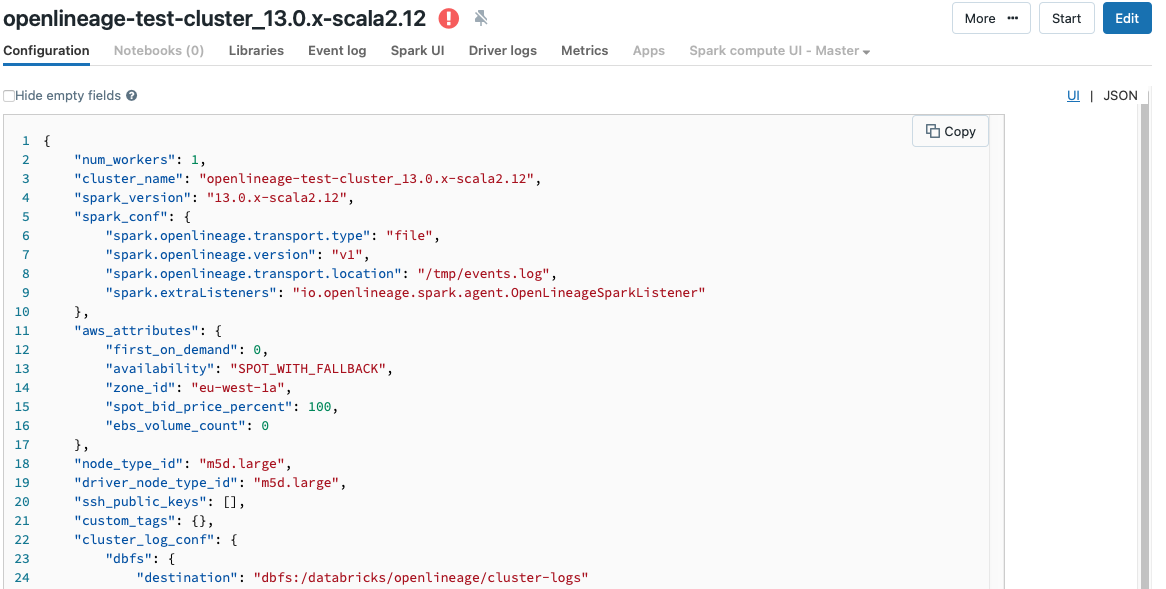 +
+  +
+  +
+  +
+ 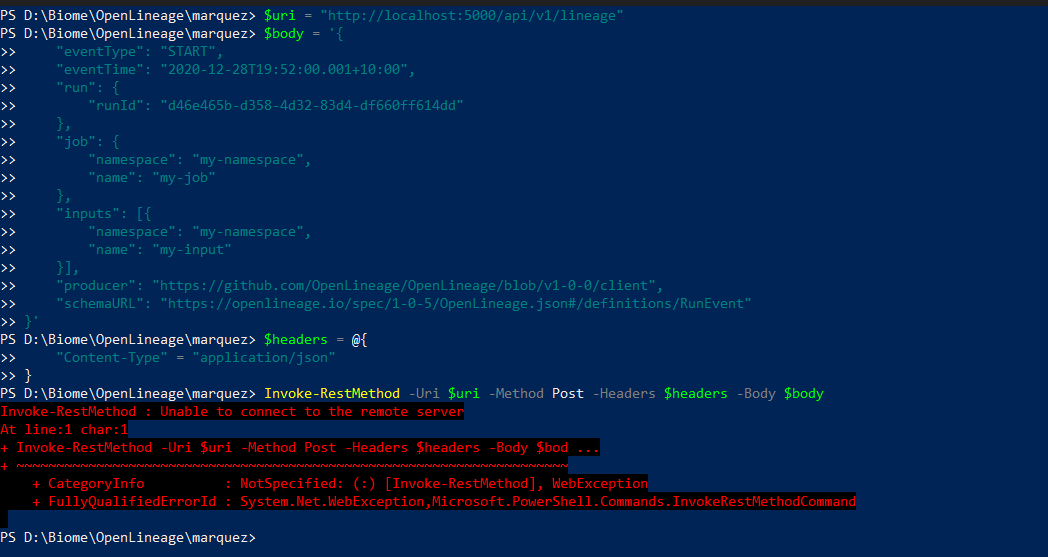 +
+  +
+  +
+  +
+ 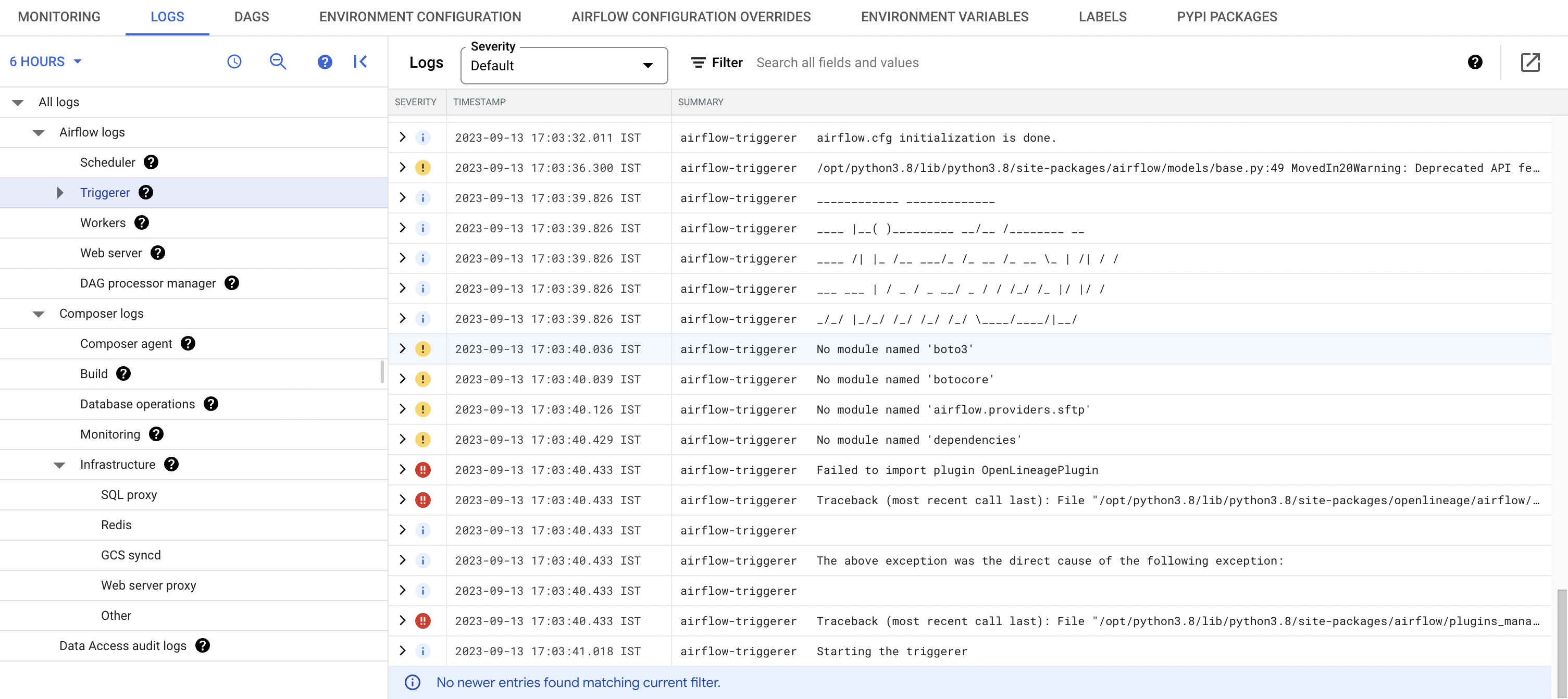 +
+  +
+  +
+ 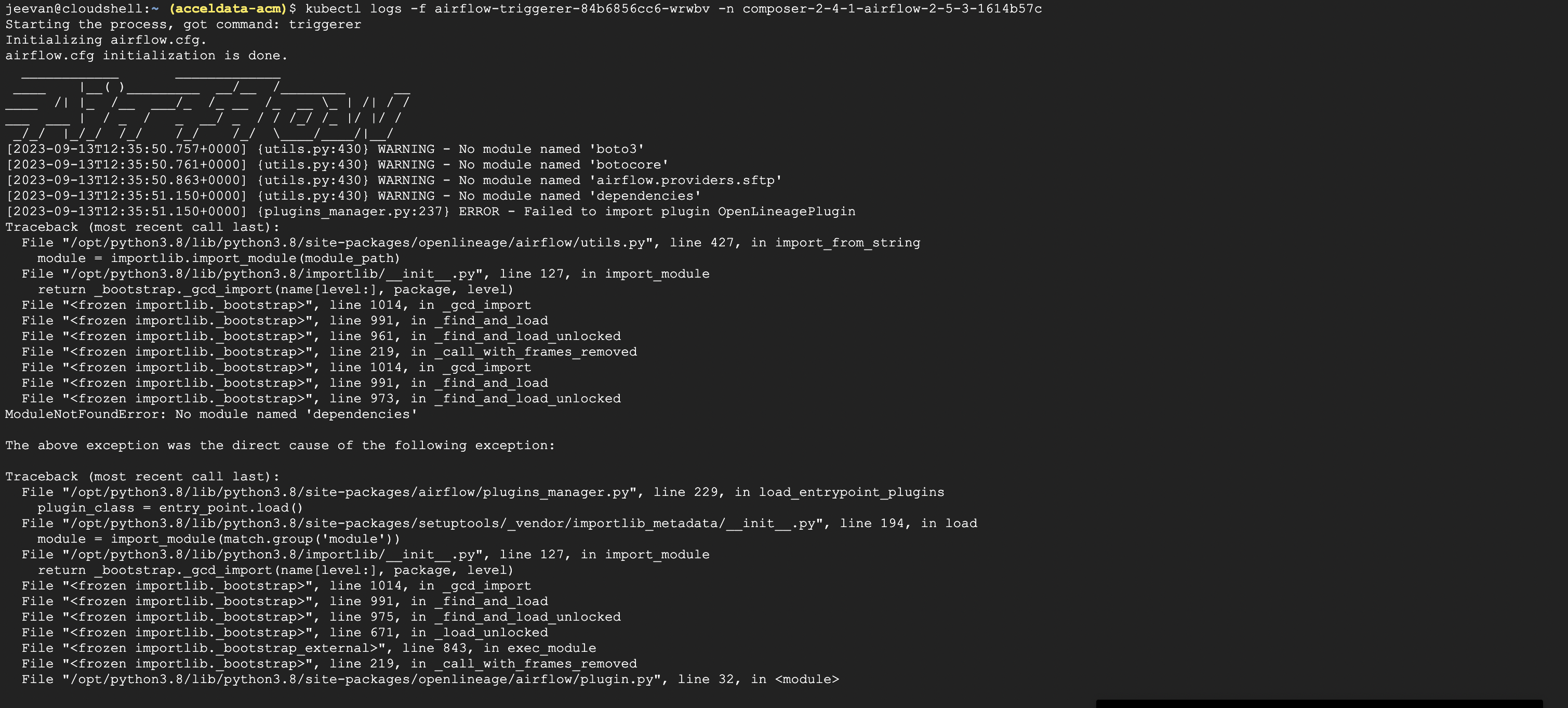 +
+ 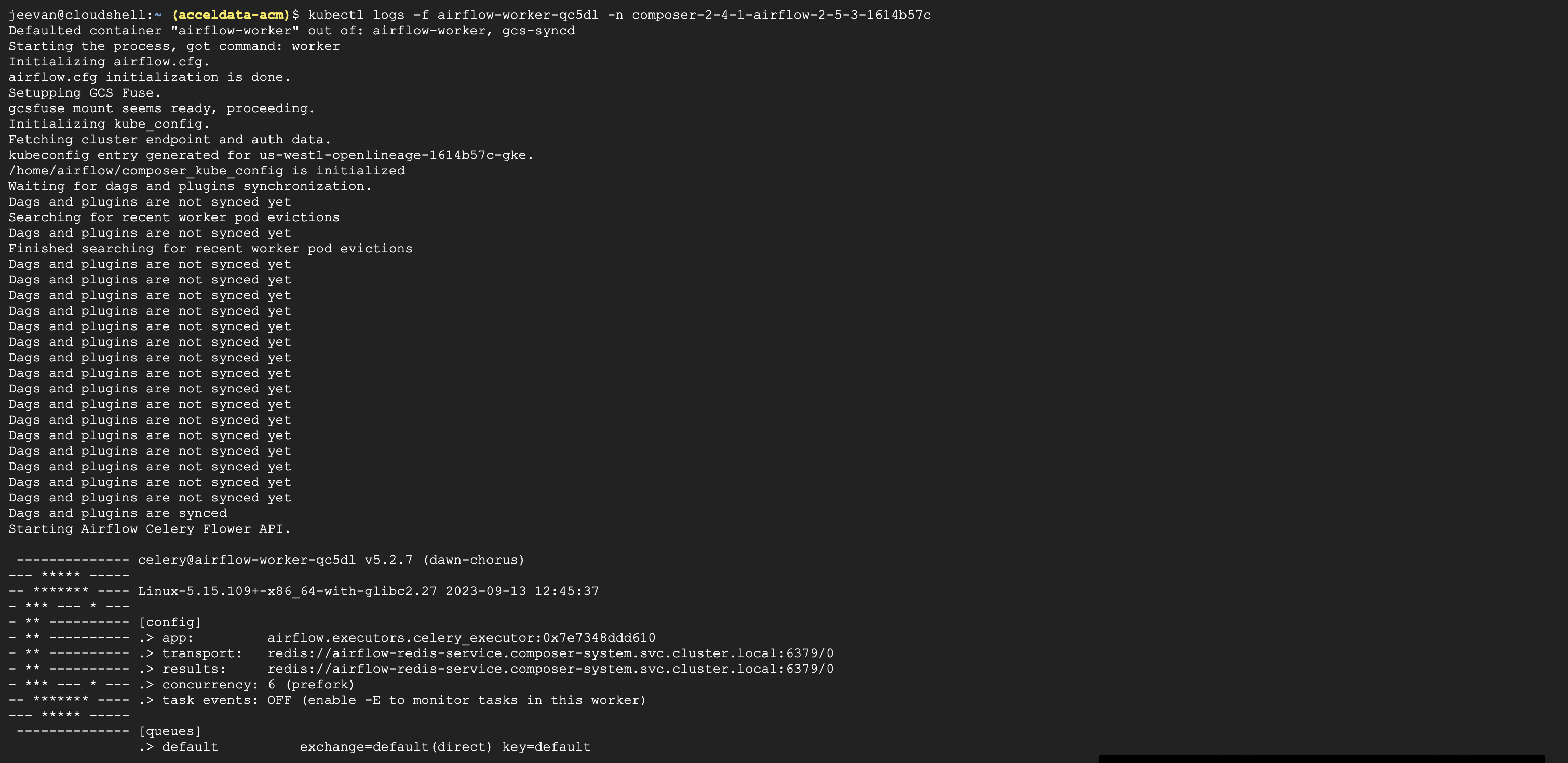 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ 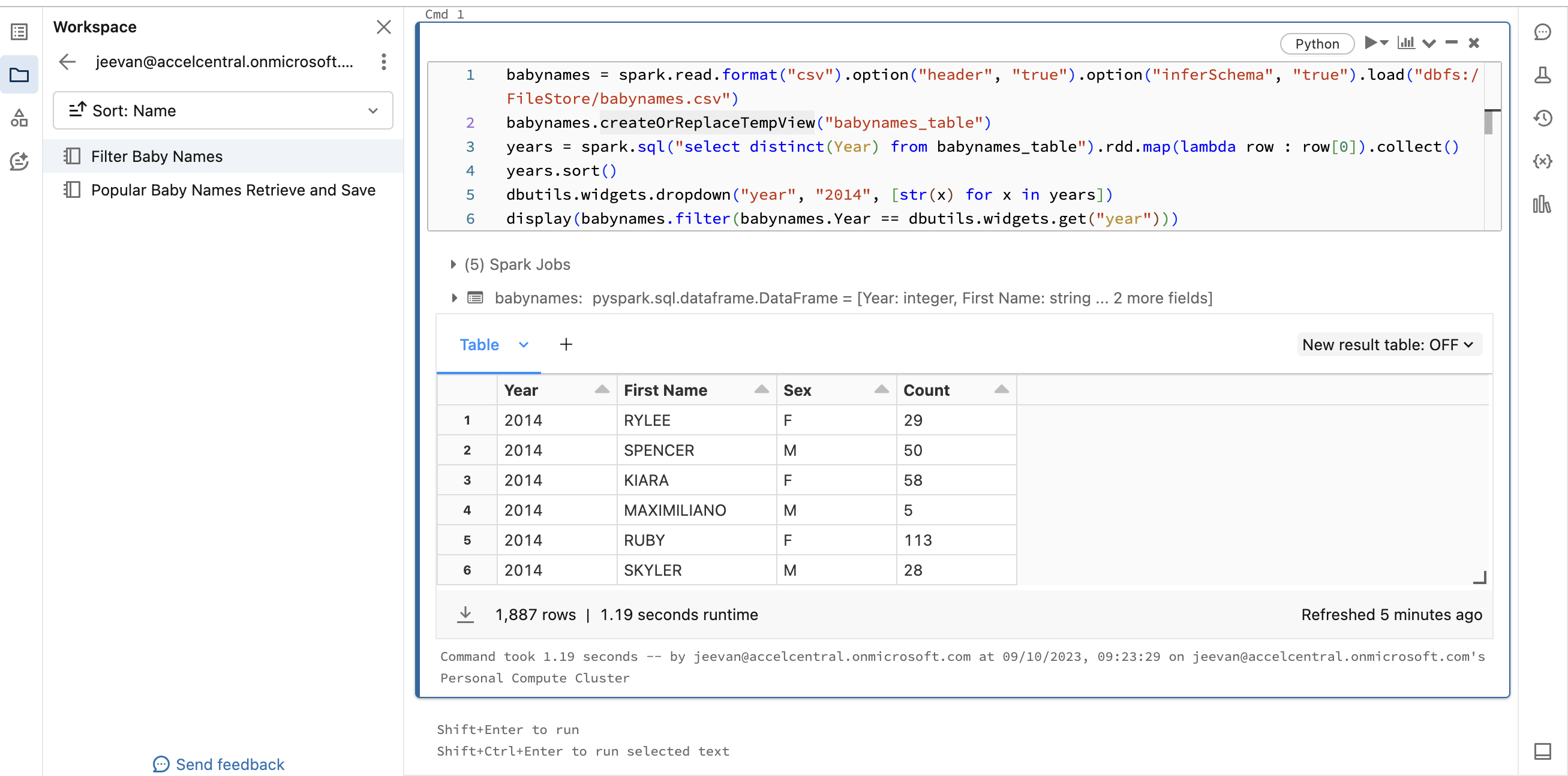 +
+  +
+  +
+  +
+  +
+  +
+  +
+ 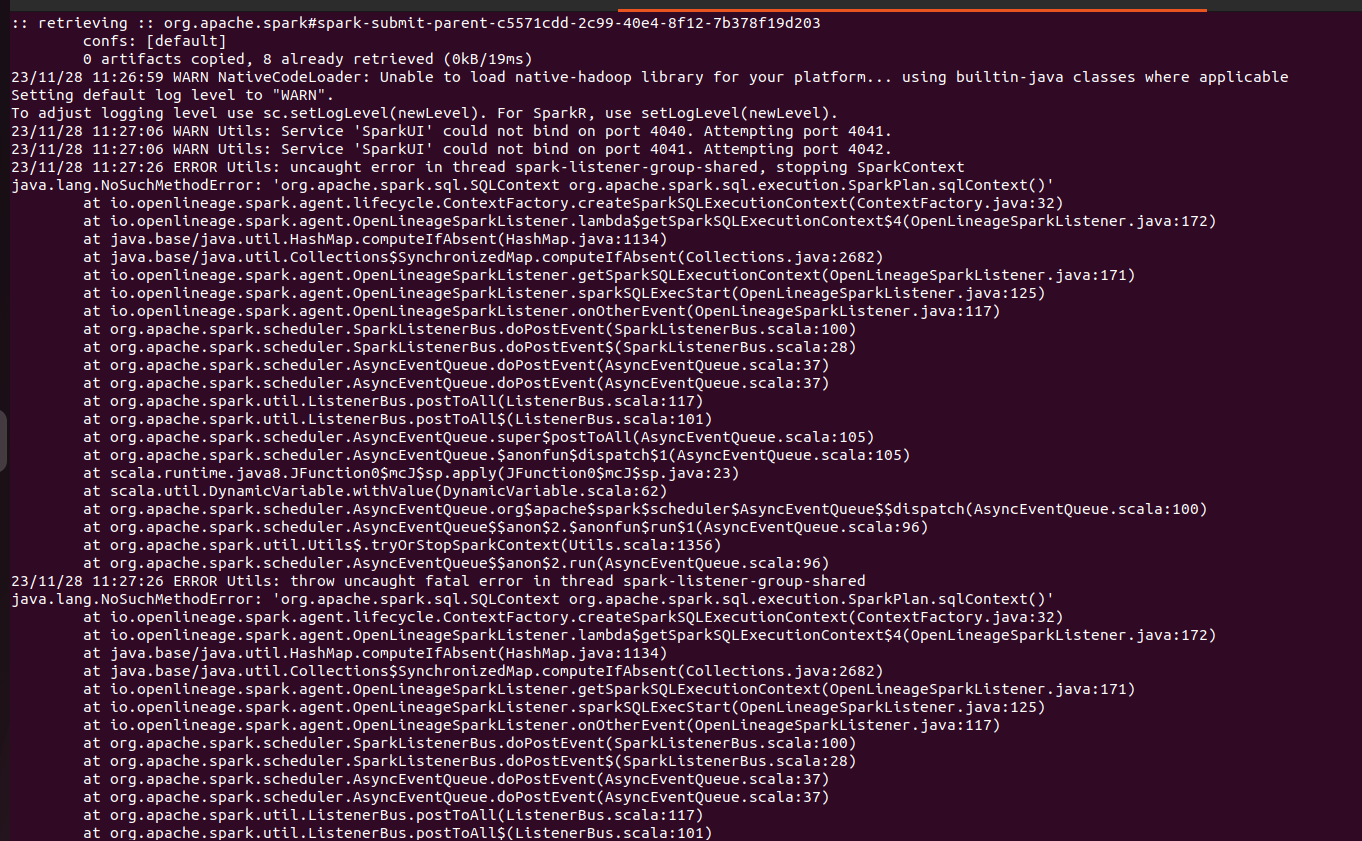 +
+  +
+  +
+  +
+  +
+  + }
+
+ }
+  + }
+
+ }
+  + }
+
+ }
+ 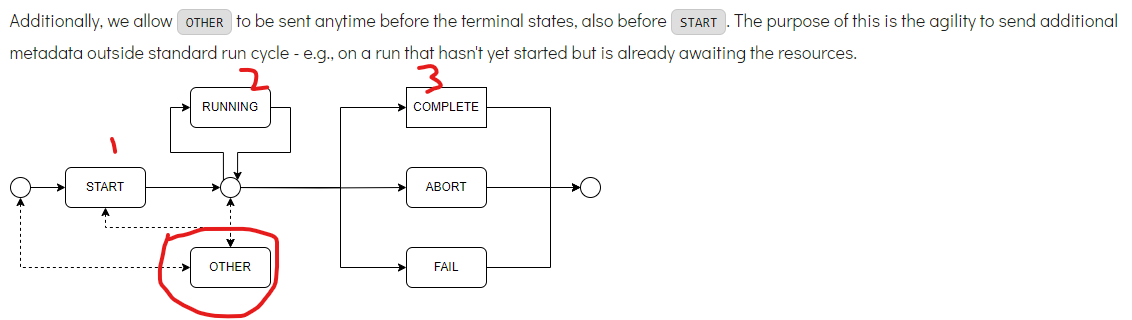 +
+  +
+  +
+  +
+ 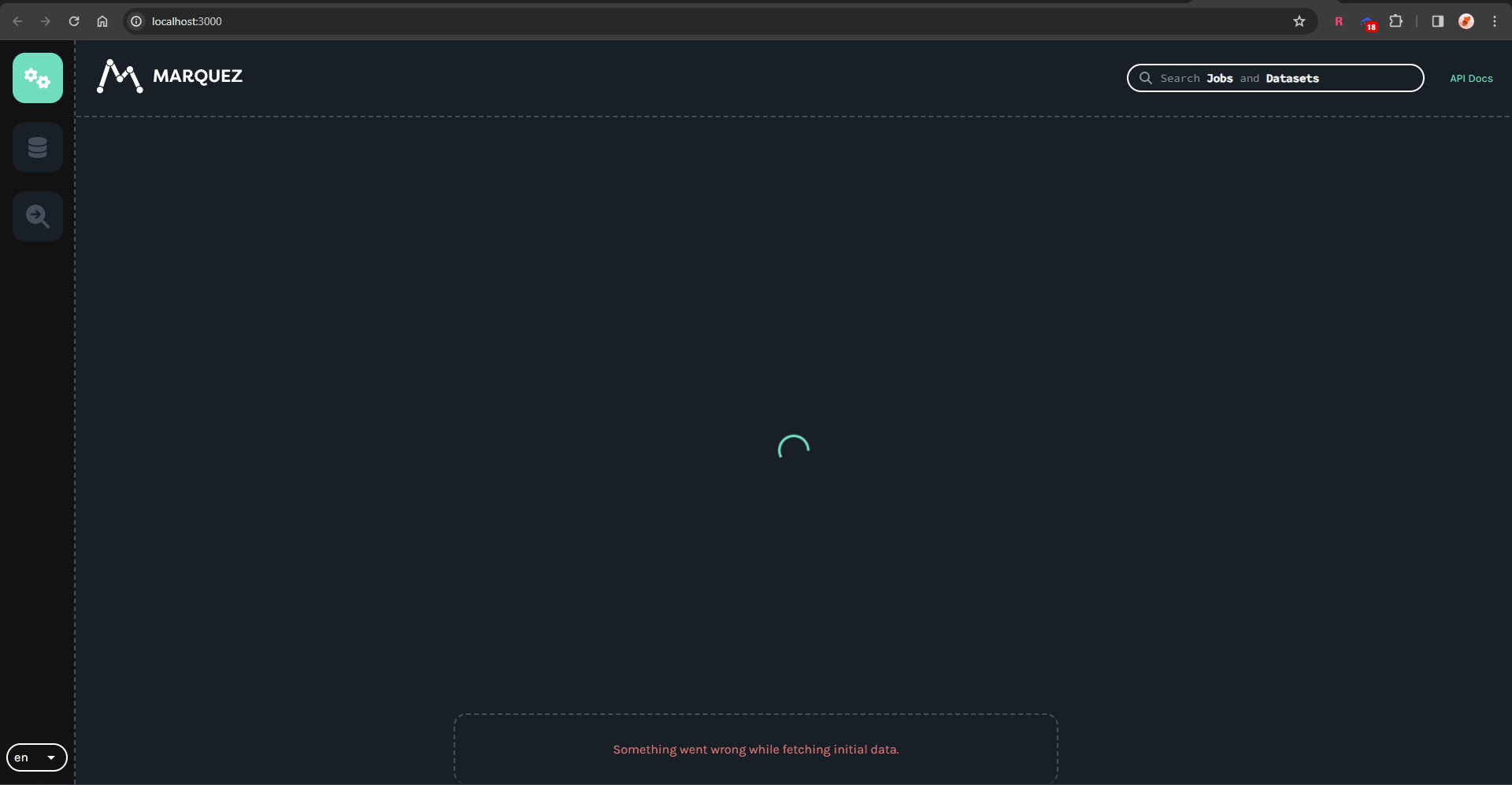 +
+ 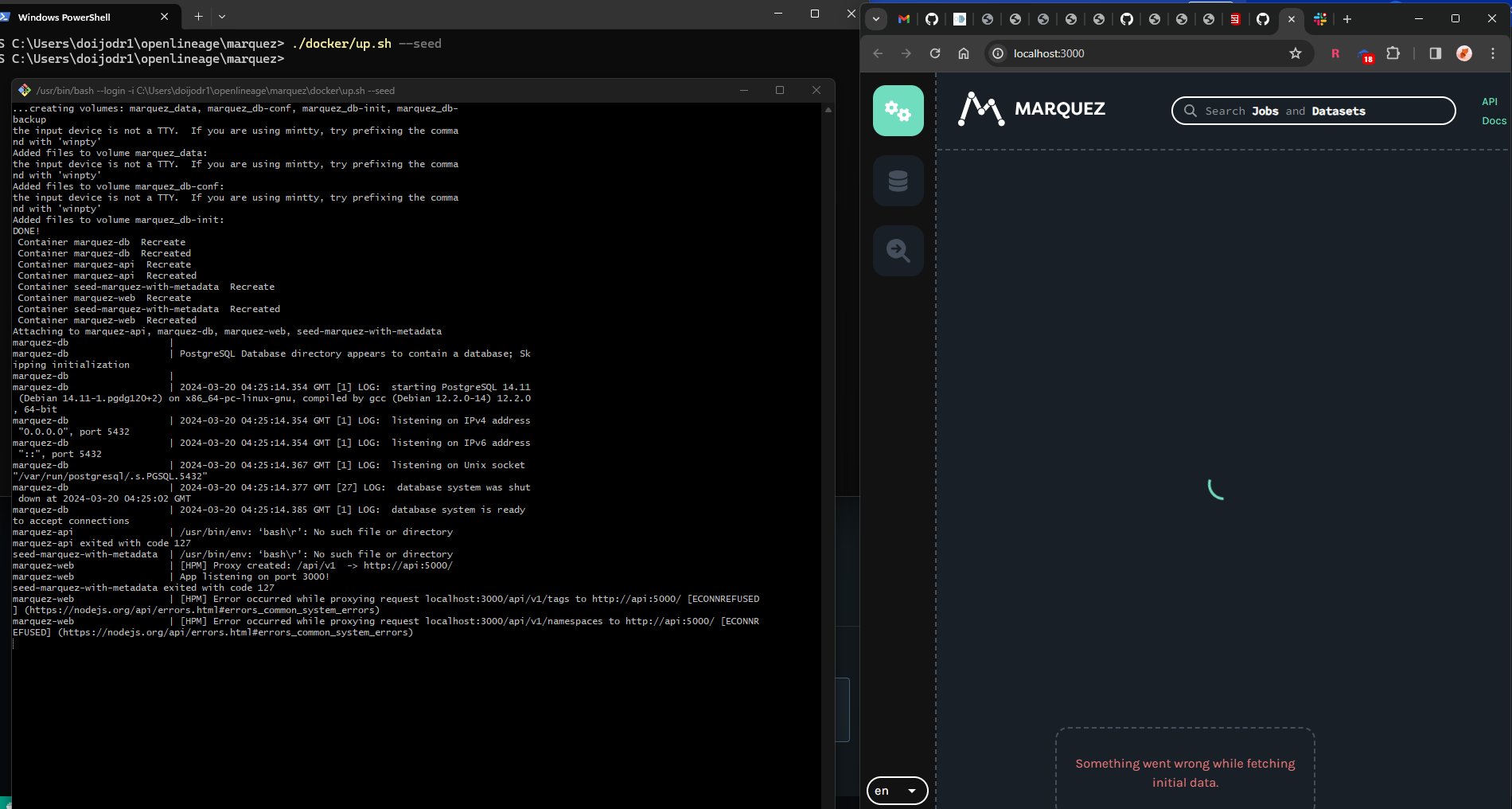 +
+  +
+  +
+ 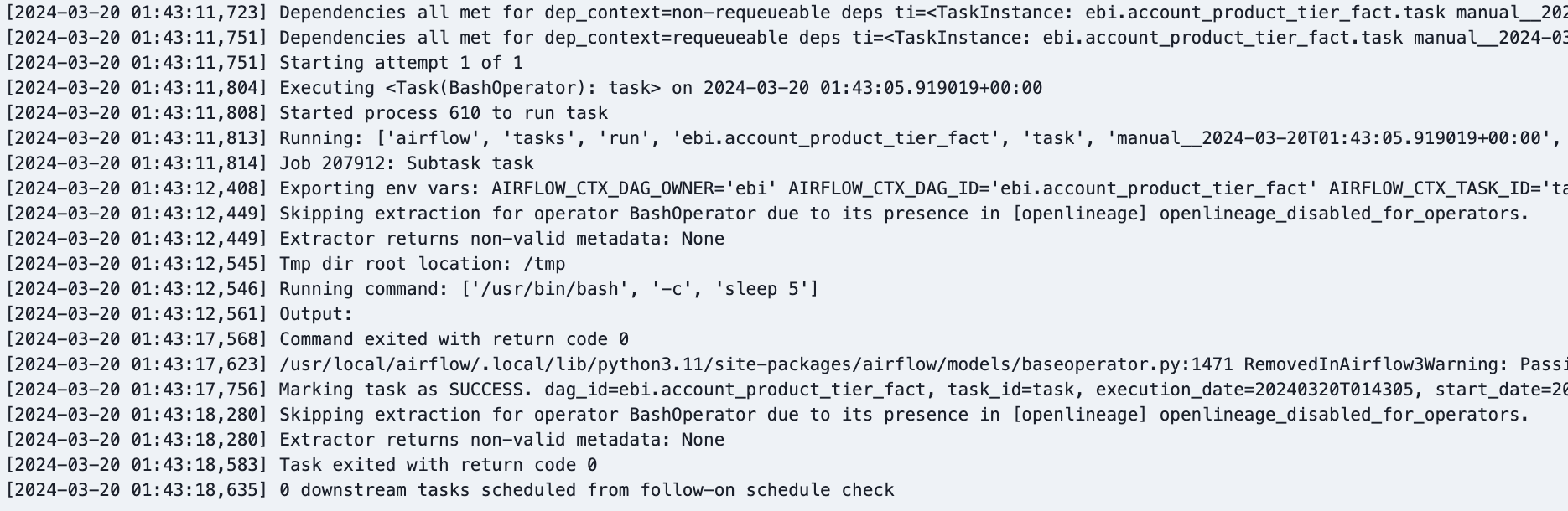 +
+  + }
+
+ }
+  + }
+
+ }
+  +
+ 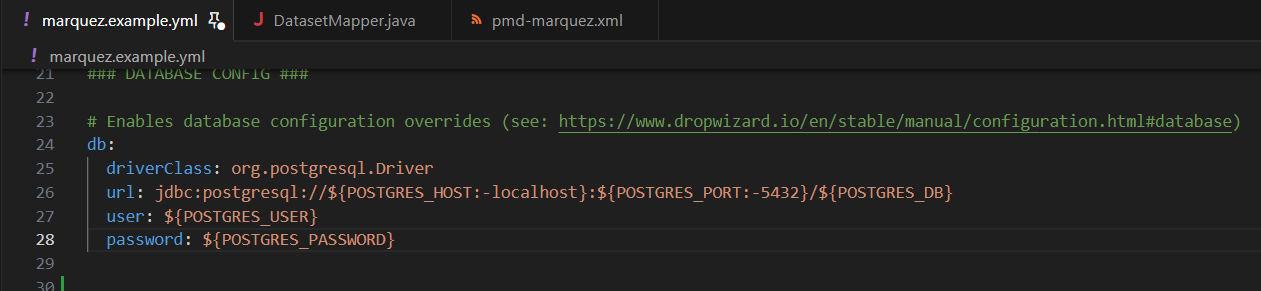 +
+ 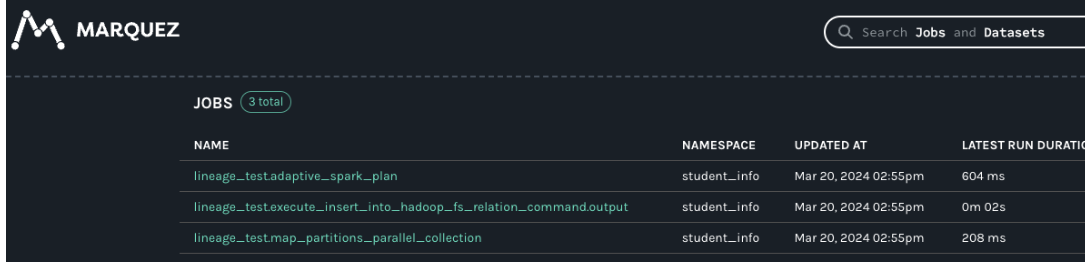 +
+  +
+ 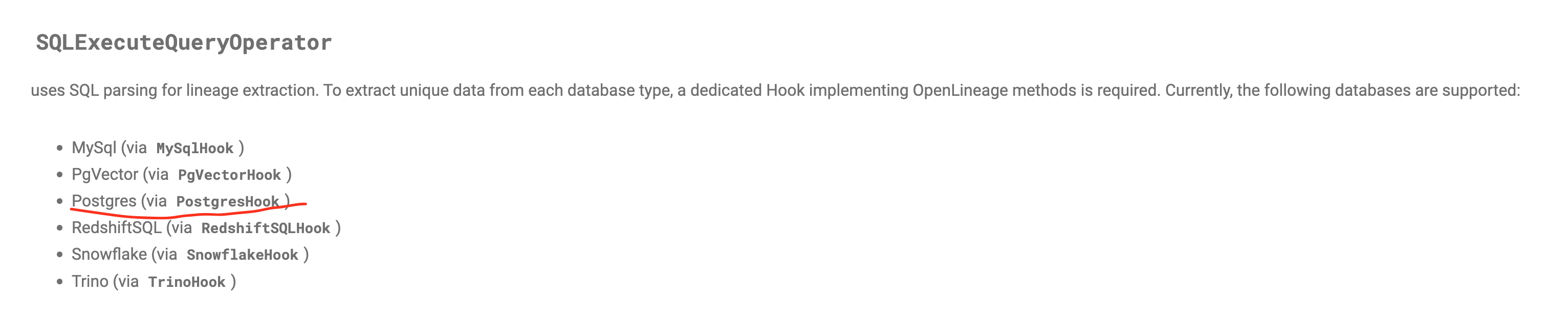 +
+  +
+  +
+  +
+  +
+ 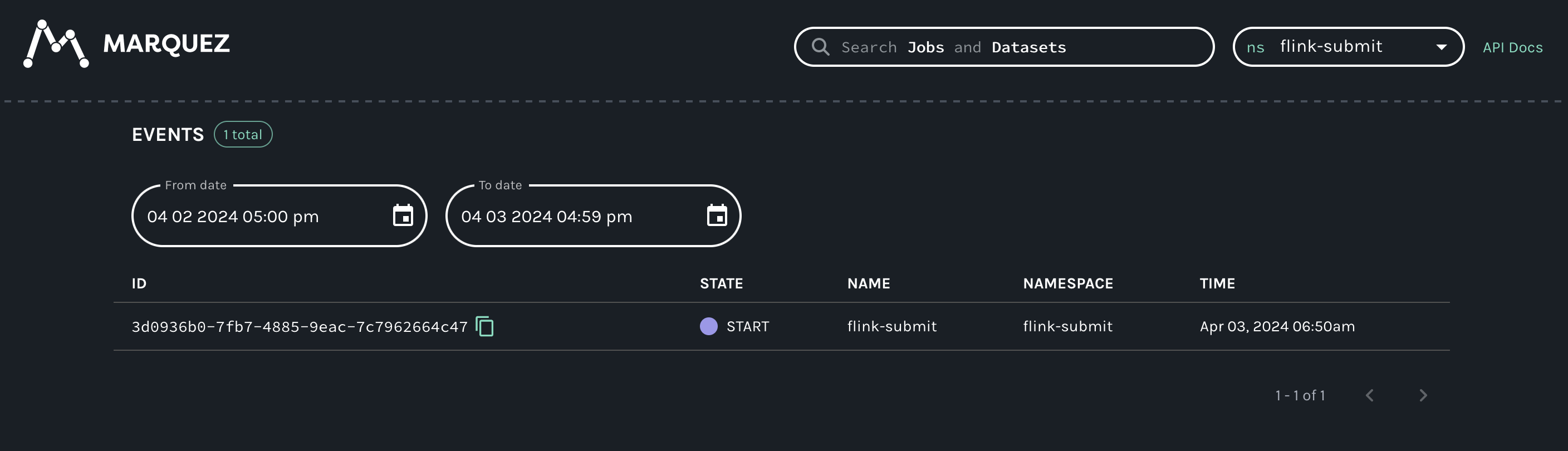 +
+  +
+  +
+  - }
-
- }
-  - }
-
- }
-  +
+  +
+  +
+  +
+  +
+ 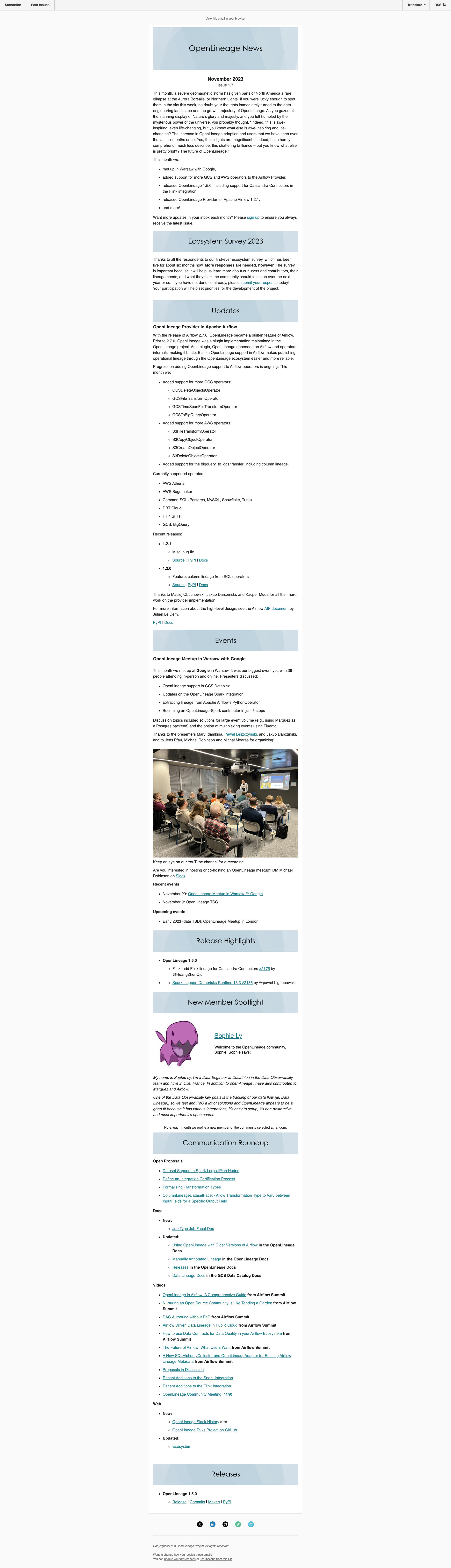{kind=link}
{kind=link}
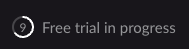{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
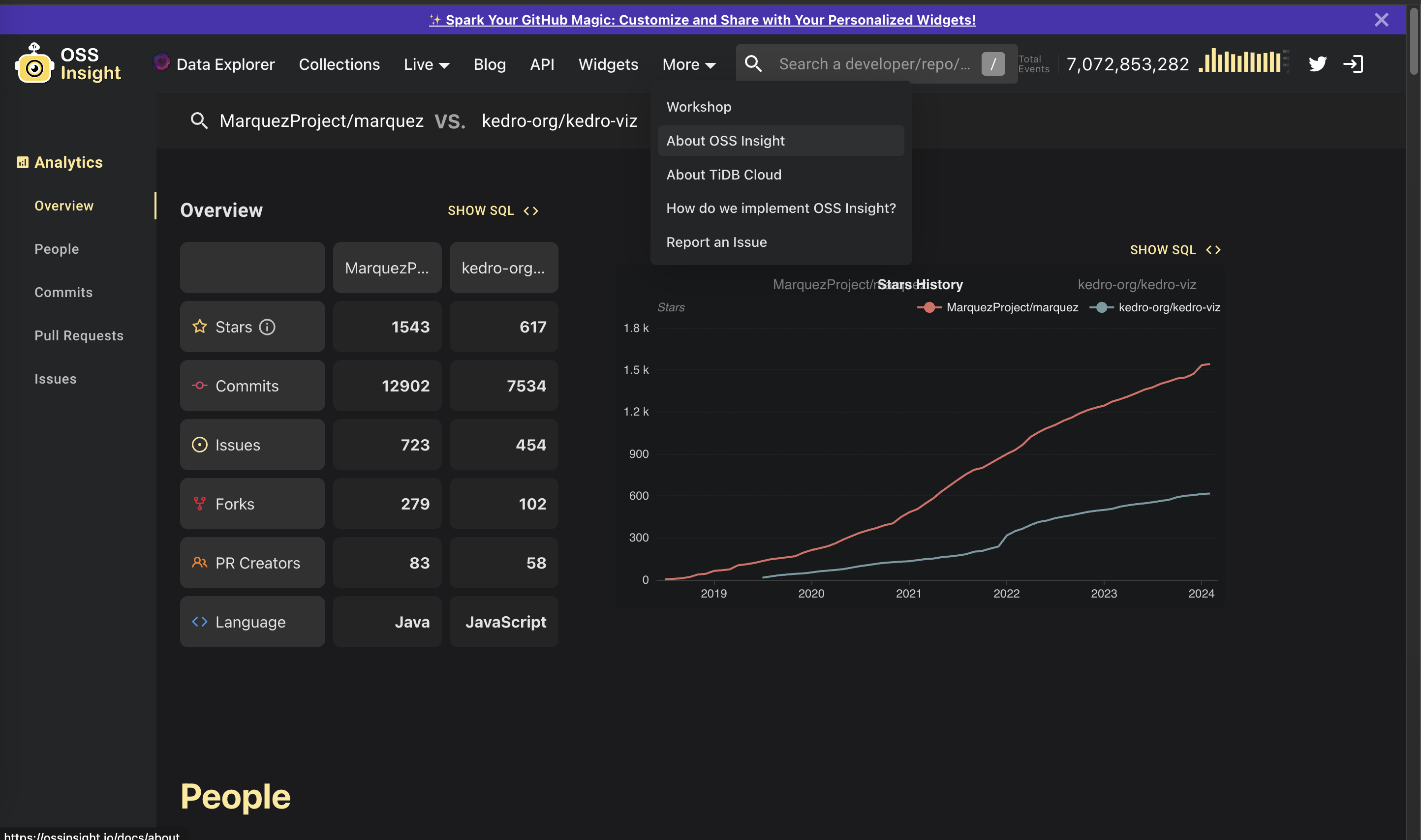{kind=link}
{kind=link}
{kind=link}
{kind=link}
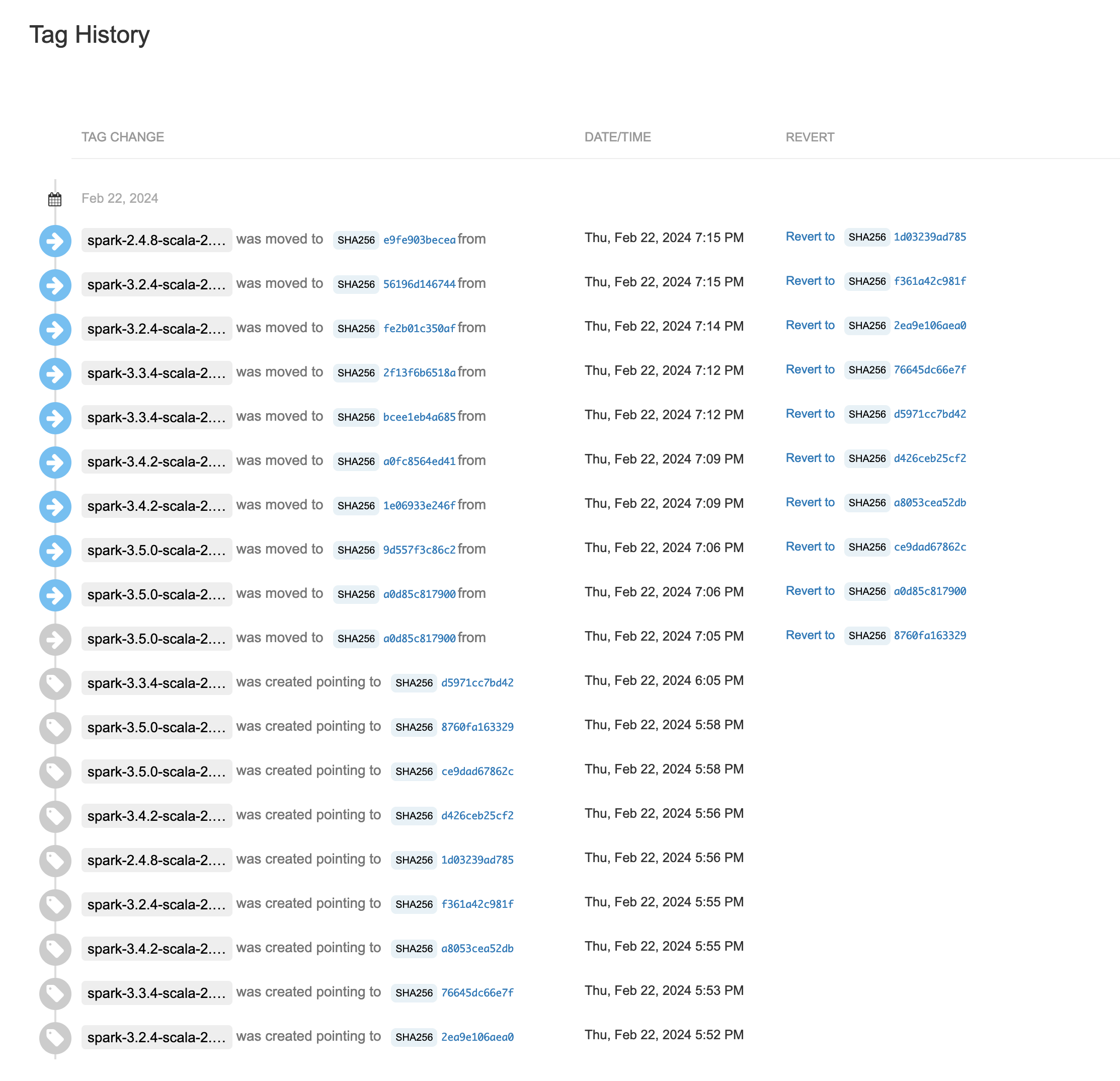{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
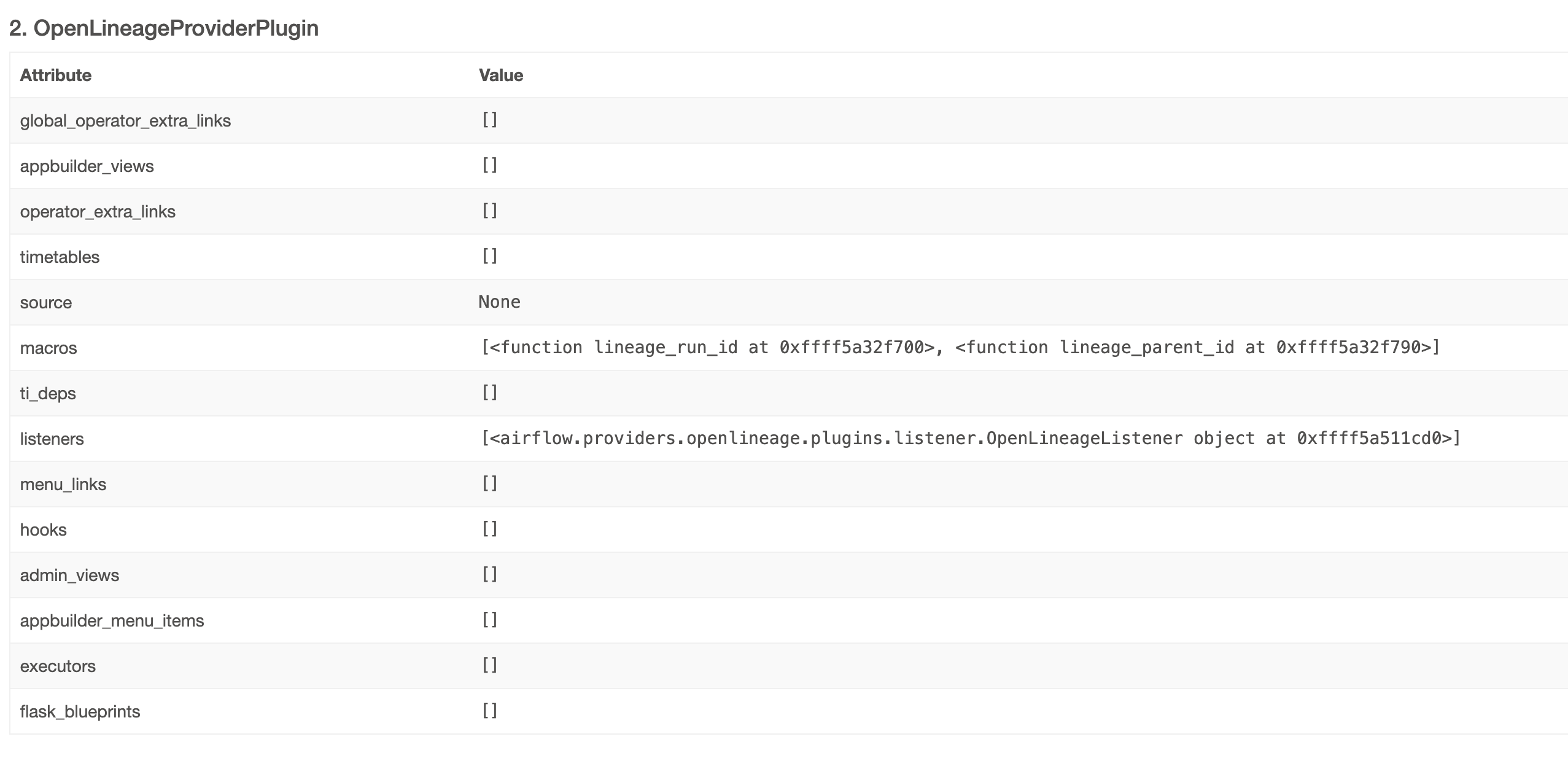{kind=link}
{kind=link}
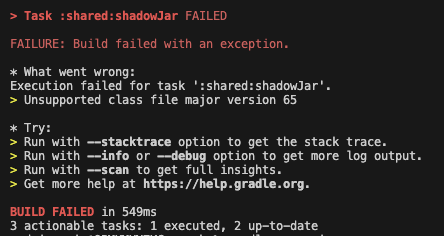{kind=link}
{kind=link}
{kind=link}
{kind=link}
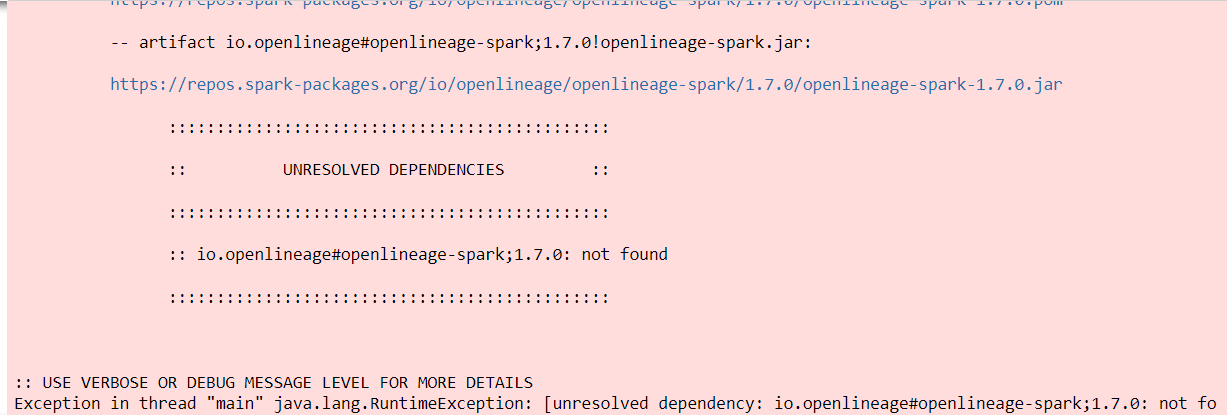{kind=link}
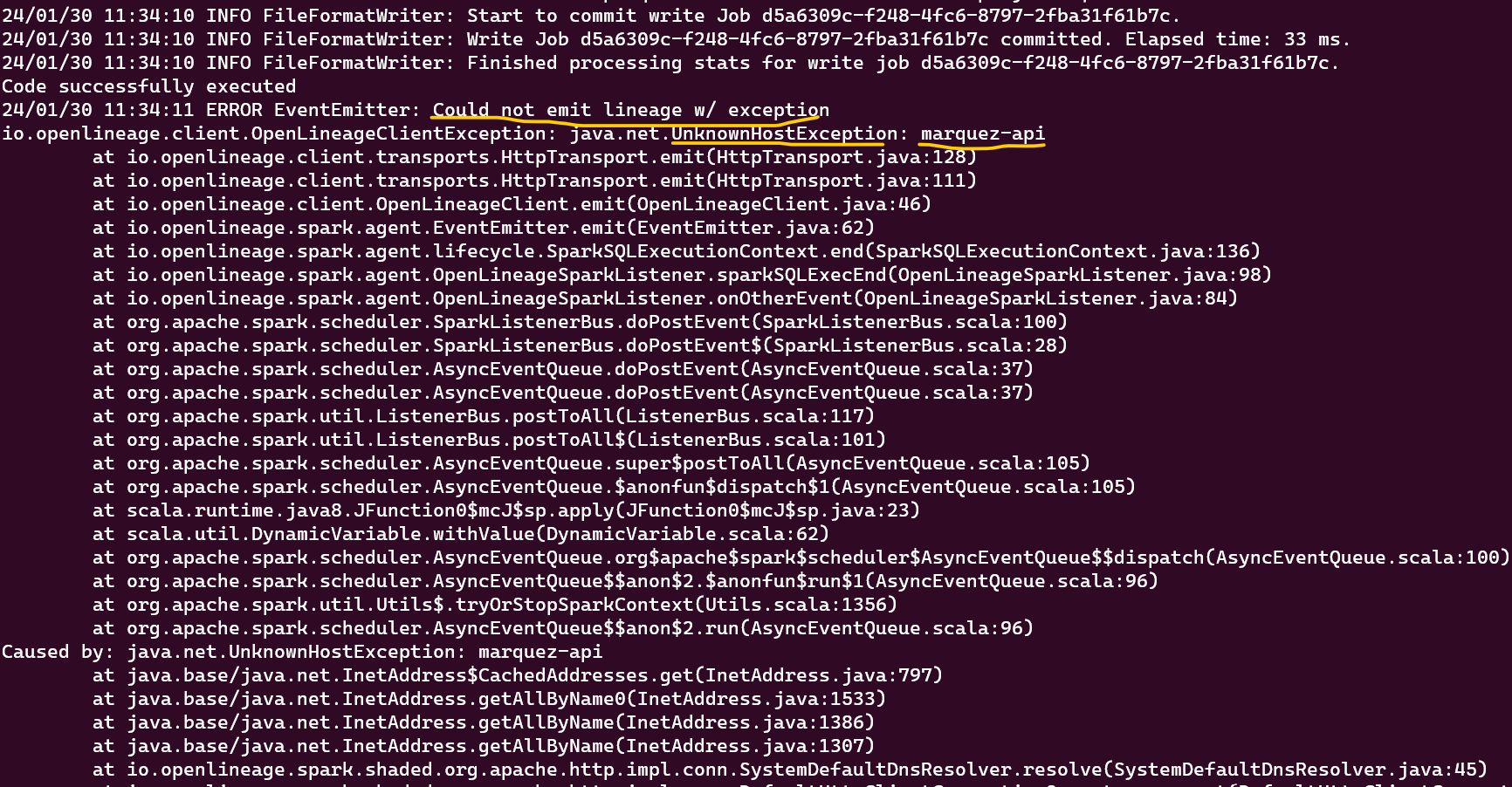{kind=link}
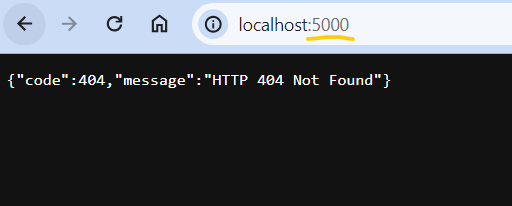{kind=link}
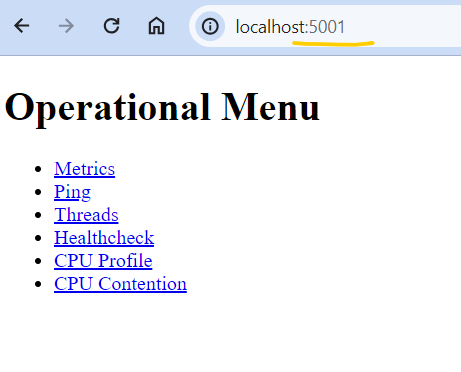{kind=link}
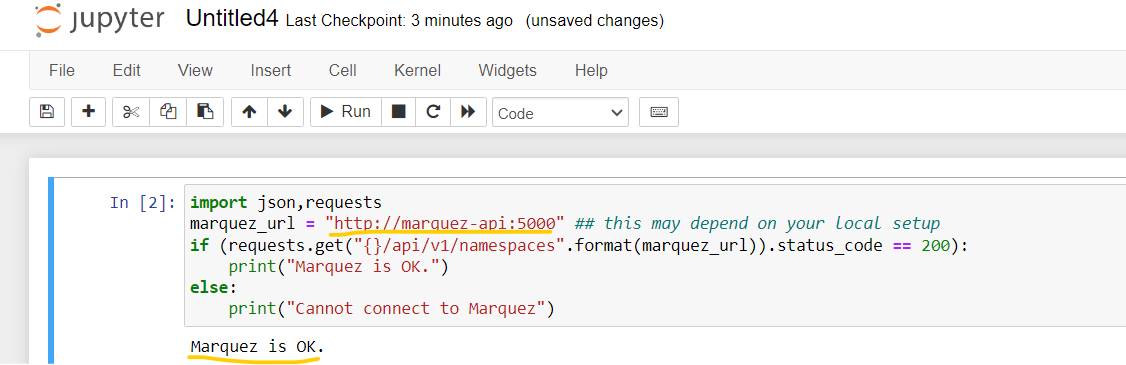{kind=link}
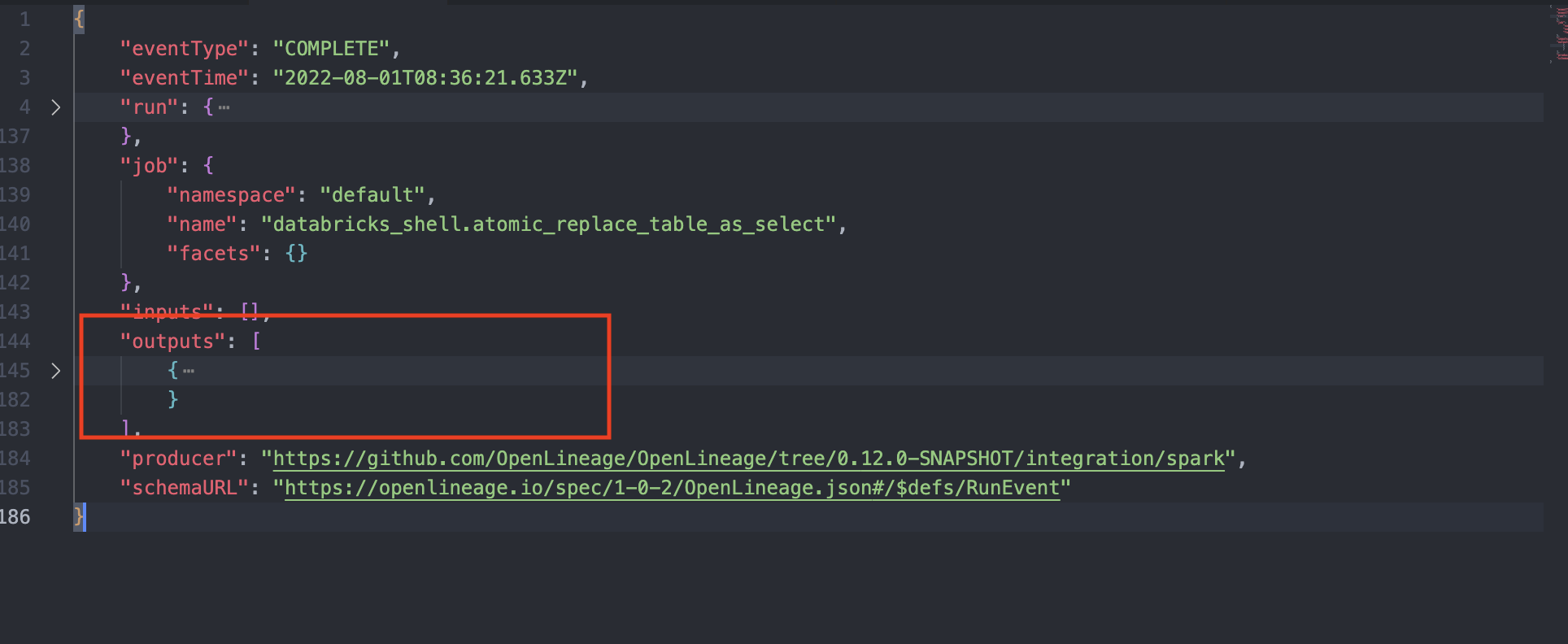{kind=link}
{kind=link}
{kind=link}
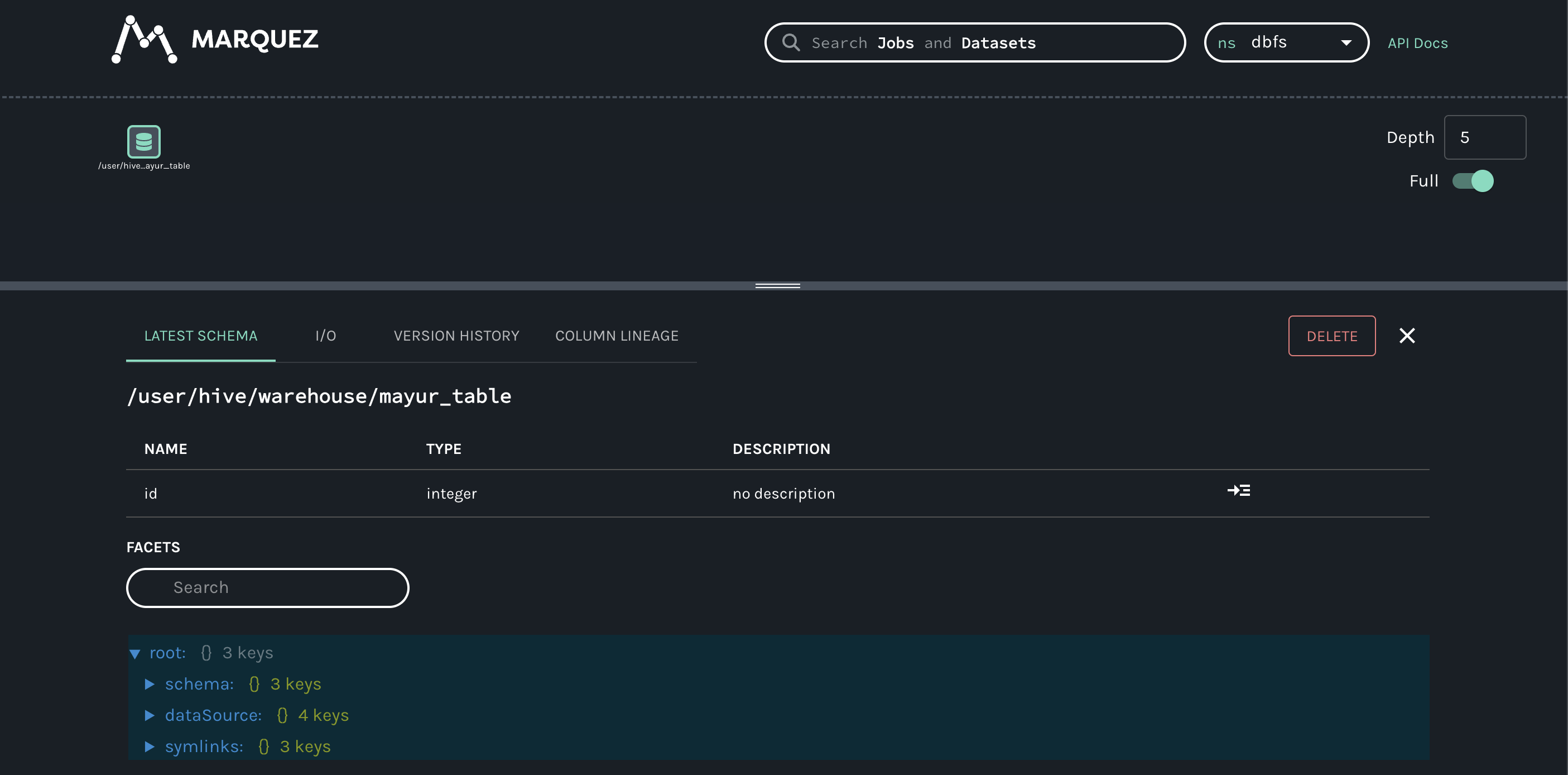{kind=link}
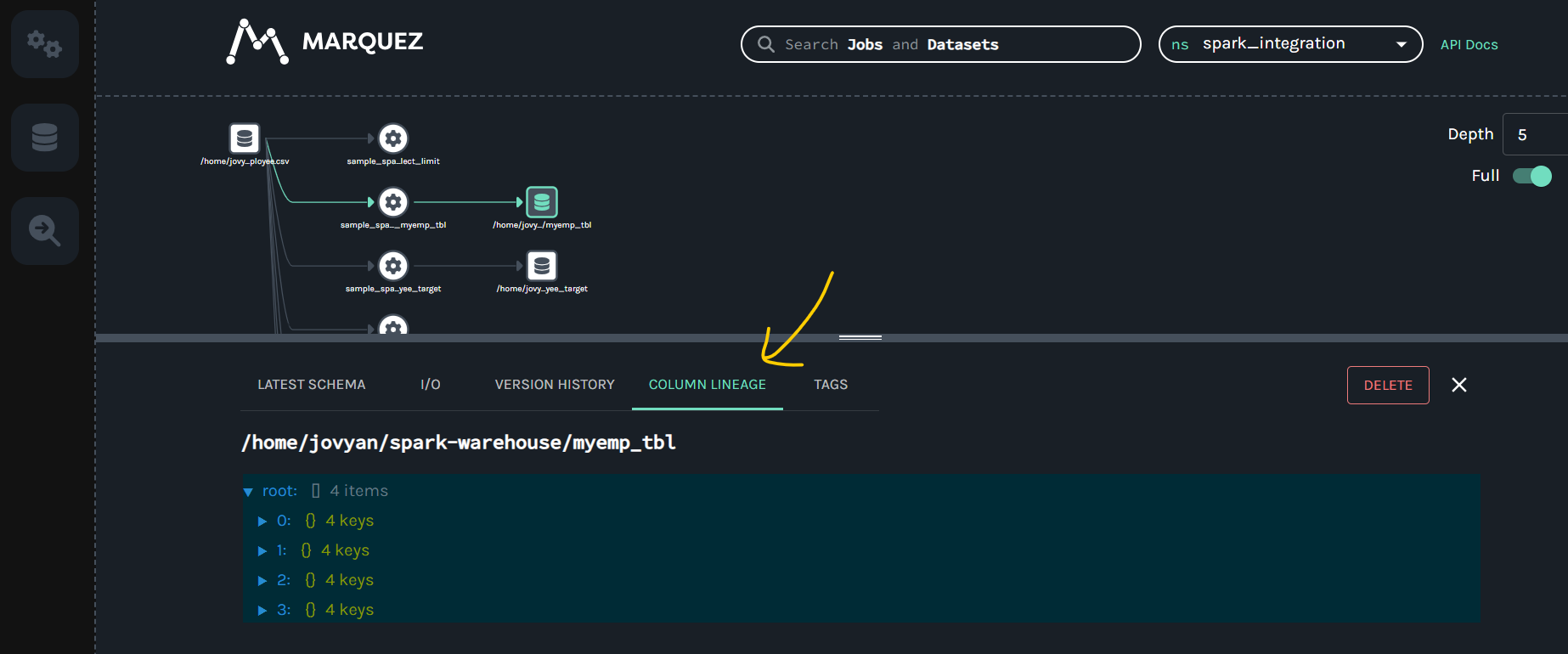{kind=link}
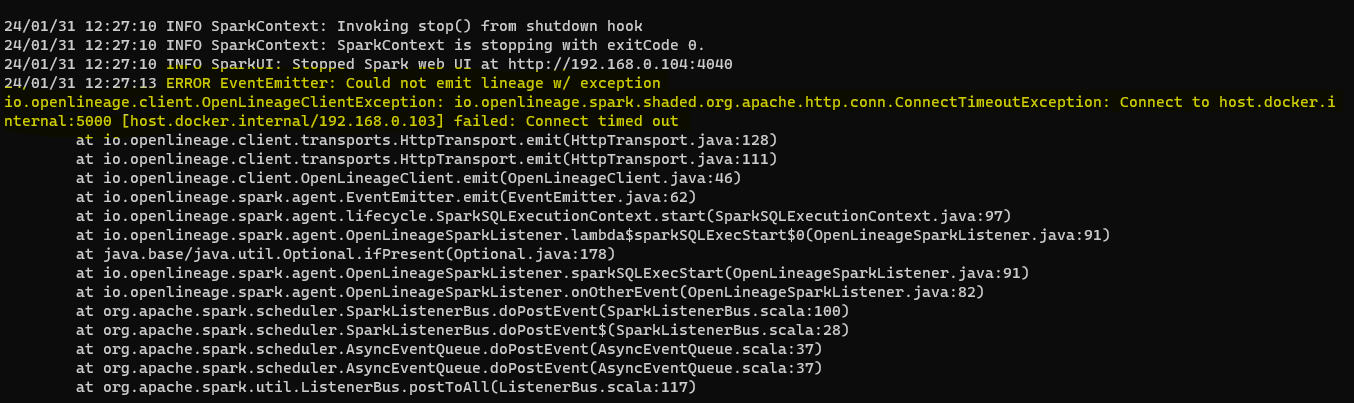{kind=link}
{kind=link}
{kind=link}
{kind=link}
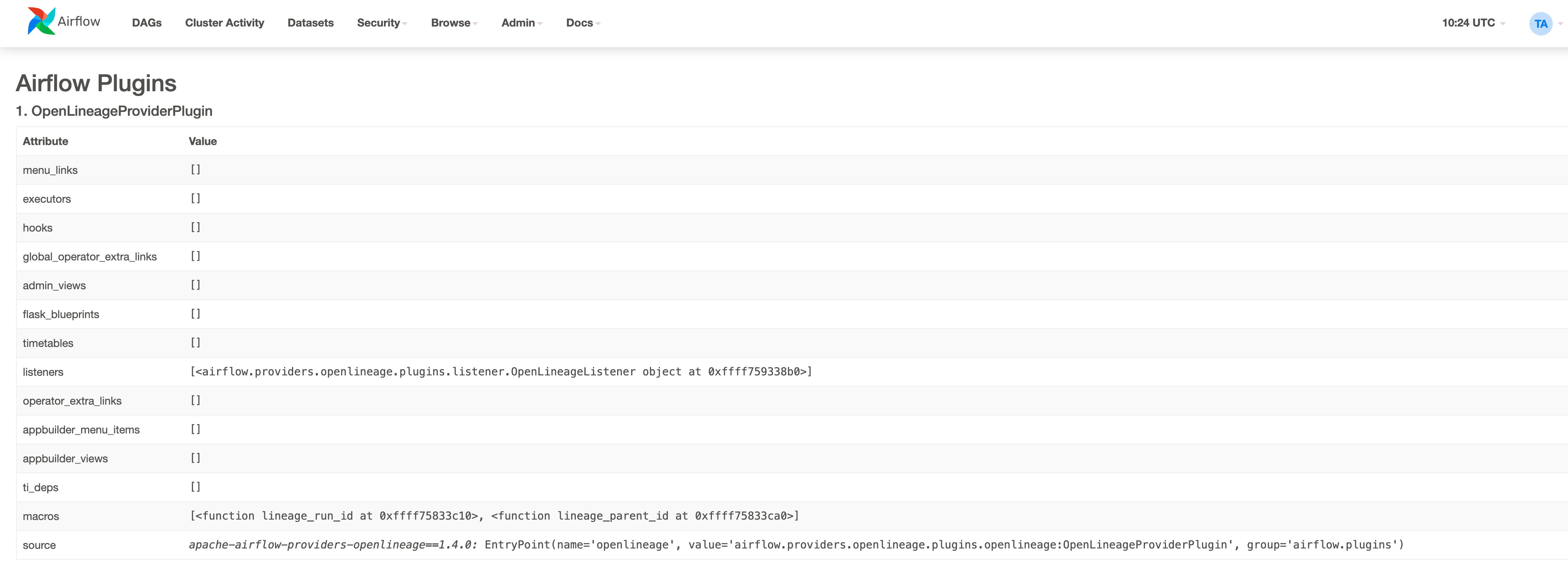{kind=link}
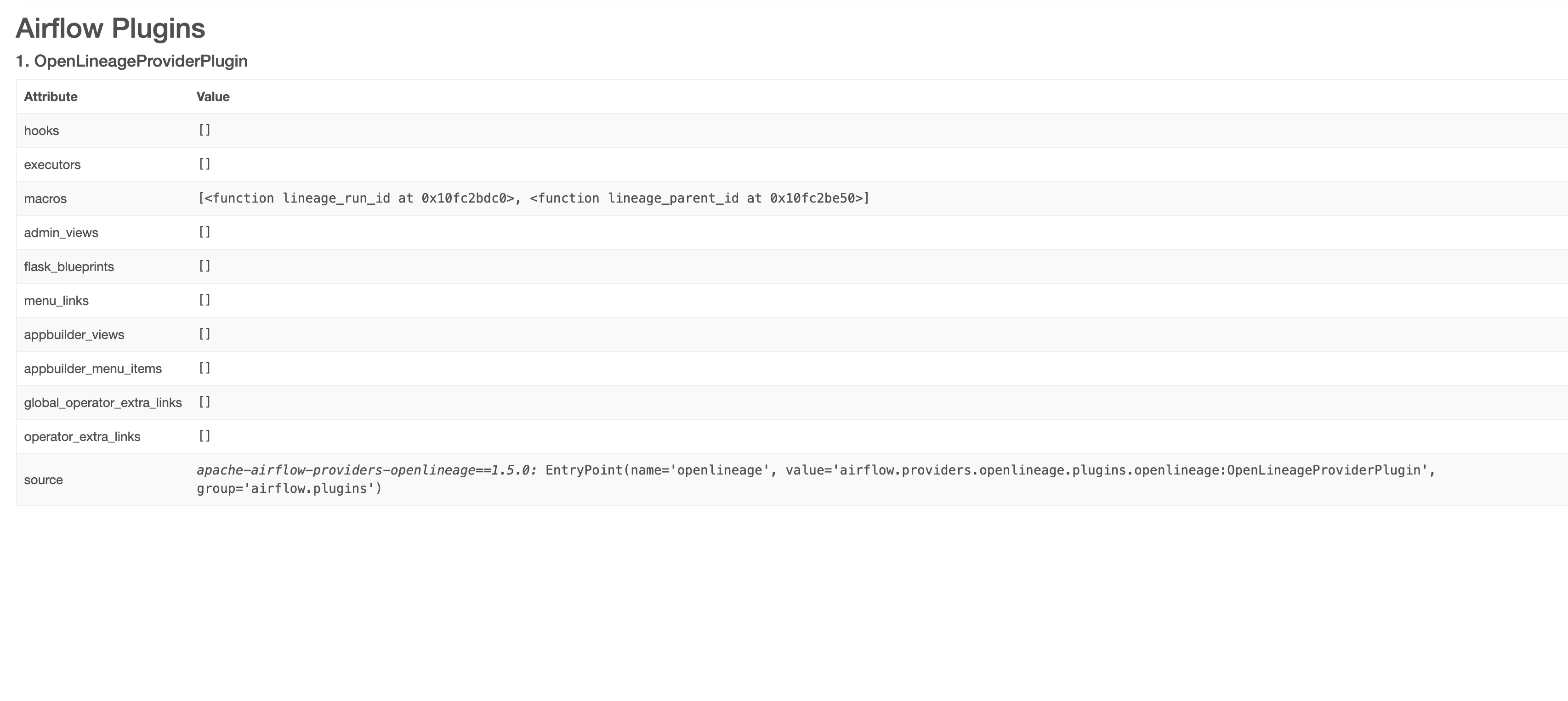{kind=link}
{kind=link}
{kind=link}
{kind=link}
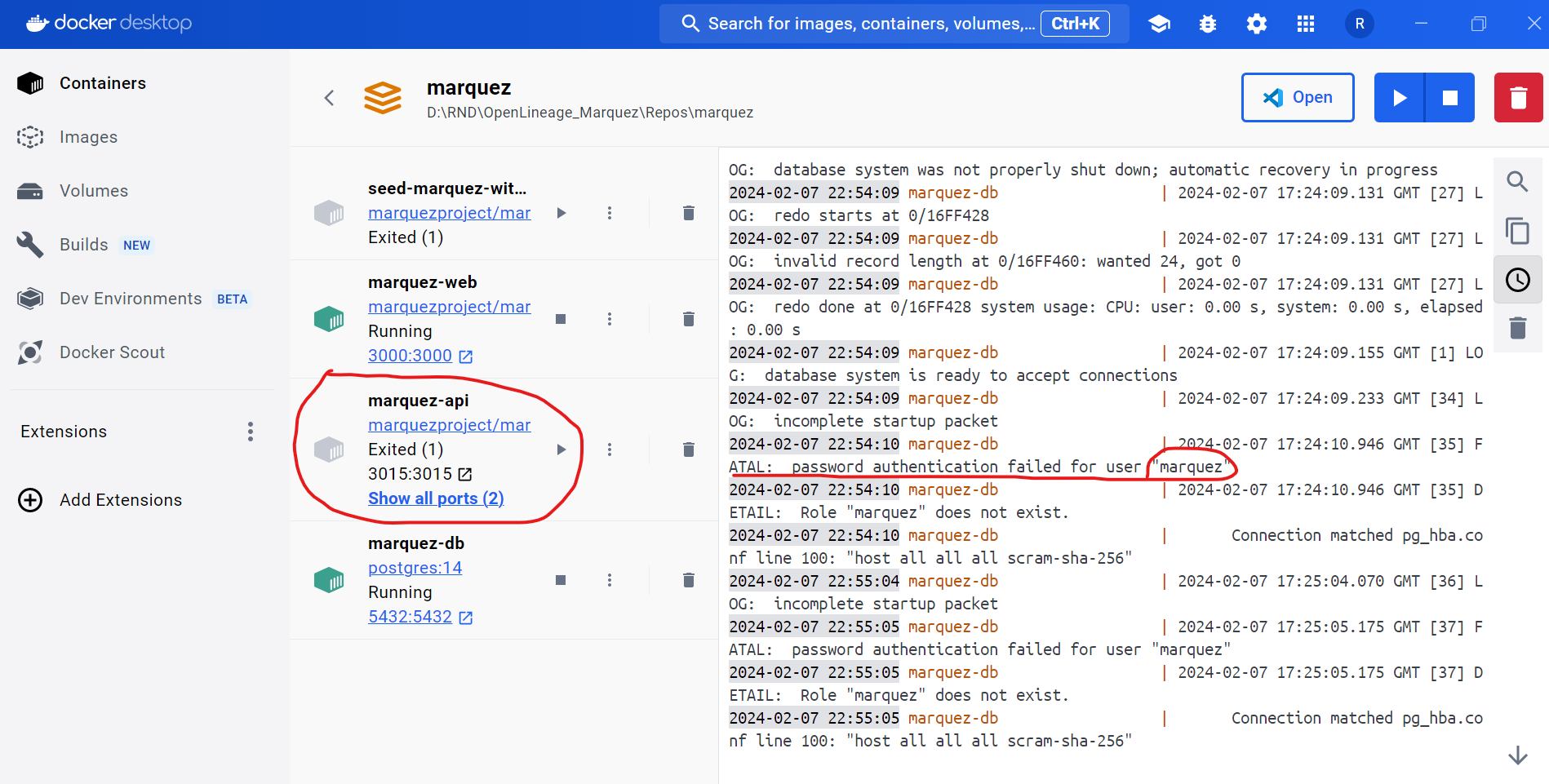{kind=link}
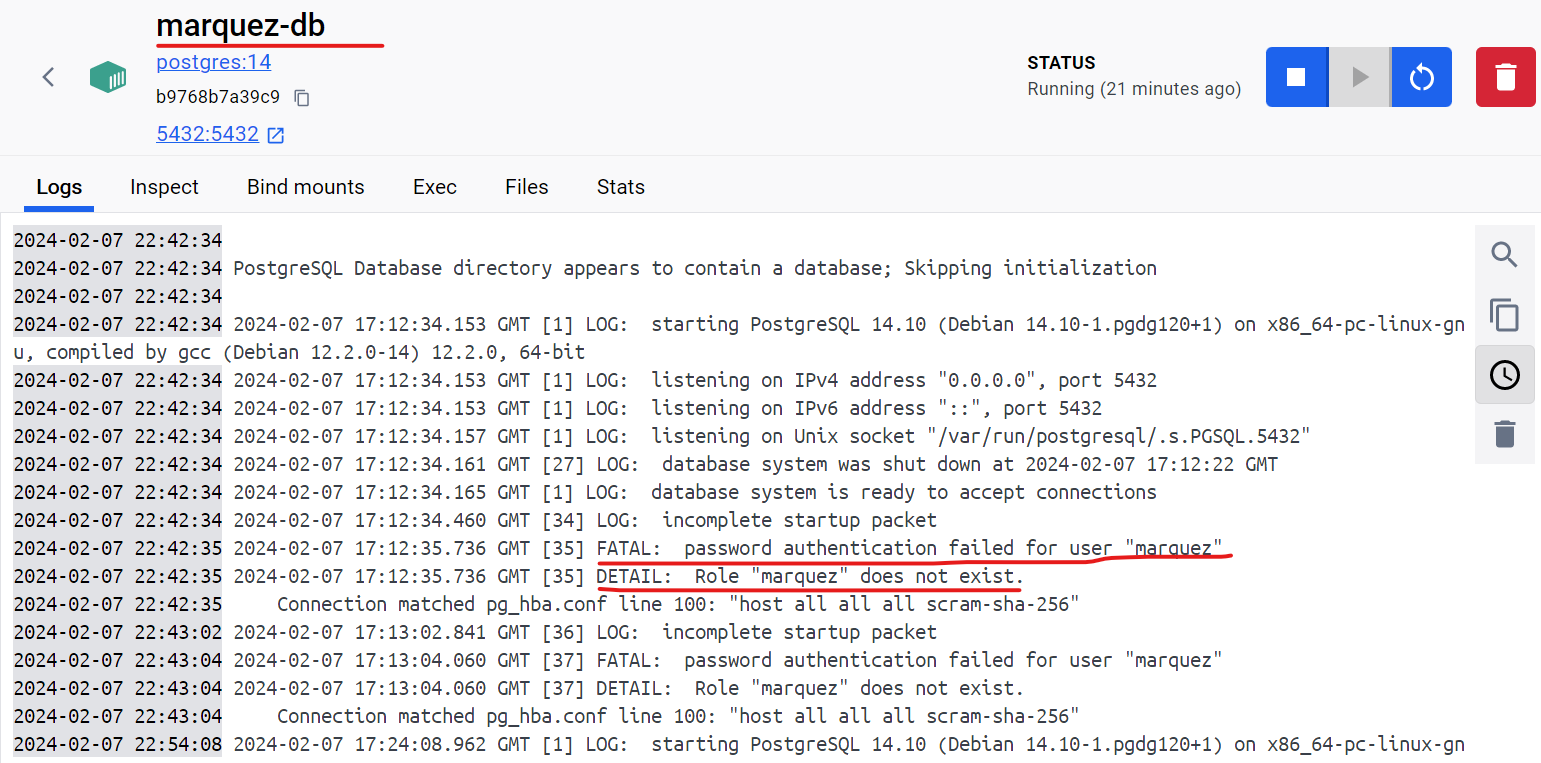{kind=link}
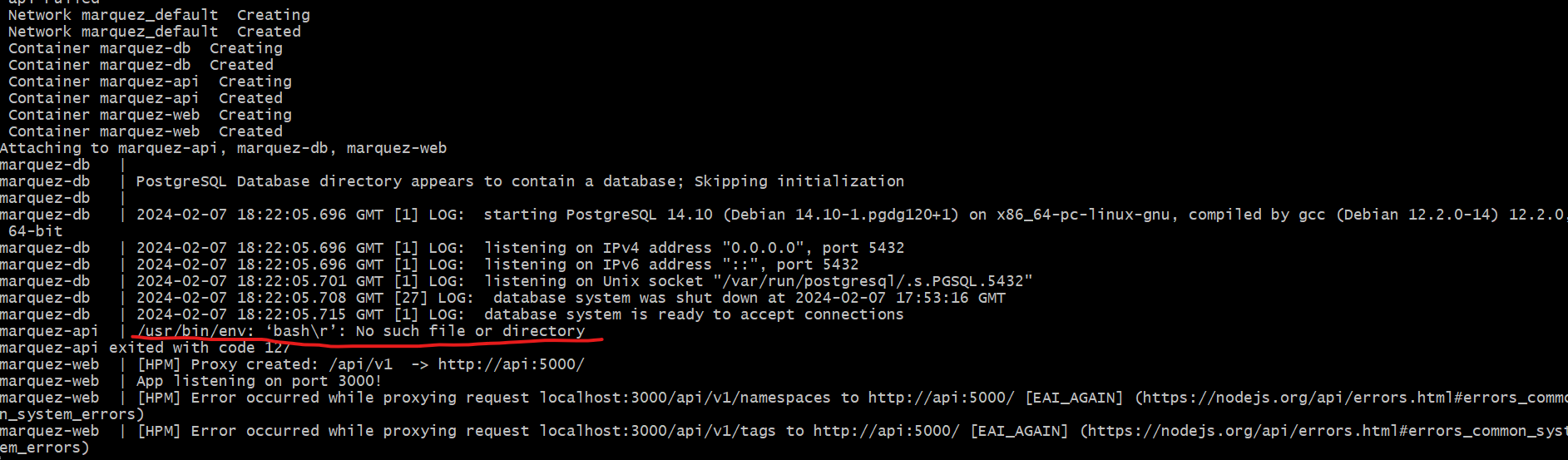{kind=link}
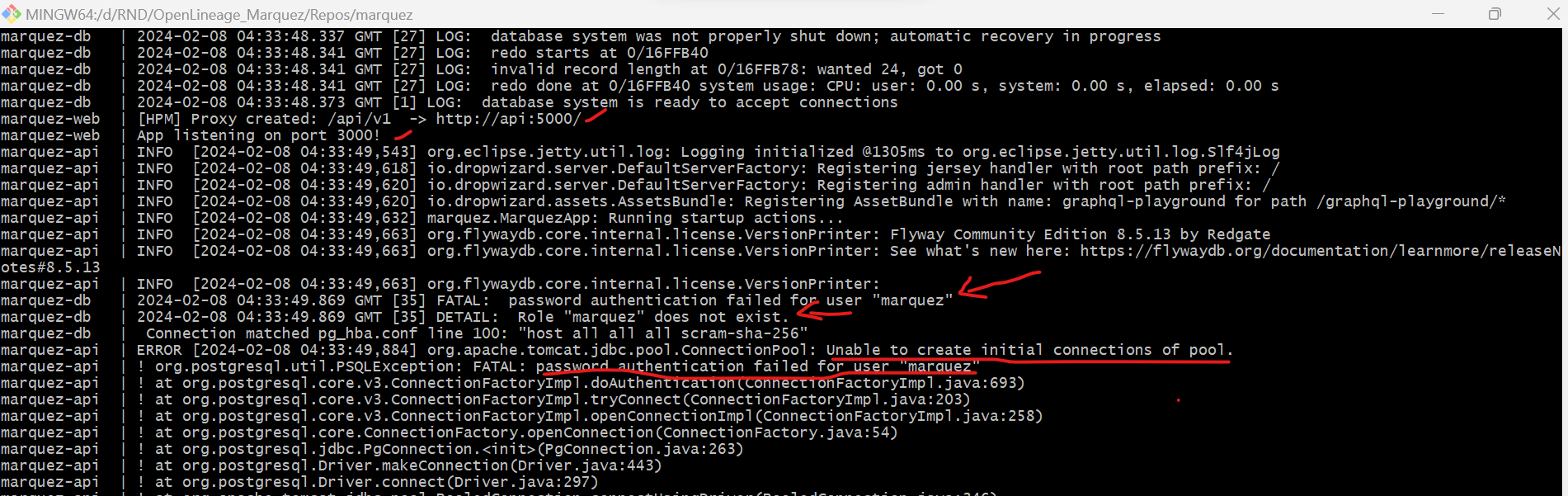{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
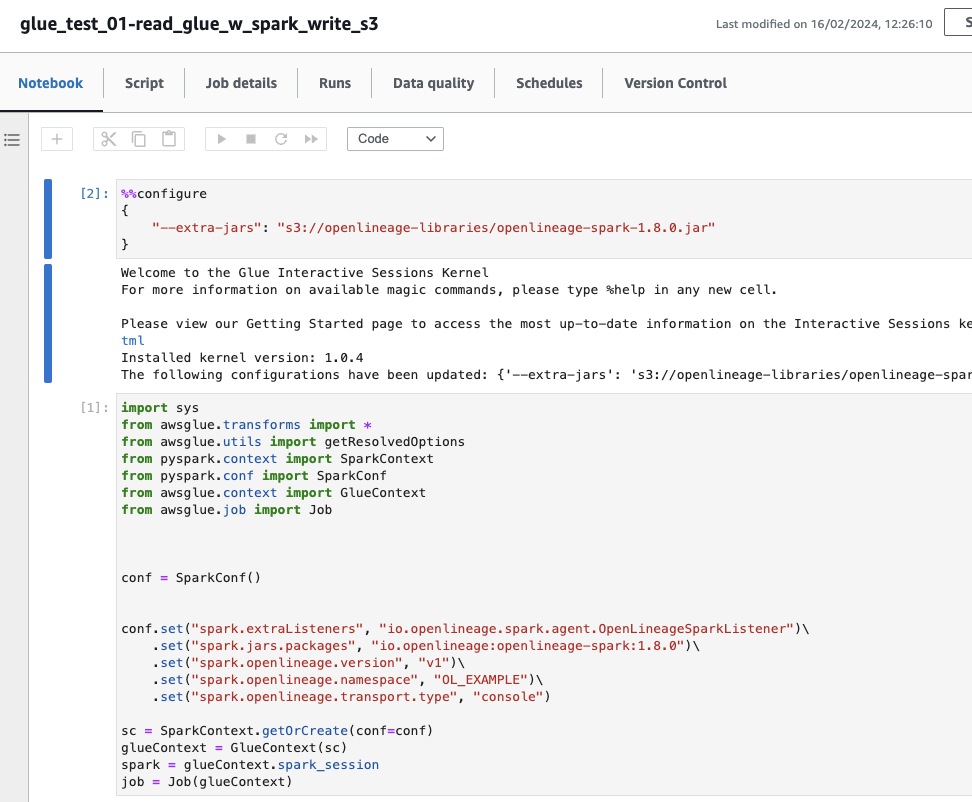{kind=link}
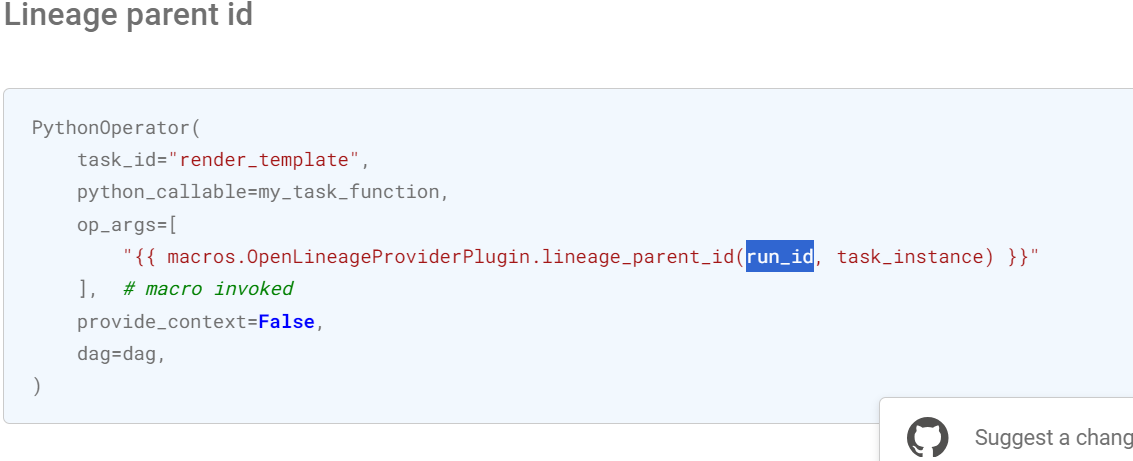{kind=link}
{kind=link}
{kind=link}
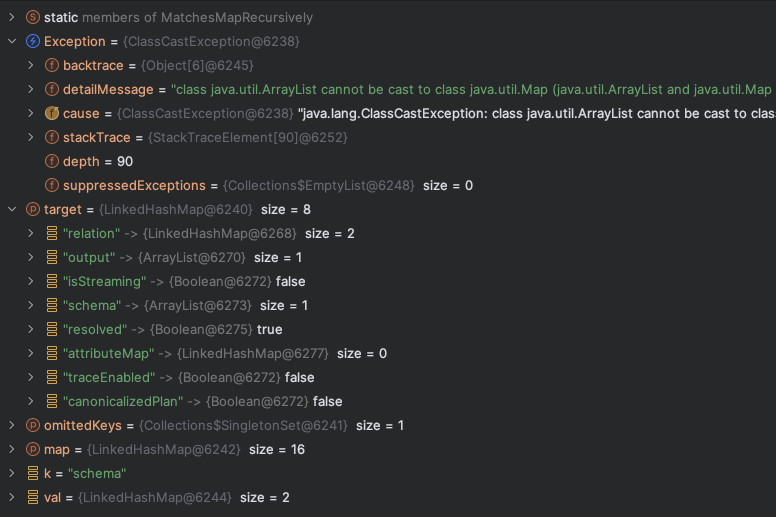{kind=link}
{kind=link}
{kind=link}
{kind=link}
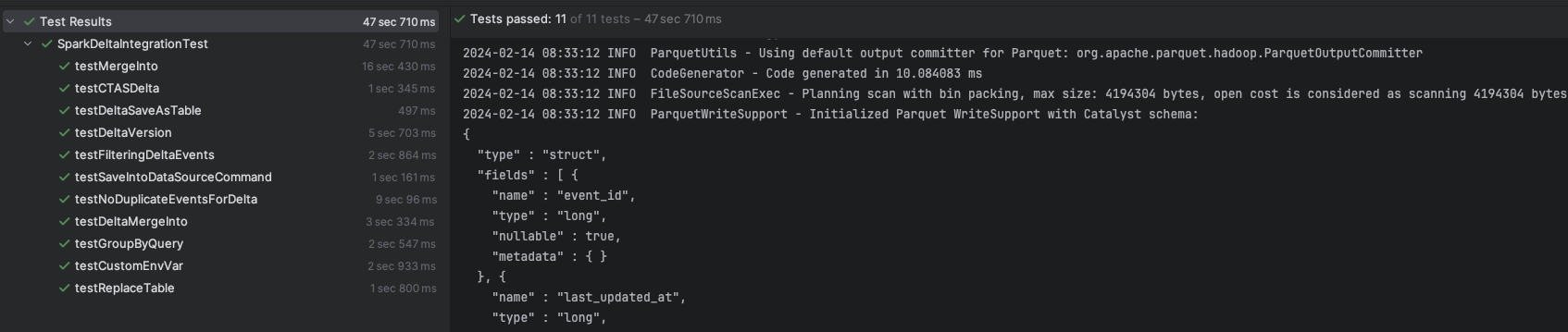{kind=link}
{kind=link}
{kind=link}