
Double-blind peer review mechanism has become the skeleton of academic research across multiple disciplines, yet several studies have questioned the quality of peer reviews and raised concerns on potential biases in the process. Although studying the peer-review process is of interet to many, features derived from textual data such as reviews or submissions are underused. This database tracks the latest International Conference on Learning Representations (ICLR) submissions/reviews/author profiles and conveniently packs metadata together with textual features for downstream analysis.
If you use this database in your work, please consider citing the following companion paper:
@misc{ZZDR22,
title = {Investigating Fairness Disparities in Peer Review: A Language Model Enhanced Approach},
author = {Zhang, Jiayao and Zhang, Hongming and Deng, Zhun and Roth, Dan},
url = {https://arxiv.org/abs/2211.06398},
publisher = {arXiv},
year = {2022},
}
Latest Snapshot:
A more refined and easy-to-follow notebook will be released soon. For the time being, please refer to
the companion paper and
the notebooks paper_summary.ipynb for instructions to reporduce figures and tables in the companion paper,
and the notebook analysis_glm.ipynb for the association studie via linear models.

ICLR is a leading CS conference whose data are openly available, thus providing a convenient platform for studying potential biases in the peer-review process. Indeed, the decision recommended by the area chair/program chair/meta reviewer is not a clearcut when the average rating is "borderlined," for example, between 5 to 7. As another example, some regions consistently have more accepted submissions, which may of be of interest to take a closer look at.


- whether any author is from a top 1% institution;
- whether any author is a top 1% author (measured by number of citation counts at the year of submission); and
- whether any author if from the US.



Below is a brief summary of the ICLR data from 2017-2022; we exclude all withdrawn submissions. For full table of all covariates, see the companion paper.
| 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|
| Submissions | 490 | 911 | 1419 | 2213 | 2595 | 2670 |
| Oral | 15 | 23 | 24 | 48 | 53 | 54 |
| Spotlight | 0 | 0 | 0 | 108 | 114 | 176 |
| Poster | 183 | 313 | 478 | 531 | 693 | 865 |
| Workshop* | 47 | 89 | 0 | 0 | 0 | 0 |
| Reject | 245 | 486 | 917 | 1526 | 1735 | 1574 |
| Author | 1416 | 2703 | 4286 | 6807 | 7968 | 8654 |
| Female | 81 | 162 | 298 | 503 | 529 | 770 |
| Male | 769 | 1565 | 2527 | 3951 | 3992 | 5524 |
| Non-Binary | 1 | 2 | 2 | 2 | 3 | 6 |
| Unspecified | 565 | 974 | 1458 | 2351 | 2125 | 2354 |
| Review | 1489 | 2748 | 4332 | 6721 | 10026 | 10401 |
| Response | 2811 | 4404 | 9504 | 11350 | 18896 | 21756 |
| Comment | 750 | 1002 | 1354 | 816 | 376 | 133 |
*When we perform analysis, we view papers with decision "Invited to Workshop Track" as a rejection.
We start with three higher-level textual features:
- Review sentiment from the RoBERTa Sentiment Model;
- Abstract embedding from the Specter Model; and
- Submission sentence-level fluency from the Parrot Paraphrase Model.
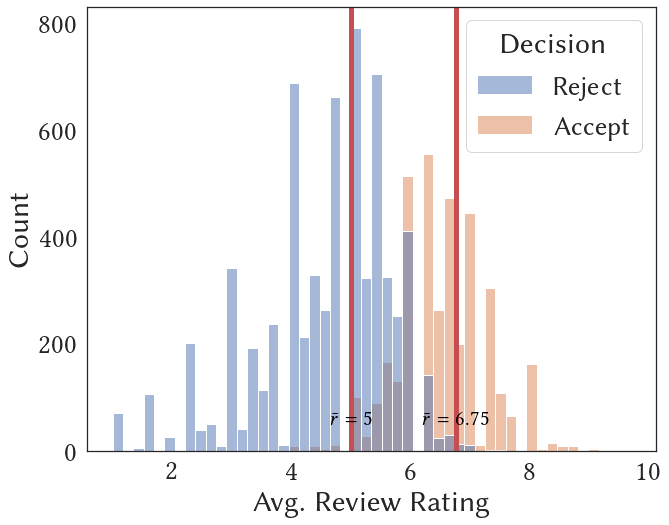
Below we show the review rating and sentiment histogram across submissions decisions; t-SNE embedding of the Specter abstract embedding from a random sample of submissions with known arXiv primary category; and a random arXiv sample of papers from different primary categories with their average sentence-level fluency. Note that more features can be constructed based on them. For example, we can assign topic clusters (in additional to reported keywords) using clustering algorithms on the Specter embedding.


Here we outline several example studies and tasks the ICLR Database enables.
More details can be found in the corresponding study.
We consider using the database from 2017-2022 to perform a matched-cohort study to test the Fisher's sharp null hypothesis of no effect:
where
by constructing
There are several ways of defininig the "prestige" of institutions; we consider two study designs,
After matching, we found the covariates are much more balanced, as shown in Tables 2-3 in the paper,
and also the following diagnostic plots of design

We can then perform a two-sided, exact McNemar's test, whose details are given in the following contigency table. The odds-ratio suggests some weak evidence that borderline articles from top-30% institutions were less favored by area chairs compared to their counterparts from the comparison group, defying the common wisdom of status bias. Nonetheless, as all retrospective, observational studies, we cannot be certain that our analysis was immune from any unmeasured confounding bias, and any interpretation of our results should be restricted to our designed matched sample and should not be generalized to other contexts.
| Design |
Comparison Articles | P-value | Odds Ratio (95%-CI) | ||
|---|---|---|---|---|---|
| Accepted | Rejected | ||||
| Top-30% Articles | Accepted | 633 | 178 | 0.050 | 0.82 (0.67, 1.00) |
| Rejected | 218 | 556 | |||
| Design |
Comparison Articles | ||||
| Accepted | Rejected | ||||
| Top-20% Articles | Accepted | 443 | 115 | 0.149 | 0.83 (0.64, 1.07) |
| Rejected | 139 | 354 |
One interesting question is that whether the inclusion
of (high-level) textual features would make classifiers
more fair (without using any fair algorithms.
We group features into several different groups,
including (i) base (submission features, including
high-level ones); (ii) author (on top of base, adding all
author featres; (iii) rev (on top of base, adding non high-level
review features (ratings, confidence, etc); (iv) revnlp (on top of rev,
adding sentiment of reviews); (v) all (throw all features).
Below we plot the disparity of score cdfs across sensitive groups (we use US author
as an example here, more are included in the companion paper), the largest
disparity is usually referred to as the Demographic Parity (DP, see e.g., Agarwal et al., 2019
and fairlearn metrics guide).
For this sensitive group, we note that the inclusion of review sentiments help to reduce DP from 0.073 to 0.070. However, note that the inclusion does not always help, as shown in the paper, it actually increase the DP for the groups based on top institutions.





With the availability of Longformer-Encoder-Decoder (LED) models that can take as inputs for a maximal of 16K tokens while most of submissions have below 12K tokens (see figure below), we are interested in conditional generationg of reviews on the tone of the review (positive (>7), negative (<5) or borderlined).

We fine-tune the LED model on the submission-review pairs based on the tone of the reviews
by minimizing the ROGUE score.
Tabulated below are two random samples from the test set, where (+) denotes the positive-toned generation
and (-) the negative generation.
| Model | Samples |
|---|---|
| Submission | 49h_IkpJtaE |
| Review Sample | In this paper, the authors introduce a novel audio-visual dereverberation approach. They propose a Visually-Informed Dereverberation of Audio (VIDA) model for dereverberation. The authors also create synthetic/simulated datasets and real-world data for experimentation. Finally, they show the impact of the proposed VIDA model on several speech tasks including, recognition, enhancement, and speaker verification. The results are encouraging... |
| LED Output (+) | This paper proposes a new task of dereverberating speech from audio-visual observations. The goal is to learn to dereverberate speech from audio-visual observations. The task is to learn to dereverberate speech from audio-visual observations. The task is to learn to dereverberate speech from audio-visual observations. The visual environment surrounding a human speaker reveals important cues about the room geometry, materials, and speaker location, all of which influence the precise reverberation effects in the audio stream... |
| LED Output (-) | This paper proposes a method to learn to dereverberate speech from audio-visual observations. The idea is to learn to dereverberate speech from audio-visual observations. The paper is well written and easy to follow. However, I have several concerns about the paper:\n\n1. The proposed method is not novel. The proposed method is based on the UNet encoder-decoder architecture. The UNet encoder is based on the UNet encoder architecture. The UNet encoder is based on the UNet encoder architecture... |
| Submission | 49h_IkpJtaE |
| Review Sample | The paper mainly investigates the effect of permutation in the class label assignment in the tasks for the MAML algorithm. First, the authors show that MAML requires a higher number of inner loop updates than what is commonly used. Then, they show that MAML is sensible to the permutation of the class labels in the tasks and experimented with diverse methods to alleviate this problem... |
| LED Output (+) | Summary:\n\nThe paper proposes a new model-agnostic meta-learning algorithm that is permutation-invariant in both the meta-training and meta-testing phases. The main idea is to meta-train only a single vector w, and use the learned initialization to initialize the linear classifiers. The inner loop optimization is done in the inner loop. The inner loop optimization is done in the inner loop... |
| LED Output (-) | This paper studies the problem of model-agnostic meta-learning (MAML) in few-shot learning. The main idea is to learn the initialization of an N-way classifier, which is the initialization of an N-way classifier, and then use the learned initialization to initialize the N linear classifiers. Experiments on MiniImageNet and TieredImageNet demonstrate the effectiveness of the proposed method.\n\nThe paper is well-written and easy to follow. However, I have some concerns about the novelty of the proposed method.\n\n1. The main idea of the paper is to learn the initialization of an N-way classifier, which is the initialization of an N-way classifier. However, the initialization of an N-way classifier is the initialization of an N-way classifier, which is the initialization of an N-way classifier... |
It is clear that there are several challenges. For example, reviews needs to contain summaries as well as opinions, which is hard to evaluate (even for humans, how to evaluate the novelty, say, of a paper?). In the generated samples above, we see that the summarization is usually done, whereas
there are signs of opinions (e.g., in the first sample, The proposed method is not novel.) Furthermore, there are several consistency issues, for example, in the negative output of the first sample, a complement (The proposed method is not novel.) is followed by a concern (However, I have several concerns about the paper.). As such, there are lots of rooms for improvement on this task and the ICLR Database may be a good corpus for baselining review generation tasks.
2023
2022